






Leetcode剑指offer1
面试题09. 用两个栈实现队列(清晰图解)
解题思路:
栈无法实现队列功能: 栈底元素(对应队首元素)无法直接删除,需要将上方所有元素出栈。
双栈可实现列表倒序: 设有含三个元素的栈 A = [1,2,3]和空栈 B=[]。若循环执行 A 元素出栈并添加入栈 B ,直到栈 A 为空,则 A = [] , B=[3,2,1] ,即 栈 B 元素实现栈 A 元素倒序 。
利用栈 B 删除队首元素: 倒序后,B 执行出栈则相当于删除了 A 的栈底元素,即对应队首元素。

函数设计:
题目只要求实现 加入队尾appendTail() 和 删除队首deleteHead() 两个函数的正常工作,因此我们可以设计栈 A 用于加入队尾操作,栈 B 用于将元素倒序,从而实现删除队首元素。
加入队尾 appendTail()函数: 将数字 val 加入栈 A 即可。
删除队首deleteHead()函数: 有以下三种情况。
当栈 B 不为空: B中仍有已完成倒序的元素,因此直接返回 B 的栈顶元素。
否则,当 A 为空: 即两个栈都为空,无元素,因此返回 -1−1 。
否则: 将栈 A 元素全部转移至栈 B 中,实现元素倒序,并返回栈 B 的栈顶元素。
复杂度分析:
由于问题特殊,以下分析仅满足添加 N个元素并删除 N个元素,即栈初始和结束状态下都为空的情况。
时间复杂度: appendTail()函数为 O(1) ;deleteHead() 函数在 N 次队首元素删除操作中总共需完成 N 个元素的倒序。
空间复杂度 O(N) : 最差情况下,栈 A 和 B 共保存 N 个元素。
class CQueue {
LinkedList<Integer> A, B;
public CQueue() {
A = new LinkedList<Integer>();
B = new LinkedList<Integer>();
}
public void appendTail(int value) {
A.addLast(value);
}
public int deleteHead() {
if(!B.isEmpty()) return B.removeLast();
if(A.isEmpty()) return -1;
while(!A.isEmpty())
B.addLast(A.removeLast());
return B.removeLast();
}
}
面试题30. 包含 min 函数的栈(辅助栈,清晰图解)
解题思路:
普通栈的 push() 和 pop() 函数的复杂度为 O(1);而获取栈最小值 min() 函数需要遍历整个栈,复杂度为 O(N) 。
本题难点: 将 min() 函数复杂度降为 O(1) ,可通过建立辅助栈实现;
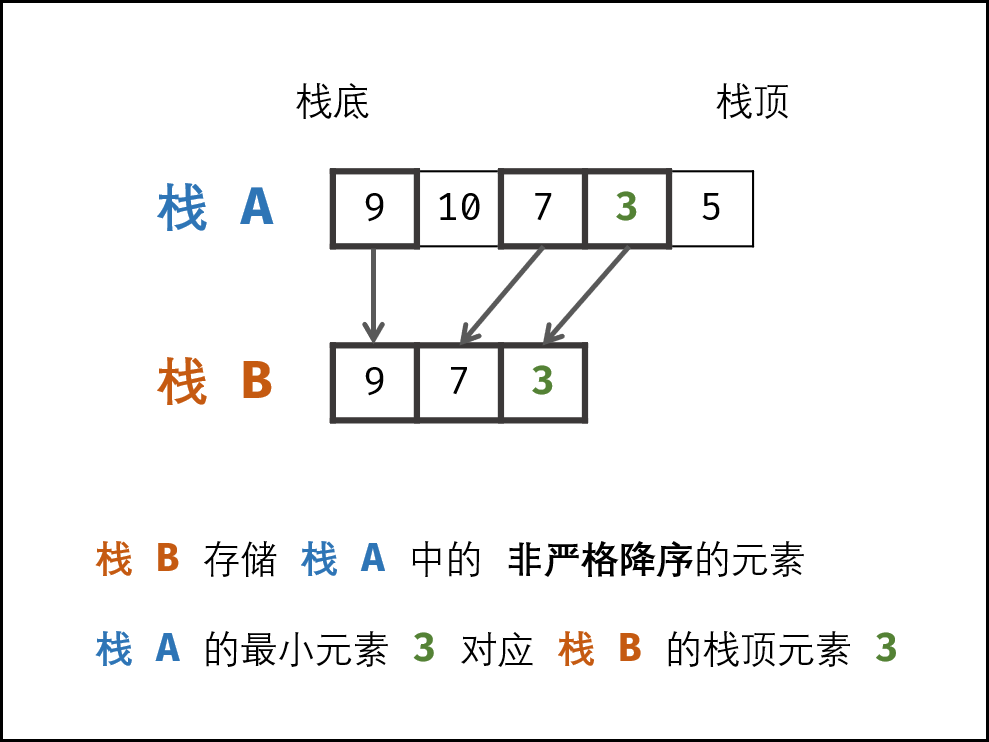
数据栈 A : 栈 A 用于存储所有元素,保证入栈 push() 函数、出栈 pop() 函数、获取栈顶 top() 函数的正常逻辑。
辅助栈 B : 栈 B 中存储栈 A中所有 非严格降序 的元素,则栈 A 中的最小元素始终对应栈 B 的栈顶元素,即 min() 函数只需返回栈 B 的栈顶元素即可。
因此,只需设法维护好 栈 B 的元素,使其保持非严格降序,即可实现 min() 函数的 O(1) 复杂度。
函数设计:
push(x) 函数: 重点为保持栈 B 的元素是 非严格降序 的。
- 将 x 压入栈 A (即 A.add(x) );
若 ① 栈 B 为空 或 ② xx 小于等于 栈 B 的栈顶元素,则将 xx 压入栈 B (即 B.add(x) )。
pop() 函数: 重点为保持栈 A, B 的 元素一致性 。 - 执行栈 A 出栈(即 A.pop() ),将出栈元素记为 yy ;
若 yy 等于栈 B的栈顶元素,则执行栈 B 出栈(即 B.pop() )。
top() 函数: 直接返回栈 A 的栈顶元素即可,即返回 A.peek() 。 - min() 函数: 直接返回栈 B 的栈顶元素即可,即返回 B.peek() 。
复杂度分析:
时间复杂度 O(1) : push(), pop(), top(), min() 四个函数的时间复杂度均为常数级别。
空间复杂度 O(N): 当共有 N 个待入栈元素时,辅助栈 B 最差情况下存储 N 个元素,使用 O(N)额外空间。
代码:
Java 代码中,由于 Stack 中存储的是 int 的包装类 Integer ,因此需要使用 equals() 代替 == 来比较值是否相等。
class MinStack {
Stack<Integer> stack = new Stack<>();
Stack<Integer> minStack = new Stack<>();
/** initialize your data structure here. */
public MinStack() {
}
public void push(int x) {
stack.push(x);
if(minStack.isEmpty()||x<=minStack.peek()){
minStack.push(x);
}
}
public void pop() {
if(stack.isEmpty())
return;
if (Objects.equals(stack.peek(), minStack.peek()))
{
stack.pop();
minStack.pop();
}
else stack.pop();
}
public int top() {
return stack.peek();
}
public int min() {
return minStack.peek();
}
}
/**
* Your MinStack object will be instantiated and called as such:
* MinStack obj = new MinStack();
* obj.push(x);
* obj.pop();
* int param_3 = obj.top();
* int param_4 = obj.min();
*/
面试题06. 从尾到头打印链表(递归法、辅助栈法,清晰图解)
方法一:递归法
解题思路:
利用递归: 先走至链表末端,回溯时依次将节点值加入列表 ,这样就可以实现链表值的倒序输出。
Java 算法流程:
递推阶段: 每次传入 head.next ,以 head == null(即走过链表尾部节点)为递归终止条件,此时直接返回。
回溯阶段: 层层回溯时,将当前节点值加入列表,即tmp.add(head.val)。
最终,将列表 tmp 转化为数组 res ,并返回即可。
复杂度分析:
时间复杂度 O(N): 遍历链表,递归 N 次。
空间复杂度 O(N): 系统递归需要使用 O(N)的栈空间。
图解以 Python 代码为例, Java 原理一致,只是把利用返回值改为 add() 操作。
class Solution {
ArrayList<Integer> tmp = new ArrayList<Integer>();
public int[] reversePrint(ListNode head) {
recur(head);
int[] res = new int[tmp.size()];
for(int i = 0; i < res.length; i++)
res[i] = tmp.get(i);
return res;
}
void recur(ListNode head) {
if(head == null) return;
recur(head.next);
tmp.add(head.val);
}
}
方法二:辅助栈法
解题思路:
链表特点: 只能从前至后访问每个节点。
题目要求: 倒序输出节点值。
这种 先入后出 的需求可以借助 栈 来实现。
算法流程:
入栈: 遍历链表,将各节点值 push 入栈。(Python 使用 append() 方法,Java借助 LinkedList 的addLast()方法)。
出栈: 将各节点值 pop 出栈,存储于数组并返回。(Python 直接返回 stack 的倒序列表,Java 新建一个数组,通过 popLast() 方法将各元素存入数组,实现倒序输出)。
复杂度分析:
时间复杂度 O(N): 入栈和出栈共使用 O(N)O(N) 时间。
空间复杂度 O(N): 辅助栈 stack 和数组 res 共使用 O(N)O(N) 的额外空间。
图解以 Java 代码为例,Python 无需将 stack 转移至 res,而是直接返回倒序数组。
class Solution {
public int[] reversePrint(ListNode head) {
LinkedList<Integer> stack = new LinkedList<Integer>();
while(head != null) {
stack.addLast(head.val);
head = head.next;
}
int[] res = new int[stack.size()];
for(int i = 0; i < res.length; i++)
res[i] = stack.removeLast();
return res;
}
}
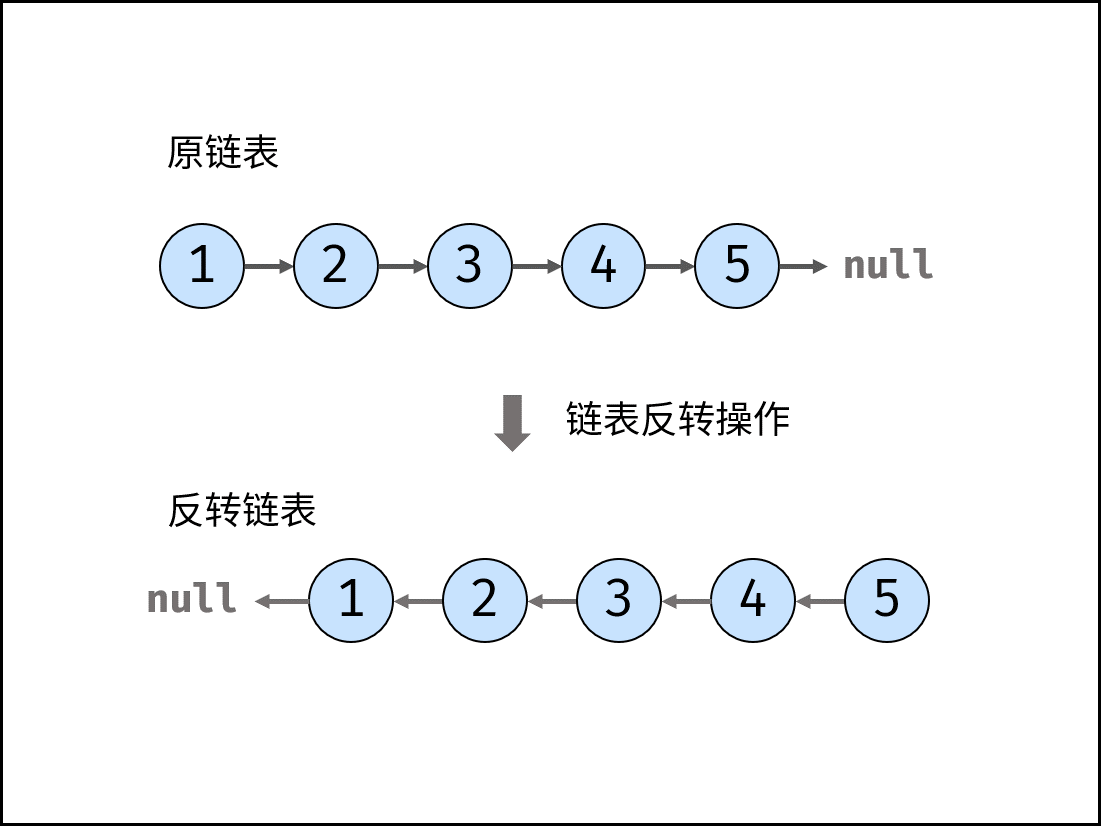
剑指 Offer 24. 反转链表(迭代 / 递归,清晰图解)
解题思路:
如下图所示,题目要求将链表反转。本文介绍迭代(双指针)、递归两种实现方法。
方法一:迭代(双指针)
考虑遍历链表,并在访问各节点时修改 next 引用指向,算法流程见注释。
复杂度分析:
时间复杂度 O(N): 遍历链表使用线性大小时间。
空间复杂度 O(1) : 变量 pre 和 cur 使用常数大小额外空间。
class Solution {
public ListNode reverseList(ListNode head) {
ListNode cur = head, pre = null;
while(cur != null) {
ListNode tmp = cur.next; // 暂存后继节点 cur.next
cur.next = pre; // 修改 next 引用指向
pre = cur; // pre 暂存 cur
cur = tmp; // cur 访问下一节点
}
return pre;
}
}
方法二:递归
考虑使用递归法遍历链表,当越过尾节点后终止递归,在回溯时修改各节点的 next 引用指向。
recur(cur, pre) 递归函数:
终止条件:当 cur 为空,则返回尾节点 pre (即反转链表的头节点);
递归后继节点,记录返回值(即反转链表的头节点)为 res ;
修改当前节点 cur 引用指向前驱节点 pre ;
返回反转链表的头节点 res ;
reverseList(head) 函数:
调用并返回 recur(head, null) 。传入 null 是因为反转链表后, head 节点指向 null ;
复杂度分析:
时间复杂度 O(N) : 遍历链表使用线性大小时间。
空间复杂度 O(N) : 遍历链表的递归深度达到 N,系统使用 O(N) 大小额外空间。
class Solution {
public ListNode reverseList(ListNode head) {
return recur(head, null); // 调用递归并返回
}
private ListNode recur(ListNode cur, ListNode pre) {
if (cur == null) return pre; // 终止条件
ListNode res = recur(cur.next, cur); // 递归后继节点
cur.next = pre; // 修改节点引用指向
return res; // 返回反转链表的头节点
}
}
剑指 Offer 35. 复杂链表的复制(哈希表 / 拼接与拆分,清晰图解)
普通链表的节点定义如下:
// Definition for a Node.
class Node {
int val;
Node next;
public Node(int val) {
this.val = val;
this.next = null;
}
}
本题链表的节点定义如下:
// Definition for a Node.
class Node {
int val;
Node next, random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
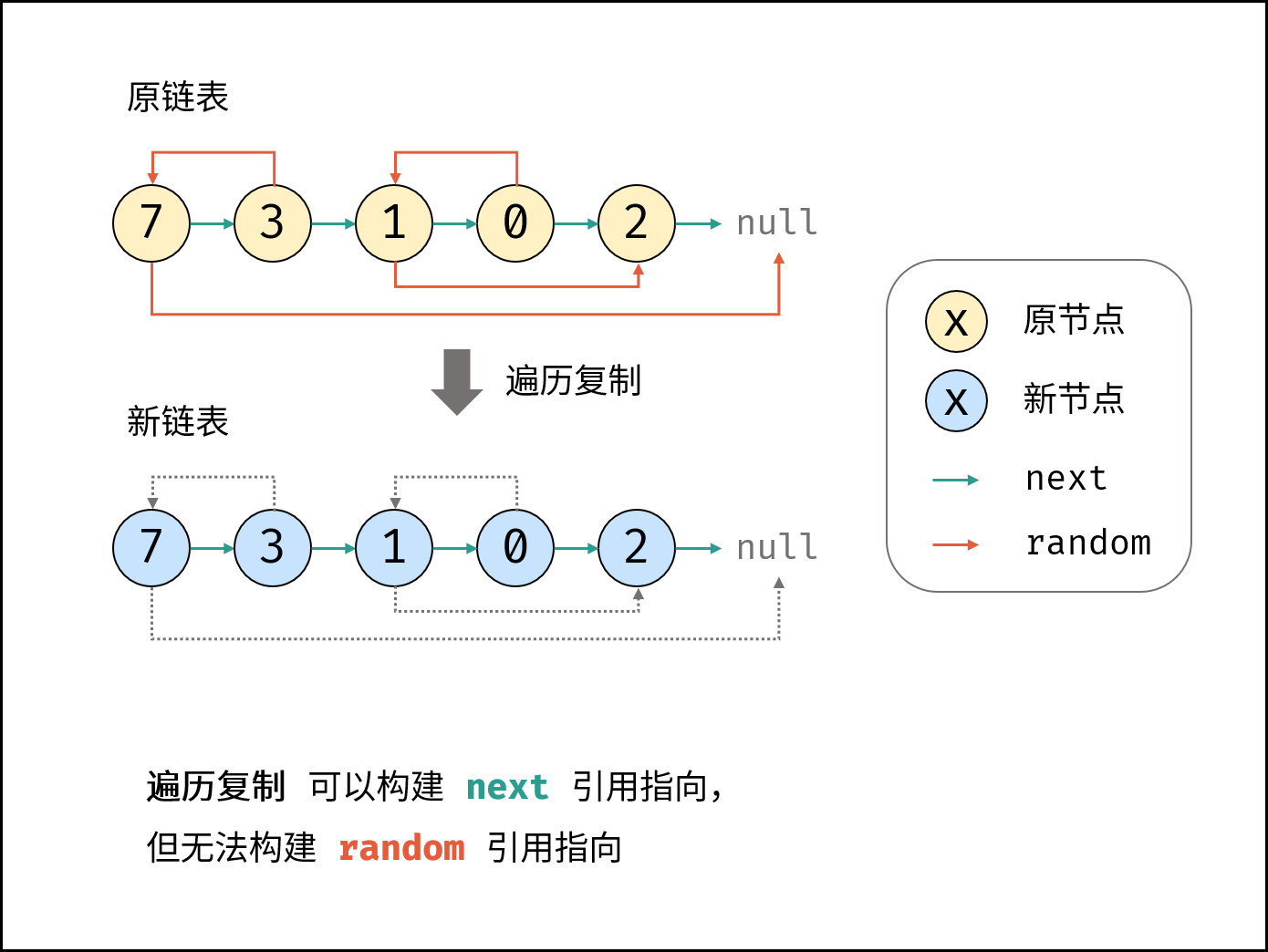
给定链表的头节点 head ,复制普通链表很简单,只需遍历链表,每轮建立新节点 + 构建前驱节点 pre 和当前节点 node 的引用指向即可。
本题链表的节点新增了 random 指针,指向链表中的 任意节点 或者 nul 。这个 random 指针意味着在复制过程中,除了构建前驱节点和当前节点的引用指向 pre.next ,还要构建前驱节点和其随机节点的引用指向 pre.random 。
本题难点: 在复制链表的过程中构建新链表各节点的 random 引用指向。
class Solution {
public Node copyRandomList(Node head) {
Node cur = head;
Node dum = new Node(0), pre = dum;
while(cur != null) {
Node node = new Node(cur.val); // 复制节点 cur
pre.next = node; // 新链表的 前驱节点 -> 当前节点
// pre.random = "???"; // 新链表的 「 前驱节点 -> 当前节点 」 无法确定
cur = cur.next; // 遍历下一节点
pre = node; // 保存当前新节点
}
return dum.next;
}
}
方法一:哈希表
利用哈希表的查询特点,考虑构建 原链表节点 和 新链表对应节点 的键值对映射关系,再遍历构建新链表各节点的 next 和 random 引用指向即可。
算法流程:
若头节点 head 为空节点,直接返回 null;
初始化: 哈希表 dic , 节点 cur 指向头节点;
复制链表:
建立新节点,并向 dic 添加键值对 (原 cur 节点, 新 cur 节点) ;
cur 遍历至原链表下一节点;
构建新链表的引用指向:
构建新节点的 next 和 random 引用指向;
cur 遍历至原链表下一节点;
返回值: 新链表的头节点 dic[cur] ;
复杂度分析:
时间复杂度 O(N) : 两轮遍历链表,使用 O(N)时间。
空间复杂度 O(N) : 哈希表 dic 使用线性大小的额外空间。
class Solution {
public Node copyRandomList(Node head) {
if(head == null) return null;
Node cur = head;
Map<Node, Node> map = new HashMap<>();
// 3. 复制各节点,并建立 “原节点 -> 新节点” 的 Map 映射
while(cur != null) {
map.put(cur, new Node(cur.val));
cur = cur.next;
}
cur = head;
// 4. 构建新链表的 next 和 random 指向
while(cur != null) {
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
}
// 5. 返回新链表的头节点
return map.get(head);
}
}
面试题05. 替换空格 (字符串修改,清晰图解)
方法一:遍历添加
在 Python 和 Java 等语言中,字符串都被设计成「不可变」的类型,即无法直接修改字符串的某一位字符,需要新建一个字符串实现。
算法流程:
初始化一个 list (Python) / StringBuilder (Java) ,记为 res ;
遍历列表 s 中的每个字符 c :
当 c 为空格时:向 res 后添加字符串 “%20” ;
当 c 不为空格时:向 res 后添加字符 c ;
将列表 res 转化为字符串并返回。
复杂度分析:
时间复杂度 O(N): 遍历使用 O(N),每轮添加(修改)字符操作使用 O(1) ;
空间复杂度 O(N) : Python 新建的 list 和 Java 新建的 StringBuilder 都使用了线性大小的额外空间。
class Solution {
public String replaceSpace(String s) {
StringBuilder res = new StringBuilder();
for(Character c : s.toCharArray())
{
if(c == ' ') res.append("%20");
else res.append(c);
}
return res.toString();
}
}
二分法详解
面试题11. 旋转数组的最小数字(二分法,清晰图解)
如下图所示,寻找旋转数组的最小元素即为寻找 右排序数组 的首个元素 nums[x] ,称 x 为 旋转点 。

排序数组的查找问题首先考虑使用 二分法 解决,其可将 遍历法 的 线性级别 时间复杂度降低至 对数级别 。
二分法的思路:
初始化: 声明 i, j双指针分别指向 nums 数组左右两端;
循环二分: 设 m = (i + j) / 2 为每次二分的中点( “/” 代表向下取整除法,因此恒有 i <= m < j ),可分为以下三种情况:
- 当 nums[m] > nums[j]时: m一定在 左排序数组 中,即旋转点 x 一定在 [m + 1, j] 闭区间内,因此执行 i = m + 1i=m+1;
- 当 nums[m] < nums[j] 时: m 一定在 右排序数组 中,即旋转点 x 一定在[i, m]闭区间内,因此执行 j = m;
- 当 nums[m] = nums[j] 时: 无法判断 m 在哪个排序数组中,即无法判断旋转点 x 在 [i, m]还是 [m + 1, j] 区间中。解决方案: 执行 j = j - 1 缩小判断范围,分析见下文。
返回值: 当i=j 时跳出二分循环,并返回 旋转点的值 nums[i] 即可。
而证明 j = j - 1 正确(缩小区间安全性),需分为两种情况:
当 x < j 时: 易得执行 j = j - 1 后,旋转点 x 仍在区间 [i, j] 内。
当 x = j 时: 执行 j = j - 1 后越过(丢失)了旋转点 x ,但最终返回的元素值 nums[i] 仍等于旋转点值 nums[x] 。
class Solution {
public int minArray(int[] numbers) {
int i = 0, j = numbers.length - 1;
while (i < j) {
int m = (i + j) / 2;
if (numbers[m] > numbers[j]) i = m + 1;
else if (numbers[m] < numbers[j]) j = m;
else j--;
}
return numbers[i];
}
}
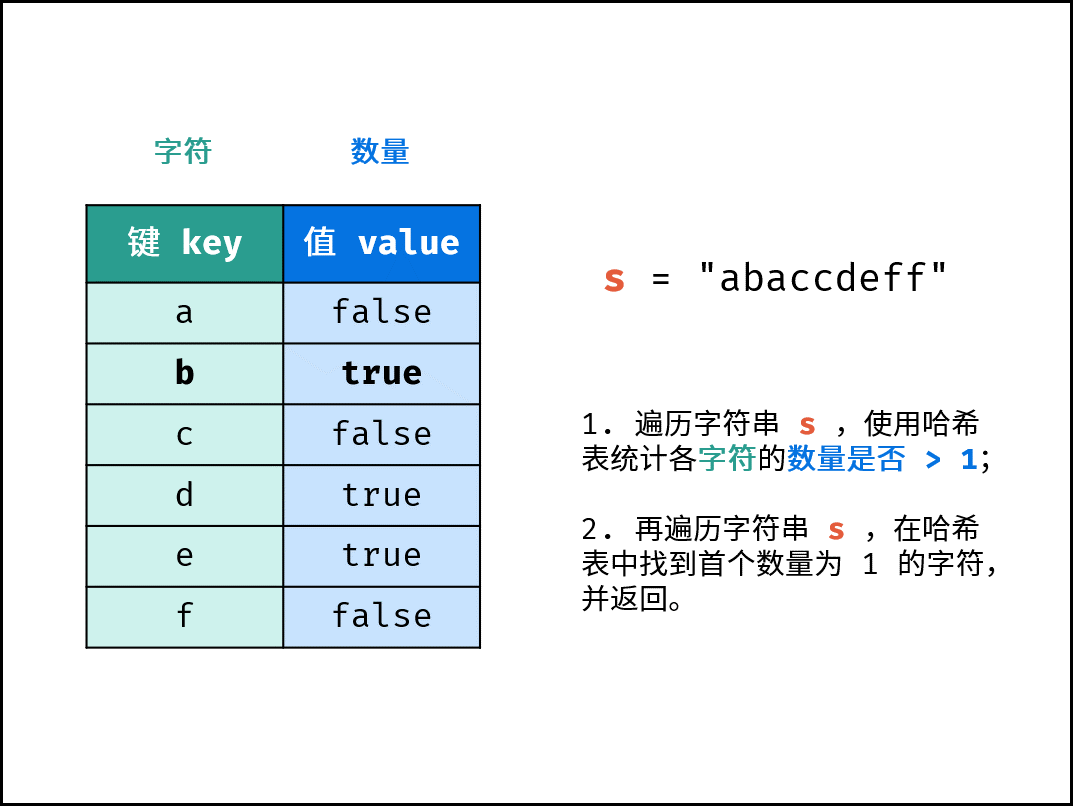
面试题50. 第一个只出现一次的字符(哈希表 / 有序哈希表,清晰图解)
在哈希表的基础上,有序哈希表中的键值对是 按照插入顺序排序 的。基于此,可通过遍历有序哈希表,实现搜索首个 “数量为 1 的字符”。
哈希表是 去重 的,即哈希表中键值对数量 ≤ 字符串 s 的长度。因此,相比于方法一,方法二减少了第二轮遍历的循环次数。当字符串很长(重复字符很多)时,方法二则效率更高。
复杂度分析:
时间和空间复杂度均与 “方法一” 相同,而具体分析:方法一 需遍历 s 两轮;方法二 遍历 s 一轮,遍历 dic 一轮( dic 的长度不大于 26 )。
class Solution {
public char firstUniqChar(String s) {
Map<Character, Boolean> dic = new LinkedHashMap<>();
char[] sc = s.toCharArray();
for(char c : sc)
dic.put(c, !dic.containsKey(c));
for(Map.Entry<Character, Boolean> d : dic.entrySet()){
if(d.getValue()) return d.getKey();
}
return ' ';
}
}
面试题32 - I. 从上到下打印二叉树(层序遍历 BFS ,清晰图解)
解题思路:
- 题目要求的二叉树的 从上至下 打印(即按层打印),又称为二叉树的 广度优先搜索(BFS)。
- BFS 通常借助 队列 的先入先出特性来实现。
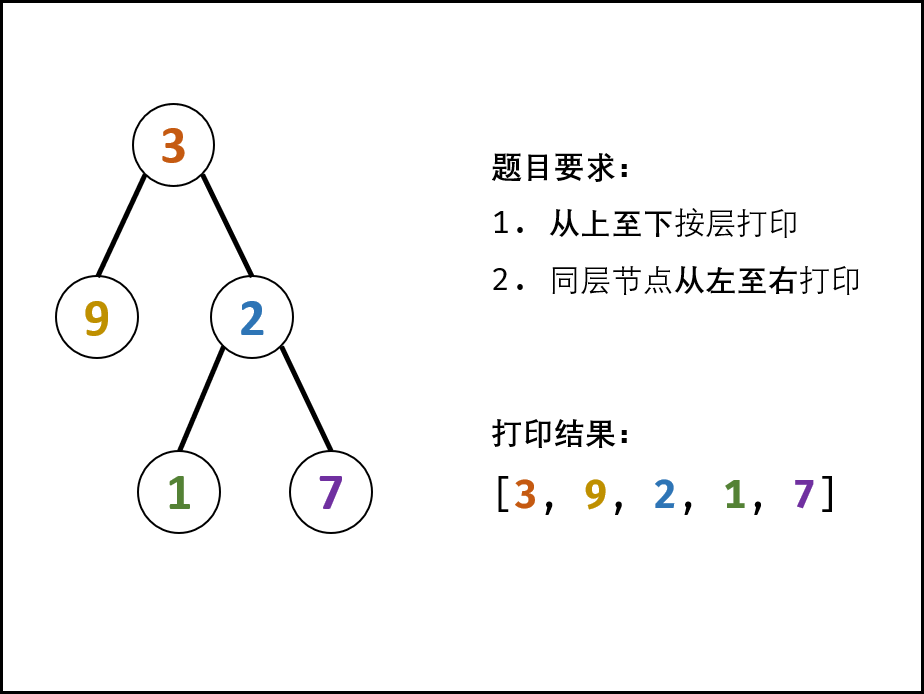
算法流程:
- 特例处理: 当树的根节点为空,则直接返回空列表 [] ;
- 初始化: 打印结果列表 res = [] ,包含根节点的队列 queue = [root] ;
- BFS 循环: 当队列 queue 为空时跳出;
-
出队: 队首元素出队,记为 node;
-
打印: 将 node.val 添加至列表 tmp 尾部;
-
添加子节点: 若 node 的左(右)子节点不为空,则将左(右)子节点加入队列 queue ;
4.返回值: 返回打印结果列表 res 即可。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int[] levelOrder(TreeNode root) {
if(root == null) return new int [0];
LinkedList<TreeNode> list = new LinkedList<>();
TreeNode node ;
ArrayList<Integer> arr = new ArrayList<>();
list.offer(root);
while(true)
{
for(int i = 0; i < list.size();i++)
{
node = list.poll();
arr.add(node.val);
TreeNode leftnode= node.left;
TreeNode rightnode = node.right;
if(leftnode!=null)
list.offer(leftnode);
if(rightnode!=null)
list.offer(rightnode);
}
if(list.isEmpty())break;
}
int [] res = new int[arr.size()];
for(int i = 0;i<arr.size();i++)
{
res[i] = arr.get(i);
}
return res;
}
}
面试题32 - II. 从上到下打印二叉树 II(层序遍历 BFS,清晰图解)
解题思路
I. 按层打印: 题目要求的二叉树的 从上至下 打印(即按层打印),又称为二叉树的 广度优先搜索(BFS)。BFS 通常借助 队列 的先入先出特性来实现。
II. 每层打印到一行: 将本层全部节点打印到一行,并将下一层全部节点加入队列,以此类推,即可分为多行打印。

算法流程:
-
特例处理: 当根节点为空,则返回空列表 [] ;
-
初始化: 打印结果列表 res = [] ,包含根节点的队列 queue = [root] ;
-
BFS 循环: 当队列 queue 为空时跳出;
-
新建一个临时列表
tmp,用于存储当前层打印结果; -
当前层打印循环: 循环次数为当前层节点数(即队列
queue长度);出队: 队首元素出队,记为 node;
打印: 将 node.val 添加至 tmp 尾部;
添加子节点: 若 node 的左(右)子节点不为空,则将左(右)子节点加入队列 queue ;
3.将当前层结果
tmp添加入res。 -
4.返回值: 返回打印结果列表 res 即可。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<List<Integer>>();
if(root==null) return res;
TreeNode node ;
LinkedList<TreeNode> queqe= new LinkedList<>();
queqe.offer(root);
while(true)
{
ArrayList <Integer> list = new ArrayList<>();
for(int i = queqe.size(); i>0 ;i--) // 将队列长度设置为初始值 防止size发生改变
{
node = queqe.poll();
list.add(node.val);
TreeNode left = node.left ;
TreeNode right = node.right;
if(left!=null)
queqe.offer(left);
if(right!= null)
queqe.offer(right);
}
res.add(list);
if(queqe.isEmpty())break;
}
return res;
}
}
面试题32 - III. 从上到下打印二叉树 III(层序遍历 BFS / 双端队列,清晰图解)
解题思路:
面试题32 - I. 从上到下打印二叉树 主要考察 树的按层打印 ;
面试题32 - II. 从上到下打印二叉树 II 额外要求 每一层打印到一行 ;
本题额外要求 打印顺序交替变化(建议按顺序做此三道题)。

层序遍历 + 双端队列
利用双端队列的两端皆可添加元素的特性,设打印列表(双端队列) tmp ,并规定:
- 奇数层 则添加至 tmp 尾部 ,
- 偶数层 则添加至 tmp 头部 。
算法流程:
-
特例处理: 当树的根节点为空,则直接返回空列表 [] ;
-
初始化: 打印结果空列表 res ,包含根节点的双端队列 deque ;
-
BFS 循环: 当 deque 为空时跳出;
-
新建列表
tmp,用于临时存储当前层打印结果; -
当前层打印循环: 循环次数为当前层节点数(即
deque长度); 出队: 队首元素出队,记为 node;
打印: 若为奇数层,将 node.val 添加至 tmp 尾部;否则,添加至 tmp 头部;
添加子节点: 若 node 的左(右)子节点不为空,则加入 deque ;
-
-
返回值: 返回打印结果列表
res即可;
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new LinkedList<List<Integer>>();
if(root==null) return res;
Deque<TreeNode> queue = new LinkedList<>();
queue.add(root);
boolean flag = true;
while(!queue.isEmpty())
{
LinkedList<Integer> list = new LinkedList<>();
for(int i = queue.size();i>0;i--){
TreeNode node = queue.poll();
if(flag)
list.add(node.val);
else
list.addFirst(node.val);
TreeNode left =node.left;
TreeNode right = node.right;
if(left!=null)
queue.add(left);
if(right!=null)
queue.add(right);
}
res.add(list);
flag = !flag;
}
return res;
}
}
递归详解
面试题26. 树的子结构(先序遍历 + 包含判断,清晰图解)
解题思路:
若树 B 是树 A 的子结构,则子结构的根节点可能为树 A 的任意一个节点。因此,判断树 B 是否是树 A 的子结构,需完成以下两步工作:
-
先序遍历树 A 中的每个节点An (对应函数 isSubStructure(A, B))
-
判断树 A 中 以An为根节点的子树 是否包含树 B 。(对应函数 recur(A, B))
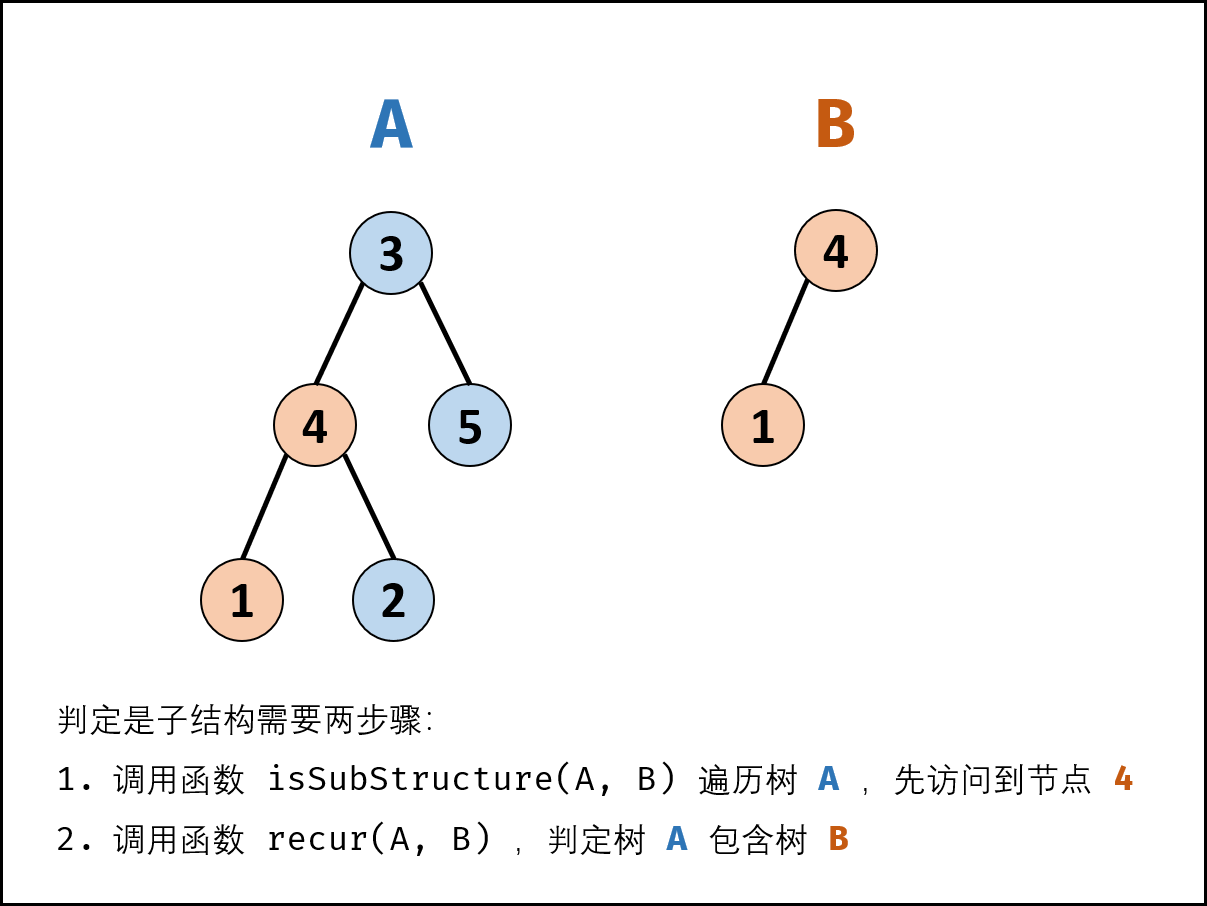
算法流程:
recur(A, B) 函数:
终止条件:
-
当节点 B 为空:说明树 B 已匹配完成(越过叶子节点),因此返回 true;
-
当节点 A 为空:说明已经越过树 A 叶子节点,即匹配失败,返回 false ;
-
当节点 A 和 B 的值不同:说明匹配失败,返回 false;
返回值:
- 判断 A 和 B 的左子节点是否相等,即 recur(A.left, B.left) ;
- 判断 A 和 B 的右子节点是否相等,即 recur(A.right, B.right) ;
isSubStructure(A, B) 函数:
-
特例处理: 当 树 A 为空 或 树 B 为空 时,直接返回 false;
-
返回值: 若树 B 是树 A 的子结构,则必满足以下三种情况之一,因此用或 || 连接;
1.以 节点 A 为根节点的子树 包含树 B ,对应 recur(A, B);
2.树 B 是 树 A 左子树 的子结构,对应 isSubStructure(A.left, B);
3.树 B 是 树 A 右子树 的子结构,对应 isSubStructure(A.right, B);
class Solution {
public boolean isSubStructure(TreeNode A, TreeNode B) {
if (B == null || A == null) {
return false;
}
if (A.val == B.val && (recur(A.left, B.left) && recur(A.right, B.right))) {
return true;
}
return isSubStructure(A.left, B) || isSubStructure(A.right, B);
}
private boolean recur(TreeNode root1, TreeNode root2) {
if (root2 == null) {
return true;
}
if (root1 == null) {
return false;
}
if (root1.val == root2.val) {
return recur(root1.left, root2.left) && recur(root1.right, root2.right);
} else {
return false;
}
}
}
剑指 Offer 27. 二叉树的镜像(递归 / 辅助栈,清晰图解)
二叉树镜像定义: 对于二叉树中任意节点 root ,设其左 / 右子节点分别为 left, right ;则在二叉树的镜像中的对应 root节点,其左 / 右子节点分别为 right, left
遍历二叉树的两种方式:递归 借助队列/栈
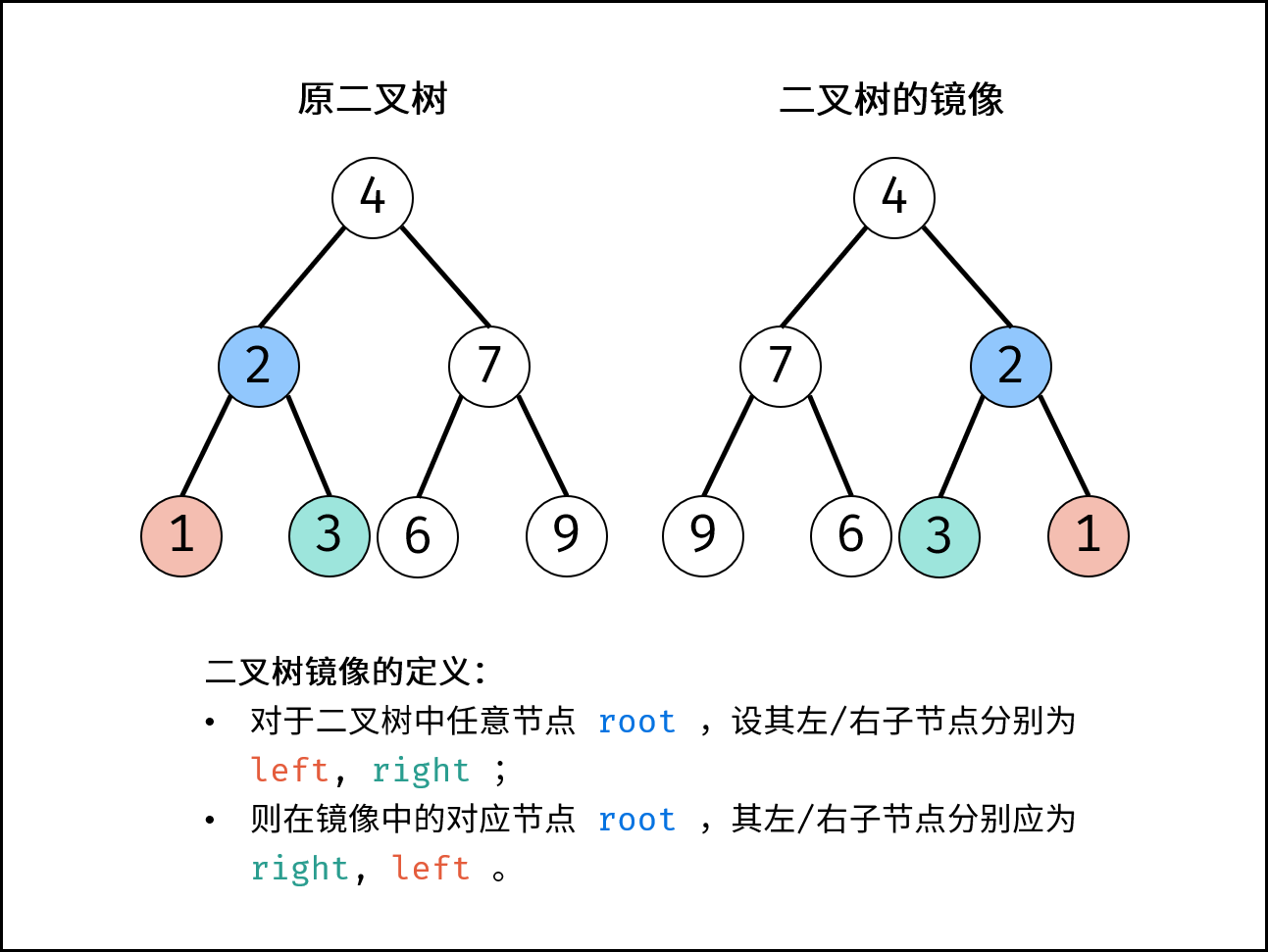
递归法
- 根据二叉树镜像的定义,考虑递归遍历(dfs)二叉树,交换每个节点的左 / 右子节点,即可生成二叉树的镜像。
递归解析:
终止条件: 当节点 root 为空时(即越过叶节点),则返回 null ;
递推工作:
- 初始化节点 tmp ,用于暂存 root的左子节点;
- 开启递归 右子节点 mirrorTree(root.right) ,并将返回值作为 root 的 左子节点 。
- 开启递归 左子节点 mirrorTree(tmp),并将返回值作为 root 的 右子节点 。
返回值: 返回当前节点 root ;
class Solution {
public TreeNode mirrorTree(TreeNode root) {
if(root == null) return null;
TreeNode tmp = root.left;
root.left = mirrorTree(root.right);
root.right = mirrorTree(tmp);
return root;
}
}
辅助栈(或队列)
- 利用栈(或队列)遍历树的所有节点 node,并交换每个 node 的左 / 右子节点。
算法流程:
- 特例处理: 当 root 为空时,直接返回 null ;
- 初始化: 栈(或队列),本文用栈,并加入根节点 root 。
- 循环交换: 当栈 stack 为空时跳出;
- 出栈: 记为 node ;
- 添加子节点: 将 node 左和右子节点入栈;
- 交换: 交换 node 的左 / 右子节点。
4.返回值: 返回根节点 root。
class Solution {
public TreeNode mirrorTree(TreeNode root) {
if(root == null) return null;
Stack<TreeNode> stack = new Stack<>() {{ add(root); }};
while(!stack.isEmpty()) {
TreeNode node = stack.pop();
if(node.left != null) stack.add(node.left);
if(node.right != null) stack.add(node.right);
TreeNode tmp = node.left;
node.left = node.right;
node.right = tmp;
}
return root;
}
}
广度优先搜索考虑队列 深度优先搜索考虑递归
面试题28. 对称的二叉树(递归,清晰图解)
解题思路:
对称二叉树定义: 对于树中 任意两个对称节点 L 和 R ,一定有:
- L.val = R.val:即此两对称节点值相等。
- L.left.val = R.right.val :即 LL 的 左子节点 和 R 的 右子节点 对称;
- L.right.val = R.left.val:即 LL 的 右子节点 和 R 的 左子节点 对称。
根据以上规律,考虑从顶至底递归,判断每对节点是否对称,从而判断树是否为对称二叉树。

算法流程:
isSymmetric(root) :
-
特例处理: 若根节点 root 为空,则直接返回 true。
-
返回值: 即 recur(root.left, root.right) ;
recur(L, R) :
终止条件:
- 当 L 和 R 同时越过叶节点: 此树从顶至底的节点都对称,因此返回 true ;
- 当 L 或 R 中只有一个越过叶节点: 此树不对称,因此返回 false ;
- 当节点 L 值 != 节点 R 值: 此树不对称,因此返回 false ;
递推工作:
- 判断两节点 L.left 和 R.right 是否对称,即 recur(L.left, R.right) ;
- 判断两节点 L.right和 R.left 是否对称,即 recur(L.right, R.left) ;
- 返回值: 两对节点都对称时,才是对称树,因此用与逻辑符 && 连接。
class Solution {
public boolean isSymmetric(TreeNode root) {
return root == null ? true : recur(root.left, root.right);
}
boolean recur(TreeNode L, TreeNode R) {
if(L == null && R == null) return true; //这个条件在前
if(L == null || R == null || L.val != R.val) return false;
return recur(L.left, R.right) && recur(L.right, R.left);
}
}
动态规划的三大步骤
动态规划,无非就是利用历史记录,来避免我们的重复计算。而这些历史记录,我们得需要一些变量来保存,一般是用一维数组或者二维数组来保存。下面我们先来讲下做动态规划题很重要的三个步骤,
如果你听不懂,也没关系,下面会有很多例题讲解,估计你就懂了。之所以不配合例题来讲这些步骤,也是为了怕你们脑袋乱了
第一步骤:定义数组元素的含义,上面说了,我们会用一个数组,来保存历史数组,假设用一维数组 dp[] 吧。这个时候有一个非常非常重要的点,就是规定你这个数组元素的含义,例如你的 dp[i] 是代表什么意思?
第二步骤:找出数组元素之间的关系式,我觉得动态规划,还是有一点类似于我们高中学习时的归纳法的,当我们要计算 dp[n] 时,是可以利用 dp[n-1],dp[n-2]……dp[1],来推出 dp[n] 的,也就是可以利用历史数据来推出新的元素值,所以我们要找出数组元素之间的关系式,例如 dp[n] = dp[n-1] + dp[n-2],这个就是他们的关系式了。而这一步,也是最难的一步,后面我会讲几种类型的题来说。
关系式的定义 一定包含原字符串/数组元素的变化 + dp[i-1] 类似的
学过动态规划的可能都经常听到最优子结构,把大的问题拆分成小的问题,说时候,最开始的时候,我是对最优子结构一梦懵逼的。估计你们也听多了,所以这一次,我将换一种形式来讲,不再是各种子问题,各种最优子结构。所以大佬可别喷我再乱讲,因为我说了,这是我自己平时做题的套路。
第三步骤:找出初始值。学过数学归纳法的都知道,虽然我们知道了数组元素之间的关系式,例如 dp[n] = dp[n-1] + dp[n-2],我们可以通过 dp[n-1] 和 dp[n-2] 来计算 dp[n],但是,我们得知道初始值啊,例如一直推下去的话,会由 dp[3] = dp[2] + dp[1]。而 dp[2] 和 dp[1] 是不能再分解的了,所以我们必须要能够直接获得 dp[2] 和 dp[1] 的值,而这,就是所谓的初始值。
由了初始值,并且有了数组元素之间的关系式,那么我们就可以得到 dp[n] 的值了,而 dp[n] 的含义是由你来定义的,你想求什么,就定义它是什么,这样,这道题也就解出来了。
面试题10- I. 斐波那契数列(动态规划,清晰图解)
动态规划:
原理: 以斐波那契数列性质 f(n + 1) = f(n) + f(n - 1) 为转移方程。
从计算效率、空间复杂度上看,动态规划是本题的最佳解法。
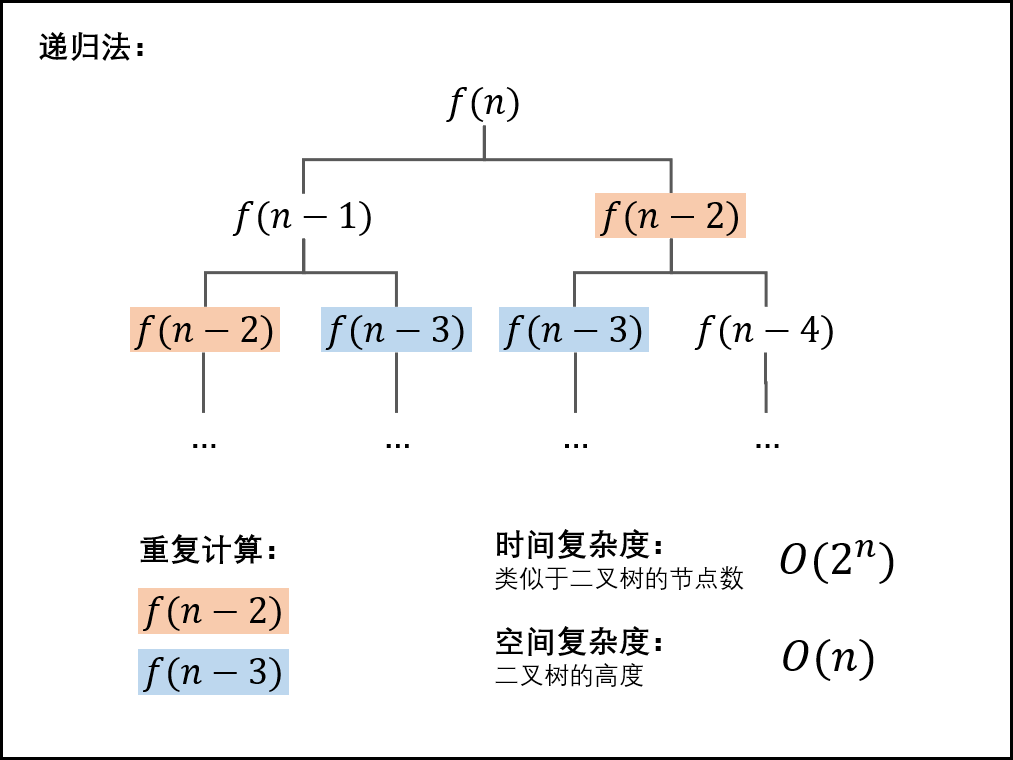
动态规划解析:
- 状态定义: 设 dp为一维数组,其中 dp[i] 的值代表 斐波那契数列第 i 个数字 。
- 转移方程: dp[i + 1] = dp[i] + dp[i - 1] ,即对应数列定义 f(n + 1) = f(n) + f(n - 1) ;
- 初始状态: dp[0] = 0, dp[1] = 1 ,即初始化前两个数字;
- 返回值: dp[n] ,即斐波那契数列的第 n 个数字。
class Solution {
public int fib(int n) {
if(n == 0) return 0;
int[] dp = new int[n + 1];
dp[0] = 0;
dp[1] = 1;
for(int i = 2; i <= n; i++){
dp[i] = dp[i-1] + dp[i-2];
dp[i] %= 1000000007;
}
return dp[n];
}
}
面试题10- II. 青蛙跳台阶问题(动态规划,清晰图解)
青蛙跳台阶问题和斐波那契相同
class Solution {
public int numWays(int n) {
if(n<2) return 1;
int [] dp = new int [n+1];
dp[0]=1;
dp[1]=1;
for(int i = 2 ;i<=n;i++){
dp[i]=dp[i-1]+dp[i-2];
dp[i]%=1000000007;
}
return dp[n];
}
}
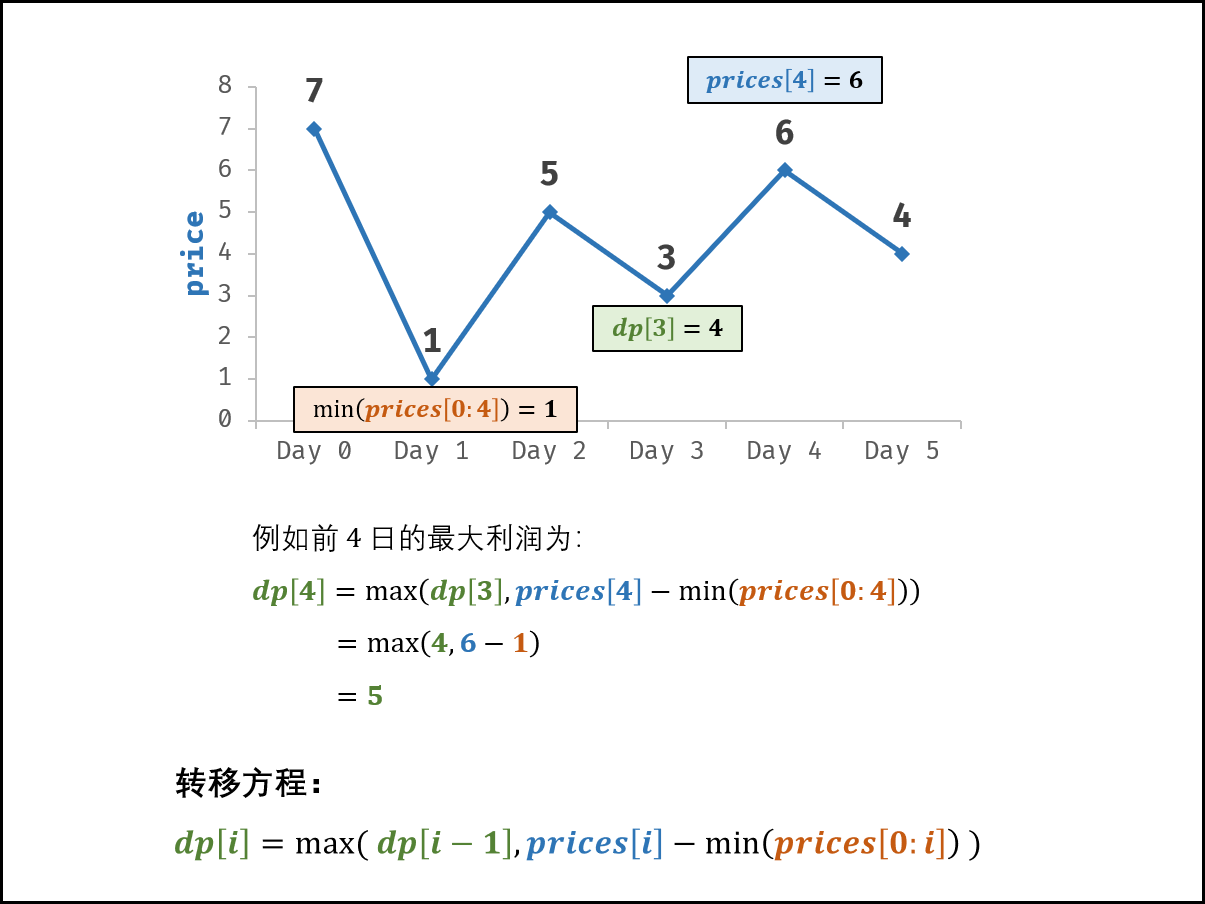
面试题63. 股票的最大利润(动态规划,清晰图解)
动态规划解析:
-
状态定义: 设动态规划列表 dp ,dp[i] 代表以 prices[i] 为结尾的子数组的最大利润(以下简称为 前 i 日的最大利润 )。
-
转移方程: 由于题目限定 “买卖该股票一次” ,因此前 i 日最大利润 dp[i] 等于前 i−1 日最大利润 dp[i−1] 和第 i 日卖出的最大利润中的最大值。
前 i 日最大利润 = max(前 (i-1) 日最大利润, 第 i 日价格 - 前 i 日最低价格)
dp[i] = max(dp[i - 1], prices[i] - min(prices[0:i]))
-
初始状态: dp[0] = 0 ,即首日利润为 0 ;
-
返回值: dp[n - 1],其中 n 为 dp 列表长度。
class Solution {
public int maxProfit(int[] prices) {
//定义数组元素的含义
//dp[i] 表示第i天的最大利润
int [] dp = new int [prices.length+1];
//设置初始状态
dp[0]=0;
int minprice = 999999;
int j = 0;
for(int i = 1 ; i<=prices.length&&j<prices.length; i++,j++){
//定义关系式
//第i天的最大利润 = max(前i日的最大利润,第i天的价格-前i日最低价)
dp[i] = Math.max(dp[i-1],(prices[j]-Math.min(minprice,prices[j])));
if(minprice>prices[j])
minprice = prices[j];
}
return dp[prices.length];
}
}
面试题42. 连续子数组的最大和(动态规划,清晰图解)
动态规划
1.状态,即子问题。
dp[i] 代表以元素 nums[i] 为结尾的连续子数组最大和。
2.转移策略,自带剪枝。
若 dp[i−1]≤0 ,说明 dp[i−1] 对 dp[i] 产生负贡献,即 dp[i−1]+nums[i] 还不如 nums[i] 本身大。
3.状态转移方程,根据前两步抽象而来。
- 当 dp[i−1]>0 时:执行 dp[i] = dp[i-1] + nums[i];
- 当 dp[i−1]≤0 时:执行 dp[i] = nums[i] ;
4.设计dp数组,保存子问题的解,避免重复计算
5.实现代码
class Solution {
public int maxSubArray(int[] nums) {
int res = nums[0];
for(int i = 1; i < nums.length; i++) {
nums[i] += Math.max(nums[i - 1], 0);
res = Math.max(res, nums[i]);
}
return res;
}
}
面试题47. 礼物的最大价值(动态规划,清晰图解)
解题思路:
题目说明:从棋盘的左上角开始拿格子里的礼物,并每次 向右 或者 向下 移动一格、直到到达棋盘的右下角。
根据题目说明,易得某单元格只可能从上边单元格或左边单元格到达。
设 f(i, j) 为从棋盘左上角走至单元格 (i ,j)的礼物最大累计价值,易得到以下递推关系:f(i,j) 等于 f(i,j−1) 和 f(i-1,j) 中的较大值加上当前单元格礼物价值 grid(i,j) 。
f(i,j)=max[f(i,j−1),f(i−1,j)]+grid(i,j)
因此,可用动态规划解决此问题,以上公式便为转移方程。
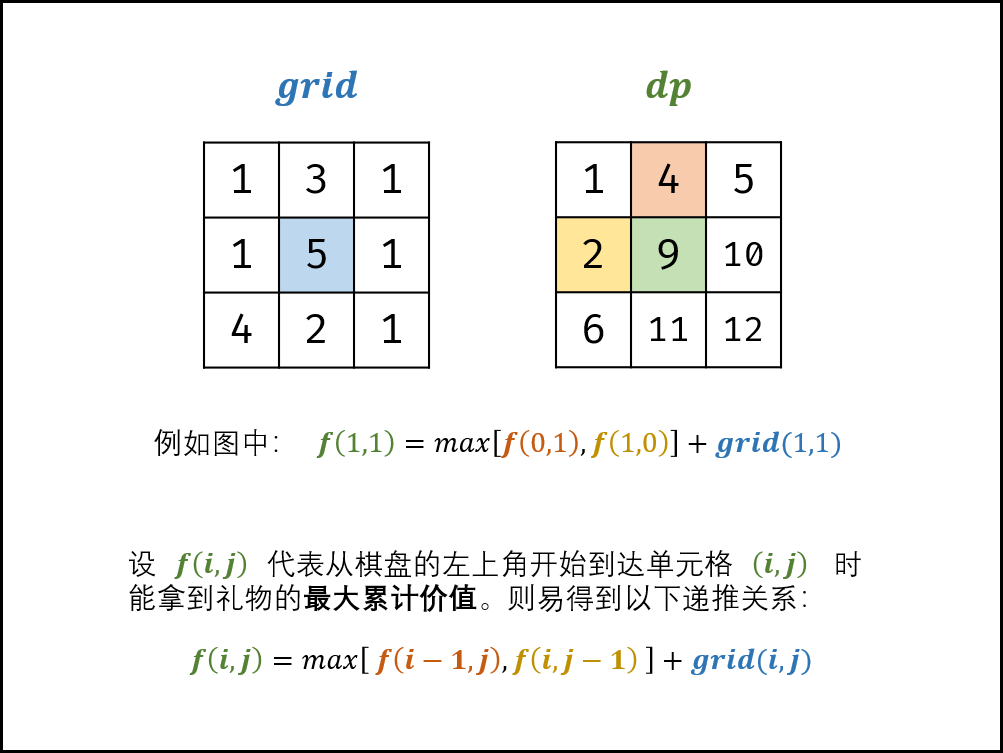
class Solution {
public int maxValue(int[][] grid) {
if(grid == null) return 0;
int m = grid.length;//2
int n = grid[0].length;//3
//定义数组元素的含义
//以二维数组的个元素作为i,j位置的礼物最大值 dp[i][j]
int [][] dp = new int [m][n];
//定义初始值
//i-1>=0 i>=1 即dp[0][j]要被赋值
//j-1>=0 j>=1 即dp[i][0]要被赋值
int tmp = 0;
for(int i = 0; i< grid[0].length; i++){
dp[0][i]=grid[0][i]+tmp;
tmp = dp[0][i];
}
tmp = 0;
for(int i = 0; i< grid.length; i++){
dp[i][0]=grid[i][0]+tmp;
tmp = dp[i][0];
}
//定义关系式
//要到达右下角的位置 那么 只有两条路可以走
//要么从grid[i][j-1]向右移动一位
//要么从grid[i-1][j]向下移动一位
//那么取最大值的话 就是 dp[i][j] = max(dp[i-1][j],dp[i][j-1]) + grid[i][j]
for(int i = 1;i<m;i++){
for(int j = 1;j<n;j++){
dp[i][j] = Math.max(dp[i-1][j],dp[i][j-1]) + grid[i][j];
}
}
return dp[m-1][n-1];
}
// 1 3 8
// 4 6 1
}
面试题46. 把数字翻译成字符串(动态规划,清晰图解)
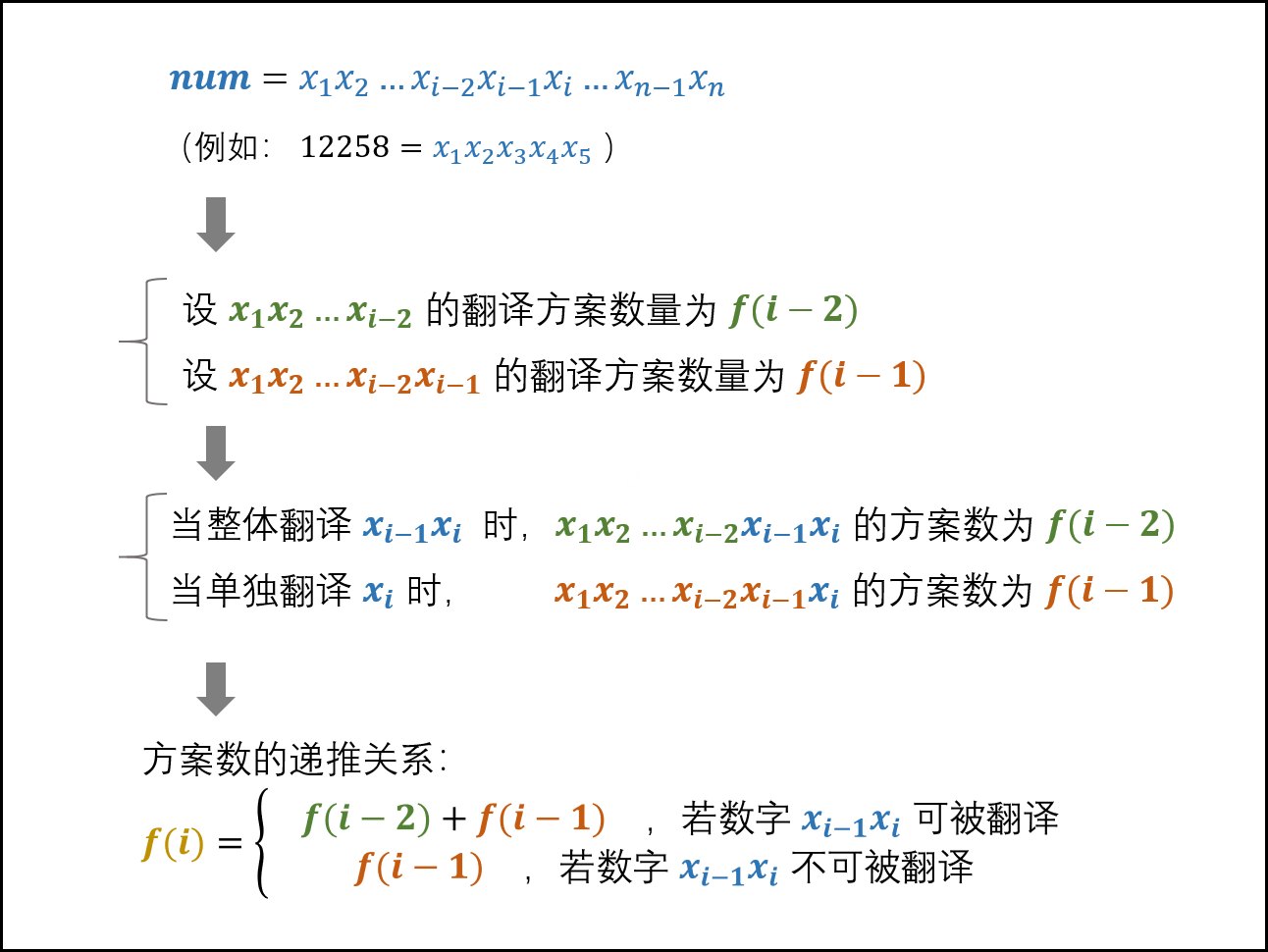
动态规划解析:
class Solution {
public int translateNum(int num) {
if(num<10) return 1;
String nums = num+"";
//定义dp[i]为 第i位的数字有多少种翻译方式
int [] dp = new int [nums.length()];
//初始化数组元素
dp[0]=1;
int fir = Integer.parseInt(nums.charAt(0)+"");
int sec = Integer.parseInt(nums.charAt(1)+"");
if((fir*10+sec)<26)
dp[1]=2;
else
dp[1]=1;
//定义关系式
//第i位的数字的翻译方式 = 第i-1位数字的翻译方式 + 引入i位字母以后前i位数字的翻译方式
//第i位的数字与第i-1位的数字能否组成翻译成字母?
//如果能 那么 i与i-1组成一对的情况下 +i-2位数字有多少种方式
//如果不能 那么引入i以后对前i位数字没有影响 则 + 0
for(int i = 2; i<nums.length(); i++){
int pre = Integer.parseInt(String.valueOf(nums.charAt(i-1)));
int cur = Integer.parseInt(String.valueOf(nums.charAt(i)));
if(pre != 0 &&(pre*10+cur)<26)
dp[i] = dp[i-1]+dp[i-2];
else
dp[i] = dp[i-1];
}
return dp[nums.length()-1];
}
}
https://leetcode-cn.com/problems/zui-chang-bu-han-zhong-fu-zi-fu-de-zi-zi-fu-chuan-lcof/solution/java-on-dong-tai-gui-hua-si-lu-qing-xi-z-w2ji/
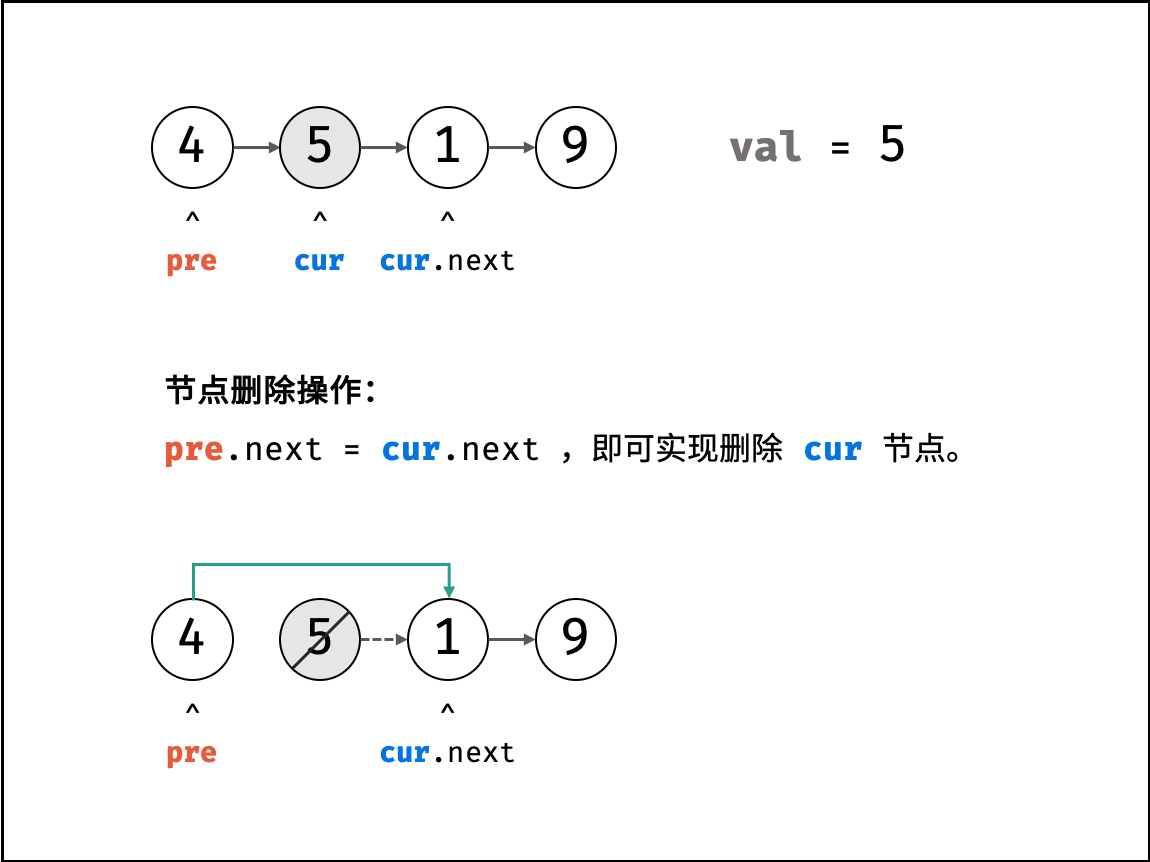
面试题18. 删除链表的节点(双指针,清晰图解)
解题思路:
定位节点: 遍历链表,直到 head.val == val 时跳出,即可定位目标节点。
修改引用: 设节点 cur 的前驱节点为 pre ,后继节点为 cur.next ;则执行 pre.next = cur.next ,即可实现删除 cur 节点。
算法流程:
- 特例处理: 当应删除头节点 head 时,直接返回 head.next 即可。
- 初始化: pre = head , cur = head.next 。
- 定位节点: 当 cur 为空 或 cur 节点值等于 val 时跳出。
- 保存当前节点索引,即 pre = cur 。
- 遍历下一节点,即 cur = cur.next 。
- 删除节点: 若 cur 指向某节点,则执行 pre.next = cur.next ;若 cur 指向 nullnull ,代表链表中不包含值为 val 的节点。
- 返回值: 返回链表头部节点 head 即可。
class Solution {
public ListNode deleteNode(ListNode head, int val) {
if(head.val == val) return head.next;
ListNode pre = head, cur = head.next;
while(cur != null && cur.val != val) {
pre = cur;
cur = cur.next;
}
if(cur != null) pre.next = cur.next;
return head;
}
}
面试题22. 链表中倒数第 k 个节点(双指针,清晰图解)
- 初始化: 前指针 former 、后指针 latter ,双指针都指向头节点 head 。
- 构建双指针距离: 前指针 former 先向前走 kk 步(结束后,双指针 former 和 latter 间相距 kk 步)。
- 双指针共同移动: 循环中,双指针 former 和 latter 每轮都向前走一步,直至 former 走过链表 尾节点 时跳出(跳出后, latter 与尾节点距离为 k-1k−1,即 latter 指向倒数第 kk 个节点)。
- 返回值: 返回 latter 即可。

class Solution {
public ListNode getKthFromEnd(ListNode head, int k) {
ListNode former = head, latter = head;
for(int i = 0; i < k; i++)
former = former.next;
while(former != null) {
former = former.next;
latter = latter.next;
}
return latter;
}
}
面试题25. 合并两个排序的链表(伪头节点,清晰图解)
解题思路:
根据题目描述, 链表l1和l2是 递增 的,因此容易想到使用双指针和遍历两链表,根据和l1.val和l2.val 的大小关系确定节点添加顺序,两节点指针交替前进,直至遍历完毕。
引入伪头节点: 由于初始状态合并链表中无节点,因此循环第一轮时无法将节点添加到合并链表中。解决方案:初始化一个辅助节点 dum 作为合并链表的伪头节点,将各节点添加至 dumdum 之后。

class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode dum = new ListNode(0), cur = dum;
while(l1 != null && l2 != null) {
if(l1.val < l2.val) {
cur.next = l1;
l1 = l1.next;
}
else {
cur.next = l2;
l2 = l2.next;
}
cur = cur.next;
}
cur.next = l1 != null ? l1 : l2;
return dum.next;
}
}
剑指 Offer 52. 两个链表的第一个公共节点(双指针,清晰图解)
设「第一个公共节点」为 node ,「链表 headA」的节点数量为 a ,「链表 headB」的节点数量为 b ,「两链表的公共尾部」的节点数量为 c ,则有:
-
头节点 headA 到 node 前,共有 a - c 个节点;
-
头节点 headB 到 node 前,共有 b - c 个节点;
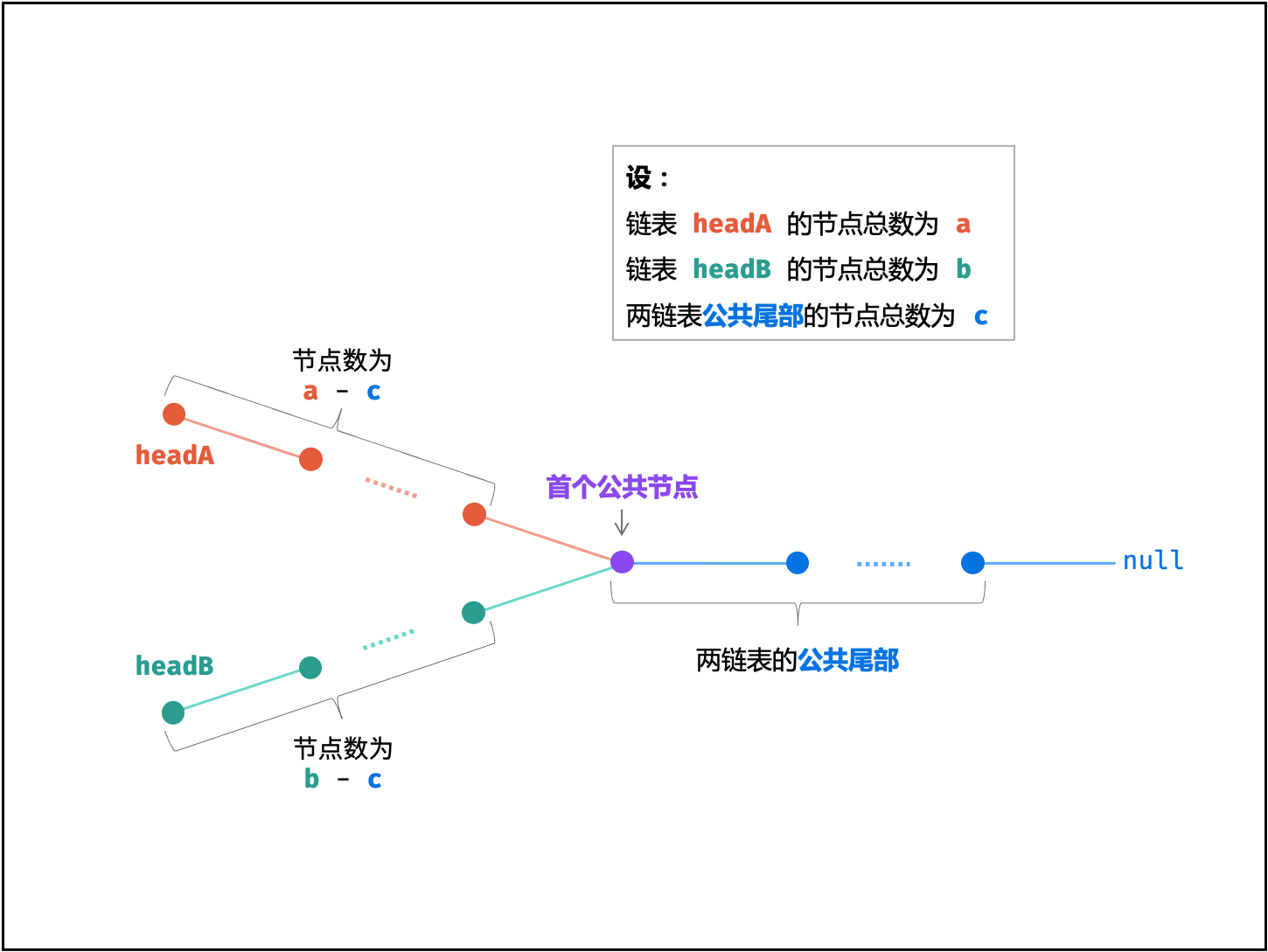
考虑构建两个节点指针 A , B 分别指向两链表头节点 headA , headB ,做如下操作:
-
指针 A 先遍历完链表 headA ,再开始遍历链表 headB ,当走到 node 时,共走步数为:a + (b - c)
-
指针 B 先遍历完链表 headB ,再开始遍历链表 headA ,当走到 node 时,共走步数为:b + (a - c)
如下式所示,此时指针 A , B 重合,并有两种情况:
a + (b - c) = b + (a - c)
若两链表 有 公共尾部 (即 c > 0 ) :指针 A , B 同时指向「第一个公共节点」node 。
若两链表 无 公共尾部 (即 c = 0 ) :指针 A , B 同时指向 null。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode A =headA,B =headB;
while(A!=B){
if(A!=null)
A=A.next;
else
A=headB;
if(B!=null)
B=B.next;
else
B=headA;
}
return A;
}
}














 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









