







语法分析(syntax analysis) 是编译程序的核心部分,其任务是检查词法分析器输出的单词序列是否是源语言中的句子
第4章 语法分析(自顶向下)
4.1 自上而下分析的问题:
- ① 回溯问题
分析过程中,当一个非终结符用某一个候选匹配成功时,这种匹配是暂时的;出错时,不得不进行“回溯”
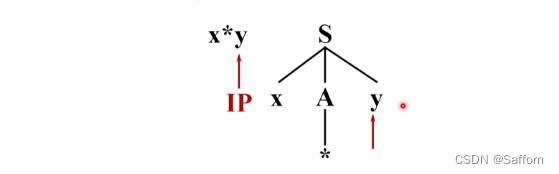
示例:对于具有两个候选式的A,第一次匹配时选择 A → ** 时,后续匹配失败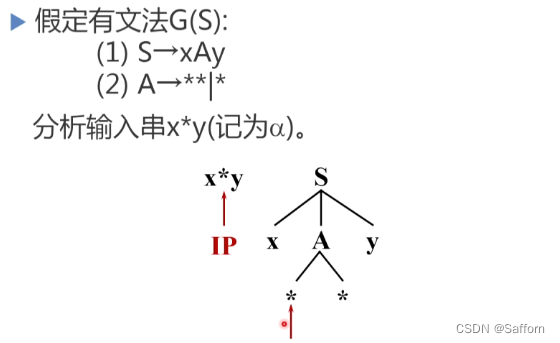
这时,回溯到对 A 的候选时,选择下一个候选式 A → *,继续匹配后续字符。最后成功。
- ② 文法左递归问题
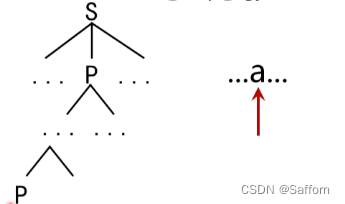
如果一个文法存在非终结符 P 使得 P ⇒ + P α P \Rightarrow^{+} P \alpha P⇒+Pα,则该文法含有左递归,导致分析器进入死循环
③ 二义性
4.2 消除左递归
- 消除直接左递归
- 问题:形如 P → P α ∣ β P\rightarrow P\alpha | \beta P→Pα∣β (其中 β \beta β不以 P P P开头)的文法,会变成 P ⇒ P α ⇒ P α α . . . ⇒ β α α . . . P\Rightarrow P\alpha \Rightarrow P\alpha\alpha ... \Rightarrow \beta\alpha\alpha... P⇒Pα⇒Pαα...⇒βαα...
- 思路:设计一种文法,也能达到上述文法的效果,而不存在左递归等死循环
- 解决:左递归变右递归。上述文法可以转换为 P → β P ′ P\rightarrow \beta P' P→βP′, P ′ → α P ′ ∣ ϵ P'\rightarrow \alpha P' | \epsilon P′→αP′∣ϵ
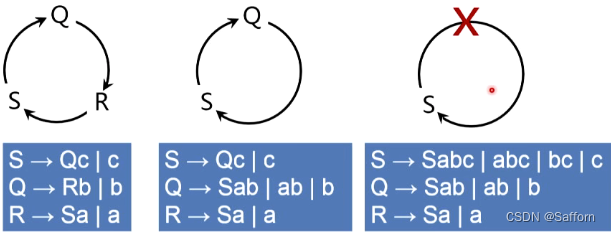
- 消除间接左递归
- 问题:问题:形如 S → Q c ∣ c S\rightarrow Qc| c S→Qc∣c, Q → R b ∣ b Q\rightarrow Rb|b Q→Rb∣b, R → S a ∣ a R\rightarrow Sa|a R→Sa∣a 的文法,会变成 S ⇒ Q c ⇒ R b c ⇒ S a b c . . . S\Rightarrow Qc\Rightarrow Rbc \Rightarrow Sabc... S⇒Qc⇒Rbc⇒Sabc...
- 解决的前提条件:① 不含以 ϵ \epsilon ϵ 为右部的产生式;② 不含回路 P ⇒ + P P\Rightarrow^+ P P⇒+P(非终结符推出本身,没有其他符号)
- 解决:将循环中的非终结符排序RQS,依次替换消除 或 消除直接左递归即可(排序不同,最终结果不同)
4.3 消除回溯 与 LL(1)文法
-
FIRST集合
- 定义
令G是一个不含左递归的文法,对G的所有非终结符的每个候选 α \alpha α 定义它的终结首符集FIRST( α \alpha α)为:
F I R S T ( α ) = { x ∣ α ⇒ ∗ x . . . , x ∈ V T } FIRST(\alpha) = \{x | \alpha\Rightarrow^{*} x..., x\in V_T\} FIRST(α)={x∣α⇒∗x...,x∈VT}
特别的,若 α ⇒ ∗ ϵ \alpha \Rightarrow^* \epsilon α⇒∗ϵ,则规定 ϵ ∈ F I R S T ( α ) \epsilon \in FIRST(\alpha) ϵ∈FIRST(α) - 理解: α \alpha α能推出的任意串,这个串如果以终结符x开头,则这个终结符 x 就在FIRST集合中;此外FIRST集合中可能存在空字 ϵ \epsilon ϵ
- 定义
-
提取公共左因子

- 目的:把每个非终结符(包括新定义的
A
′
A'
A′等)的FIRST集变成两两不相交,进而在匹配字符时,能更准确的匹配某一个候选继续进行匹配,从而“避免”回溯问题

- 缺点:提取公因子不能完全消除回溯,只能不断延后回溯的发生
- 目的:把每个非终结符(包括新定义的
A
′
A'
A′等)的FIRST集变成两两不相交,进而在匹配字符时,能更准确的匹配某一个候选继续进行匹配,从而“避免”回溯问题
-
FOLLOW集合
- 引入

在上面的例子中,我们希望获得一个句型: E ⇒ . . . ⇒ i T ′ E\Rightarrow...\Rightarrow iT' E⇒...⇒iT′+ . . . ... ...,其中的 + 号跟在 T ′ T' T′后面 - FOLLOW集合 定义
设 S 是文法G的开始符号,对G的所有非终结符A,A的FOLLOW集合为:
F O L L O W ( A ) = { x ∣ S ⇒ ∗ . . . A x . . . , x ∈ V T } FOLLOW(A) = \{x | S\Rightarrow^{*} ...Ax..., x\in V_T\} FOLLOW(A)={x∣S⇒∗...Ax...,x∈VT}
特别的,若 S ⇒ ∗ . . . A S\Rightarrow^{*} ...A S⇒∗...A,则规定 # ∈ F O L L O W ( A ) \in FOLLOW(A) ∈FOLLOW(A) - 理解: 在某个句型中,跟在非终结符A后面的的终结符 x 在A的FOLLOW集合中
- 引入
-
LL(1)文法

第一个 L:left to right,从左到右扫描输入串
第二个 L:leftmost derivation,最左推导
(1):表示每一步只需向前查看 1 个字符
- 构造每个文法符号的FIRST集合
对每一个 A ∈ V T ∪ V N A\in V_T\cup V_N A∈VT∪VN,连续使用下面的规则,直至每个集合FIRST不再增大为止:- 若 A ∈ V T A\in V_T A∈VT,A是终结符,则 F I R S T ( A ) = { A } FIRST(A) = \{A\} FIRST(A)={A}
- 若
A
∈
V
N
A\in V_N
A∈VN,A是非终结符,且有产生式
A
→
x
.
.
.
A\rightarrow x...
A→x...,其中
x
x
x 是一个终结符,则 把
x
x
x 加入到
F
I
R
S
T
(
A
)
FIRST(A)
FIRST(A)中;
若 A → ϵ A\rightarrow\epsilon A→ϵ 也是一条产生式,则把 ϵ \epsilon ϵ 也加入到 F I R S T ( A ) FIRST(A) FIRST(A)中 - 若 A → B . . . A\rightarrow B... A→B...是产生式,且 B B B是非终结符,则把 F I R S T ( B ) FIRST(B) FIRST(B)中的 非 ϵ \epsilon ϵ 元素都加到 F I R S T ( A ) FIRST(A) FIRST(A)中
- 若
A
→
B
1
B
2
.
.
.
B
i
.
.
.
B
k
A\rightarrow B_1B_2...B_i...B_k
A→B1B2...Bi...Bk是产生式,且
B
1
B
2
.
.
.
B
i
−
1
B
i
.
.
.
B
k
B_1B_2...B_{i-1}B_i...B_k
B1B2...Bi−1Bi...Bk都是非终结符
① 对于所有 j j j, 1 ≤ j ≤ i − 1 1≤j≤i-1 1≤j≤i−1, F I R S T ( B j ) FIRST(B_j) FIRST(Bj)都含有 ϵ \epsilon ϵ (即 B 1 . . . B i − 1 ⇒ ∗ ϵ B_1...B_{i-1}\Rightarrow^* \epsilon B1...Bi−1⇒∗ϵ),则把 F I R S T ( B i ) FIRST(B_i) FIRST(Bi)中的所有非 ϵ \epsilon ϵ 元素都加到 F I R S T ( A ) FIRST(A) FIRST(A) 中
② 若所有的 F I R S T ( B j ) FIRST(B_j) FIRST(Bj) 均含有 ϵ \epsilon ϵ, j = 1 , 2 , . . . , k j=1,2,...,k j=1,2,...,k,则把 ϵ \epsilon ϵ 加到 F I R S T ( A ) FIRST(A) FIRST(A) 中
- 构造任何符号串的FIRST集合
对文法G的任何符号串 α = X 1 X 2 . . . X n \alpha=X_1X_2...X_n α=X1X2...Xn 构造集合 F I R S T ( α ) FIRST(\alpha) FIRST(α)- 置 F I R S T ( α ) = F I R S T ( X 1 ) FIRST(\alpha) = FIRST(X_1) FIRST(α)=FIRST(X1) \ { ϵ } \{\epsilon\} {ϵ}
- 若对任何
1
≤
j
≤
i
−
1
,
ϵ
∈
F
I
R
S
T
(
X
j
)
1≤j≤i-1, \epsilon\in FIRST(X_j)
1≤j≤i−1,ϵ∈FIRST(Xj),则把
F
I
R
S
T
(
X
j
)
FIRST(X_j)
FIRST(Xj) \
{
ϵ
}
\{\epsilon\}
{ϵ} 加至
F
I
R
S
T
(
α
)
FIRST(\alpha)
FIRST(α)中
特别的,若所有的 F I R S T ( X j ) FIRST(X_j) FIRST(Xj) 都含有 ϵ , 1 ≤ j ≤ n \epsilon, 1≤j≤n ϵ,1≤j≤n,则把 ϵ \epsilon ϵ也加至 F I R S T ( α ) FIRST(\alpha) FIRST(α)中
若 α = ϵ \alpha = \epsilon α=ϵ,则 F I R S T ( α ) = { ϵ } FIRST(\alpha) = \{\epsilon\} FIRST(α)={ϵ}
- 构造每个 非终结符 的 FOLLOW集合
对于文法G的每个非终结符A构造FOLLOW(A),连续使用下面的规则,直至每个FOLLOW集都不再增大为止:- 对于文法的开始符号 S,置 # 于 FOLLOW(S)中
- 若 A → α B β A\rightarrow \alpha B\beta A→αBβ是一个产生式,则把 F I R S T ( β ) FIRST(\beta) FIRST(β) \ { ϵ } \{\epsilon\} {ϵ} 加至 F O L L O W ( B ) FOLLOW(B) FOLLOW(B)中
- 若 A → α B A\rightarrow \alpha B A→αB是一个产生式,或 A → α B β A\rightarrow \alpha B\beta A→αBβ 且 β ⇒ ∗ ϵ \beta\Rightarrow^{*} \epsilon β⇒∗ϵ (即 ϵ ∈ F I R S T ( β ) \epsilon\in FIRST(\beta) ϵ∈FIRST(β)),则把FOLLOW(A)加至FOLLOW(B)中
练习
- (4.2节 - 消除直接左递归)

答:对于 E 的左递归,可以变为 E → T E ′ E \rightarrow TE' E→TE′, E ′ → + T E ′ ∣ ϵ E' \rightarrow +TE' | \epsilon E′→+TE′∣ϵ;对于 F 的左递归,可以变为 T → F T ′ T \rightarrow FT' T→FT′, T ′ → ∗ F T ′ ∣ ϵ T' \rightarrow *FT' | \epsilon T′→∗FT′∣ϵ;F没有左递归。 - (4.2节 - 消除间接左递归)

答:第①步,对 非终结符 排序:B,A,S
第②步,遍历排好序的非终结符,进行 身后变量替换 或 消除直接左递归
i = 1,B → Sa | a 无直接左递归,也不存在需要替换的身前语法变量
i = 2,A → Bb | b,右侧的B在A前,替换B后得到 A → Sab | ab | b
i = 3,S → Ac | c,右侧的A在S前,替换A得到 S → Sabc | abc | bc | c,发现直接左递归
消除直接左递归,S → abcS’ | bcS’ | cS’,S’ → abcS’ | ϵ \epsilon ϵ
第③步,简化得到的文法(学校老师没说qwq )
第5章 语法分析(自下向上)
5.1 LR(0)文法
- 拓展文法:
G’(S’) = G(S) + { S’ → S } - 项目



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









