







常常听到很多人说python这种语言的奇特之处就是你不用再自己造轮子,你只需要懂得车子的构架,就能完整的造出来一辆车子,在此次入坑百度飞桨之后我才深深的理解到这句话的涵义。于是此次想分享一下本人在使用百度飞桨以及打包自己使用百度飞桨中字符识别模块paddleocr的一些踩坑经验,由于公司电脑的一些局限性,导致在公司做的时候坑确实挺多的,不过在公司填完各种坑之后就很顺利在自己的电脑上配置好环境,以下就是我本次带来的百度飞桨环境配置和一键预测字符demo:
一、配置百度飞桨环境、安装paddlepaddle、paddlehub、paddleocr等环境。
二、使用百度飞桨中字符识别模块paddleocr进行字符的一键预测。
三、打包自己的一键预测ocr图形界面demo,测试是否打包成功。
一、配置百度飞桨环境
1、安装paddlepaddle
进入百度飞桨官网中选择自己的电脑环境进行安装
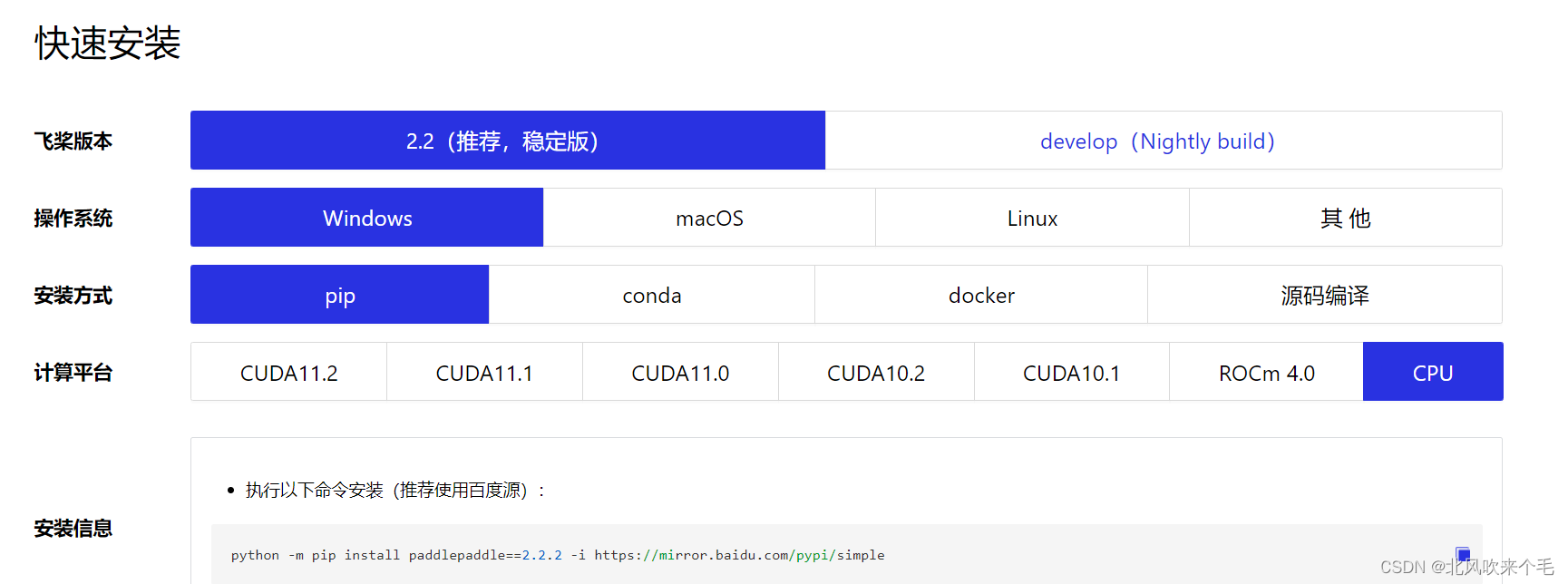
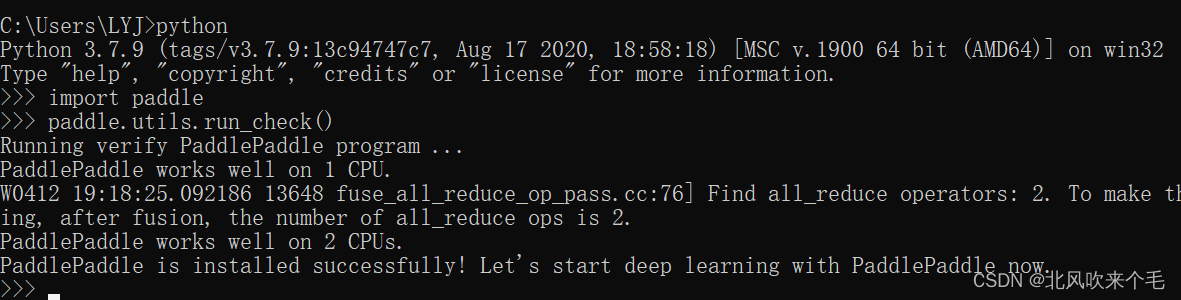
使用上面的命令进行安装paddlepaddle环境,接着在命令行中输入python进入python解释器,接着输入import paddle,再输入paddle.utils.run_check(),查看环境是否安装成功,若安装成功则显示如下:
2、安装paddlehub
安装paddlepaddle成功后可以直接使用命令pip install -i https://mirror.baidu.com/pypi/simple paddlehub 安装,接着在python解释器里导入paddlehub,输入padlehub.server_check(),安装成功信息如下:

3、安装paddleocr
使用 pip install -i https://mirror.baidu.com/pypi/simple paddleocr安装,一般情况下会报出这个错:
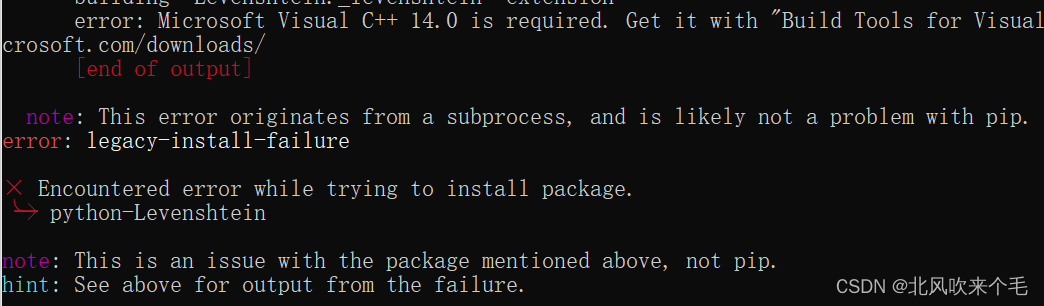
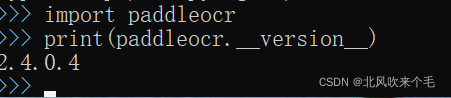
这是由于我们的电脑里缺少了VC++ 14.0这个东西,到下面链接去下载一个并安装就可以了。Download Visual Studio Tools - Install Free for Windows, Mac, LinuxDownload Visual Studio IDE or VS Code for free. Try out Visual Studio Professional or Enterprise editions on Windows, Mac. https://visualstudio.microsoft.com/downloads/ 安装好 VS Code 之后再使用上面命令进行安装,导入paddleocr模块,输入paddleocr.__version__,进行测试,若显示如下信息,则安装成功。
https://visualstudio.microsoft.com/downloads/ 安装好 VS Code 之后再使用上面命令进行安装,导入paddleocr模块,输入paddleocr.__version__,进行测试,若显示如下信息,则安装成功。
二、使用百度飞桨模块paddleocr进行字符一键预测
这里就使用paddleocr进行字符的一键预测,参考paddleocr官方文档,可以使用以下代码进行字符进行一键预测:
from paddleocr import *
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = 'E:/OCR/OCR/NG/E/3.bmp'
result = ocr.ocr(img_path, cls=True)
#for line in result:
#print(line)
text_ = [line[1][0] for line in result]
text_box_position = [line[0] for line in result]
confidence = [line[1][1] for line in result]
text = {}
text['text'] = text_[0]
text['text_box_position'] = text_box_position
text['confidence'] = confidence这里的lang='ch'代表的是识别中英文的模型,另外的模型还有en等。在此处我做了一个图形界面来识别字符,看看效果。
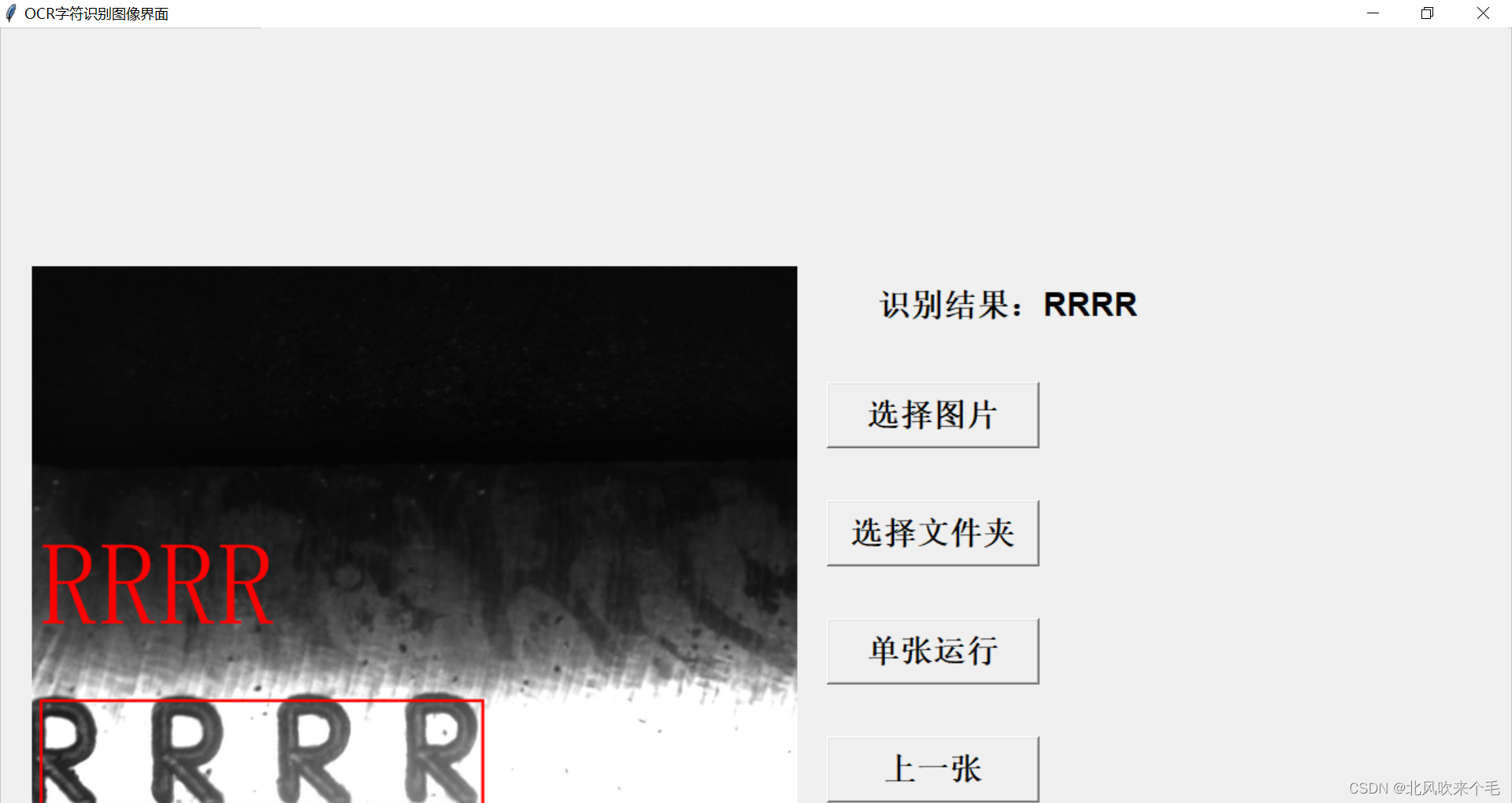

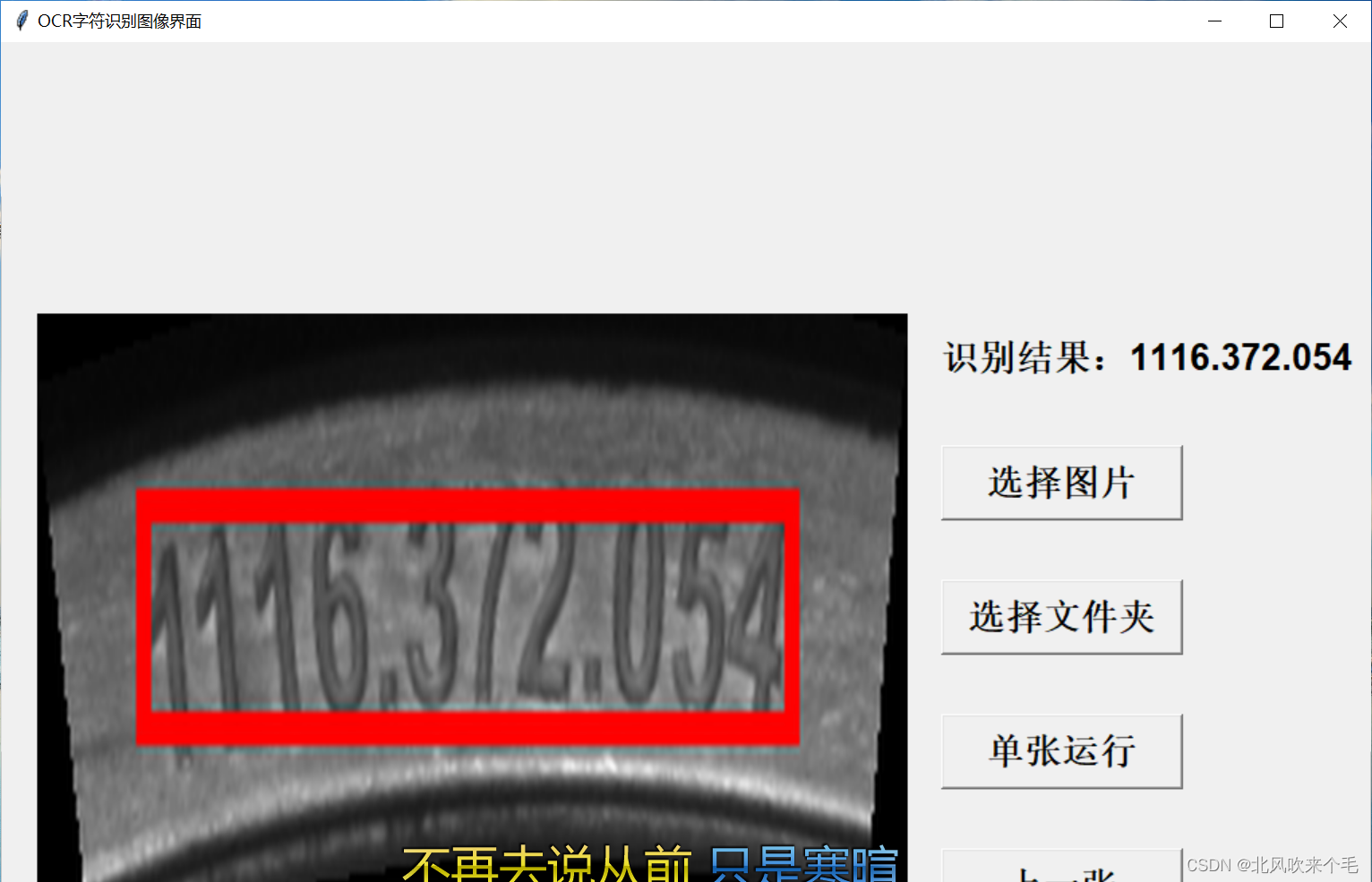
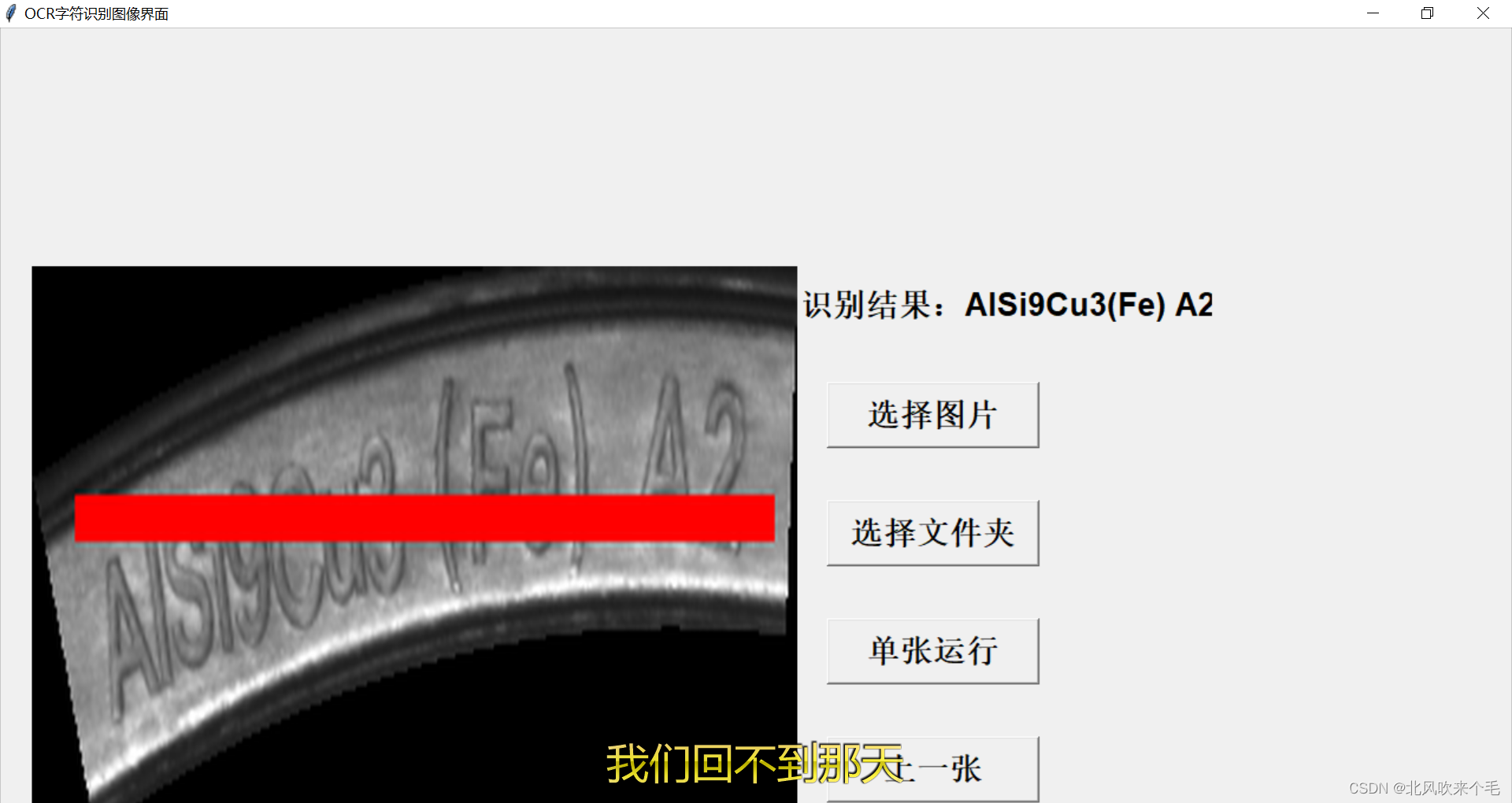
可见所有结果识别正确!此处本人由于使用的不是标准的图像,因此在画图像矩形框时某些矩形框的效果不好。
三、打包自己的一键预测ocr图形界面
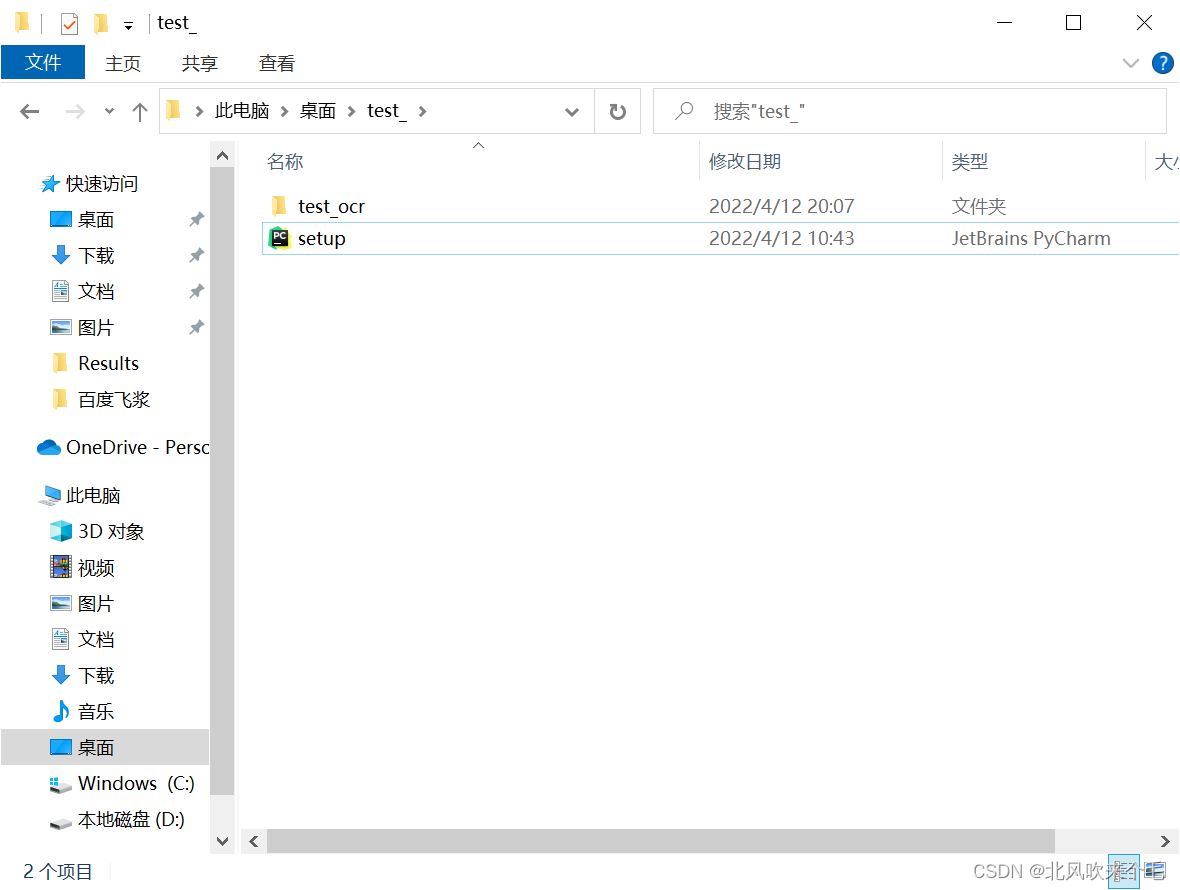
1、首先在包含你代码文件的同等级别目录下创建一个名为setup.py代码文件,并在源码文件同等目录下创建一个名为__init__代码文件,我的文件夹如下:
2、创建好之后在setup.py的内容如下:
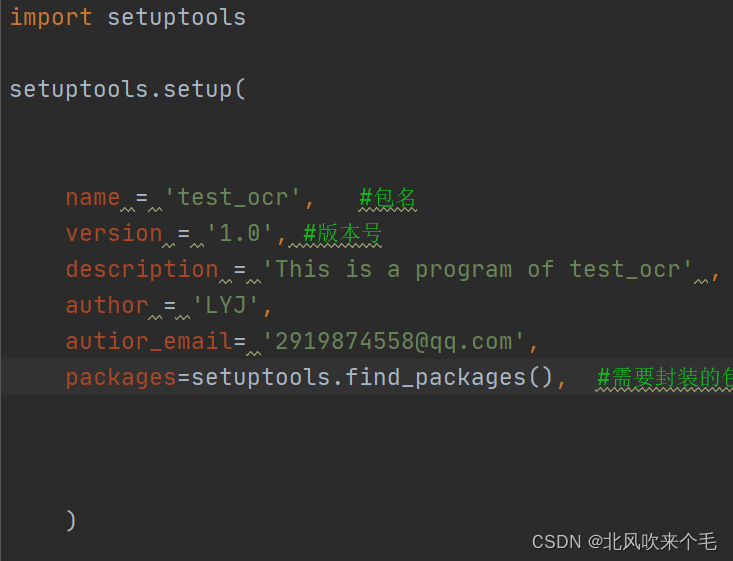
name为你导入库时的名字也就是包名,version为版本号,packages为你想要封装的包,这里是找到文件夹下的所有文件夹进行打包,以下是一些可有可无的选项:description:这个库的一些描述,author:作者,autior_email: 你的email。
3、__init__源代码文件的内容如下:
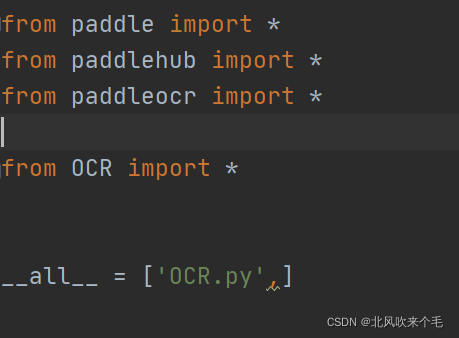
用from 包名 import * 导入你需要的库,否则后面导入自己打包好的包名将会报错。
使用from 源代码 import * 导入你自己写的源码里所有的函数,方便后面导入库使用,这里OCR和test是我自己写的源码。 __all__=['OCR.py'] 是你要打包的源代码文件。
4、使用命令行cd切换到你自己与setup.py同级别目录下,使用python setup.py bdist_wheel进行打包,如图:
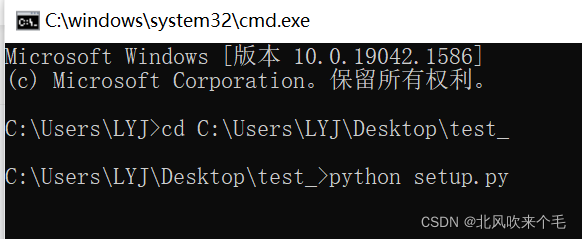
5、等待打包完成,你会发现在与setup.py同级别的目录下多了几个文件,其中dist中的文件就是我们打包成库的文件,使用命令行cd切换到dist文件夹中,使用pip install + 包名进行安装,安装成功显示如下:
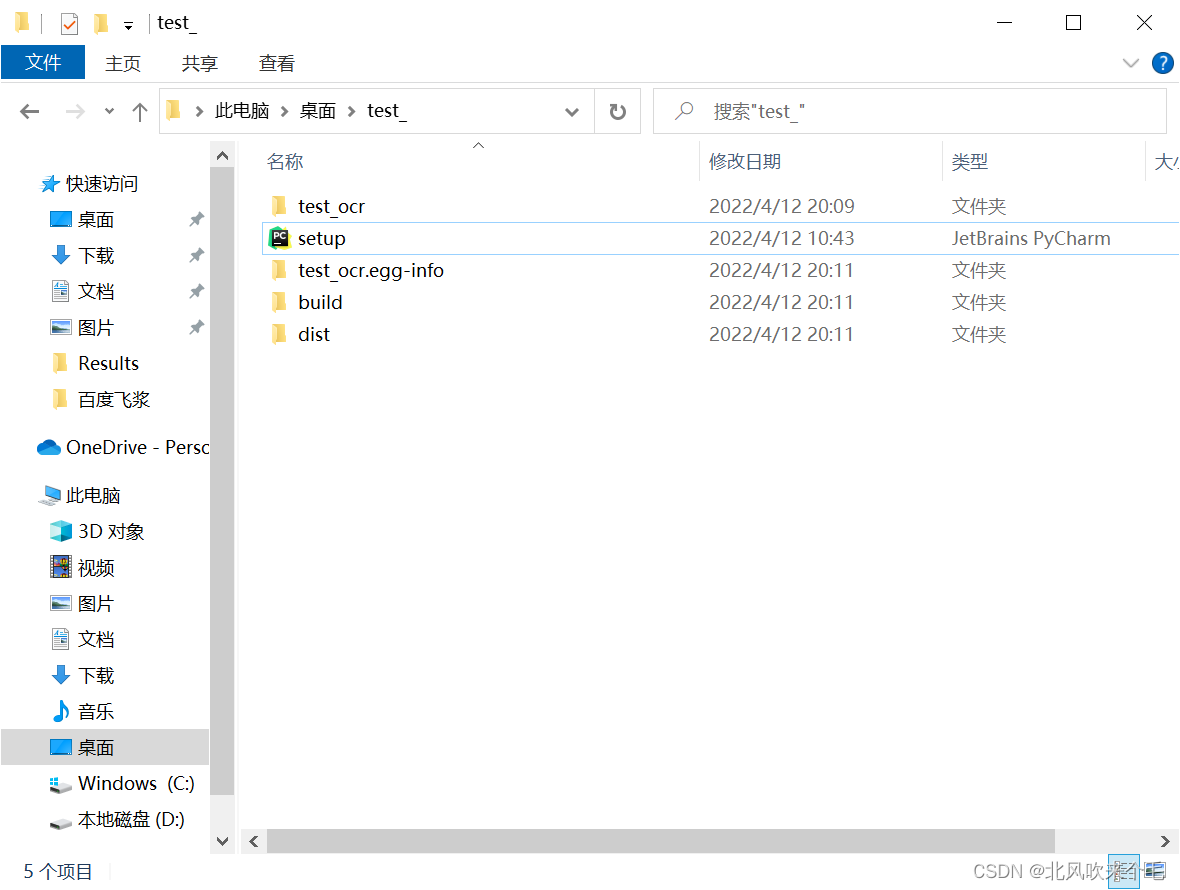

至此,自己写的源码打包成库完成!
最后进行自己打包的库测试,使用命令行切换到python 解释器,接着导入我前面打包文件的库名字test_ocr,并调用我的界面显示函数show()进行测试,测试成功界面如下,可以见到我们自己封装成的库文件已经导入成功:
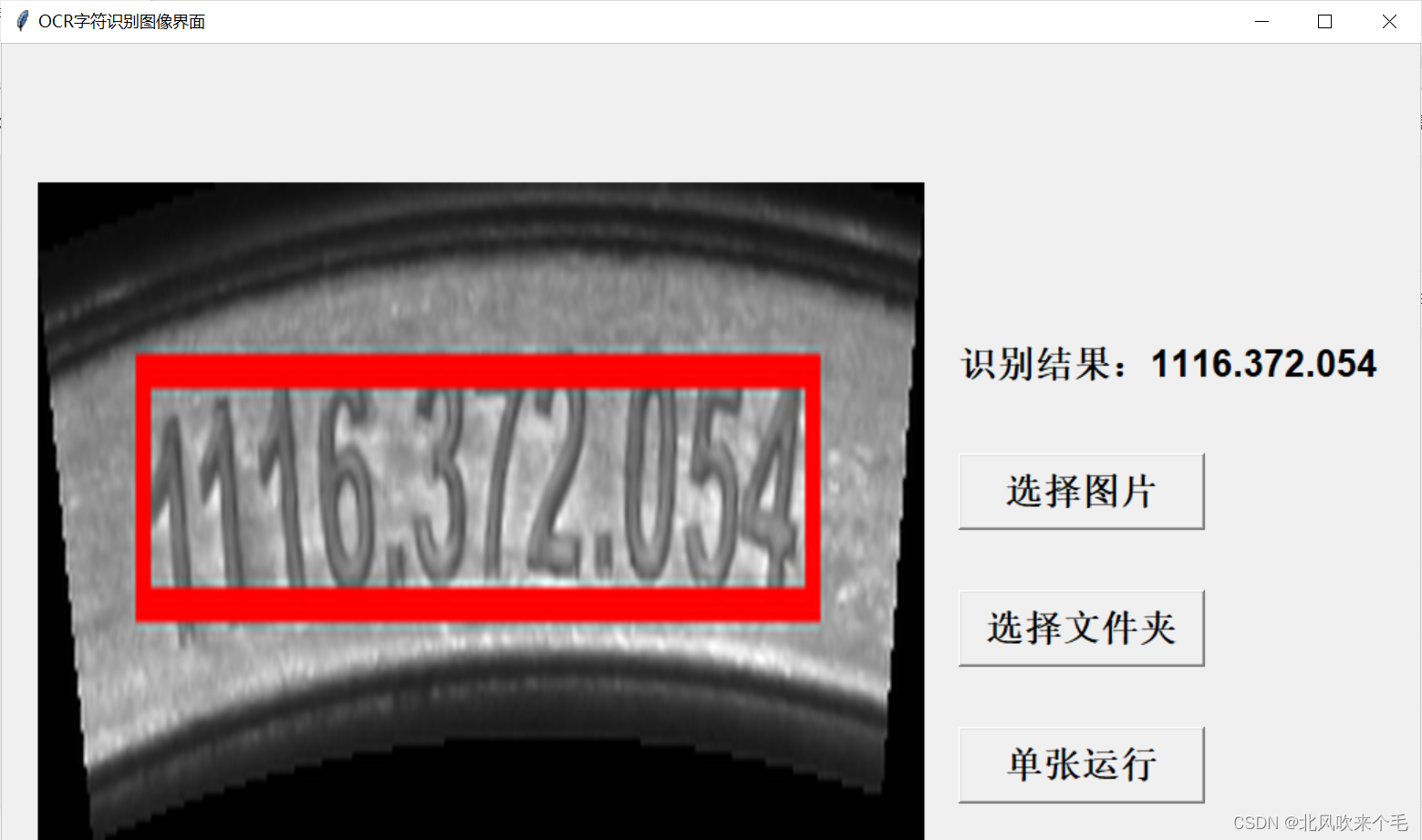
至此,调用百度飞桨识别字符的项目完成!后面本人还会带来使用百度飞桨自动标注器标注自己的数据集,接着调用百度飞桨训练自己数据集的教程,训练自己的数据集是为了更好的适应各种场景的字符识别,得到更好的字符识别结果。















 3503
3503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









