






各种机器学习问题
一、监督学习
概述
- 擅长在**“给定输入特征”**(记为x)的情况下预测标签(记为y)。每个“特征-标签”对(x, y)都称为一个样本(example)。有时,即便y是未知的,样本也可以指代输入特征。我们目标是生成一个模型,能将任何输入特征映射到标签(即预测)
- 例子:假设我们需要预测患者的心脏病是否会发作,则结果“心脏病发作”或“心脏病不发作”是样本的标签(y)。输入特征(x)可能是一些生命体征(心率、舒张压等)
- 在训练参数时,我们为模型提供了一个数据集,其中每个样本都有真实的标签(已知正确的结果)。从概率论的角度看,我们希望预测“估计给定输入特征的标签”的条件概率。即在给定一组特定的可用数据的情况下,估计未知事物的概率(如根据本月的财报数据,预测下个月股票的价格)
步骤
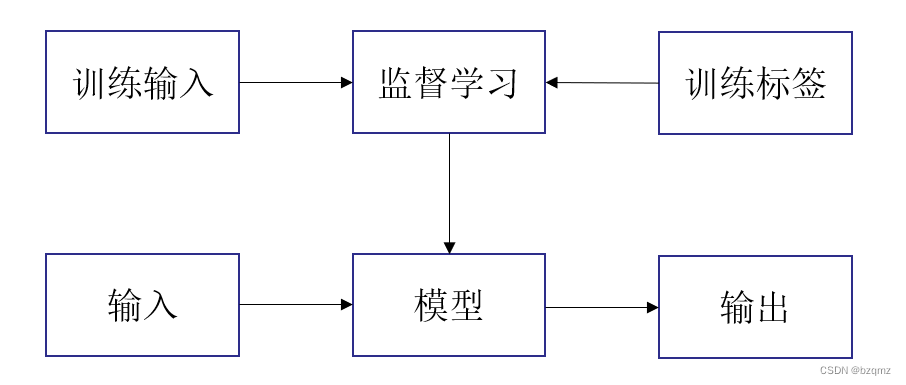
- 从已知大量数据样本中随机选取一个子集,为每个样本获取真实标签。有时这些样本已有标签;有时可能需要人工标记。(见概述中第1点)这些输入和相应的标签一起构成了训练数据集
- 选择有监督的学习算法,它将训练数据集作为输入,并输出一个“已完成学习的模型“
- 将之前没有见过的样本特征放到这个“已完成学习的模型”中,使用模型的输出作为相应标签的预测
过程:
回归(Regression)
- 回归是最简单的监督学习任务之一
- 判断回归问题的方法:有关**”有多少“**的问题很可能就是回归问题。如这个手术需要多少时间等
- 尝试学习最小化“预测值和实际标签值的差异”的模型,主要关注平方误差损失函数的最小化(将平方误差损失函数作为常见的回归问题的损失函数)
分类
- 虽然回归模型可以很好地解决“有多少”的问题,但是很多问题并非如此。如将手写字符映射到对应的已知字符上,手写数字可能有10类,标签被设置为数字0~9
- 上述这种“哪一个”的问题叫做分类(Classification)问题。分类问题希望模型能够预测样本属于哪个类别(Category,正式称为类(Class))。最简单的分类为二项分类(Binomial Classification)
- 回归是训练一个回归函数来输出一个数值;分类是训练一个分类器来输出预测的类别
- 模型怎么判断得出这种“是”或“不是”的硬分类预测呢?我们可以试着用概率语言来理解模型。给定一个样本特征,模型为每个可能的类分配一个概率。如猫狗分类的例子,分类器可能会输出图像是猫的概率为0.9(分类器90%确定图像描绘的是一只猫)。预测类别的概率的大小传达了一种模型的不确定性
- 与解决回归问题不同,分类问题的常见损失函数被称为交叉熵(CrossEntropy)
- 最常见的类别不一定是最终用于决策的类别。如分类器输出一种蘑菇无毒的概率为0.8,但我们也不会吃它(不值得冒20%的死亡风险)。即不确定风险的影响远远大于收益
标记问题
- 学习预测不相互排斥的类别的问题称为多标签分类(Multi‐label Classification)。如人们在技术博客上贴的标签,一篇博客可能会用到多个标签
搜索
- 在海量搜索结果中找到用户最需要的那部分
推荐系统
- 目标是向特定用户进行“个性化”推荐
序列学习
- 如果输入的样本之间没有任何关系,以上模型可能完美无缺。但是如果输入是连续的,模型可能就需要拥有“记忆”功能
- 如标记和解析、自动语音识别、文本到语言、机器翻译
二、无监督学习
- 上述所有的例子都与监督学习有关,即需要向模型提供巨大数据集:每个样本包含特征和相应标签值
- 这类数据中不含有“目标”的机器学习问题通常被为无监督学习(Unsupervised Learning)
分类
- 聚类(Clustering)问题:没有标签的情况下,我们是否能给数据分类呢
- 主成分分析(Principal Component Analysis)问题:我们能否找到少量的参数来准确地捕捉数据的线性相关属性?比如,一个球的运动轨迹可以用球的速度、直径和质量来描述
- 因果关系(Causality)和概率图模型(Probabilistic Graphical Models)问题:我们能否描述观察到的许多数据的根本原因
- 生成对抗性网络(Generative Adversarial Networks):为我们提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据
三、与环境互动
- 不管是监督学习还是无监督学习,我们都会预先获取大量数据,然后启动模型,不再与环境交互。这里所有学习都是在算法与环境断开后进行的,被称为离线学习(Offline Learning)
强化学习
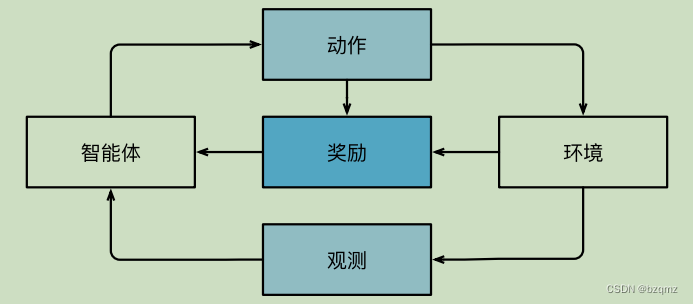
- 在强化学习问题中,智能体(Agent)在一系列的时间步骤上与环境交互。在每个特定时间点,智能体从环境接收一些观察(Observation),并且必须选择一个动作(Action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励(Reward)。此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推
- 强化学习的目标是产生一个好的策略(policy)。强化学习智能体选择的“动作”受策略控制,即一个从环境观察映射到行动的功能














 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









