







——开源软件开发导论项目实践总结报告
摘要:本项目是应用openEuler A-Ops项目中的gala-gopher组件而开发的通用场景下TCP传输性能劣化检测工具,主要功能是通过对gala-gopher组件检测得到的网络中有关TCP传输的各项性能指标值进行分析,得到当前TCP传输是否存在故障以及具体故障原因的判断。本文将从目标与分工、技术研发进展、开源开发工作、项目效果展示和总结与展望五个方面介绍本项目的开发情况。
关键词:开源开发,TCP传输,相关性分析,故障根因
一、目标与分工
本项目的最终目标是需要在不影响业务正常性能的情况下,完成通用场景的TCP传输性能劣化检测,并希望能够输出故障原因。本项目的仓库地址为:OpenEulerA-Ops TCP: openEulerA-Ops通用场景TCP传输性能劣化检测 (gitee.com)。项目开发的具体要求主要分为技术要求和产出要求:
-
技术要求:
1.熟悉Linux内核的TCP原理及源码。
2.了解网络故障注入工具并学习其使用方法。
3.熟悉常见的异常检测算法。
4.数据源采用A-Ops系统提供的数据采集器。
-
产出要求:
1.不同故障原因的故障特征向量列表以及相关性分析报告。
2.性能检测功能以及相关的代码,性能检测要具备场景粒度的通用性。
3.性能检测验证报告以及功能说明书,性能检测准确率>70%。
为了保证项目完成的效率,我们根据项目的最终目标与产出要求对小组成员进行了分工,分工的详细情况如下:
组员1负责项目中TCP传输性能指标与故障类型间的相关性分析算法、故障类型检测时的根因算法的构思与具体实现;
组员2负责项目中TCP传输时各性能指标的数据样本的获取与格式化处理以及相关性分析报告文档的撰写;
组员3负责项目中的主要说明文档以及功能说明文档和检测结果验证报告文档等项目整体的总结性文档的撰写。
组内三位成员的工作可以并行,但并非相互割裂无关:组员2需要组员1利用后者给出的相关性分析算法对前者收集到的格式化数据样本进行分析后得到的结果来撰写故障相关性分析报告,而后组员1将依此作为构思实现故障根因算法的参考。组员3则需要根据项目开发的实时进度不断完善修改说明文档与总结文档,同时及时指出项目中可能存在的问题。
二、技术研发进展
根据前一节中的项目开发目标与组员分工情况,我们决定将项目的技术研发过程分为五个依次递进的主要阶段进行:
(一)配置环境并熟悉要用到的工具
首先使用openEuler的22.09镜像与Vmware Workstation软件安装openEuler虚拟机并配置开发环境。之后在其上安装A-Ops系统中的gala-gopher组件作为TCP传输性能数据采集器,并安装tc命令作为网络故障注入工具。完成安装后,通过实际测试熟悉各工具的使用方法,完成项目开发前的准备工作。
(二)收集标准情况下的数据样本作为基准
考虑到本项目的最终要求为根据收集到的有关TCP传输性能的各项指标数据对其作出异常与否的判断并进一步进行故障根因,我们认为首要任务应当是先在未注入任何故障的标准情况下收集得到TCP传输性能指标的数据样本作为一种“基准”,方便之后依据其判断收集到的样本是否出现了异常。我们称这种“基准”为将数据划定为标准状态的阈值。
在这一阶段中,我们通过gala-gopher组件中的tcpprobe探针多次获取标准数据样本并观察其分布后发现,大多数指标的数据都围绕着各自的“中心值”在一定的偏差范围内随机波动,但仍有个别数据偏离“中心值”较远,于是最初的分析想法是对这些数据进行正态分布的拟合求出其期望与方差,并依据3sigma准则将(μ±3σ)作为判断标准情况的阈值。
但在经过实际拟合计算后发现,部分指标数据的结果出现了3倍方差大于甚至远大于均值的情况,因此显然无法使用3sigma准则进行判断。我们进一步观察指标数据的分布情况后发现,大多数指标的数据事实上并不严格遵从正态分布,部分分布情况如下所示:
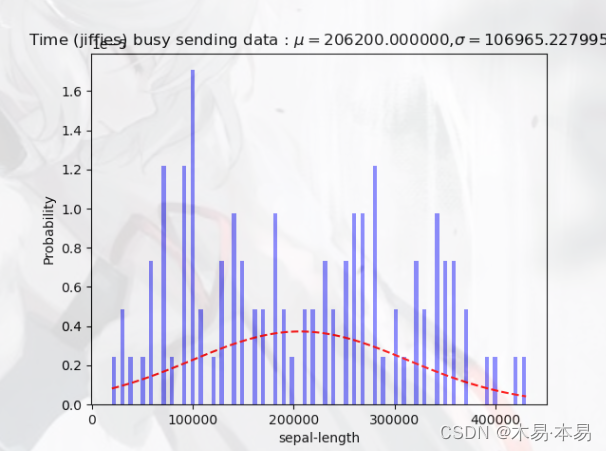
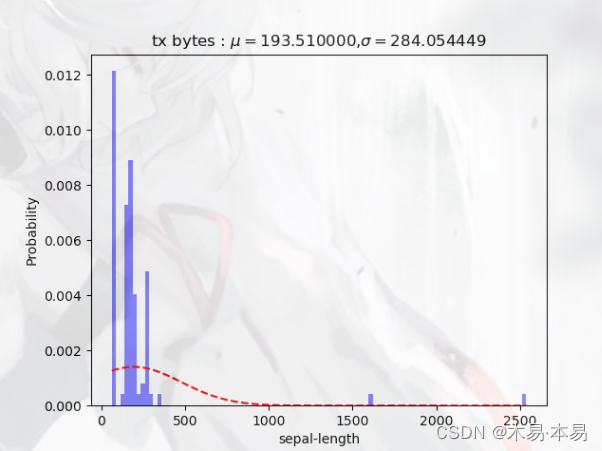
此外,还有部分数据出现了多个“中心值”,如下所示:

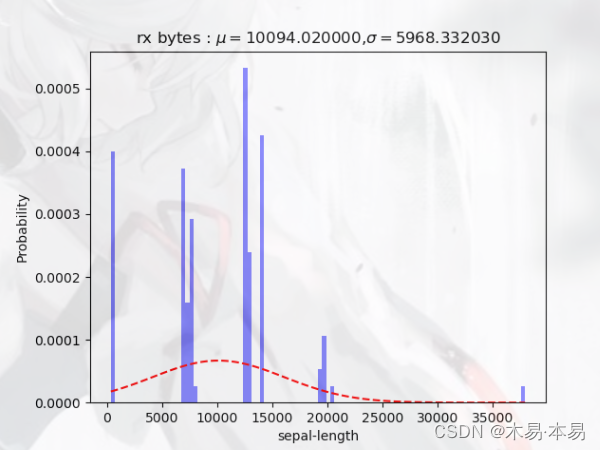
对于如此分布的数据,贸然进行μ和σ的拟合求取显然是不可行的。
于是,在转而考虑到这些数据内部的“集群”特征后,我们开始采用基于距离的异常分析算法KNN。这一算法的核心思想是对数据集中的每一个数据求其与最近的K个邻居的距离(对于一维数据即差值)的平均值,为这些平均值划定一个阈值,则超过了这一阈值的平均值所代表的数据将被认定为异常数据。KNN并不关心数据本身的分布特征,而是把重点放在了数据内的“集群”情况上,如此一来,既解决了数据分布不严格遵从正态分布但又围绕着某一“中心值”波动的问题,又解决了多个“中心值”影响的问题。
在标准情况下,我们对共计18个有效的性能指标(将值恒为某一常数且与所要判断的故障无关的性能指标认定为无效性能指标,暂时不考虑收集与分析)各自收集了100个数据样本,共计18×100=1800个数据。对于某一性能指标,对其100个数据逐个使用KNN算法求取平均值(K取总数的十分之一,即10),共得到100个平均值,而后在按升序排序后选定其中第85个数据(后通过多次实验证明使用第85位数据效果最佳)作为该性能指标的平均距离阈值,也即用来判断该性能是否处于标准情况的阈值。
对于每个性能指标的处理过程如下图所示,共计得到了18个不同性能的阈值:

(三)收集指定故障下的异常数据样本用于进行相关性分析
在确定了各性能指标的标准情况判断阈值后,我们开始考虑在注入故障后的异常情况下各性能指标与故障类型间相关性分析及量化的方法。在通过tc命令的相关选项向网卡设备中注入特定故障后,我们仍使用tcpprobe探针来获取数据样本,并最终决定借助上一阶段中获得的标准情况判断阈值来进行相关性的分析与量化。
具体而言,在注入故障的异常情况下时,同样可以先对每个性能指标取一定量的数据样本,也以100个为默认数量,由于目前总共判断4种故障类型(时延、丢包、包重复和包乱序),共计4×18×100=7200个数据。对于某一故障下某一性能中的某一个数据,将其放到对应性能的100个标准数据样本中,之后在这101个数据中使用KNN算法对该数据求其与10个邻居距离的平均值,将该平均值与该性能指标的平均距离阈值比较,若超出,则对该数据记1,表示该数据有异常,否则记0。每个性能最终获得100个0或1的值,求和后再求与100的比值(也即异常数据的占比),该比值即可反映当前性能指标受到该故障的影响程度。换言之,该比值即为该故障与该性能相关性的量化值。
在4种故障下分别求18个性能的相关性量化值,则共计得到4×18=72个相关性量化值,对于某一故障下每个性能指标的相关性量化值的计算过程如下图所示:
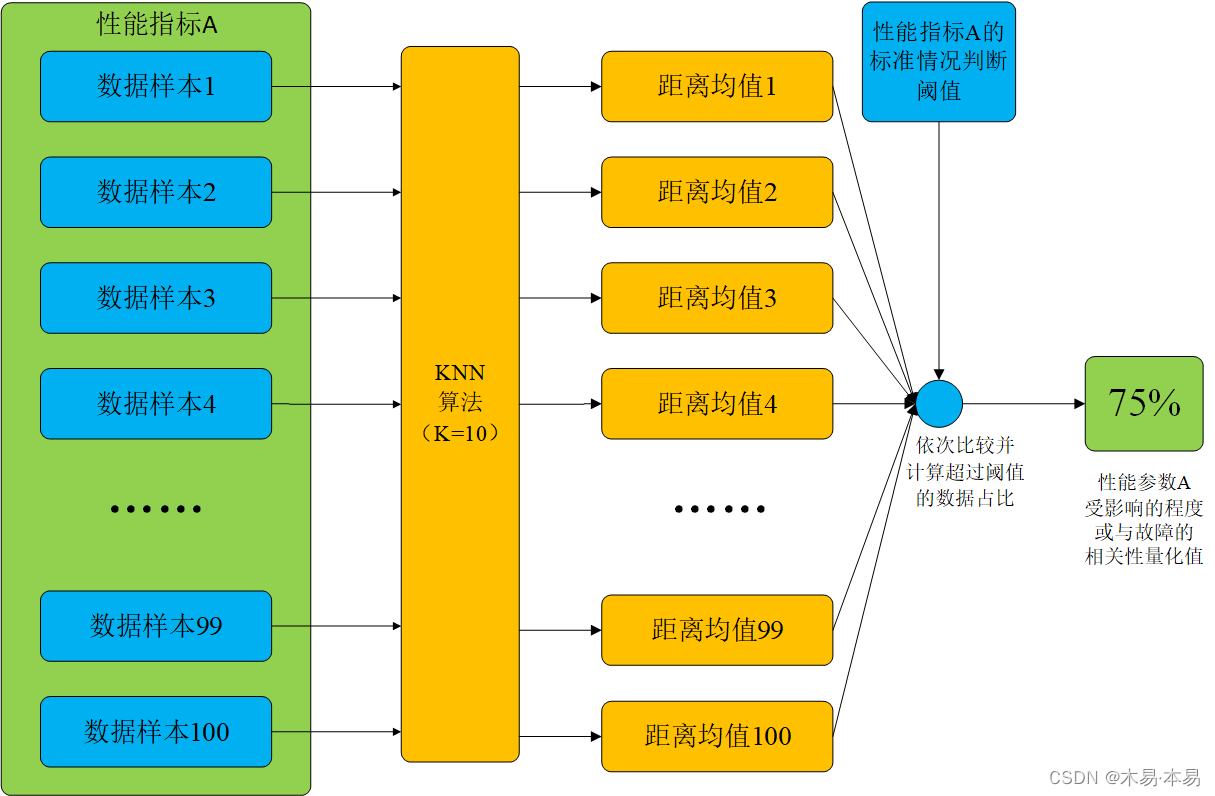
(四)利用相关性分析结果构建故障类型检测算法
在上一阶段的相关性分析过程中,由于该相关性量化值实际上也可以表征当前样本中的该性能指标受到某一故障的影响程度,这个值的计算过程实际上也可以作为TCP传输性能故障检测算法的重要参考。
具体而言,在进行故障检测时,数据收集与整理相关脚本会先对每个性能指标取一定量的数据样本,以10个为默认数量,共计18×10=180个数据。对于某一性能中的某一个数据,分析脚本会将其放到对应性能的100个标准数据样本中,之后在这101个数据中使用KNN算法对该数据求其与10个邻居距离的平均值,将该平均值与该性能指标的平均距离阈值比较,若超出,则对该数据记1,表示该数据有异常,否则记0。每个性能最终获得10个0或1的值,求和后再求与10的比值(也即异常数据的占比),该比值即可反映当前性能指标受到影响的程度。共计18个比值。
实际上,对于在未知情况下随机收集到的数据样本,故障类型检测算法应当被进一步划分为两部分:
1. 对数据样本是否异常的判断:
首先,算法需要进一步对这18个比值求它们对于0的方均根值,也即标准差,用于表征这18个性能偏离标准情况的程度。因为在理想情况下,若18个性能指标的样本值均在标准情况下取得,则由上述步骤得到的18个比值也均为0(即每个性能指标中异常数据的占比为0)。但实际上往往会由于偶然因素导致结果存在偏差,这里取60作为判断比值是否正常的阈值(后通过多次检测证明使用60作为阈值时根因效果最佳),即大于该阈值的标准差对应的传输性能状态将被判断为存在故障,需要进行进一步的故障根因,否则即认定当前的TCP传输性能处于标准情况。
2. 对异常样本的故障类型根因:
如果发现样本数据存在异常,算法就会对前面已经得到的18个比值依次考虑每种故障的影响,具体而言,算法先将之前分析相关性得到的各故障与性能间得相关性量化值以故障为分组进行归一化处理,从而分别作为18个比值的权重对其求加权平均值。进行这一步的目的在于应用故障与性能之间的相关性反映出样本整体受到某一故障影响的程度或概率。共4种故障类型,故共进行4次求加权平均的计算。这一计算将得到一个包含4个元素的向量,每个元素对应于某一故障是导致TCP传输性能劣化的主导因素的概率。因此,其中最大值对应的故障类型将被认定为故障根因的最终结果。
(五)构建验证集数据以说明本项目分析与检测算法的可行性
在通过前四个阶段实现了项目中的主要算法后,就需要进一步构建验证集数据来验证故障检测算法的准确率并说明其可行性了。
对于算法给出的五种检测结果(标准情况加四种故障情况),我们决定对于每种结果分别生成20组验证数据样本,则验证集中将共有100组验证数据样本。
在经由故障检测算法分析后,测得的验证集中五种故障类型内部检测准确率和总体的检测准确率如下图所示:

可见,检测算法的总体检测准确率达到了80%,超过了开始时70%的项目产出要求,同时说明了本项目的性能指标与故障类型相关性分析算法以及最后的故障类型检测算法具有较高的可行性。
三、开源开发工作
有关于本项目开源开发工作的介绍主要分为如下两个部分:
(一)本项目仓库的开源建设情况
本项目仓库的概况如下图所示:

目前已经将所有算法源码上传,并在README.md和项目功能说明书文档中对本项目进行了详细的介绍:

项目要求中还涉及到的性能指标与故障的相关性分析报告和性能检测验证报告也已完成撰写并上传至course/docs目录中,以便于后续的使用者或开发者深入了解本项目的原理与使用方法:
 (二)与华为openEuler项目的合并情况
(二)与华为openEuler项目的合并情况
目前我们的项目仍属于达成了开发要求与产出要求的独立项目,我们会在课程结束后继续进行优化改进,并争取在寒假时间内对本项目中的输入输出接口进行规范化后将项目合并至华为openEuler的gala-anteater项目中(项目地址为:gala-anteater: A time-series anomaly detection platform for operating system (gitee.com)):

四、项目功能展示
如下图所示,项目的主要功能分为三大部分:

(一)对于标准数据样本的收集与处理
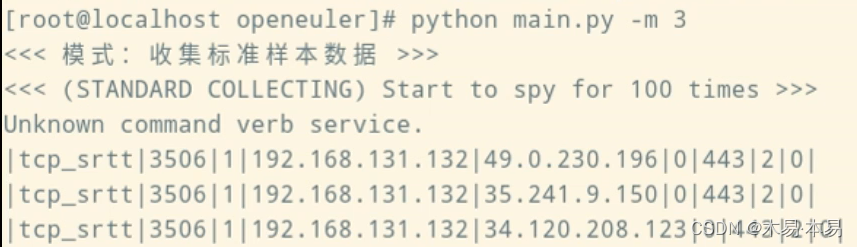
在不注入故障的标准情况下,通过tcpprobe探针获取TCP传输性能指标的数据样本,并进行处理得到当前环境下的标准情况判断阈值。如果想要使用该功能,可在项目根目录下运行命令(“[ ]”中的选项为可选项):
python main.py -m 3 [-i 需要筛选的IP地址]
(二)对于故障数据样本的收集与分析
在注入特定故障的异常情况下,通过tcpprobe探针获取TCP传输性能指标的数据样本,并进行相关性分析得到当前环境下的性能指标与故障类型相关性的量化值。如果想要使用该功能,可在项目根目录下运行命令(“[ ]”中的选项为可选项):
python main.py -m 3 -e 已注入故障的类型 [-i 需要筛选的IP地址]

(三)对于随机数据样本的收集与分析
如果想要对当前未知状况下TCP的传输性能指标进行随机采样与故障检测,可根据需求在项目根目录下运行下列命令(“[ ]”中的选项为可选项):
1. 仅收集数据样本:
python main.py -m 1 [-c 每个性能收集的样本数] [-i 需要筛选的IP地址]

2. 仅对已收集的样本进行检测:
python main.py -m 2 [-d 0/1(是否显示细节)]

3. 收集数据样本后进行检测:
python main.py [-m 0] [-c 每个性能收集的样本数] [-i 需要筛选的IP地址] [-d 0/1(是否显示细节)]

4. 对验证集中的样本进行检测:
python main.py -m 2 -a 1 [-d 0/1(是否显示细节)]
(结果展示详见第二节的第(五)小节)
此外,运行项目根目录下的主脚本main.py时所有可用的选项与参数及其说明如下表所示:

五、总结与展望
(一)项目开发总结
我们的项目目前已具备输入、处理、输出的全部过程,功能结构完整,并且已经基本达成了开始时的项目开发与产出要求。
本项目的主要亮点在于我们创新地将异常检测算法KNN应用于相关性分析算法中,从而在对标准数据进行处理取得标准情况判断阈值的同时也对故障数据进行了性能与故障的相关性分析,并将所得结果作为相关性分析的量化值应用于后续的故障检测算法中。这一处理使得我们的算法能够忽略标准数据样本中呈现非正态分布和出现多个“中心值”的情况,转而关注数据本身的“集群”情况,使得我们对标准情况判断阈值的提取更为准确。此外,由于存在相关性量化的过程,我们才能很好地将相关性分析的结果应用于故障检测算法之中,并且极大地提高了检测算法的准确率。
但在有关项目多场景使用时的通用性的方面,我们的设计仍有待改进。由于不同环境下的标准数据的分布情况不同,进行相关性分析时的基准也因此不同,这导致对于不同的检测环境需要重新获取其标准状况下的各基准值并进行分析,但这一过程的耗时主要在于数据的收集,在合并至华为的gala-anteater项目后将有望得到解决。
(二)项目展望
本项目虽然已达成了开发目标与产出要求,但由于目前仍独立于华为openEuler项目且尚未进行提交合并,我们希望能在本课程结束后继续保持对该项目的开发与改进,同时通过对当前输入输出接口的规范化调整争取尽早将我们的项目合并至华为的项目中,为其开发贡献一份我们的力量。














 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









