







开始在letcode刷题为以后工作打基础,先跟着“代码随想录”学习一遍,希望研一一年可以跟完。
这篇文章主要记录了开始学习或者练习代码之前需要注意的东西。包含了代码规范、刷题时是否调用库函数、两种刷题模式(核心代码模式和ACM模式)、互联网大厂研发流程、kv存储引擎介绍、git私服搭建等相关内容。
目录
一、代码规范
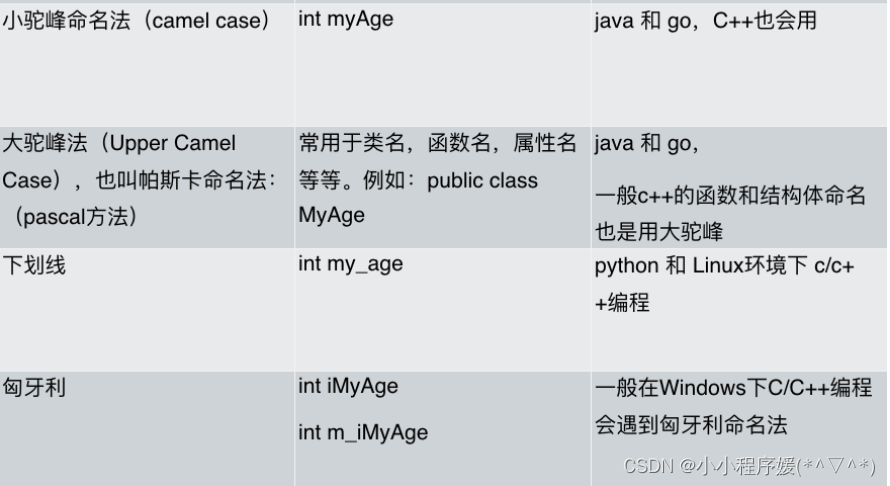
1.变量命名规则
- 小驼峰命名发:第一个单词首字母小写,后面其他单词首字母大写。例如
int myAge; - 大驼峰命名发:把第一个单词的首字母也大写了。例如:
int MyAge; - 下划线命名法:是名称中的每一个逻辑断点都用一个下划线来标记,例如:
int my_age - 匈牙利命名法:变量名 = 属性 + 类型 + 对象描述,例如:
int iMyAge;
2.水平留白(代码空格)
操作符左右一定有空格
i = i + 1;
分隔符(, 和;)前一位没有空格,后一位保持空格
int i, j;
for (int fastIndex = 0; fastIndex < nums.size(); fastIndex++)大括号和函数保持同一行,并有一个空格
while (n) {
n--;
}控制语句(while,if,for)后都有一个空格
while (n) {
if (k > 0) return 9;
n--;
}二、是否调用库函数
在刷代码的时候不建议调用库函数,最好根据题目的考点将该部分的知识点掌握好,否则就违背了刷题的本意。除非已经很清楚并掌握这种题型的解法,节约时间可以调用。
三、核心代码模式 VS ACM模式
ACM输入模式就是所有的代码内容都必须自己输入,推荐ACM模式练习网站kamacoder.com
力扣上是核心代码模式,就是把要处理的数据都已经放入容器里,可以直接写逻辑,例如这样:
class Solution {
public:
int minimumTotal(vector<vector<int>>& triangle) {
}
};四、互联网大厂研发流程
五、kv存储引擎
后端都要熟悉非关系型数据库redis,而redis的存储引擎是跳表实现的。
现在很多云厂商提供的云数据库,其底层都是用了Facebook开源的rocksdb,而rocksdb的底层是Google开源的Levedb,而Levedb的核心实现也是跳表。
如果你是后端开发的话,你在简历上一定会写熟悉或者了解redis吧,那么可以进一步介绍一下自己的项目用跳表实现了redis核心引擎。
面试官一定会非常感兴趣的,然后你就可以和面试官侃侃而谈你是如何用跳表实现的这个KV存储引擎的。
项目地址:https://github.com/youngyangyang04/Skiplist-CPP
该文档地址:手把手带你实现存储引擎 | 代码随想录
六、git私服搭建
参考“代码随想录”学习















 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









