







本博客为OUC2022秋季软件工程第二次作业
一、视频学习心得及问题总结
1.1心得:
王梓萌:
当今时代人工智能领域的人才缺口是相当大的,且我国对于人工智能方面人才的培养也相当重视。人工智能是使一部机器像人一样进行感知、认知、决策、执行的人工程序或系统。
人工智能的三个发展阶段:计算智能,感知智能、认知智能
机器学习是基于数据的自动学习,减少了人工繁杂工作,但结果可能不易解释,提高了信息处理的效率且准确率高,并且由于机器学习是来源于真实数据,减少了人工规则主观性,可信度高。机器学习主要应用于计算机视觉、语音识别和自然语言处理
了解了深度学习的6个不能和m-p神经元及一些激活函数,简单了解了万有逼近定理,了解了网络的深度和宽度对函数复杂度的贡献是不同的,增加网络深度可以比增加宽度带来更强的网络表示能力,了解了受限玻耳兹曼机(RBM),其包含可见层和隐藏层,是生成式模型,而自编码器是判别式模型。
徐雅娟:
通过这两个视频,我们通过老师的讲解,了解了人工智能的几个发展阶段过程。人工智能的起源,人工智能的几个层面,人工智能与金融方面、机器人方面的结合应用。以及了解了机器学习,机器学习的模型(包括监督学习模型,无监督学习模型)、机器学习方法(参数模型和无参数模型),同时告诉我们机器学习不是万能的有很多局限性。深度学习应用了深度神经网络,随着各种硬件的支持算力的提高等等,发展的越来越快,应用领域已经遍及到我们周围。但是深度学习也有其不能地方,如算法输出不稳定容易被攻击,模型复杂难以纠错,模型层级符合程度高,参数不透明等等。第二个视频中,浅层神经网络:生物神经元到单层感知器,多层感知器,反向传播和梯度消失,深度学习是一种大型的神经网络,是一种重要的深度神经网络参数初始化和预训练方法。对于很多数据来说,仅使用两层神经网络的自编码器还不足以获取一种好的数据表示。我们可以使用更深层的神经网络,来获得更好的数据表示。增加深度更容易产生梯度消失,造成误差无法传播,并且多层网络容易陷入局部极值,难以找到更优解,难以训练,因此,在很长一段时间内,三层神经网络是主流,要想实现更深的神经网络,需要采取措施来抑制梯度消失,比如预训练、更改激活函数等
杨惠婷:
通过绪论的学习我了解到人工智能广阔的就业前景以及国家对这方面的重视,坚定了我要努力学习的信念。后面在老师的讲解下知道了机器慢慢变成人工智能的过程,模型的建立,算法的编写,机器的深度学习对我都是新奇领域。之后老师又对深度学习进行了更深入的展开,从浅层的神经网络到当前较成熟的人工智能的实现过程,让我知道要想学好人工智能可以从哪些方面入手,也了解到了行业方面很出名的例子。
严美美:
在绪论学习中,介绍了机器学习以及老师向我们系统的介绍了一些人工智能的相关发展历史,让我更深刻的理解了人工智能以及其发展前景及相关历史。还了解到了深度学习的思想就是堆叠多个层,也就是说这一层的输出作为下一层的输入,深度学习不仅是目前热度最高的人工智能研究方向,但是深度学习并不是万能的,有着一定的局限性。在学习深度学习概论中,知道浅层神经网络自然是由数个神经元构成的,对于一个简单的两层神经网络其结构如下图所示: 它包含了输入层(即X)、隐藏层、输出层,知道了更多相关知识。
林文浩:
- 视频一首先介绍了人工智能的发展情况,人工智能的发展阶段和人工智能与其他产业的结合,然后比较了专家系统和机器学习突出了机器学习的优势,然后介绍机器学习是什么和如何学习并介绍了几种机器学习的模型。然后比较了传统机器学习和深度学习,然后介绍了深度学习的发展阶段和行业著名人物。
- 视频二首先紧接上节课内容介绍了深度学习的不足,然后介绍了单层感知器多层感知器和刺激函数,然后介绍了神经网络每一层的作用,节点数与模型的线性转换能力有关,层数与模型的非线性转换能力有关,然后提出梯度消失问题,然后介绍了逐层预训练来应对梯度消失问题,然后介绍了实现逐层预训练的两种实现方法,用自编码器和用受限玻尔兹曼机。
1.2 问题总结:
1. 深层神经网络问题的梯度消失问题
2. 激活函数实验ReLU为什么会改善梯度消失
3. 深度学习强大的拟合能力需要在多大的样本数据量中体现
4. 怎样用RBM实现预训练模型
5. 机器人的行为和运动如何与代码产生联系 即关节的运动与弯曲如何做到量化并做到代码实现
6. 如今严峻的就业形势 人工智能还能同介绍的那么吃香吗
二、代码练习
2.1
一般定义数据使用torch.Tensor , tensor的意思是张量,是数字各种形式的总称
在PyTorch中,张量Tensor是最基础的运算单位,张量表示的是一个多维矩阵。PyTorch中的Tensor可以运行在GPU上。
可以是一个数
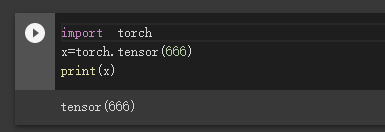
可以是一维数组
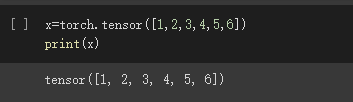
可以是二维数组
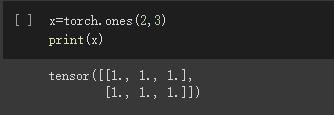
可以是任意维度的数组
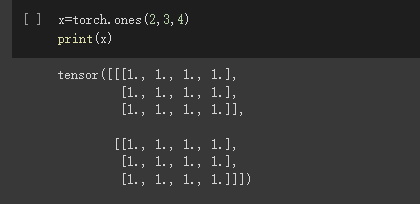
Tensor支持各种各样类型的数据,包括:
torch.float32, torch.float64, torch.float16, torch.uint8, torch.int8, torch.int16, torch.int32, torch.int64
创建Tensor有多种方法,包括:ones, zeros, eye, arange, linspace, rand, randn, normal, uniform, randperm等
创建一个空张量
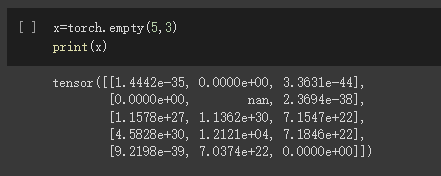
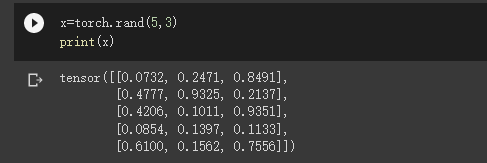
创建一个随机初始化的张量
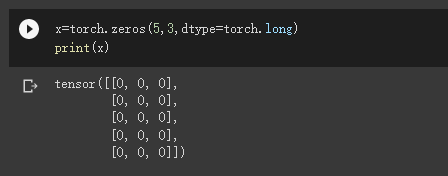
创建一个全0的张量,里面的数据类型为 long
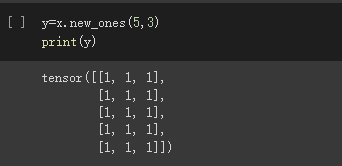
基于现有的tensor,创建一个新tensor,从而可以利用原有的tensor的dtype,device,size之类的属性信息
利用原来的tensor的大小,但是重新定义了dtype
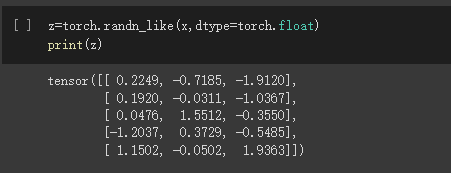
凡是用Tensor进行各种运算的,都是Function
最终,还是需要用Tensor来进行计算的,计算无非是
- 基本运算,加减乘除,求幂求余
- 布尔运算,大于小于,最大最小
- 线性运算,矩阵乘法,求模,求行列式
基本运算包括: abs/sqrt/div/exp/fmod/pow ,及一些三角函数 cos/ sin/ asin/ atan2/ cosh,及 ceil/round/floor/trunc 等具体在使用的时候可以百度一下
布尔运算包括: gt/lt/ge/le/eq/ne,topk, sort, max/min
线性计算包括: trace, diag, mm/bmm,t,dot/cross,inverse,svd 等
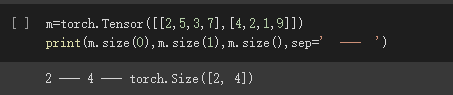
创建一个 2x4 的tensor

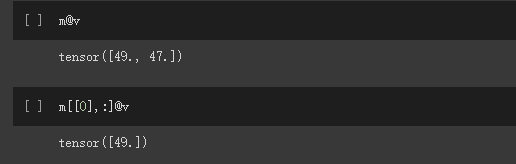
注意:若上一句代码中没有将v设置为float型而直接 m@v,代码会报错
原因:m,v类型不一致, m为float类型,v是long型
解决:将v设置为float类型即可
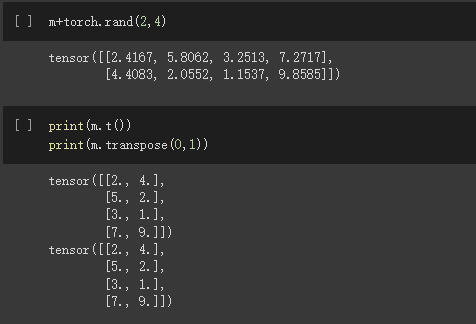
tensor @ tensor.T,可以实现张量的矩阵乘法
转置,且transpose也可以达到转置效果
 8
8
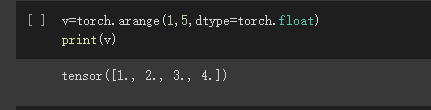
创建一个等步长的张量,起点为3,终点为8,步长为1/20

matlabplotlib 只能显示numpy类型的数据,下面展示了转换数据类型,然后显示 注意 randn 是生成均值为 0, 方差为 1 的随机数 下面是生成 1000 个随机数,并按照 100 个 bin 统计直方图
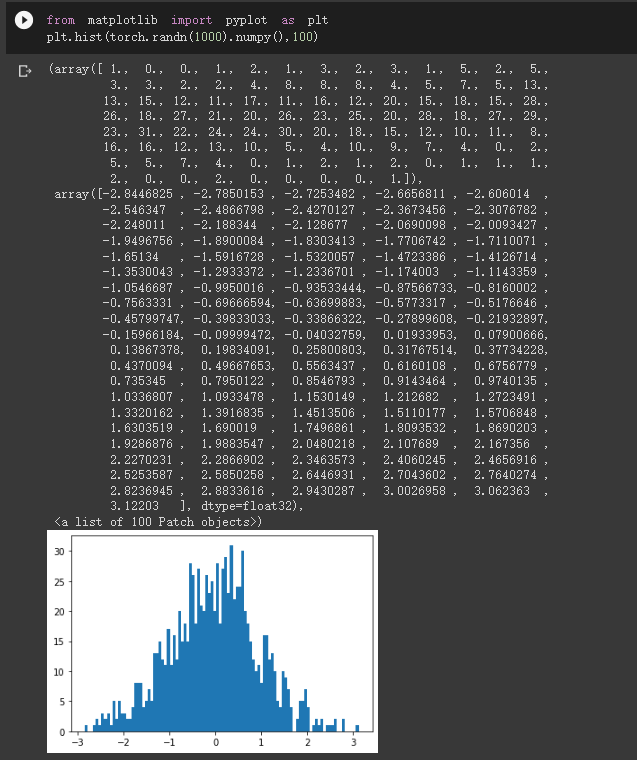
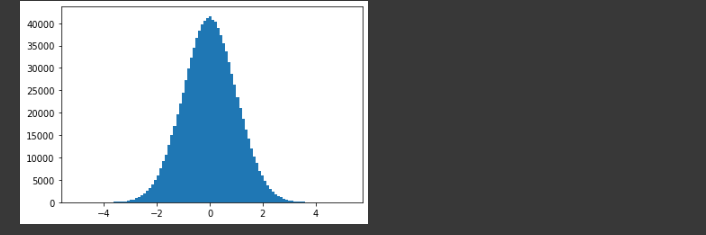
当数据非常非常多的时候,正态分布会体现的非常明显
![]()
在 0 方向拼接 (即在 Y 方各上拼接), 会得到 2x4 的矩阵
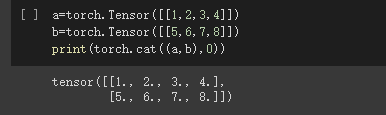
在 1 方向拼接 (即在 X 方各上拼接), 会得到 1x8 的矩阵

- plt.hist() 将统计值的范围分段,即将整个值的范围分成一系列间隔,然后计算每个间隔中有多少值。直方图也可以被归一化以显示“相对”频率。 然后,它显示了属于几个类别中的每个类别的占比,其高度总和等于1,
- torch.cat 在给定维度上对输入的张量序列seq 进行连接操作
2.2
2.2.1构建线性模型分类


运行结果:


2.2.2构建两层神经网络分类
线性整流函数(ReLU). 线性整流函数 (Rectified Linear Unit, ReLU ),又称 修正线性单元, 是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数
对于线性函数而言,ReLU的表达能力更强,尤其体现在深度网络中;而对于非线性函数而言,ReLU由于非负区间的梯度为常数,因此不存在梯度消失问题(Vanishing Gradient Problem),使得模型的收敛速度维持在一个稳定状态
运行结果:
![]()

两个分类对比之下,在两层神经网络里加入 ReLU 激活函数以后,分类的准确率得到了显著提高。















 2184
2184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









