









目录
JDK8中的ConcurrentHashMap为什么使用synchronized来进行加锁?
第一代线程安全集合类
- Vector、Hashtable
- 是怎么保证线程安排的: 使用synchronized修饰方法*
- 缺点:效率低下
- 直接用synchronized来修饰方法,这相当于直接针对 Hashtable 对象本身加锁.
- 如果多线程访问同一个 Hashtable 就会直接造成锁冲突.
- size 属性也是通过 synchronized 来控制同步, 也是比较慢的.,一旦触发扩容, 就由该线程完成整个扩容过程. 这个过程会涉及到大量的元素拷贝, 效率会非常低.
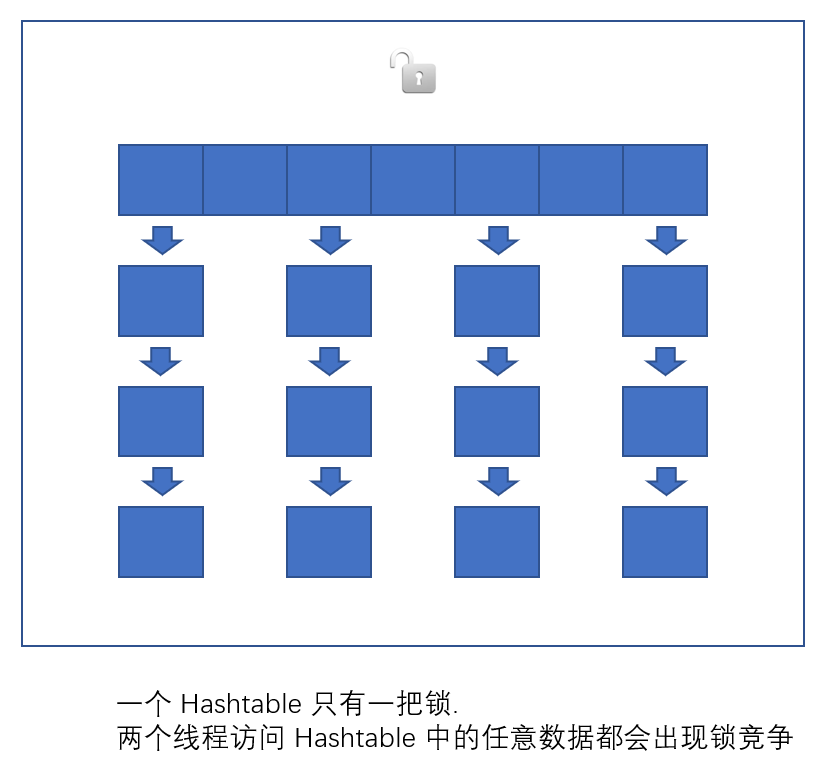
HashTable容器使用Synchronized保证多线程安全,但在线程竞争激烈的情况下HashTable的效率十分低下,是因为当一个线程访问HashTable的同步方法时,其他线程也会访问HashTable的同步方法,会进入阻塞或轮询状态,所以已经被废弃了HashTable与HashMap对比
(1)线程安全:HashMap是线程不安全的类,多线程下会造成并发冲突,但单线程下运行效率较高;HashTable是线程安全的类,很多方法都是用synchronized修饰,但同时因为加锁导致并发效率低下,单线程环境效率也十分低;
(2)插入null:HashMap允许有一个键为null,允许多个值为null;但HashTable不允许键或值为null;
(3)容量:HashMap底层数组长度必须为2的幂,这样做是为了hash准备,默认为16;而HashTable底层数组长度可以为任意值,这就造成了hash算法散射不均匀,容易造成hash冲突,默认为11;
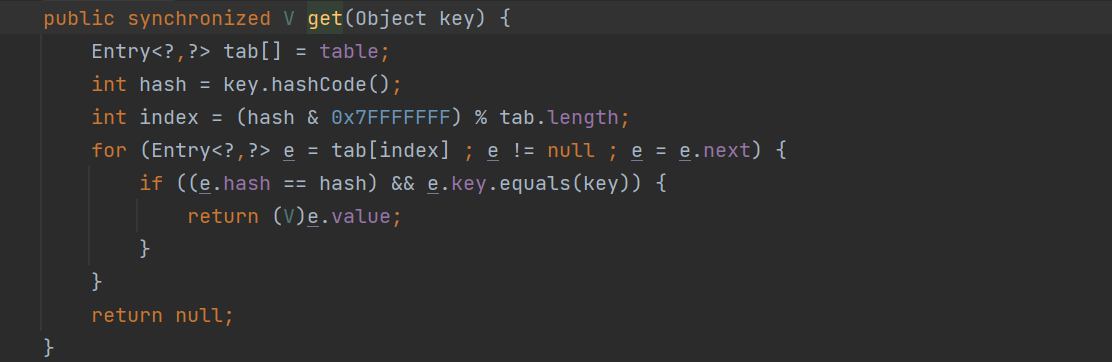
(4)Hash映射:HashMap的hash算法通过非常规设计,将底层table长度设计为2的幂,使用位与运算代替取模运算,减少运算消耗;而HashTable的hash算法首先使得hash值小于整型数最大值,再通过取模进行散射运算;
// HashMap static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } // 下标index运算 int index = (table.length - 1) & hash(key) // HashTable int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;(5)扩容机制:HashMap创建一个为原先2倍的数组,然后对原数组进行遍历以及rehash;HashTable扩容将创建一个原长度2倍+1的数组,再使用头插法将链表进行反序;
(6)结构区别:HashMap是由数组+链表形成,在JDK1.8之后链表长度大于8时转化为红黑树;而HashTable一直都是数组+链表;
(7)继承关系:HashTable继承自Dictionary类;而HashMap继承自AbstractMap类;
第二代线程非安全集合类
- ArrayList、HashMap
- 线程不安全,但是性能好,用来替代Vector、Hashtable
使用ArrayList、HashMap,需要线程安全怎么办呢?
- 自己使用同步机制 (synchronized 或者 ReentrantLock)
- Collections.synchronizedList(new ArrayList); Collections.synchronizedMap(new HashMap)
源代码
static class SynchronizedList<E> extends SynchronizedCollection<E> implements List<E> { private static final long serialVersionUID = -7754090372962971524L; final List<E> list; SynchronizedList(List<E> list) { super(list); this.list = list; } SynchronizedList(List<E> list, Object mutex) { super(list, mutex); this.list = list; } public boolean equals(Object o) { if (this == o) return true; synchronized (mutex) {return list.equals(o);} } public int hashCode() { synchronized (mutex) {return list.hashCode();} } public E get(int index) { synchronized (mutex) {return list.get(index);} } public E set(int index, E element) { synchronized (mutex) {return list.set(index, element);} } public void add(int index, E element) { synchronized (mutex) {list.add(index, element);} } public E remove(int index) { synchronized (mutex) {return list.remove(index);} } public int indexOf(Object o) { synchronized (mutex) {return list.indexOf(o);} } public int lastIndexOf(Object o) { synchronized (mutex) {return list.lastIndexOf(o);} } public boolean addAll(int index, Collection<? extends E> c) { synchronized (mutex) {return list.addAll(index, c);} } public ListIterator<E> listIterator() { return list.listIterator(); // Must be manually synched by user } public ListIterator<E> listIterator(int index) { return list.listIterator(index); // Must be manually synched by user } public List<E> subList(int fromIndex, int toIndex) { synchronized (mutex) { return new SynchronizedList<>(list.subList(fromIndex, toIndex), mutex); } } @Override public void replaceAll(UnaryOperator<E> operator) { synchronized (mutex) {list.replaceAll(operator);} } @Override public void sort(Comparator<? super E> c) { synchronized (mutex) {list.sort(c);} } private Object readResolve() { return (list instanceof RandomAccess ? new SynchronizedRandomAccessList<>(list) : this); } }private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable { // use serialVersionUID from JDK 1.2.2 for interoperability private static final long serialVersionUID = 1978198479659022715L; private final Map<K,V> m; // Backing Map final Object mutex; // Object on which to synchronize SynchronizedMap(Map<K,V> m) { if (m==null) throw new NullPointerException(); this.m = m; mutex = this; } SynchronizedMap(Map<K,V> m, Object mutex) { this.m = m; this.mutex = mutex; } public int size() { synchronized(mutex) {return m.size();} } public boolean isEmpty(){ synchronized(mutex) {return m.isEmpty();} } public boolean containsKey(Object key) { synchronized(mutex) {return m.containsKey(key);} } public boolean containsValue(Object value){ synchronized(mutex) {return m.containsValue(value);} } public V get(Object key) { synchronized(mutex) {return m.get(key);} } public V put(K key, V value) { synchronized(mutex) {return m.put(key, value);} } public V remove(Object key) { synchronized(mutex) {return m.remove(key);} } public void putAll(Map<? extends K, ? extends V> map) { synchronized(mutex) {m.putAll(map);} } public void clear() { synchronized(mutex) {m.clear();} } private transient Set<K> keySet = null; private transient Set<Map.Entry<K,V>> entrySet = null; private transient Collection<V> values = null; public Set<K> keySet() { synchronized(mutex) { if (keySet==null) keySet = new SynchronizedSet<K>(m.keySet(), mutex); return keySet; } } public Set<Map.Entry<K,V>> entrySet() { synchronized(mutex) { if (entrySet==null) entrySet = new SynchronizedSet<Map.Entry<K,V>>(m.entrySet(), mutex); return entrySet; } } public Collection<V> values() { synchronized(mutex) { if (values==null) values = new SynchronizedCollection<V>(m.values(), mutex); return values; } } public boolean equals(Object o) { if (this == o) return true; synchronized(mutex) {return m.equals(o);} } public int hashCode() { synchronized(mutex) {return m.hashCode();} } public String toString() { synchronized(mutex) {return m.toString();} } private void writeObject(ObjectOutputStream s) throws IOException { synchronized(mutex) {s.defaultWriteObject();} } } SynchronizedMap
- SynchronizedMap 是一个实现了Map接口的代理类,该类中对Map接口中的方法使用synchronized 同步关键字来保证对Map的操作是线程安全的。
- 底层使用synchronized代码块锁 虽然也是锁住了所有的代码,但是锁在方法里边,并所在方法外边性能可以理解为稍有提高吧。毕竟进方法本身就要分配资源的
- Collections.synchronizedMap他是一个大锁(重量级锁),在用它包裹起来的集合,该集合所有的数据都会被上锁,类似的还有Collections.synchronizedList等集合,他们都是一种情况
- Mutex在构造时默认赋值为this,即所有方法都用的同一个锁,m就是我们传入的map。
第三代线程安全集合类
大量并发情况下如何提高集合的效率和安全呢?
- java.util.concurrent.*
- ConcurrentHashMap:
- CopyOnWriteArrayList :
- CopyOnWriteArraySet: 注意 不是CopyOnWriteHashSet*
- 底层大都采用Lock锁(1.8的ConcurrentHashMap不使用Lock锁),保证安全的同时,性能也很高。
- 在并发编程的情况下,使用
HashMap可能会导致程序死循环,而使用线程安全的HashTable效率又十分低下,所以大名鼎鼎的Doug Lea写出了伟大的并发安全的ConcurrentHashMap!ConcurrentHashMap结构
JDK1.7
- JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现
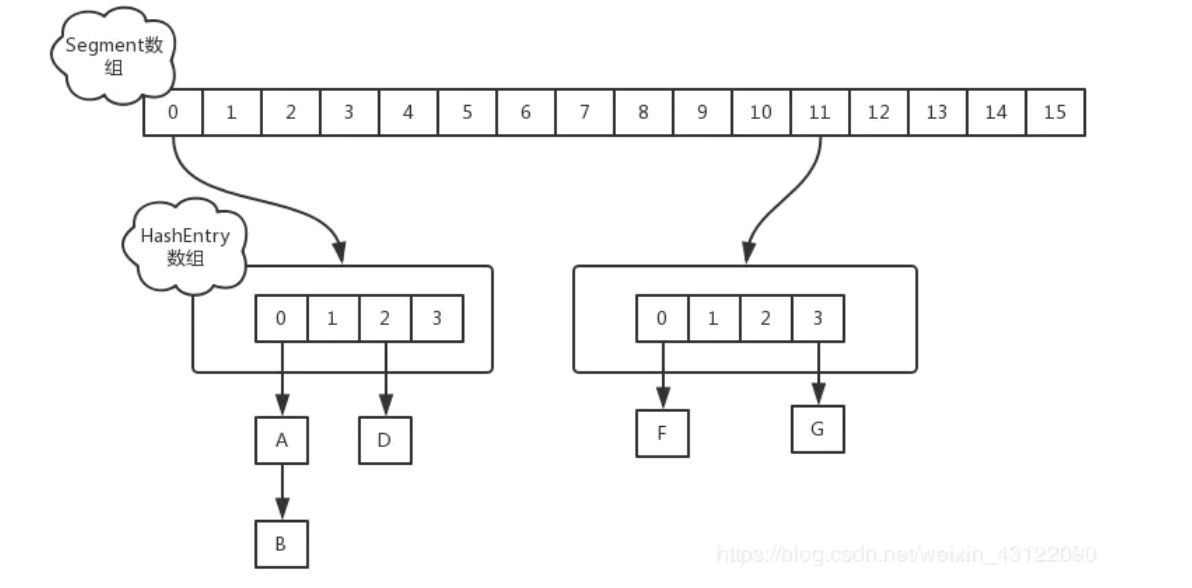
- 在JDK1.7中,ConcurrentHashMap是由Segment数组和Entry数组组成,Segment是一种可重入锁,在源码中直接继承的ReentrantLock
- JDK7中ConcurrentHashMap是通过ReentrantLock+分段思想来保证的并发安全的,ConcurrentHashMap的put方法会通过CAS的方式,把一个Segment对象存到Segment数组中,一个Segment内部存在一个HashEntry数组,相当于分段的HashMap,Segment继承了ReentrantLock,每段put开始会加锁。get方法无需加锁,用volatile来保证数据的正确性
- 对于元素查询,第一次是在hash到对应的segment段,第二次是hash到对应的数组索引
static class Segment<K,V> extends ReentrantLock implements Serializable { private static final long serialVersionUID = 2249069246763182397L; final float loadFactor; Segment(float lf) { this.loadFactor = lf; } }
- 每一个Segment就类似一个HashMap,也就是数组+链表,一个Segment中包含一个HashEntry数组,数组中每个元素就对应一条链表,每个Segment守护着一个HashEntry数组中的元素,当对HashEntry中的元素进行修改时,就必须要获得该HashEntry数组对应的Segment锁
- 所以1.7ConcurrentHashMap的并发度就是段的个数,段的个数就是支持同时多少个线程操作,锁的段,但是不会影响其他段的操作
- 因为1.7是基于segment,相当于每个segment是一个hashmap,所以扩容也是针对于segment的内部进行扩容,不会影响其他segment,
JDK1.8
JDK1.8的实现已经抛弃了
Segment分段锁机制,利用CAS+Synchronized来保证并发更新的安全,底层采用数组+链表+红黑树的存储结构
- 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑
树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对
synchronized锁做了很多优化)- 读操作没有加锁(但是使用了 volatile 保证从内存读取结果), 只对写操作进行加锁. 加锁的方式仍然是是用 synchronized, 但是不是锁整个对象, 而是 "锁桶" (用每个链表的头结点作为锁对象), 大大降低了锁冲突的概率
- 查找赋值操作使用CAS锁,读操作无锁,Node的val和next来使用volatile修饰,数组也是用volatile,为了能够发现多线程下有线程在扩容
- 锁的是链表的head节点,不影响其他元素的读写,但是扩容的时候,会阻塞所有的读写操作,并发扩容(多个线程进行扩容),当某个线程在进行put的时候,如果发现正在进行扩容,那么该线程会进行扩容(一个线程在put的时候,如果发现没有进行扩容,在将元素插入到ConcurrentHashMap中,如果超过阈值,则进行扩容)
- 在扩容也先生成一个新的数组,在转移元素的时候,先将数组进行分组,将每组分别交给不同的线程来进行元素的转移,每个线程负责一组或者多组的元素的转移
public V put(K key, V value) { return putVal(key, value, false); } final V putVal(K key, V value, boolean onlyIfAbsent) { //ConcurrentHashMap的key不能为null if (key == null || value == null) throw new NullPointerException(); //得到hash值 int hash = spread(key.hashCode()); //用于记录相应链表的长度 int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; //数组为空则初始化 if (tab == null || (n = tab.length) == 0) tab = initTable(); //通过hash值找到对应的数组下标f,并且该数组中还没有元素 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //使用CAS操作将新值放入table中 // 成功则退出循环 // 失败则表示有并发操作,进入下一次循环 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED) //扩容导致数据迁移 tab = helpTransfer(tab, f); //找到数组下标后,数组中已经有元素了,f是头结点 else { V oldVal = null; //获得头结点f的监视器锁 synchronized (f) { if (tabAt(tab, i) == f) { //头结点f的哈希值大于0,说明是链表 if (fh >= 0) { //用于累加,记录链表长度 binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; //如果该节点的hash值等于待put的key的hash并且key值与节点key值“相等”则覆盖value if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; //如果到了链表末尾,则将新值插入链表最后 if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } //红黑树 else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; //调用红黑树的方法插入节点 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) //链表长度大于8转为红黑树 treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; }public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { //判断头节点是否就是要查找的元素 if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } //hash值小于0,说明链表已经转为红黑树 else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; //遍历链表获得value while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }区别
- JDK8中新增了红黑树
- JDK7中使用的是头插法,JDK8中使用的是尾插法
- JDK7中使用了分段锁,而JDK8中没有使用分段锁了
- JDK7中使用了ReentrantLock,JDK8中没有使用ReentrantLock了,而使用了Synchronized
- JDK7中的扩容是每个Segment内部进行扩容,不会影响其他Segment,而JDK8中的扩容和HashMap的扩容类似,只不过支持了多线程扩容,并且保证了线程安全
JDK8中的ConcurrentHashMap为什么使用synchronized来进行加锁?
JDK8中使用synchronized加锁时,是对链表头结点和红黑树根结点来加锁的,而ConcurrentHashMap会保证,数组中某个位置的元素一定是链表的头结点或红黑树的根结点,所以JDK8中的ConcurrentHashMap在对某个桶进行并发安全控制时,只需要使用synchronized对当前那个位置的数组上的元素进行加锁即可,对于每个桶,只有获取到了第一个元素上的锁,才能操作这个桶,不管这个桶是一个链表还是红黑树。
想比于JDK7中使用ReentrantLock来加锁,因为JDK7中使用了分段锁,所以对于一个ConcurrentHashMap对象而言,分了几段就得有几个ReentrantLock对象,表示得有对应的几把锁。而JDK8中使用synchronized关键字来加锁就会更节省内存,并且jdk也已经对synchronized的底层工作机制进行了优化,效率更好。
CopyOnWriteArrayList
- CopyOnWrite容器即写时复制的容器。当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
- 这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
优点:
在读多写少的场景下, 性能很高, 不需要加锁竞争.
缺点:
- 1. 占用内存较多.
- 2. 新写的数据不能被第一时间读取到
HashMap 和 ConcurrentHashMap 的区别
- ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的synchronized锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。(JDK1.8之后ConcurrentHashMap启用了一种全新的方式实现,利用CAS算法。)HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
ConcurrentHashMap 和 Hashtable 的区别?
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
- 实现线程安全的方式(重要): ① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。) 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。
- (JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
JDK1.7的ConcurrentHashMap:
JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点 Node: 链表节点
ConcurrentHashMap 底层具体实现知道吗?实现原理是什么?
JDK1.7
- 首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
- 在JDK1.7中,ConcurrentHashMap采用Segment + HashEntry的方式进行实现,结构如下:
- 一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
- 该类包含两个静态内部类 HashEntry 和 Segment ;前者用来封装映射表的键值对,后者用来充当锁的角色;
- Segment 是一种可重入的锁 ReentrantLock,每个 Segment 守护一个HashEntry 数组里得元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 锁
JDK1.8
- 在JDK1.8中,放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
CopyOnWriteArrayList
- 适合读操作远远多余写操作的应用,特别在并发情况下,可以提高性能的并发读取,但是他的原理导致了他只能保证了数据的最终一致性,不能保证数据的实时一致性,所以你希望写入的数据,马上就能读到,就不要使用CopyOnWrite
CopyOnWriteArraySet






















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











