






第二次作业:深度学习基础
1.视频学习心得和总结
关子琦
绪论部分首先讲述了人工智能的起源和发展以及现况,将人工智能分为了三个层面。然后讲解了机器学习的定义,即计算机系统能够利用经验提高自身的性能,将机器学习分为三个主要部分:模型、策略和算法,讲解了半监督学习、监督学习、无监督学习和强化学习的特征。比较了参数模型和无参数模型。介绍了传统机器学习和深度学习的区别,最后介绍了现在深度学习中的一些热门问题。通过学习视频,我对机器学习和深度学习的概念有了初步的了解,对比于机器学习,深度学习的学习能力和泛化能力要更加强大,是目前的新兴技术之一。
深度学习概论部分首先介绍了深度学习的一些应用场景,说明了深度学习的“能”与“不能”,深度学习的不能表现在算法输出不稳定,容易被攻击;模型复杂度高,难以纠错和调试;模型层级复合程度高,参数不透明;端到端训练方式对数据依赖性强,模型增量性差;专注直观感知类问题,对开放性推理问题无能为力;人类知识无法有效引入监督,机器偏见难以避免等方面。然后视频介绍了神经网络的一些基本概念,如生物神经元、M-P神经元、激活函数、单层感知器、多层感知器。然后介绍了神经网络每一层的作用,介绍了万有逼近定理,说明了误差反向传播的概念以及梯度下降和梯度消失的问题。最后介绍了神经网络的常用算法比如逐层预训练、自编码器、受限兹曼机等,给出了解决梯度消失的方案。通过视频的学习,我了解到神经网络学习是一个复杂的过程,要在学习中寻找最优参数,实现梯度下降法,同时解决梯度消失的问题。神经网络学习中存在许多高级算法和概念,需要认真学习。
别鹏飞
深度学习是一种基于神经网络的机器学习。
神经网络模型计算中会涉及大量的向量、矩阵和张量计算。
最重要的部分是怎么去设计神经网络的模型,比如隐层的层数,参数的个数,计算的方式(例如卷积线性变换)以及激活函数的选择,在这里面还会涉及到很多最优化理论的知识。
许胤韬
神经网络是一种仿生模型。神经元--可以接收、发射脉冲信号的细胞。树突--接收其他神经元的脉冲信号。轴突-将神经元的输出脉冲传递给其他神经元。突触--发生信息的交换传递。在生物神经网络中,每个神经元与其他神经元相连,当它“兴奋”时,就会向相连的神经元发送化学物质,从而改变神经元内的点位,如果某个神经元的电位超过了一个阈值,那么它就会被激活,即“兴奋”起来,向其他神经元发送化学物质。
玻尔兹曼机是一大类的神经网络模型,但是在实际应用中使用最多的则是受限玻尔兹曼机(RBM)。受限玻尔兹曼机(RBM)是一个随机神经网络(即当网络的神经元节点被激活时会有随机行为,随机取值)。它包含一层可视层和一层隐藏层。在同一层的神经元之间是相互独立的,而在不同的网络层之间的神经元是相互连接的(双向连接)。在网络进行训练以及使用时信息会在两个方向上流动,而且两个方向上的权值是相同的。但是偏置值是不同的(偏置值的个数是和神经元的个数相同的)。
吕思毅
1.知识工程基于手工设计规则建立专家系统(~80年代末期),结果容易解释,系统构建费时费力,依赖专家主观经验,难以保证一致性和准确性。
2.机器学习基于数据自动学习(90年代中期~),减少人工繁杂工作,但结果可能不易解释,提高信息处理的效率,且准确率较高,来源于真实数据,减少人工规则主观性,可信度高。
3.根据是否应用了神经网络可将机器学习分为传统机器学习和神经网络,若应用了深度神经网络,则称为深度学习。
4.深度学习的“能”:学习能力强,能够作曲、下棋、写诗、生成艺术画。
5.深度学习的“不能”:算法输出不稳定,容易被“攻击”;模型复杂度高,难以纠错和调试;模型层级复合程度高,参数不透明;端到端训练方式对数据依赖性强,模型增量性差;专注直观感知类问题,对开放性推理问题无能为力;人类知识无法有效引入进行监督,机器偏见难以避免。
李泊林
在学习完了视频后,我更觉得人工智能是神秘的科学,也是一种迷人的学科。在视屏中我了解了人工智能当前的发展情况,和其他产业的巧妙结合,国家对其的重视和当下的发展情况和对其站展望的美好蓝图等。多重比较之下,我觉得当下应用的深度学习是一种多么玄妙美好又效率十足的产物,应用广泛且优点多多,但是当下我们还有很长一段路要走,这一切还在不断的学习发展当中。随着学习的深入,了解到感知器的刺激函数,万有逼近定理,神经网络各层的作用,误差反向传播,梯度下降和消失等后,我不禁被数学与科学的巧妙结合所折服,但是了解越深,我的问题也越多,一个又一个为什么不断在心中重复。之后介绍逐层预训练,自编码器和受限玻尔兹曼机等内容的时候,我更是觉得心中有层层迷雾,但又惊叹于这美妙的科学。学习完成后,我深感这门学科的神秘,但也愈加觉得迷人,在日后人工智能这一科学必定有大作为,也希望自己可以为他的发展尽一份力。
小组在视频学习中遇到的问题
1.参数学习的误差反向传播学的不是很明白
2.没太搞明白传统机器学习和深度学习的差别
3.人工智能作画是否运用了NLP的知识
4.对三层前馈神经网络的BP算法理解不是很清楚
5.对受限玻尔兹曼机的理解不是很到位
6.Relu、leakrelu、elu的区别
代码练习
2.1 pytorch 基础练习
1.定义数据
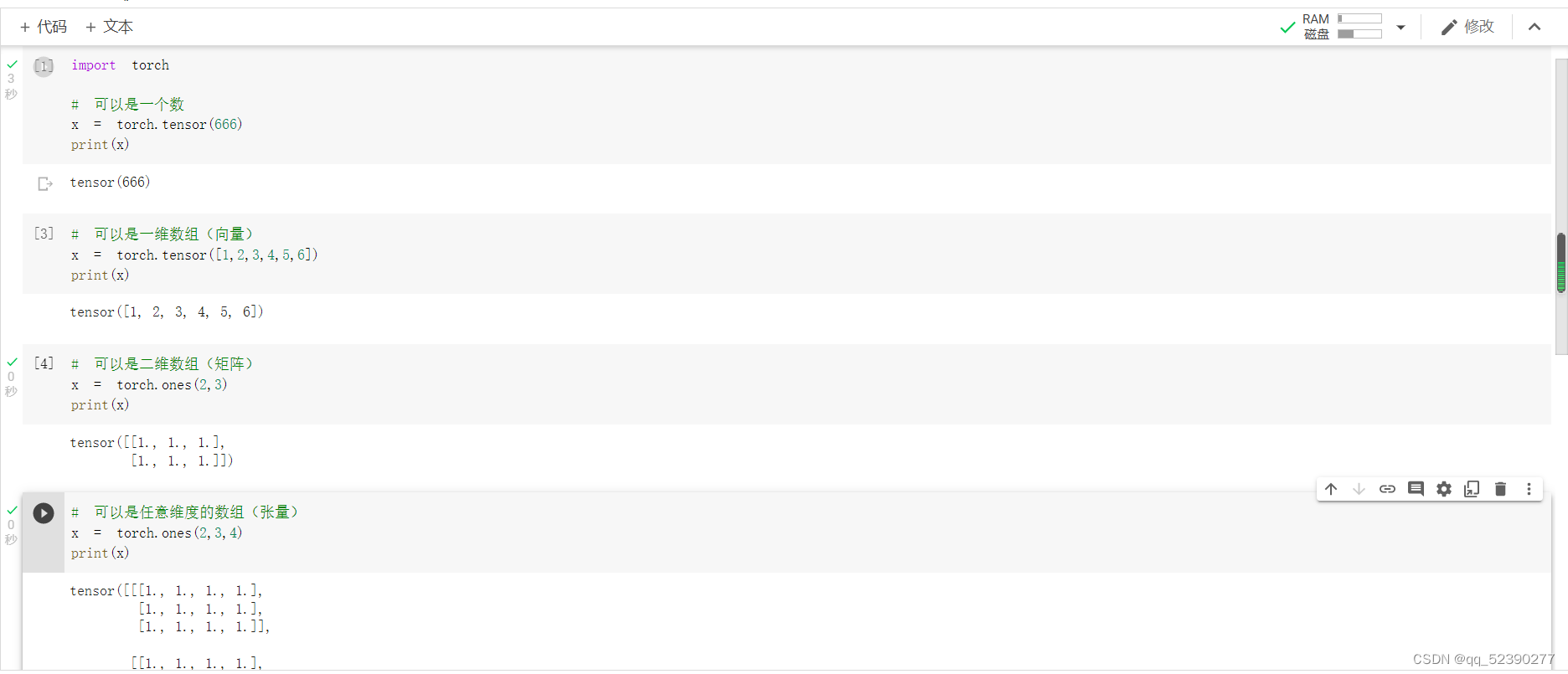
Tensor中定义数据使用Tensor,其可定义多种类型的数据,可以创建单个数值、二维矩阵以及多维矩阵等,并可使用ones、zeros等函数快速创建特殊矩阵。

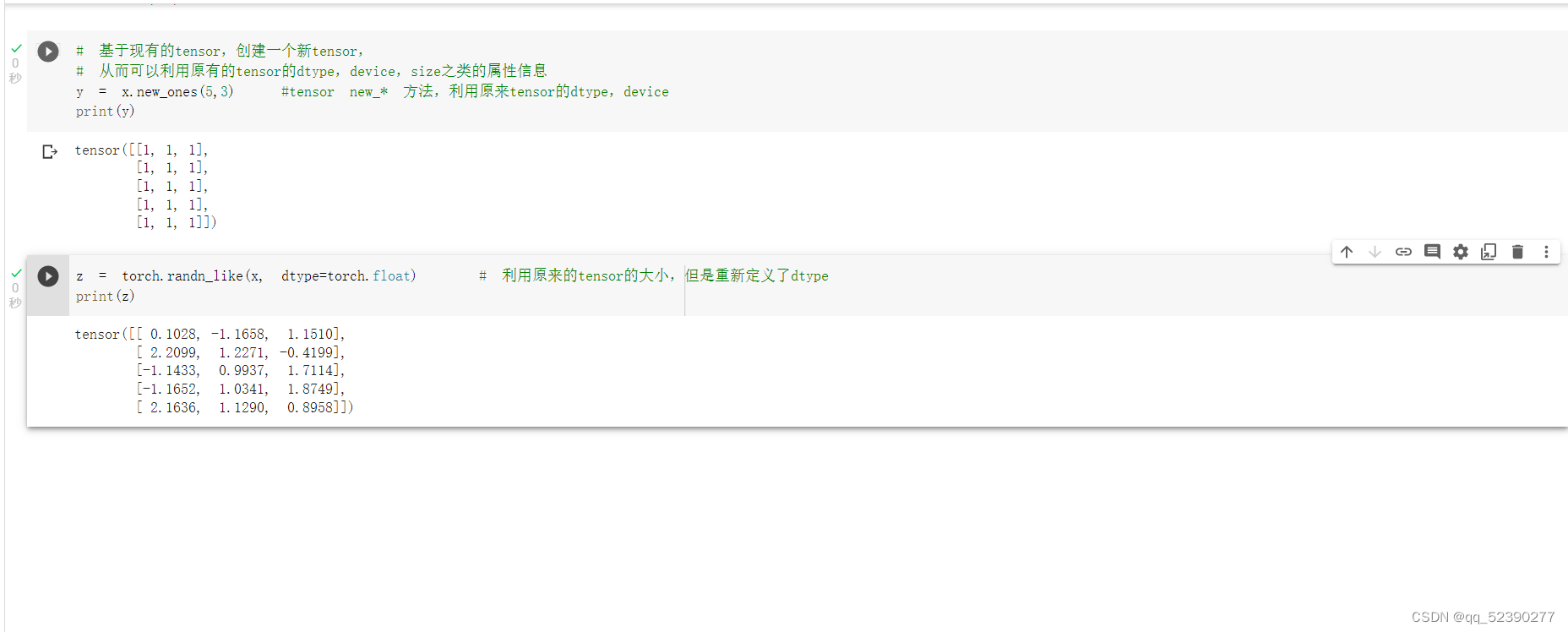 使用empty函数可以创建空张量,rand函数可以创建随机化张量,zeros函数可以创建全0张量并可以定义数据类型,new_*方法可以基于现有的tensor创建新的tensor,同时保留原来tensor的dtype、device、size等信息,randn_like方法可以根据现有tensor的大小创建新的tensor,同时可以指定新的数据类型。
使用empty函数可以创建空张量,rand函数可以创建随机化张量,zeros函数可以创建全0张量并可以定义数据类型,new_*方法可以基于现有的tensor创建新的tensor,同时保留原来tensor的dtype、device、size等信息,randn_like方法可以根据现有tensor的大小创建新的tensor,同时可以指定新的数据类型。
2.定义运算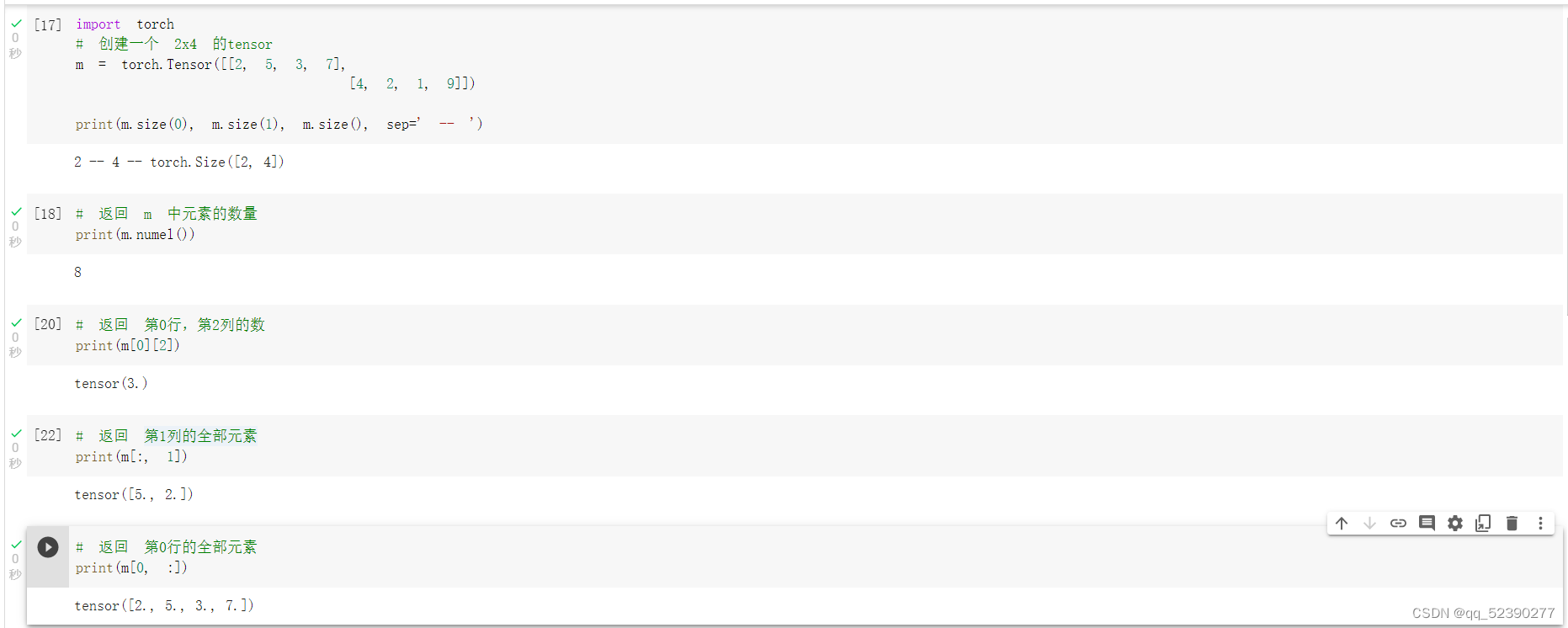
首先创建一个2*4的矩阵m,size(0)表示矩阵的行数,size(1)表示矩阵的列数,而size()表示矩阵的行数和列数,numel函数可以求出矩阵中的元素数,使用[]运算符可以定位到矩阵中的元素,例如m[0][2]表示矩阵中第一行第三个元素,m[:,1]表示矩阵的第2列,m[0,:]表示矩阵的第1行,直接使用:符号表示取整行或者整列。
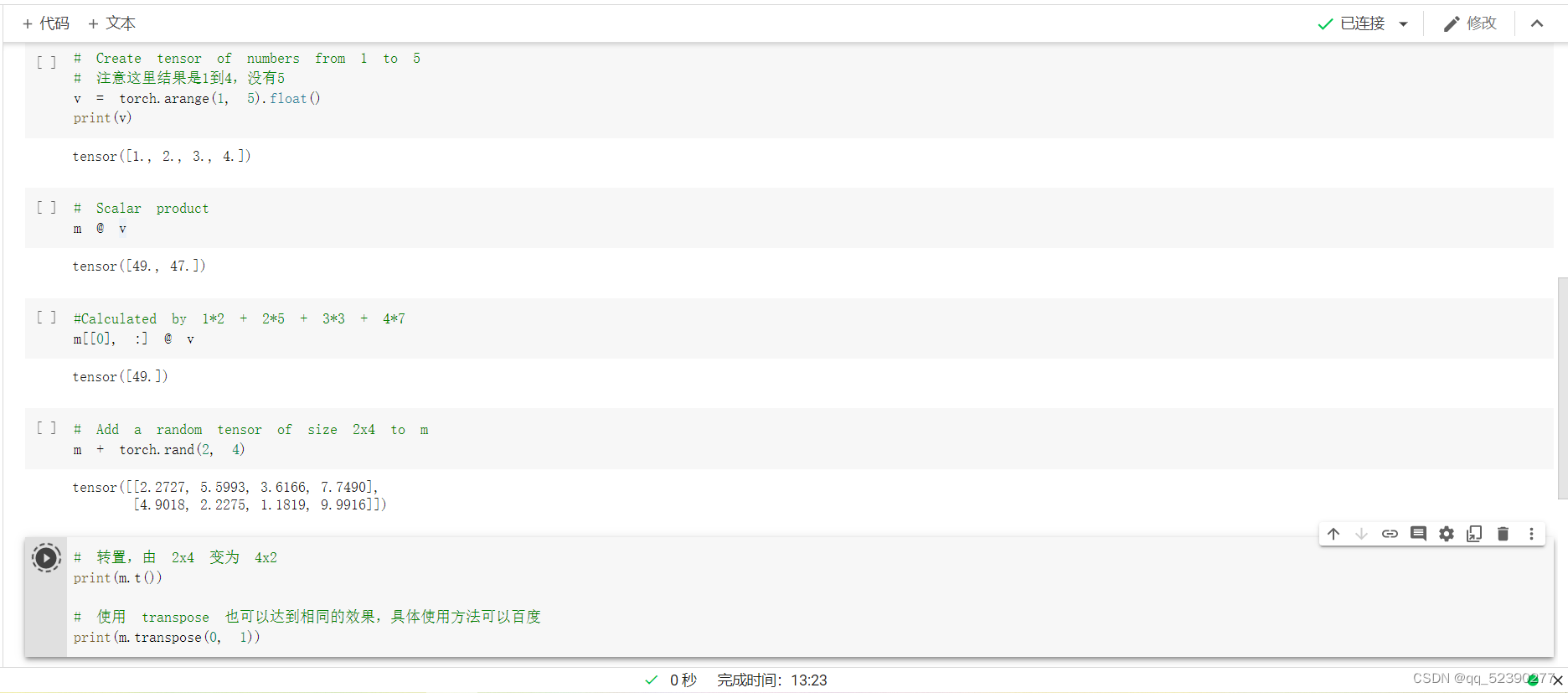
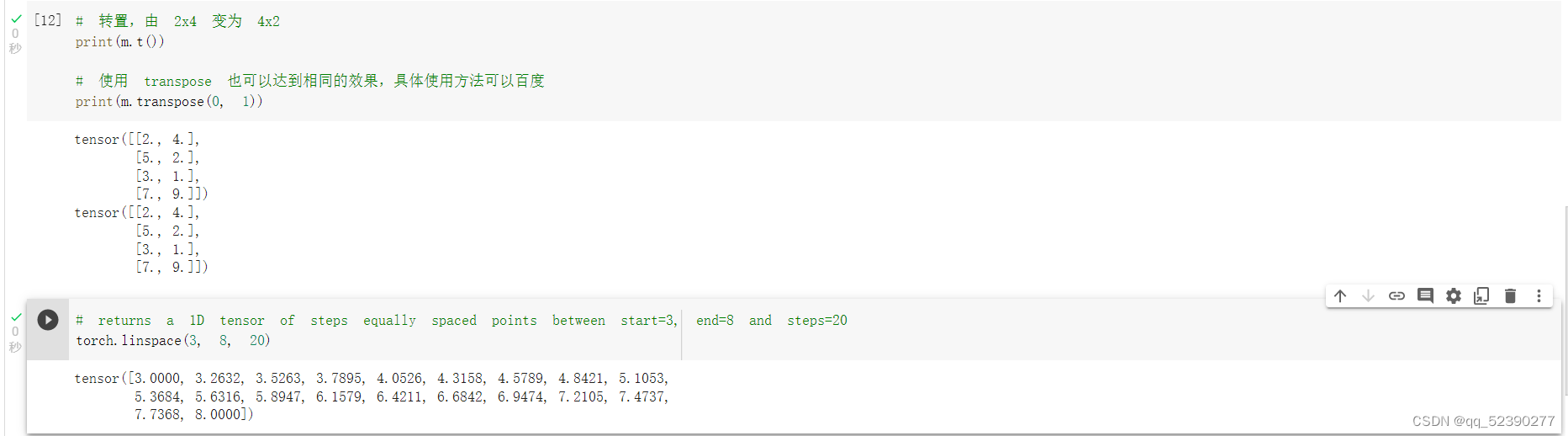
使用arange函数可以快速创建一定范围内的矩阵,使用m@v表示进行m矩阵和v矩阵的乘法,这里按照实验手册运行时报错,提示矩阵数据类型不一直。发现m矩阵数据是float类型,而使用arange函数创建的v矩阵数据是long类型,所以在使用arange函数创建v矩阵时在后面加上.float(),将其数据也转换为float类型,再进行矩阵的乘法,结果如上图,m[[0],:] @ v表示取出m矩阵的第一行与v进行矩阵乘法,结果是1*1的矩阵,m+torch.rand(2,4)表示将m与0到1的2*4的矩阵进行矩阵加法,t()函数或transpose可实现矩阵的转置,linspace(3,8,20)表示在3到8之间取间隔相等的20个数构成矩阵,即每两个数的间隔为5/19=0.2632。
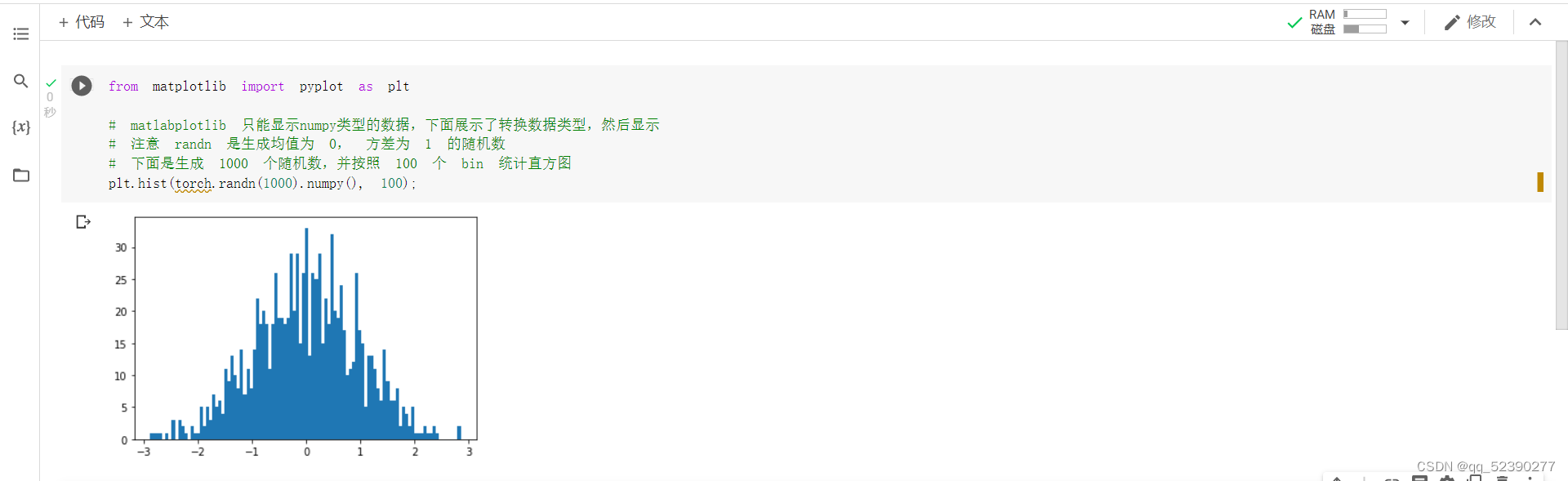
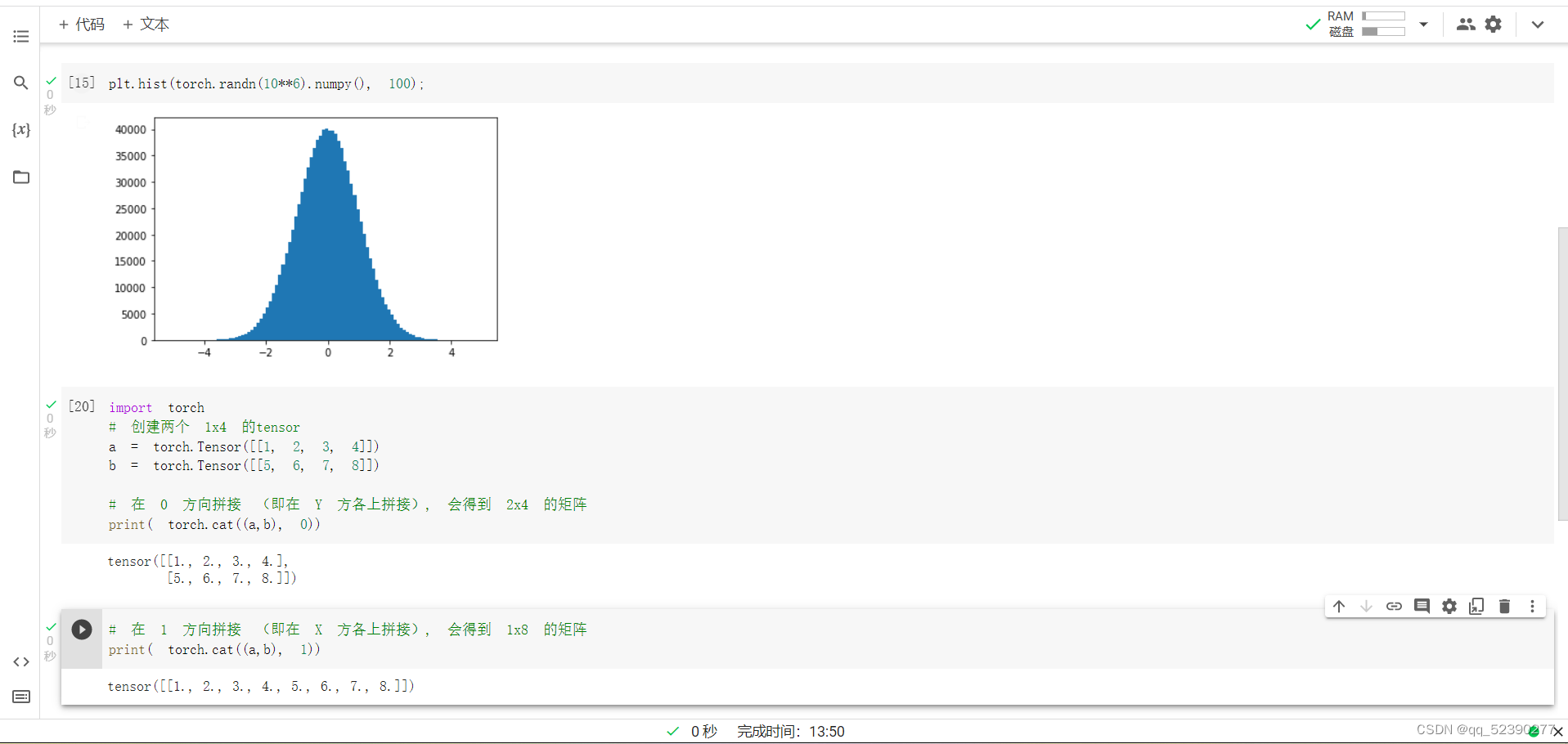
randn函数分别生成了1e3和1e6的符合正态分布的两组数,使用numpy()将其转换为numpy类型的数据,并以100个数为一组绘制频率直方图,可以看出数据量为1e3时,数据符合正态分布不是很明显,而当数据量为1e6时数据几乎完全符合正态分布。cat函数可以用于矩阵的拼接,参数为0表示在列方向进行拼接,此时拼接a和b得到了一个2*4的矩阵,参数为1表示在行方向进行拼接,此时拼接a和b得到了1*8的矩阵。
2.2 螺旋数据分类

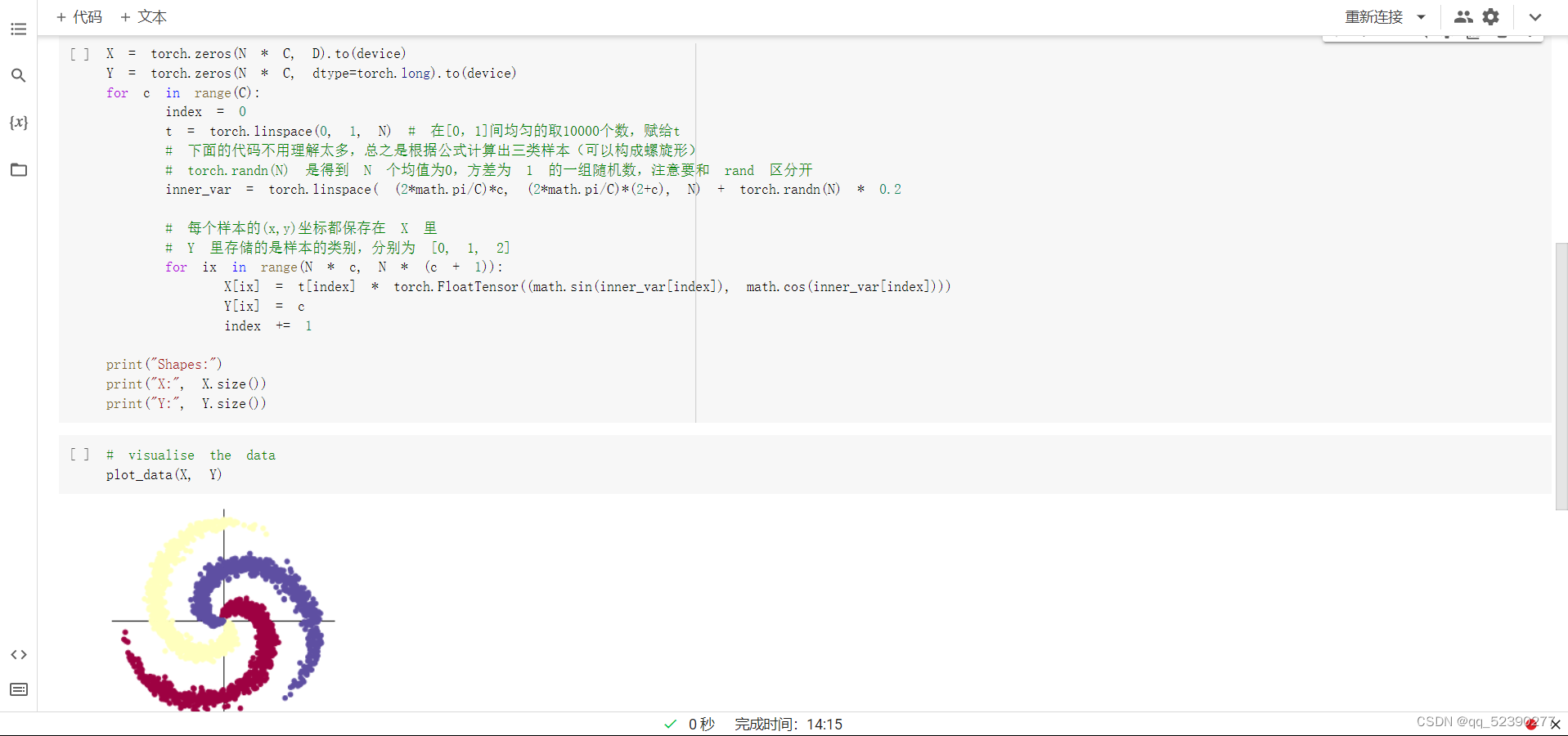
初始化 X 和 Y。 X 可以理解为特征矩阵,Y可以理解为样本标签。 结合代码可以看到,X的为一个 NxC 行, D 列的矩阵。C 类样本,每类样本是 N个,所以是 N*C 行。每个样本的特征维度是2,所以是 2列。
在 python 中,调用 zeros 类似的函数,第一个参数是 y方向的,即矩阵的行;第二个参数是 x方向的,即矩阵的列,大家得注意下,不要搞反了。下面结合代码看看 3000个样本的特征是如何初始化的。
1.构建线性模型分类
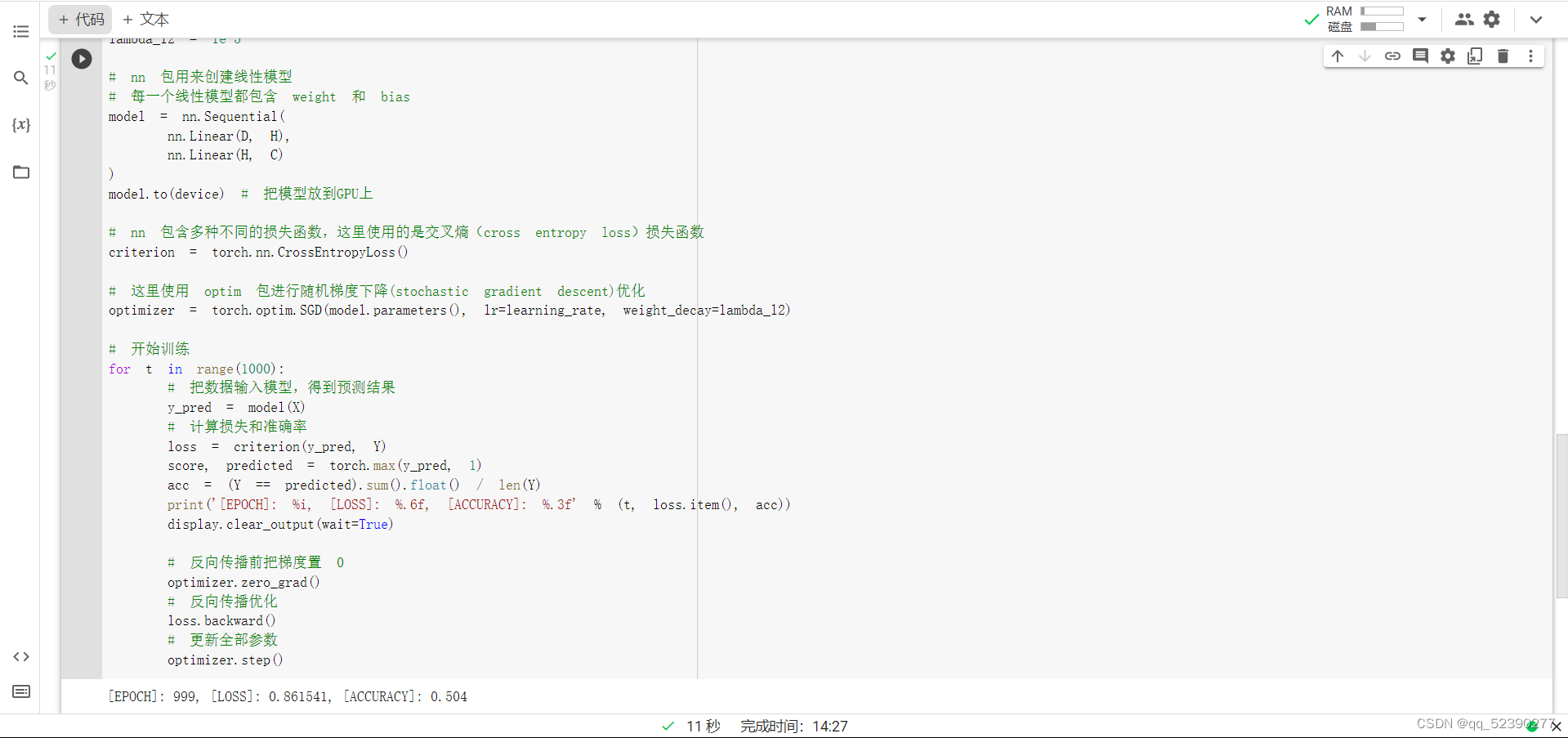
这里对上面的一些关键函数进行说明:
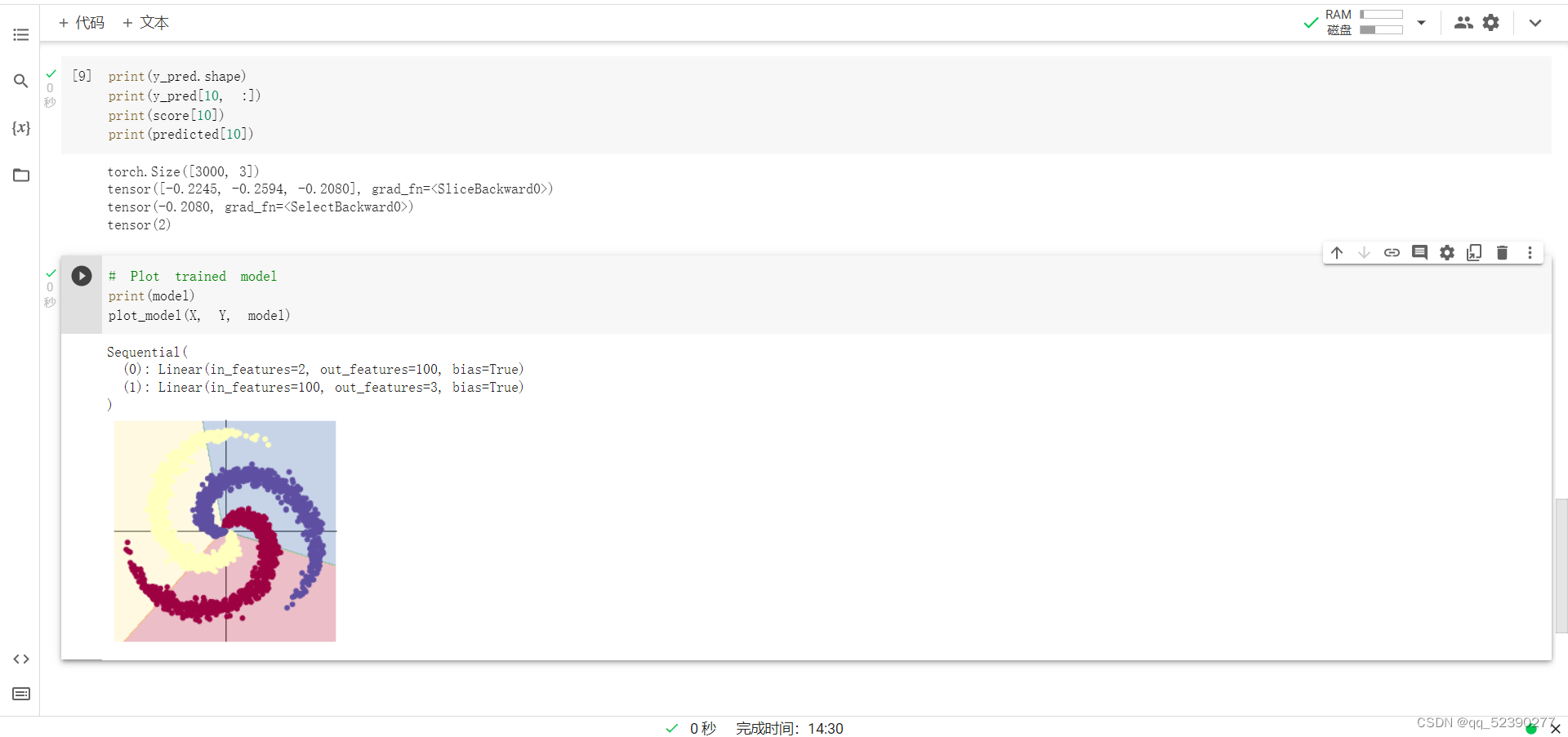
使用 print(y_pred.shape) 可以看到模型的预测结果,为[3000, 3]的矩阵。每个样本的预测结果为3个,保存在 y_pred 的一行里。值最大的一个,即为预测该样本属于的类别
score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中。下面代码把第10行的情况输出,供解释说明
2. 构建两层神经网络分类
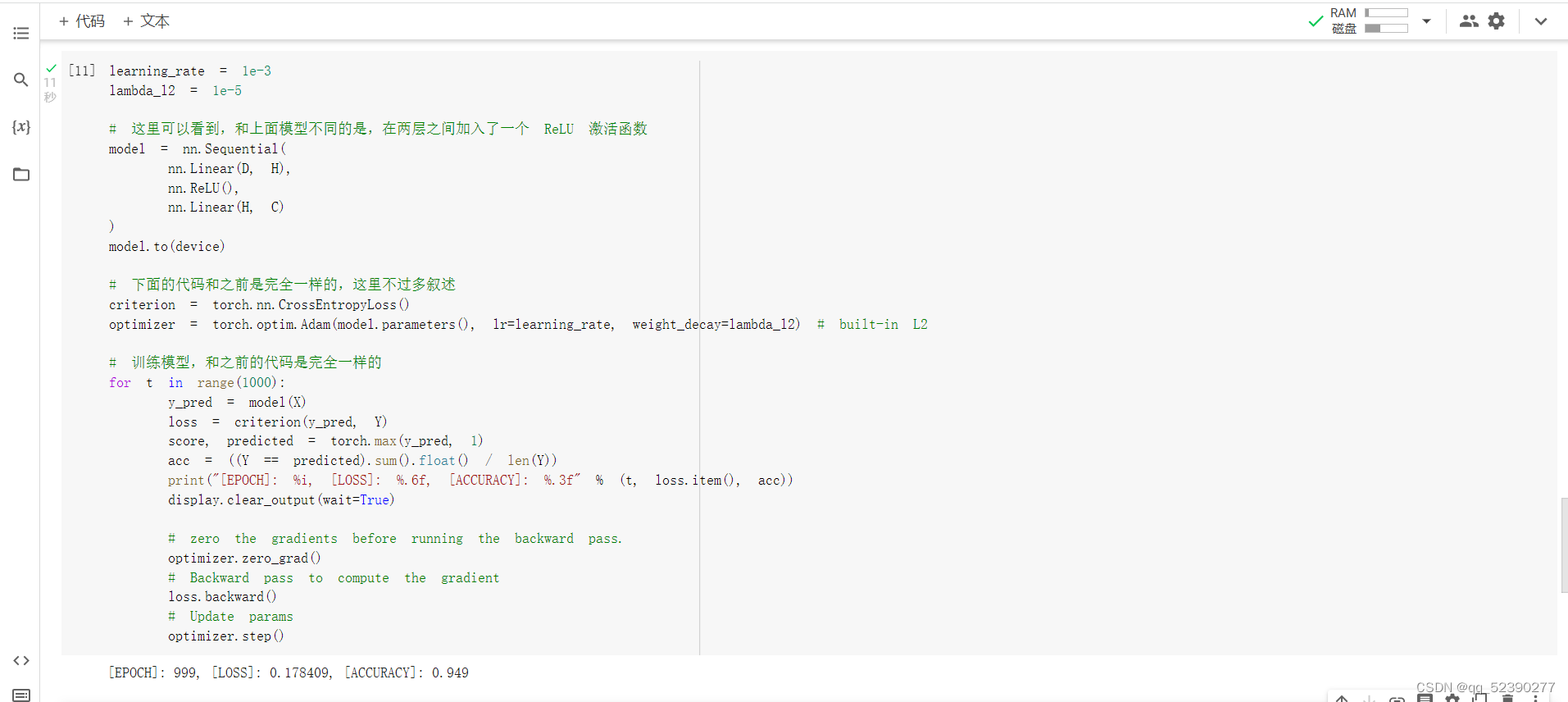
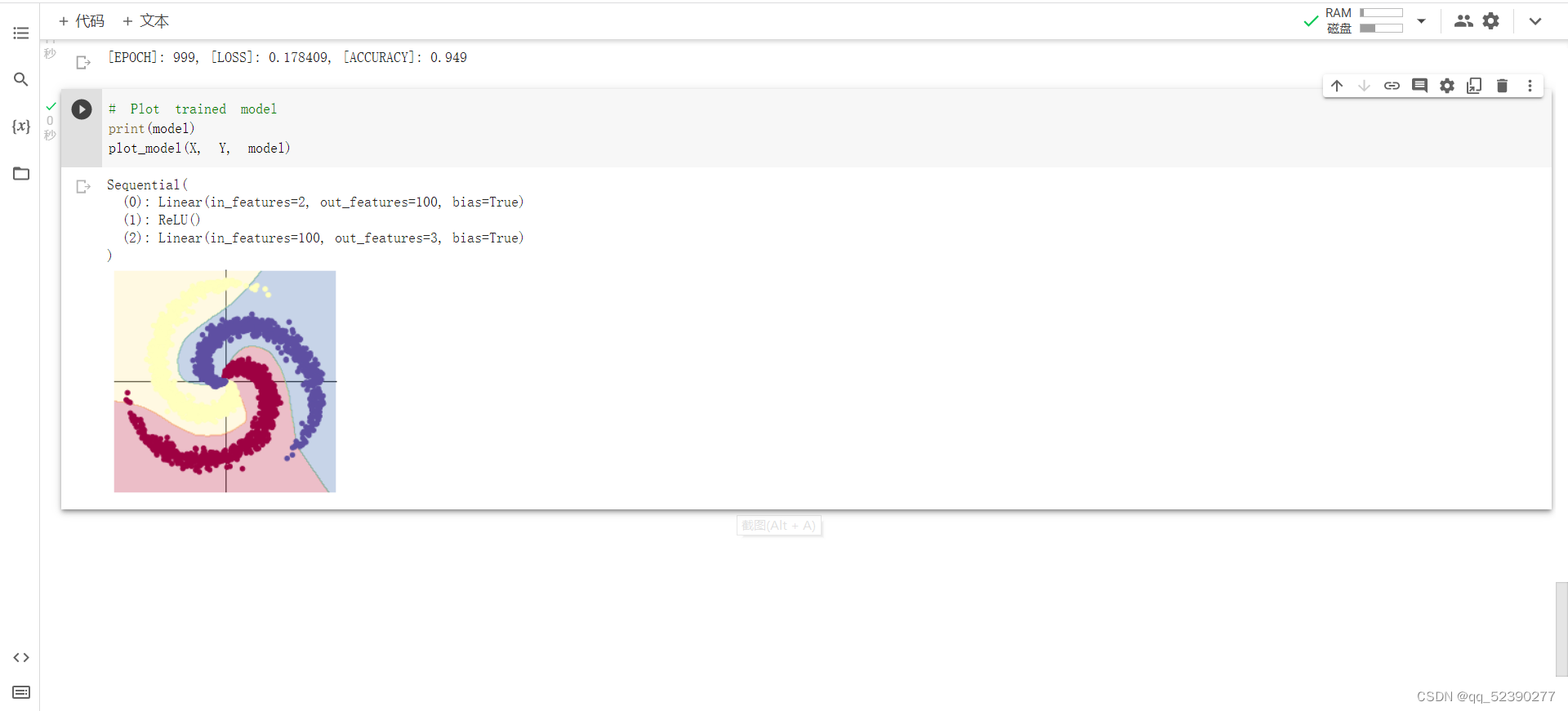
和线性模型相比,两层神经网络分类的准确率明显较高,说明两层神经网络分类中的RELU激活函数能使分类模型适用于较复杂的情况,明显地提高了分类的准确率。
实验心得体会
通过实验,我们组发现线性分类模型和两层神经网络分类模型只有RELU激活函数的差别,而后者的准确率却明显地提高,查找资料后我们分析认为采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失 的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。同时ReLu会使一部分神经元的输出为0,这样就造成了 网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。但RELU函数也存在不足,比如一个非常大的梯度流过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。如果这个情况发生了,那么这个神经元的梯度就永远都会是0。因此进行分类时要认真研究,选择合适的模型。















 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









