






记录一下这篇文章的代码复现和学习过程,欢迎交流
首先要特别鸣谢我的好朋友——hxy女士,在整个复现过程中帮了我很多,她真的很优秀,感谢她百忙之中抽出时间教我,非常非常非常感谢她!!!!
一、数据集下载、处理
这篇文章用到的数据集分别是来自LSUN的卧室和教堂图像,以及来自FFHQ的人脸图像。每个子集包括70,000个随机选择的图像,归一化为256 × 256像素。下载方法有三种(参考文章:https://blog.csdn.net/qq_40859587/article/details/134563263):
1)https://pan.baidu.com/s/17cf-7ZktjbmitZUzt9KJTg#list/path=%2F 提取码:gyl5 (开VIP速度很快)
2)http://dl.yf.io/lsun/scenes/
3)https://github.com/fyu/lsun 用脚本-c传场景参数
我选择的方法是第一种。
下载好之后是这样的:(其实没必要全下下来,当时没想到这一点,好崩溃,盘全满了)
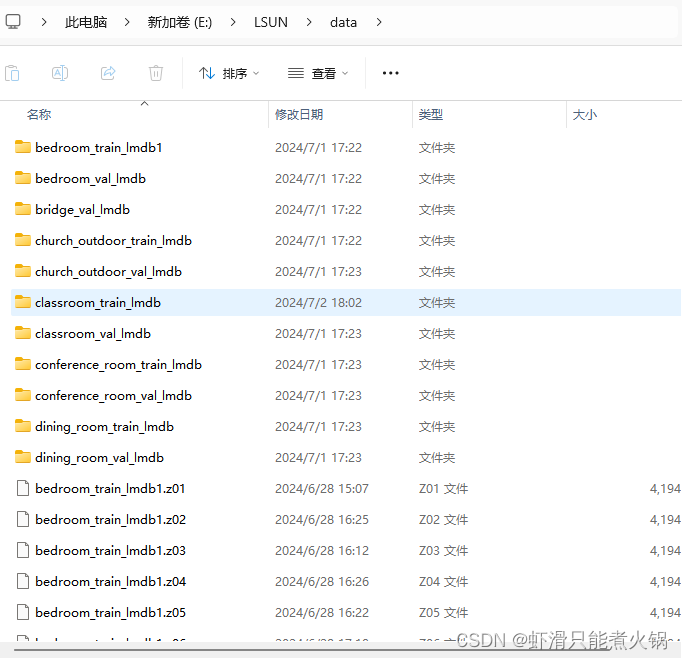
下载完成后,发现里面的数据是以.mdb格式呈现的,需要将其转换成图片格式。先下载一个LSUN 数据集文档和演示代码,需要用到里面的data.py文件,下载链接:
fyu/lsun: LSUN Dataset Documentation and Demo Code (github.com)
然后将data.py文件放在E:\IDEAS-master下【这一步很关键】,也就是我们下载的IDEAS这篇论文的源码,在github上可以搜到。接着打开pycharm,先安装三个python依赖项:numpy、lmdb、opencv,使用如下命令:【!!注意:安装前把代理一定要关掉,否则会报错】
pip install opencv
pip install lmdb
pip install opencv-python
报错截图:
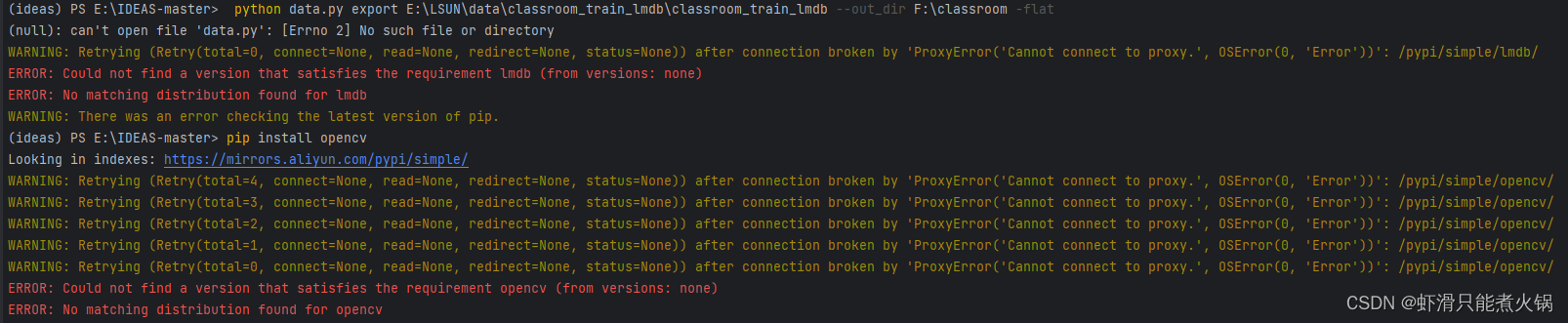
这里可以先安装一个清华源,再安装依赖项:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn opencv-python
安装完成之后就可以开始解压mdb文件了,下面是一个具体过程记录:
以classroom这个类别为例,先在F盘新建一个文件夹,用来存放转换后的图片。然后在pycharm的终端输入命令:(注意路径,我使用的是绝对路径,第一个路径是data.mdb和lock.mdb两个文件所在的位置)
python data.py export E:\LSUN\data\classroom_train_lmdb\classroom_train_lmdb --out_dir F:\classroom --flat
然后回车,可以看到已经开始转换了(转换时间好长……)
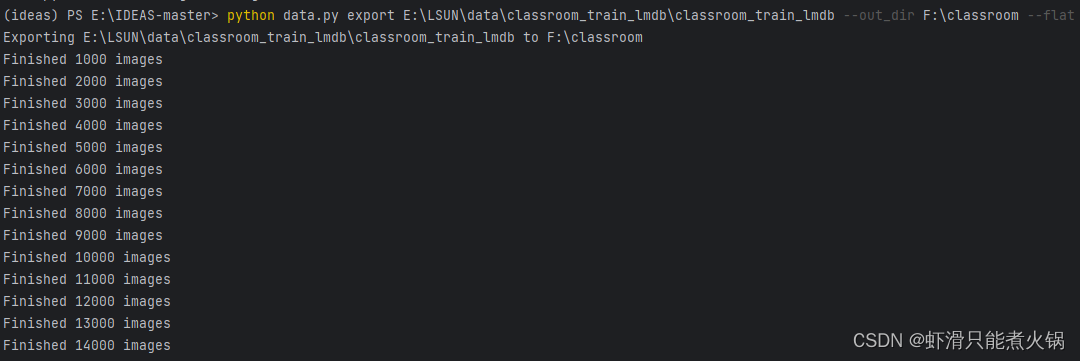
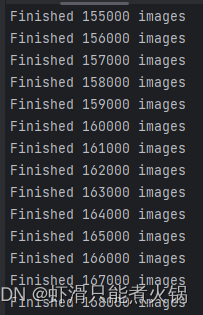 这个数据集还挺大的,将近17万张图片。
这个数据集还挺大的,将近17万张图片。
然后使用相同的方法转换classroom_val的图片:
1、F盘新建文件夹存放图片;2、pycharm终端输入命令;(这个只有300张图片,很快就转好了)
python data.py export E:\LSUN\data\classroom_val_lmdb\classroom_val_lmdb --out_dir F:\classroom_val --flat
![]()
我一共转换了classroom、church两个类别的*_train和*_val里的图片,完成后发现图片格式为webp,需要转换成jpg格式(好崩溃,还没跑代码,到这一步已经快要歇菜了……),又查询了很多博主写的文章,选择了这篇文章的方法:python 批量webp格式转换成jpg_python图片webq转jpg格式转换-CSDN博客
真的!很好用!亲测!!!下面是我运行时的代码截图和转换成功截图:
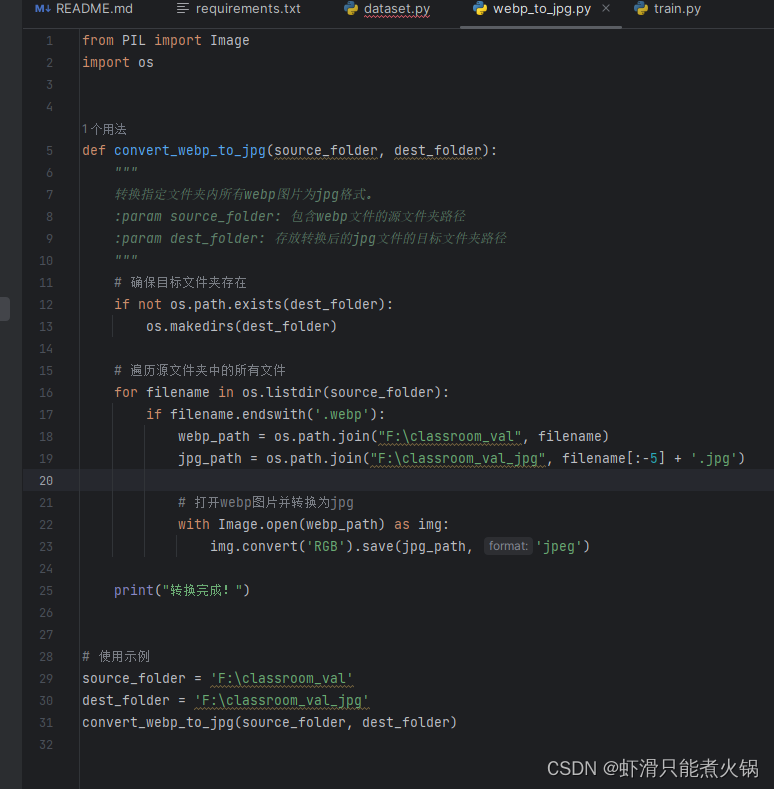
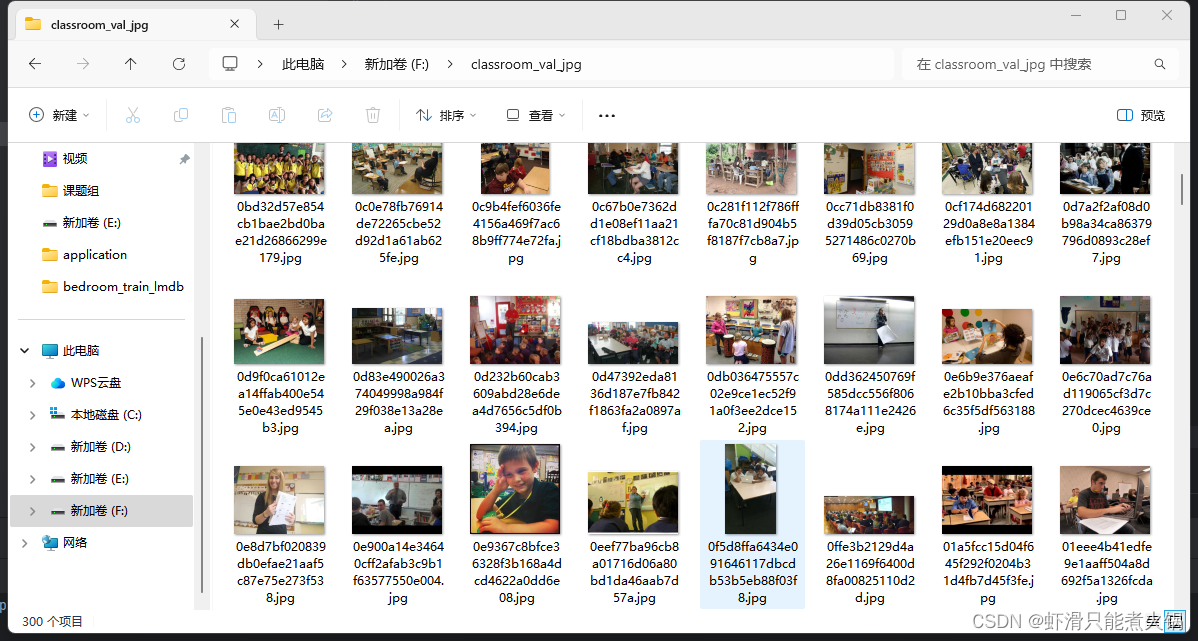
发现图片名称乱码,使用这篇文章的教程进行批量重命名:LSUN数据集读取和解压,mdb格式转换为jpg格式(保姆教程)-CSDN博客
具体操作过程:
1、新建一个txt文件,然后输入代码:
@Echo Off&SetLocal ENABLEDELAYEDEXPANSION
FOR %%a in (*) do (
set "name=%%a"
set "name=!name: (=!"
set "name=!name:)=!"
ren "%%a" "!name!"
)
exit然后保存,将txt改成bat格式,之后选中需要重命名的图片,右键重命名,对第一个命名为classroom_val,然后双击bat文件,即可完成。下面是重命名后的文件截图:

完成格式转换后,将数据集压缩包都上传到阿里云盘。(漫长且磨人的过程啊……)
二、数据集、代码上传
由于这篇文章的代码是在Linux上运行的,我的电脑是Windows,所以还是在AutoDL上租了一个服务器来跑:(提醒自己:服务器不用的时候一定要关机!!)

选择无卡开机(因为我们还没有正式跑代码,只是下载数据集,无卡也可以),在“快捷工具”中点击第二项“AutoPanel”,之后点击“公网网盘”,这里不用设置密码,直接点击确定,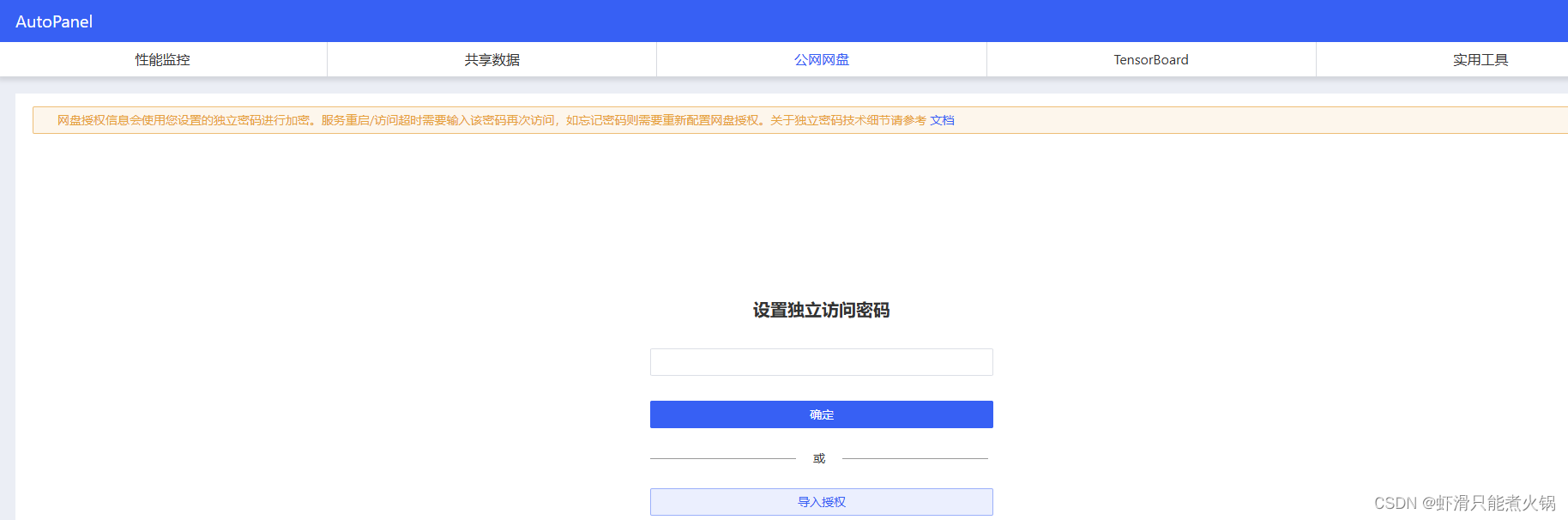
然后使用手机端阿里云盘APP扫码授权,接着就可以下载数据集压缩包了,下载到哪里了呢,可以看到在autodl-tmp文件夹里。(继续等吧,不过这个还挺快……)

同时,还下载了一个解压工具,具体参考这篇文章:【如果服务器终端可以直接解压zip文件,就不需要这个工具,这一步可以跳过】zip压缩包太大无法用unzip成功解压(保姆级)_please check that you have transferred or created -CSDN博客
将p7zip_16.02_src_all.tar.bz2同样地,上传到阿里云盘,再下载到租的服务器中。
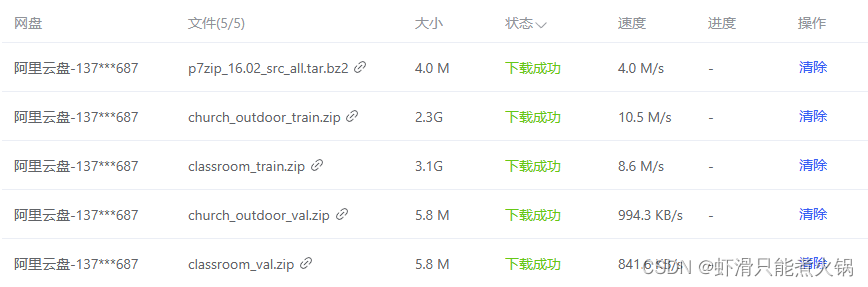
下载完成后,关掉autopanel,在jupyterlab的终端里解压这些包。【这一步由于没选好解压保存路径,数据集过大导致卡死,只能删了重来……】
在终端先输入cd autodl-tmp进入当前目录,然后输入解压命令:(这里的命令示例意思是将classroom_val.zip解压到classroom_val文件夹中,这个文件夹是我手动建的,为了保存不同类别的数据集图片)
unzip classroom_val.zip -d classroom_val
解压命令参考文章:linux系统中解压缩zip文件_linux能解压zip文件吗-CSDN博客
然后就可以开始训练了。
三、代码训练
使用如下命令进行训练:【各个含义在github上可以看到】
python train.py --exp_name ./experiments/1 --dataset_type normal --dataset_path ./classroom_train --num_iters 80000
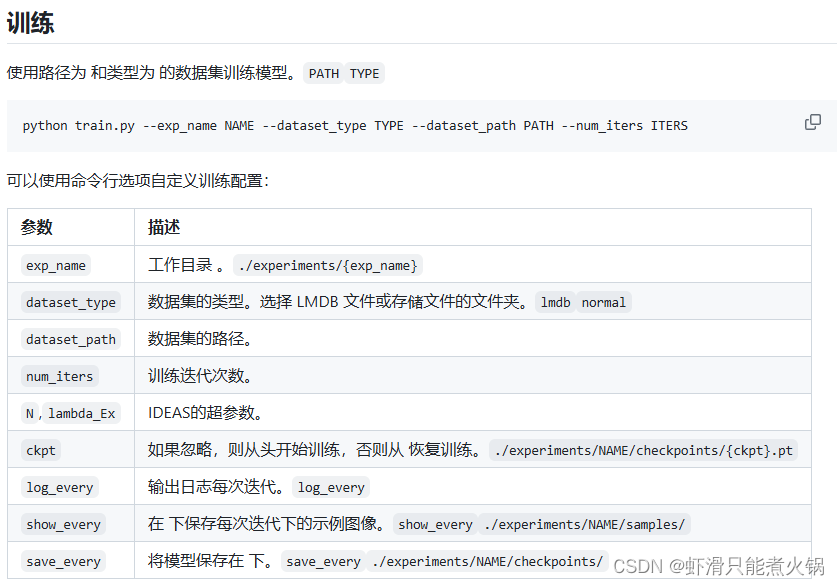
这个num_iters在代码中找到,它没有设置,建议至少80k次:

我最终训练的命令为:
python train.py --exp_name ./experiments/1 --dataset_type normal --dataset_path ../classroom_train --num_iters 80000
回车后发现缺少torchvision包:

好吧,再安装一下……(继续等……)

好的,然后每次尝试都发现有新的module没有安装,一步一步来吧……(下面是具体截图记录)





可以看到跑起来了【好开心好开心啊啊啊啊啊啊啊啊啊啊啊啊啊啊】

四、结果展示
还在跑……等跑完了再更新吧
【-----------------------------------------2024.07.06更新分割线-----------------------------------------------】
跑完的截图记录:

samples文件夹里的图片示例:(虽然看不懂……)

差不多复现结果就是这样,接下来就是学习看看具体的代码,了解含义,完成大作业报告啦。(不知道还会不会更新学习记录,谢谢大家看到这里)
-------------------------------------------【2024.07.11更新】分割线-------------------------------------------
上次只是跑了classroom_train的数据集,这次跑church_outdoor_train的【不知道是不是要分开训练,有大佬可以指点一下吗】,classroom_train跑出来的部分结果展示如下:



第一次跑代码,跑出来的结果不是很懂(不懂这四幅图分别代表什么含义),回去再看看论文吧……
然后今天在跑church_outdoor_train数据集的过程中遇到了一些报错,发现是需要重新安装ninja、lmdb、opencv_python这些库,此外还有一些简单的操作由于个人不太熟练导致报错,这里也整理出来,以备后续学习:
1、终端中切换到指定文件夹下,格式:cd ./切换相对路径
2、使用conda命令创建pytorch虚拟环境:conda create -n name python=3.x --name为环境名称
3、跑代码前记得先激活pytorch虚拟环境,格式:conda activate ideass --ideass是环境名称
训练代码:【注意“..”】
4、解压zip命令中要注意路径是否正确
最终训练命令如下:【注意路径是否正确】
python train.py --exp_name ./experiments/2 --dataset_type normal --dataset_path ../church_outdoor_train --num_iters 80000



跑完了,结果展示:



------------------------------------------【2024.07.12更新】分割线------------------------------------------------
hello,跑上瘾了,打算再跑一个桥梁的数据集,方法同上:
python train.py --exp_name ./experiments/3 --dataset_type normal --dataset_path ../ibridge_train --num_iters 80000

跑完结果展示:



---------------------------------------------【2024.07.15更新】分割线----------------------------------------------
五、代码学习
记录代码学习过程
(一)train.py
def train(
exp_name, # 实验名称
args, # 参数
loader, # 数据加载器
trainer, # 训练器
device # 设备(CPU或GPU)
):
# 将数据加载器包装在sample_data函数中,可能是为了从加载器中无限次获取样本,确保在每次迭代中都有数据供给。
loader = sample_data(loader)
# 初始化损失字典,用于存储训练过程中的损失值
loss_dict = {}
# 累积变量,用于指数移动平均的计算
accum = 0.5 ** (32 / (10 * 1000))
# 记录训练开始的时间
start_time = time.time()
# 主训练循环,从1开始迭代到args.num_iters
for idx in range(1, args.num_iters + 1):
# 计算当前的迭代索引
iter_idx = idx + args.start_iter
# 如果迭代索引超过了总迭代次数,打印"Done!"并结束训练
if iter_idx > args.num_iters:
print("Done!")
break
# 从数据加载器中获取下一个批次的样本(参考图像X)
X = next(loader)
# 将样本移动到指定的设备上(通常是GPU)
X = X.to(device)训练判别器部分的代码:
'''
Training Discriminators 训练判别器
'''
# 设置模型中各个模块的梯度计算状态
# 其中,编码器(E)、生成器(G)、结构生成器(Gstru)、编码器(Ex)的梯度计算被关闭(False),以确保它们在训练判别器时不更新参数。判别器(Dreal、Dco、Ddist)的梯度计算被打开(True),以便它在训练过程中更新参数。
requires_grad(trainer['E'], False)
requires_grad(trainer['G'], False)
requires_grad(trainer['Gstru'], False)
requires_grad(trainer['Ex'], False)
requires_grad(trainer['Dreal'], True)
requires_grad(trainer['Dco'], True)
requires_grad(trainer['Ddist'], True)
# 特征编码与生成
# 使用编码器E对输入图像X进行编码,得到结构S1和纹理T1
S1, T1 = trainer['E'](X)
# 随机生成一个秘密张量Z,尺寸与S1相同
Z = torch.rand(size=(S1.shape[0], args.N, S1.shape[2], S1.shape[3]),
dtype=torch.float).cuda() * 2 - 1
# 使用结构生成器Gstru对Z进行处理,生成新的结构S2
S2 = trainer['Gstru'](Z)
# 随机生成一个新的纹理T2,尺寸与T1相同
T2 = torch.rand_like(T1) * 2 - 1
# 图像合成
# 重建图像\hat{X}_1:使用S1和T1生成
hat_X1 = trainer['G'](S1, T1)
# 合成图像\hat{X}_2和\hat{X}_3:分别使用S2和T1、S2和T2生成
hat_X2 = trainer['G'](S2, T1)
hat_X3 = trainer['G'](S2, T2)
# 计算判别器损失L_{D,real}
# 将生成的假图像(hat_X1, hat_X2, hat_X3)拼接并输入Dreal,得到预测结果fake_pred
fake_pred = trainer['Dreal'](torch.cat((hat_X1, hat_X2, hat_X3), 0))
# 将真实图像X输入Dreal,得到预测结果real_pred
real_pred = trainer['Dreal'](X)
# 使用对数损失计算真实和假图像的损失D_real_loss
D_real_loss = d_logistic_loss(real_pred, fake_pred)
# 计算判别器Dco的纹理损失L_{D,texture}
# 将假图像hat_X2、真实图像X和参考图像X裁剪成小块
fake_patch = patchify_image(hat_X2, args.n_crop)
real_patch = patchify_image(X, args.n_crop)
ref_patch = patchify_image(X, args.ref_crop * args.n_crop)
# 将假图像块和参考图像块输入Dco,得到假图像的预测fake_texture_pred和参考输入ref_input
fake_texture_pred, ref_input = trainer['Dco'](fake_patch, ref_patch, ref_batch=args.ref_crop)
# 将真实图像块和参考输入再次输入Dco,得到真实图像的预测real_texture_pred
real_texture_pred, _ = trainer['Dco'](real_patch, ref_input=ref_input)
# 使用对数损失计算真实和假图像的纹理损失D_texture_loss
D_texture_loss = d_logistic_loss(real_texture_pred, fake_texture_pred)
# 计算判别器Ddist的分布损失L_{D,distribution}
# 将假图像的纹理T1和真实图像的纹理T2分别输入Ddist,得到假图像的预测fake_dist_pred和真实图像的预测real_dist_pred
fake_dist_pred = trainer['Ddist'](T1)
real_dist_pred = trainer['Ddist'](T2)
# 使用对数损失计算真实和假图像的分布损失D_dist_loss
D_dist_loss = d_logistic_loss(real_dist_pred, fake_dist_pred)
# 记录判别器D的损失并进行优化
# 将各个判别器的损失记录到loss_dict中
loss_dict["D_real_loss"] = D_real_loss
loss_dict["D_texture_loss"] = D_texture_loss
loss_dict["D_dist_loss"] = D_dist_loss
# 清空判别器优化器的梯度
trainer['d_optim'].zero_grad()
# 反向传播计算梯度
(D_real_loss + D_texture_loss + D_dist_loss).backward()
# 更新判别器的参数
trainer['d_optim'].step()
# 正则化,每隔一定的迭代次数进行一次正则化,防止模型过拟合
# 设置真实图像X、真实图像块real_patch和真实纹理T2的requires_grad属性为True,以便计算R1正则化损失
if iter_idx % args.d_reg_every == 0:
X.requires_grad = True
# 计算真实图像的预测结果,并使用d_r1_loss函数计算R1正则化损失
real_pred = trainer['Dreal'](X)
D_real_r1_loss = d_r1_loss(real_pred, X)
real_patch.requires_grad = True
real_patch_pred, _ = trainer['Dco'](real_patch, ref_patch, ref_batch=args.ref_crop)
D_texture_r1_loss = d_r1_loss(real_patch_pred, real_patch)
T2.requires_grad = True
real_uniform_pred = trainer['Ddist'](T2)
D_dist_r1_loss = d_r1_loss(real_uniform_pred, T2)
# 清空优化器的梯度
trainer['d_optim'].zero_grad()
# 计算所有R1正则化损失的总和,并进行反向传播计算梯度
r1_loss_sum = args.real_r1 / 3 * D_real_r1_loss * args.d_reg_every
r1_loss_sum += args.texture_r1 / 3 * D_texture_r1_loss * args.d_reg_every
r1_loss_sum += args.dist_r1 / 3 * D_dist_r1_loss * args.d_reg_every
r1_loss_sum.backward()
# 使用优化器更新判别器的参数
trainer['d_optim'].step()
# 将R1正则化损失记录到loss_dict字典中
loss_dict["D_real_r1_loss"] = D_real_r1_loss
loss_dict["D_texture_r1_loss"] = D_texture_r1_loss
loss_dict["D_dist_r1_loss"] = D_dist_r1_loss
训练主要组件部分的代码:
'''
Training main components.
'''
# 设置模型中各个组件的梯度计算状态,启用了编码器E、生成器G、结构生成器Gstru、提取器Ex的梯度计算,禁用了判别器Dreal、Dco、Ddist的梯度计算
requires_grad(trainer['E'], True)
requires_grad(trainer['G'], True)
requires_grad(trainer['Gstru'], True)
requires_grad(trainer['Ex'], True)
requires_grad(trainer['Dreal'], False)
requires_grad(trainer['Dco'], False)
requires_grad(trainer['Ddist'], False)
# 特征编码与生成
# 编码器E对输入图像X进行编码,得到结构特征S1和纹理特征T1
S1, T1 = trainer['E'](X)
# 生成随机的秘密张量Z
Z = torch.rand(size=(S1.shape[0], args.N, S1.shape[2], S1.shape[3]),
dtype=torch.float).cuda() * 2 - 1
# 使用结构生成器Gstru生成结构特征S2
S2 = trainer['Gstru'](Z)
# 生成与T1相同维度的随机纹理特征T2
T2 = torch.rand_like(T1) * 2 - 1
# 使用生成器G进行图像合成
# 使用S1和T1合成重建图像hat_X1
hat_X1 = trainer['G'](S1, T1)
# 使用S2和T1合成图像hat_X2
hat_X2 = trainer['G'](S2, T1)
# 使用S2和T2合成图像hat_X3
hat_X3 = trainer['G'](S2, T2)
# 损失计算
# L_{G,rec}
# G_rec_loss:重建图像hat_X1和输入图像X的L1损失
G_rec_loss = F.l1_loss(hat_X1, X)
# L_{G,real}
fake_pred = trainer['Dreal'](torch.cat((hat_X1, hat_X2, hat_X3), 0))
# G_real_loss:生成图像hat_X1、hat_X2、hat_X3的非饱和生成损失
G_real_loss = g_nonsaturating_loss(fake_pred)
# L_{E,dist}
fake_dist_pred = trainer['Ddist'](T1)
# E_dist_loss:纹理特征T1的非饱和生成损失
E_dist_loss = g_nonsaturating_loss(fake_dist_pred)
# L_{G,texture}
fake_patch = patchify_image(hat_X2, args.n_crop)
ref_patch = patchify_image(X, args.ref_crop * args.n_crop)
fake_patch_pred, _ = trainer['Dco'](fake_patch, ref_patch, ref_batch=args.ref_crop)
# G_texture_loss:生成图像hat_X2的图像块与参考图像块的非饱和生成损失
G_texture_loss = g_nonsaturating_loss(fake_patch_pred)
# L_{E,stru}
if iter_idx > args.num_iters * 0.8:
container_image = hat_X3
else:
container_image = hat_X2
# The recovered structure \hat{S}_2
hat_S2, _ = trainer['E'](container_image)
# E_stru_loss:从容器图像container_image中恢复的结构特征hat_S2与生成的结构特征S2的L1损失
E_stru_loss = F.l1_loss(hat_S2, S2)
# L_{REC}
# The extracted secret tensor \hat{Z}
hat_Z = trainer['Ex'](hat_S2)
# Ex_loss:从hat_S2中提取的秘密张量hat_Z与生成的秘密张量Z的L1损失
Ex_loss = F.l1_loss(hat_Z, Z)
# 损失记录
# 将各个损失记录到loss_dict字典中
loss_dict["G_rec_loss"] = G_rec_loss
loss_dict["G_real_loss"] = G_real_loss
loss_dict["G_texture_loss"] = G_texture_loss
loss_dict["E_dist_loss"] = E_dist_loss
loss_dict["E_stru_loss"] = E_stru_loss
loss_dict["Ex_loss"] = Ex_loss
# 计算生成器和编码器的总损失Loss_G、Loss_E和提取器的损失Loss_Ex
# L_G
Loss_G = G_rec_loss + G_texture_loss + 2 * G_real_loss
# L_E
Loss_E = E_dist_loss + E_stru_loss
# L_Ex
Loss_Ex = Ex_loss
# L_{total}:计算总损失Loss_total
Loss_total = Loss_G + Loss_E + args.lambda_Ex * Loss_Ex
# 优化生成器和编码器的参数
trainer['g_optim'].zero_grad()
Loss_total.backward(retain_graph=True)
trainer['g_optim'].step()
# 优化提取器的参数
trainer['ex_optim'].zero_grad()
Loss_Ex.backward()
trainer['ex_optim'].step()
# EMA更新:使用指数移动平均(EMA)更新模型参数E_ema、G_ema、Gstru_ema、Ex_ema
accumulate(trainer['E_ema'], trainer['E'], accum)
accumulate(trainer['G_ema'], trainer['G'], accum)
accumulate(trainer['Gstru_ema'], trainer['Gstru'], accum)
accumulate(trainer['Ex_ema'], trainer['Ex'], accum)
# Log日志记录(每隔一定的迭代次数记录一次损失值和训练时间,并打印和保存日志)
if iter_idx % args.log_every == 0:
G_rec_val = loss_dict["G_rec_loss"].mean().item()
G_texture_val = loss_dict["G_texture_loss"].mean().item()
G_real_val = loss_dict["G_real_loss"].mean().item()
E_dist_val = loss_dict["E_dist_loss"].mean().item()
E_stru_val = loss_dict["E_stru_loss"].mean().item()
Ex_val = loss_dict["Ex_loss"].mean().item()
now_time = time.time()
used_time = now_time - start_time
rest_time = (now_time - start_time) / idx * (args.num_iters - iter_idx)
log_output = f"[{iter_idx:07d}/{args.num_iters:07}] Total: {Loss_total.item():.4f}; " \
f"G,rec: {G_rec_val:.4f}; G,texture: {G_texture_val:.4f}; G,real: {G_real_val:.4f}; " \
f"E,dist: {E_dist_val:.4f}; E,stru: {E_stru_val:.4f}; Ex: {Ex_val:.4f} " \
f"used time: {time_change(used_time)};" \
f"rest time: {time_change(rest_time)}"
print(log_output, flush=True)
with open(f'{base_dir}/training_logs.txt', 'a') as fp:
fp.write(f'{log_output}\n')
# 输出样本:输出训练过程中生成的样本图像,并记录相关日志
# 每隔一定的迭代次数,采样生成图像并保存到指定目录
if iter_idx % args.show_every == 0:
with torch.no_grad():
# Sample a secret message and map it to secret tensor
S1, T1 = trainer['E_ema'](X)
# The secret message M
M = torch.randint(low=0, high=2, dtype=torch.float,
size=(S1.shape[0], args.N * S1.shape[2] * S1.shape[3]))
Z = message_to_tensor(M, sigma=1, delta=0.5).to(device)
Z = Z.reshape(shape=(S1.shape[0], args.N, S1.shape[2], S1.shape[3]))
# Generate structure S2 from the secret tensor
S2 = trainer['Gstru_ema'](Z)
# Sample a texture T2
T2 = torch.rand_like(T1) * 2 - 1
# Image Synthesis
hat_X1 = trainer['G_ema'](S1, T1)
hat_X2 = trainer['G_ema'](S2, T1)
hat_X3 = trainer['G_ema'](S2, T2)
# Secret Tensor Extracting
if iter_idx > args.num_iters * 0.8:
container_image = hat_X3
fake_img_used_as_container = 3
else:
container_image = hat_X2
fake_img_used_as_container = 2
hat_S2, _ = trainer['E_ema'](container_image)
hat_Z = trainer['Ex_ema'](hat_S2)
tensor_recovering_loss = torch.mean(torch.abs(hat_Z - Z))
hat_Z = hat_Z.reshape(shape=(Z.shape[0], -1))
# The extracted secret message \hat_{M}
hat_M = tensor_to_message(hat_Z, sigma=1)
BER = torch.mean(torch.abs(M - hat_M))
ACC = 1 - BER
log_output = f'[Testing {iter_idx:07d}/{args.num_iters:07d}] sigma=1 delta=50% ' \
f'using synthesised image \hatX_{fake_img_used_as_container} ' \
f'ACC of Msg: {ACC:.4f}; L1 loss of tensor: {tensor_recovering_loss:.4f}'
print(log_output, flush=True)
with open(f'{base_dir}/training_logs.txt', 'a') as fp:
fp.write(f'{log_output}\n')
sample = torch.cat((X, hat_X1, hat_X2, hat_X3), 0)
utils.save_image(
sample,
f"{sample_dir}/{iter_idx:07d}.png",
nrow=int(args.batch_size),
normalize=True,
range=(-1, 1),
)
print(f'Sample images are saved in experiments/{exp_name}/samples')
# 模型保存:每隔一定的迭代次数,将模型参数和训练状态保存到指定的检查点文件中
if iter_idx % args.save_every == 0:
trainer_ckpt = {}
for key in trainer.keys():
trainer_ckpt[key] = trainer[key].state_dict()
torch.save(
{
'iter_idx': iter_idx,
'N': args.N,
"trainer": trainer_ckpt,
"args": args,
},
f"{ckpt_dir}/{iter_idx}.pt",
)
print(f'Checkpoint is saved in experiments/{exp_name}/checkpoints')
整个训练流程的初始化和配置部分:(定义了训练过程中的各种参数,并初始化了所需的模型、优化器和数据加载器。)
if __name__ == "__main__":
# 设置设备和CUDA优化
device = "cuda"
torch.backends.cudnn.benchmark = True
# 解析命令行参数,通过命令行参数来配置实验名称、数据集路径、训练迭代次数、学习率、批次大小等超参数
parser = argparse.ArgumentParser()
# Working directory: experiments/exp_name
parser.add_argument("--exp_name", type=str, required=True)
# Training dataset
parser.add_argument("--dataset_path", type=str, required=True)
# Select 'lmdb' for the lmdb files, like LSUN (https://github.com/fyu/lsun)
# Select 'normal' for the dataset storing files (e.g., in PNG format) in a folder, like FFHQ (https://github.com/NVlabs/ffhq-dataset)
parser.add_argument("--dataset_type", choices=['lmdb', 'normal'], required=True)
# We recommend training at least 80k iterations
parser.add_argument("--num_iters", type=int, required=True)
# Hyper-parameters
parser.add_argument("--N", type=int, default=1)
parser.add_argument("--lambda_Ex", type=float, default=10)
# Resume training
parser.add_argument("--ckpt", type=str, default=None)
# Trainig parameters
parser.add_argument("--lr", type=float, default=0.002)
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--image_size", type=int, default=256)
parser.add_argument("--real_r1", type=float, default=10)
parser.add_argument("--texture_r1", type=float, default=1)
parser.add_argument("--dist_r1", type=float, default=1)
parser.add_argument("--ref_crop", type=int, default=4)
parser.add_argument("--n_crop", type=int, default=8)
parser.add_argument("--d_reg_every", type=int, default=16)
parser.add_argument("--channel", type=int, default=32)
parser.add_argument("--channel_multiplier", type=int, default=1)
parser.add_argument("--structure_channel", type=int, default=8)
parser.add_argument("--texture_channel", type=int, default=2048)
# Output logs every 'log_every' iterations
parser.add_argument("--log_every", type=int, default=200)
# Save example images every 'show_every' iterations
parser.add_argument("--show_every", type=int, default=1000)
# Save models every 'save_every' iterations
parser.add_argument("--save_every", type=int, default=200000)
args = parser.parse_args()
args.start_iter = 0
args.blur_kernel = (1, 3, 3, 1)
# 创建工作目录和日志文件
# 创建实验所需的目录结构,包括检查点和样本保存目录
base_dir = f"experiments/{args.exp_name}"
ckpt_dir = f"{base_dir}/checkpoints"
sample_dir = f"{base_dir}/samples"
os.makedirs(ckpt_dir, exist_ok=True)
os.makedirs(sample_dir, exist_ok=True)
# 保存训练配置到文本文件中
with open(f"{base_dir}/training_config.txt", "wt") as fp:
for k, v in vars(args).items():
fp.write(f'{k}: {v}\n')
fp.close()
# 清空之前的训练日志文件
with open(f"{base_dir}/training_logs.txt", "wt") as fp:
fp.close()
# 初始化模型(Init models):初始化训练所需的模型,包括编码器、生成器、结构生成器、提取器、以及多个判别器,同时初始化这些模型的EMA(指数移动平均)版本。
trainer = {
'E': init_model('DisentanglementEncoder', args).to(device),
'G': init_model('Generator', args).to(device),
'Gstru': init_model('StructureGenerator', args).to(device),
'Ex': init_model('TensorExtractor', args).to(device),
'Dreal': init_model('ImageLevelDiscriminator', args).to(device),
'Dco': init_model('CooccurenceDiscriminator', args).to(device),
'Ddist': init_model('DistributionDiscriminator', args).to(device),
'E_ema': init_model('DisentanglementEncoder', args).to(device),
'G_ema': init_model('Generator', args).to(device),
'Gstru_ema': init_model('StructureGenerator', args).to(device),
'Ex_ema': init_model('TensorExtractor', args).to(device),
}
# 将EMA模型设置为评估模式,并用初始模型参数更新EMA模型
trainer['E_ema'].eval()
trainer['G_ema'].eval()
trainer['Gstru_ema'].eval()
trainer['Ex_ema'].eval()
accumulate(trainer['E_ema'], trainer['E'], 0)
accumulate(trainer['G_ema'], trainer['G'], 0)
accumulate(trainer['Gstru_ema'], trainer['Gstru'], 0)
accumulate(trainer['Ex_ema'], trainer['Ex'], 0)
# 初始化生成器、提取器和判别器的优化器,分别设置不同的学习率和betas参数
trainer['g_optim'] = optim.Adam(
list(trainer['E'].parameters()) + list(trainer['G'].parameters()) + list(trainer['Gstru'].parameters()),
lr=args.lr,
betas=(0, 0.99),
)
trainer['ex_optim'] = optim.Adam(
trainer['Ex'].parameters(),
lr=args.lr,
betas=(0, 0.99),
)
d_reg_ratio = args.d_reg_every / (args.d_reg_every + 1)
trainer['d_optim'] = optim.Adam(
list(trainer['Dreal'].parameters()) + list(trainer['Dco'].parameters()) + list(trainer['Ddist'].parameters()),
lr=args.lr * d_reg_ratio,
betas=(0 ** d_reg_ratio, 0.99 ** d_reg_ratio),
)
# 加载检查点(可选):如果指定了检查点文件,则加载该文件中的模型参数和训练状态
# Resume training from the 'experiments/exp_name/checkpoints/{ckpt}.pt' file
if args.ckpt is not None:
print("load model:", args.ckpt)
ckpt = torch.load(f"{ckpt_dir}/{args.ckpt}.pt", map_location=lambda storage, loc: storage)
args.start_iter = ckpt['iter_idx']
for key in trainer.keys():
trainer[key].load_state_dict(ckpt['trainer'][key])
else:
args.start_iter = 0
# Init transforms:初始化数据增强变换(如随机水平翻转、归一化等)
transform = transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True),
]
)
# Init dataset and dataloader初始化数据集及其加载器
dataset = set_dataset(
type=args.dataset_type,
path=args.dataset_path,
transform=transform,
resolution=args.image_size
)
loader = data.DataLoader(
dataset=dataset,
batch_size=args.batch_size,
sampler=data_sampler(dataset=dataset, shuffle=True)
)
# 启动训练过程
print('Data Loaded')
exp_name = args.exp_name
# 调用train函数开始训练模型,传入实验名称、参数、数据加载器、训练器和设备
train(
exp_name=exp_name,
args=args,
loader=loader,
trainer=trainer,
device=device
)(二)models.py
1、EqualConvTranspose2d 类
EqualConvTranspose2d 是一个卷积转置层,使用等效学习率技术来稳定训练。
class EqualConvTranspose2d(nn.Module):
def __init__(
self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True
):
super().__init__()
self.weight = nn.Parameter(
torch.randn(in_channel, out_channel, kernel_size, kernel_size)
)
self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
self.stride = stride
self.padding = padding
if bias:
self.bias = nn.Parameter(torch.zeros(out_channel))
else:
self.bias = None
def forward(self, input):
out = F.conv_transpose2d(
input,
self.weight * self.scale,
bias=self.bias,
stride=self.stride,
padding=self.padding,
)
return out
def __repr__(self):
return (
f"{self.__class__.__name__}({self.weight.shape[0]}, {self.weight.shape[1]},"
f" {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})"
)
初始化:
self.weight:卷积核权重,初始化为高斯分布。self.scale:缩放因子,用于等效学习率,确保权重的方差保持稳定。self.stride和self.padding:卷积操作的步长和填充。self.bias:偏置项,可选,如果有偏置则初始化为零。前向传播:
F.conv_transpose2d:执行转置卷积操作,使用缩放后的权重和偏置。self.weight * self.scale:调整后的权重。
__repr__方法:
- 返回层的字符串表示,便于打印和调试。
2、ConvLayer 类
ConvLayer 是一个顺序卷积层,可以执行上采样、下采样和不同的填充方式。
class ConvLayer(nn.Sequential):
def __init__(
self,
in_channel,
out_channel,
kernel_size,
upsample=False,
downsample=False,
blur_kernel=(1, 3, 3, 1),
bias=True,
activate=True,
padding="zero",
tanh=False
):
layers = []
self.padding = 0
stride = 1
if downsample:
factor = 2
p = (len(blur_kernel) - factor) + (kernel_size - 1)
pad0 = (p + 1) // 2
pad1 = p // 2
layers.append(Blur(blur_kernel, pad=(pad0, pad1)))
stride = 2
if upsample:
layers.append(
EqualConvTranspose2d(
in_channel,
out_channel,
kernel_size,
padding=0,
stride=2,
bias=bias and not activate,
)
)
factor = 2
p = (len(blur_kernel) - factor) - (kernel_size - 1)
pad0 = (p + 1) // 2 + factor - 1
pad1 = p // 2 + 1
layers.append(Blur(blur_kernel, pad=(pad0, pad1)))
else:
if not downsample:
if padding == "zero":
self.padding = (kernel_size - 1) // 2
elif padding == "reflect":
padding = (kernel_size - 1) // 2
if padding > 0:
layers.append(nn.ReflectionPad2d(padding))
self.padding = 0
elif padding != "valid":
raise ValueError('Padding should be "zero", "reflect", or "valid"')
layers.append(
EqualConv2d(
in_channel,
out_channel,
kernel_size,
padding=self.padding,
stride=stride,
bias=bias and not activate,
)
)
if activate:
if tanh:
layers.append(nn.Tanh())
else:
if bias:
layers.append(FusedLeakyReLU(out_channel))
else:
layers.append(ScaledLeakyReLU(0.2))
super().__init__(*layers)
初始化:
- 根据上采样、下采样和填充选项动态构建层。
blur_kernel:模糊核,用于在下采样和上采样时减少伪影。stride和padding:控制卷积的步长和填充。activate:决定是否添加激活函数。上采样:
- 使用
EqualConvTranspose2d进行上采样。- 添加模糊层
Blur以减少伪影。下采样:
- 使用模糊层
Blur进行预处理。- 设置步长为 2 以实现下采样。
填充:
- 支持三种填充方式:“zero”、“reflect”和“valid”。
激活函数:
- 支持两种激活函数:
FusedLeakyReLU和ScaledLeakyReLU。- 还支持
tanh激活函数。
3、StyledResBlock 类
StyledResBlock 是一个带有样式输入的残差块,通常用于生成对抗网络(GAN)或图像风格转换任务。
class StyledResBlock(nn.Module):
def __init__(
self, in_channel, out_channel, style_dim, upsample, blur_kernel=(1, 3, 3, 1)
):
super().__init__()
self.conv1 = StyledConv(
in_channel,
out_channel,
3,
style_dim,
upsample=upsample,
blur_kernel=blur_kernel,
)
self.conv2 = StyledConv(out_channel, out_channel, 3, style_dim)
if upsample or in_channel != out_channel:
self.skip = ConvLayer(
in_channel,
out_channel,
1,
upsample=upsample,
blur_kernel=blur_kernel,
bias=False,
activate=False,
)
else:
self.skip = None
def forward(self, input, style, noise=None):
out = self.conv1(input, style, noise)
out = self.conv2(out, style, noise)
if self.skip is not None:
skip = self.skip(input)
else:
skip = input
return (out + skip) / math.sqrt(2)
初始化:
conv1和conv2:两个StyledConv层,用于带有样式输入的卷积操作。skip:用于跳跃连接,如果需要上采样或输入输出通道数不同,则添加一个ConvLayer层。前向传播:
conv1和conv2:依次执行两个卷积操作。skip:执行跳跃连接。- 返回加权平均后的结果,保留残差连接的优点。
4、ResBlock 类
ResBlock 是一个标准的残差块,常用于各种卷积神经网络。
class ResBlock(nn.Module):
def __init__(
self,
in_channel,
out_channel,
downsample,
padding="zero",
blur_kernel=(1, 3, 3, 1),
):
super().__init__()
self.conv1 = ConvLayer(in_channel, out_channel, 3, padding=padding)
self.conv2 = ConvLayer(
out_channel,
out_channel,
3,
downsample=downsample,
padding=padding,
blur_kernel=blur_kernel,
)
if downsample or in_channel != out_channel:
self.skip = ConvLayer(
in_channel,
out_channel,
1,
downsample=downsample,
blur_kernel=blur_kernel,
bias=False,
activate=False,
)
else:
self.skip = None
def forward(self, input):
out = self.conv1(input)
out = self.conv2(out)
if self.skip is not None:
skip = self.skip(input)
else:
skip = input
return (out + skip) / math.sqrt(2)
初始化:
conv1和conv2:两个ConvLayer层,执行卷积操作。skip:用于跳跃连接,如果需要下采样或输入输出通道数不同,则添加一个ConvLayer层。前向传播:
conv1和conv2:依次执行两个卷积操作。skip:执行跳跃连接。- 返回加权平均后的结果,保留残差连接的优点。
5、DisentanglementEncoder 类
DisentanglementEncoder 是一个用于图像特征分离的编码器,将图像分离成结构特征和纹理特征。
class DisentanglementEncoder(nn.Module):
def __init__(
self,
channel,
structure_channel=8,
texture_channel=2048,
blur_kernel=(1, 3, 3, 1),
):
super().__init__()
stem = [ConvLayer(3, channel, 1)]
in_channel = channel
for i in range(1, 5):
ch = channel * (2 ** i)
stem.append(ResBlock(in_channel, ch, downsample=True, padding="reflect", blur_kernel=blur_kernel))
in_channel = ch
self.stem = nn.Sequential(*stem)
self.structure = nn.Sequential(
ConvLayer(in_channel, in_channel, 1, blur_kernel=blur_kernel),
ConvLayer(in_channel, structure_channel, 1, blur_kernel=blur_kernel)
)
self.texture = nn.Sequential(
ConvLayer(in_channel, in_channel * 2, 3, downsample=True, padding="valid", blur_kernel=blur_kernel),
ConvLayer(in_channel * 2, in_channel * 4, 3, downsample=True, padding="valid", blur_kernel=blur_kernel),
nn.AdaptiveAvgPool2d(1),
ConvLayer(in_channel * 4, texture_channel, 1, tanh=True, blur_kernel=blur_kernel),
)
def forward(self, input):
out = self.stem(input)
structure = self.structure(out)
texture = torch.flatten(self.texture(out), 1)
return structure, texture
初始化:
stem:由多个ResBlock组成的主干网络,逐步下采样输入图像。structure:用于提取结构特征的网络,由两个ConvLayer层组成。texture:用于提取纹理特征的网络,包括下采样卷积层和自适应平均池化层,最后输出一个tanh激活的卷积层。前向传播:
stem:通过主干网络提取初步特征。structure:提取结构特征。texture:提取纹理特征,并展平为一维向量。
6、Generator 类
Generator 类用于生成图像,其输入是结构特征和纹理特征,输出是生成的图像。
class Generator(nn.Module):
def __init__(
self,
channel,
structure_channel=8,
texture_channel=2048,
blur_kernel=(1, 3, 3, 1),
):
super().__init__()
ch_multiplier = (4, 8, 12, 16, 16, 16, 8, 4)
upsample = (False, False, False, False, True, True, True, True)
self.layers = nn.ModuleList()
in_ch = structure_channel
for ch_mul, up in zip(ch_multiplier, upsample):
self.layers.append(
StyledResBlock(
in_ch, channel * ch_mul, texture_channel, up, blur_kernel
)
)
in_ch = channel * ch_mul
self.to_rgb = ConvLayer(in_ch, 3, 1, activate=False)
def forward(self, structure, texture, noises=None):
if noises is None:
noises = [None] * len(self.layers)
out = structure
for layer, noise in zip(self.layers, noises):
out = layer(out, texture, noise)
out = self.to_rgb(out)
return out
初始化:
ch_multiplier和upsample:分别定义了每层的通道数倍数和是否上采样。self.layers:包含多个StyledResBlock层,每层可以选择是否进行上采样。to_rgb:将最后一层的输出转化为 RGB 图像。前向传播:
- 初始化
noises:如果没有提供噪声,则初始化为None。- 依次通过每个
StyledResBlock层。- 最后通过
to_rgb层将特征转换为 RGB 图像。
7、StructureGenerator 类
StructureGenerator 类用于生成结构特征,其输入是噪声,输出是结构特征。
class StructureGenerator(nn.Module):
def __init__(
self,
channel,
N=1,
structure_channel=8,
blur_kernel=(1, 3, 3, 1),
):
super().__init__()
stem = [ConvLayer(N, channel, 1, blur_kernel=blur_kernel)]
stem.append(ResBlock(channel, channel * 2, downsample=False, padding="reflect", blur_kernel=blur_kernel))
stem.append(ResBlock(channel * 2, channel * 4, downsample=False, padding="reflect", blur_kernel=blur_kernel))
stem.append(ResBlock(channel * 4, channel * 2, downsample=False, padding="reflect", blur_kernel=blur_kernel))
stem.append(ConvLayer(channel * 2, structure_channel, 1, blur_kernel=blur_kernel))
self.structure = nn.Sequential(*stem)
def forward(self, noise):
out = self.structure(noise)
return out
初始化:
stem:包含多个ConvLayer和ResBlock层,用于逐步提取和处理特征。前向传播:
- 输入噪声通过
self.structure层,逐步提取和处理,输出结构特征。
8、ImageLevelDiscriminator 类
ImageLevelDiscriminator 类用于判别生成图像的真实性,其输入是图像,输出是真实性评分。
class ImageLevelDiscriminator(nn.Module):
def __init__(self, size, channel_multiplier=1, blur_kernel=(1, 3, 3, 1)):
super().__init__()
channels = {
4: 512,
8: 512,
16: 512,
32: 512,
64: 256 * channel_multiplier,
128: 128 * channel_multiplier,
256: 64 * channel_multiplier,
512: 32 * channel_multiplier,
1024: 16 * channel_multiplier,
}
convs = [ConvLayer(3, channels[size], 1, blur_kernel=blur_kernel)]
log_size = int(math.log(size, 2))
in_channel = channels[size]
for i in range(log_size, 2, -1):
out_channel = channels[2 ** (i - 1)]
convs.append(ResBlock(in_channel, out_channel, downsample=True, blur_kernel=blur_kernel))
in_channel = out_channel
self.convs = nn.Sequential(*convs)
self.final_conv = ConvLayer(in_channel, channels[4], 3, blur_kernel=blur_kernel)
self.final_linear = nn.Sequential(
EqualLinear(channels[4] * 4 * 4, channels[4], activation="fused_lrelu"),
EqualLinear(channels[4], 1),
)
def forward(self, input):
out = self.convs(input)
out = self.final_conv(out)
out = out.view(out.shape[0], -1)
out = self.final_linear(out)
return out
初始化:
channels:定义了每个分辨率对应的通道数。convs:包含多个ConvLayer和ResBlock层,逐步下采样和提取特征。final_conv和final_linear:最终卷积层和全连接层,用于输出真实性评分。前向传播:
- 输入图像通过
self.convs层,逐步下采样和提取特征。- 最后通过
final_conv和final_linear层输出真实性评分。
9、CooccurenceDiscriminator 类
CooccurenceDiscriminator 类用于比较输入图像和参考图像之间的特征相似性,输出一个判别结果。
class CooccurenceDiscriminator(nn.Module):
def __init__(self, channel, size=256):
super().__init__()
encoder = [ConvLayer(3, channel, 1)]
ch_multiplier = (2, 4, 8, 12, 12, 24)
downsample = (True, True, True, True, True, False)
in_ch = channel
for ch_mul, down in zip(ch_multiplier, downsample):
encoder.append(ResBlock(in_ch, channel * ch_mul, down))
in_ch = channel * ch_mul
if size > 511:
k_size = 3
feat_size = 2 * 2
else:
k_size = 2
feat_size = 1 * 1
encoder.append(ConvLayer(in_ch, channel * 12, k_size, padding="valid"))
self.encoder = nn.Sequential(*encoder)
self.linear = nn.Sequential(
EqualLinear(
channel * 12 * 2 * feat_size, channel * 32, activation="fused_lrelu"
),
EqualLinear(channel * 32, channel * 32, activation="fused_lrelu"),
EqualLinear(channel * 32, channel * 16, activation="fused_lrelu"),
EqualLinear(channel * 16, 1),
)
def forward(self, input, reference=None, ref_batch=None, ref_input=None):
out_input = self.encoder(input)
if ref_input is None:
ref_input = self.encoder(reference)
_, channel, height, width = ref_input.shape
ref_input = ref_input.view(-1, ref_batch, channel, height, width)
ref_input = ref_input.mean(1)
out = torch.cat((out_input, ref_input), 1)
out = torch.flatten(out, 1)
out = self.linear(out)
return out, ref_input
初始化:
encoder:包含多个ConvLayer和ResBlock层,用于逐步提取和处理特征。linear:全连接层序列,用于输出最终的判别结果。前向传播:
input通过encoder层得到out_input。- 如果
ref_input为空,则将reference图像也通过encoder层处理,并计算其平均值。- 将
out_input和ref_input连接起来,展平后通过linear层得到最终的判别结果out。
10、DistributionDiscriminator 类
DistributionDiscriminator 类用于对纹理特征进行分布判别。
class DistributionDiscriminator(nn.Module):
def __init__(self, texture_channel=2048):
super().__init__()
self.model = nn.Sequential(
EqualLinear(texture_channel, texture_channel // 4, activation="fused_lrelu"),
EqualLinear(texture_channel // 4, texture_channel // 16, activation="fused_lrelu"),
EqualLinear(texture_channel // 16, texture_channel // 64, activation="fused_lrelu"),
EqualLinear(texture_channel // 64, 1, activation="fused_lrelu")
)
def forward(self, input):
out = self.model(input)
return out
初始化:
model:包含多个全连接层,用于对纹理特征进行处理和判别。前向传播:
- 输入
input通过model层得到输出out,表示纹理特征的判别结果。
11、TensorExtractor 类
TensorExtractor 类用于从结构特征中提取张量。
class TensorExtractor(nn.Module):
def __init__(
self,
channel,
N=1,
structure_channel=8,
blur_kernel=(1, 3, 3, 1),
):
super().__init__()
stem = [ConvLayer(structure_channel, channel * 2, 1, blur_kernel=blur_kernel)]
stem.append(ResBlock(channel * 2, channel * 4, downsample=False, padding="reflect", blur_kernel=blur_kernel))
stem.append(ResBlock(channel * 4, channel * 2, downsample=False, padding="reflect", blur_kernel=blur_kernel))
stem.append(ResBlock(channel * 2, channel, downsample=False, padding="reflect", blur_kernel=blur_kernel))
stem.append(ConvLayer(channel, N, 1, blur_kernel=blur_kernel))
self.extract = nn.Sequential(*stem)
def forward(self, input):
out = self.extract(input)
return out
初始化:
stem:包含多个ConvLayer和ResBlock层,用于逐步提取和处理特征。前向传播:
- 输入
input通过extract层逐步提取特征,最终输出out。
12、init_model 函数
根据传入的 model 字符串和 args 参数初始化并返回相应的模型对象。
- 参数说明:
model:字符串,指定要初始化的模型类型。args:包含模型初始化所需的参数的命名空间(可能是 argparse.Namespace 对象或类似的结构)。
def init_model(model, args):
if model == 'DisentanglementEncoder':
return DisentanglementEncoder(
channel=args.channel,
structure_channel=args.structure_channel,
texture_channel=args.texture_channel,
blur_kernel=args.blur_kernel
)
elif model == 'Generator':
return Generator(
channel=args.channel,
structure_channel=args.structure_channel,
texture_channel=args.texture_channel,
blur_kernel=args.blur_kernel
)
elif model == 'StructureGenerator':
return StructureGenerator(
channel=args.channel,
N=args.N,
structure_channel=args.structure_channel,
blur_kernel=args.blur_kernel
)
elif model == 'ImageLevelDiscriminator':
return ImageLevelDiscriminator(
size=args.image_size,
channel_multiplier=args.channel_multiplier,
blur_kernel=args.blur_kernel
)
elif model == 'CooccurenceDiscriminator':
return CooccurenceDiscriminator(
channel=args.channel,
size=args.image_size
)
elif model == 'DistributionDiscriminator':
return DistributionDiscriminator(
texture_channel=args.texture_channel
)
elif model == 'TensorExtractor':
return TensorExtractor(
channel=args.channel,
N=args.N,
structure_channel=args.structure_channel,
blur_kernel=args.blur_kernel
)
else:
raise NotImplementedError
分支解析:
- 根据
model字符串的不同值,选择不同的模型进行初始化并返回。- 每个分支根据对应的模型类型创建相应的实例,并传入相应的参数
args。模型初始化:
- 每个分支都调用对应模型类的构造函数,并根据
args中的具体参数来初始化模型。- 参数包括但不限于
channel(通道数)、structure_channel(结构通道数)、texture_channel(纹理通道数)、blur_kernel(模糊核大小)、size(图像尺寸)、channel_multiplier(通道倍增因子)等。异常处理:
- 如果传入的
model不在预定义的模型类型中,则抛出NotImplementedError异常。
(三)dataset.py
定义了两个自定义的 PyTorch 数据集类 LMDBDataset 和 NormalDataset,以及一个工具函数 set_dataset 来根据指定的数据集类型创建相应的数据集实例。
1、LMDBDataset 类
功能是从 LMDB 数据库中加载图像数据。
class LMDBDataset(Dataset):
def __init__(self, path, transform, resolution=256, max_num=70000):
self.env = lmdb.open(
path,
max_readers=32,
readonly=True,
lock=False,
readahead=False,
meminit=False,
)
if not self.env:
raise IOError('Cannot open lmdb dataset', path)
self.keys = []
with self.env.begin(write=False) as txn:
cursor = txn.cursor()
for idx, (key, _) in enumerate(cursor):
self.keys.append(key)
if idx > max_num:
break
self.length = len(self.keys)
self.resolution = resolution
self.transform = transform
def __len__(self):
return self.length
def __getitem__(self, index):
with self.env.begin(write=False) as txn:
key = self.keys[index]
img_bytes = txn.get(key)
buffer = BytesIO(img_bytes)
img = Image.open(buffer).resize((self.resolution, self.resolution))
img = self.transform(img)
return img
构造函数
__init__:
path:LMDB 数据库的路径。transform:图像转换函数,用于对图像进行预处理。resolution:图像的分辨率,默认为 256x256。max_num:最大加载的图像数量,默认为 70000。初始化过程:
- 使用
lmdb.open打开 LMDB 数据库,并设置一些参数如max_readers、readonly等。- 如果无法打开数据库,抛出
IOError异常。- 通过
self.env.begin(write=False)获取事务,并遍历数据库的所有键(图像的唯一标识)。- 将键存储在
self.keys列表中,同时限制加载的图像数量为max_num。- 设置
self.length为数据集的长度(图像数量)、保存resolution和transform函数。
__len__方法:
- 返回数据集的长度,即
self.length,表示图像的总数。
__getitem__方法:
- 根据索引
index从 LMDB 数据库中读取对应的图像数据。- 使用
self.env.begin(write=False)打开事务,并通过键key获取图像的字节数据img_bytes。- 将图像字节数据读取到
BytesIO缓冲区中,并使用PIL.Image.open打开图像。- 调整图像大小为
self.resolution x self.resolution,然后应用transform进行图像预处理。- 返回预处理后的图像
img。
2、NormalDataset 类
功能是从普通的图像文件夹加载图像数据。
class NormalDataset(Dataset):
def __init__(self, path, transform, resolution=256, max_num=70000):
self.files = []
listed_files = sorted(list(list_files(path)))
for i in range(min(max_num, len(listed_files))):
file = listed_files[i]
if any(file.lower().endswith(ext) for ext in IMG_EXTENSIONS):
self.files.append(file)
self.resolution = resolution
self.transform = transform
self.length = len(self.files)
def __len__(self):
return self.length
def __getitem__(self, index):
img = Image.open(self.files[index]).resize((self.resolution, self.resolution))
img = self.transform(img)
return img
构造函数
__init__:
path:图像文件夹的路径。transform:图像转换函数,用于对图像进行预处理。resolution:图像的分辨率,默认为 256x256。max_num:最大加载的图像数量,默认为 70000。初始化过程:
- 使用
imutils.paths.list_files函数列出指定路径下的所有文件,并按名称排序。- 遍历列表中的文件,如果文件的扩展名在
IMG_EXTENSIONS中(支持的图像格式),则将文件路径添加到self.files列表中。- 设置
self.resolution、self.transform和self.length分别为图像分辨率、转换函数和数据集的长度。
__len__方法:
- 返回数据集的长度,即
self.length,表示图像的总数。
__getitem__方法:
- 根据索引
index从self.files列表中读取对应的图像文件路径。- 使用
PIL.Image.open打开图像,并调整大小为self.resolution x self.resolution。- 应用
transform进行图像预处理。- 返回预处理后的图像
img。
3、set_dataset 函数
功能是根据指定的数据集类型 type 创建相应的数据集实例。
def set_dataset(type, path, transform, resolution):
datatype = None
if type == 'lmdb':
datatype = LMDBDataset
elif type == 'normal':
datatype = NormalDataset
else:
raise NotImplementedError
return datatype(path, transform, resolution)
参数:
type:字符串,指定数据集类型,可以是'lmdb'或'normal'。path:数据集的路径。transform:图像转换函数。resolution:图像分辨率。返回值:
- 根据
type的不同值选择并返回对应的数据集实例。异常处理:
- 如果
type不是'lmdb'或'normal',则抛出NotImplementedError异常。
(四)utils.py
1、时间格式转换 (time_change)
- 功能:将秒数转换为小时、分钟和秒的字符串格式。
- 细节:
- 根据输入的
time_init计算小时、分钟和秒数。- 将计算结果以字符串形式拼接成格式化的时间字符串并返回。
def time_change(time_init):
time_list = []
if time_init / 3600 > 1:
time_h = int(time_init / 3600)
time_m = int((time_init - time_h * 3600) / 60)
time_s = int(time_init - time_h * 3600 - time_m * 60)
time_list.append(str(time_h))
time_list.append('h ')
time_list.append(str(time_m))
time_list.append('m ')
elif time_init / 60 > 1:
time_m = int(time_init / 60)
time_s = int(time_init - time_m * 60)
time_list.append(str(time_m))
time_list.append('m ')
else:
time_s = int(time_init)
time_list.append(str(time_s))
time_list.append('s')
time_str = ''.join(time_list)
return time_str2、训练工具 (data_sampler, requires_grad, accumulate, sample_data)
data_sampler(dataset, shuffle):
- 根据
shuffle参数返回对应的数据采样器,可以是随机采样器或顺序采样器。
requires_grad(model, flag=True):
- 设置模型
model中所有参数的requires_grad属性为flag。
accumulate(model1, model2, decay=0.999):
- 对
model1的参数进行滑动平均更新,更新系数为decay,通过与model2的参数进行加权平均实现。
sample_data(loader):
- 从数据加载器
loader中无限循环地产生数据批次。
'''
Training tools
'''
def data_sampler(dataset, shuffle):
if shuffle:
return data.RandomSampler(dataset)
else:
return data.SequentialSampler(dataset)
def requires_grad(model, flag=True):
for p in model.parameters():
p.requires_grad = flag
def accumulate(model1, model2, decay=0.999):
par1 = dict(model1.named_parameters())
par2 = dict(model2.named_parameters())
for k in par1.keys():
par1[k].data.mul_(decay).add_(par2[k].data, alpha=1 - decay)
def sample_data(loader):
while True:
for batch in loader:
yield batch3、二进制消息与张量之间的映射 (message_to_tensor, tensor_to_message)
message_to_tensor(message, sigma, delta):
- 将二进制消息
message转换为张量。sigma控制消息的编码密度,delta控制噪声的幅度。- 返回一个张量,表示编码后的消息。
tensor_to_message(secret_tensor, sigma):
- 将张量
secret_tensor反向解码为二进制消息。- 返回一个二进制消息的张量。
'''
Mapping between binary messages and floating tensors
'''
def message_to_tensor(message, sigma, delta):
secret_tensor = torch.zeros(size=(message.shape[0], message.shape[1] // sigma))
step = 2 / 2 ** sigma
random_interval_size = step * delta
message_nums = torch.zeros_like(secret_tensor)
for i in range(sigma):
message_nums += message[:, i::sigma] * 2 ** (sigma - i - 1)
secret_tensor = step * (message_nums + 0.5) - 1
secret_tensor = secret_tensor + (torch.rand_like(secret_tensor) * random_interval_size * 2 - random_interval_size)
return secret_tensor
def tensor_to_message(secret_tensor, sigma):
message = torch.zeros(size=(secret_tensor.shape[0], secret_tensor.shape[1] * sigma))
step = 2 / 2 ** sigma
secret_tensor = torch.clamp(secret_tensor, min=-1, max=1) + 1
message_nums = secret_tensor / step
zeros = torch.zeros_like(message_nums)
ones = torch.ones_like(message_nums)
for i in range(sigma):
zero_one_map = torch.where(message_nums >= 2 ** (sigma - i - 1), ones, zeros)
message[:, i::sigma] = zero_one_map
message_nums -= zero_one_map * 2 ** (sigma - i - 1)
return message4、损失函数 (d_logistic_loss, d_r1_loss, g_nonsaturating_loss)
d_logistic_loss(real_pred, fake_pred):
- 计算生成对抗网络的 logistic 损失函数,用于判别器。
- 返回实部和虚部的损失均值。
d_r1_loss(real_pred, real_img):
- 计算梯度惩罚损失函数,用于判别器。
- 返回梯度惩罚的值。
g_nonsaturating_loss(fake_pred):
- 计算生成对抗网络的非饱和损失函数,用于生成器。
- 返回损失值。
'''
Loss functions
'''
def d_logistic_loss(real_pred, fake_pred):
real_loss = F.softplus(-real_pred)
fake_loss = F.softplus(fake_pred)
return real_loss.mean() + fake_loss.mean()
def d_r1_loss(real_pred, real_img):
(grad_real,) = autograd.grad(
outputs=real_pred.sum(), inputs=real_img, create_graph=True
)
grad_penalty = grad_real.pow(2).reshape(grad_real.shape[0], -1).sum(1).mean()
return grad_penalty
def g_nonsaturating_loss(fake_pred):
loss = F.softplus(-fake_pred).mean()
return loss5、图像裁剪操作 (patchify_image)
patchify_image(img, n_crop, min_size=1/8, max_size=1/4):
- 将输入的图像
img裁剪成多个尺寸不同的小块。n_crop控制裁剪的数量,min_size和max_size控制裁剪块的最小和最大尺寸。- 返回裁剪后的图像小块的张量。
def patchify_image(img, n_crop, min_size=1 / 8, max_size=1 / 4):
crop_size = torch.rand(n_crop) * (max_size - min_size) + min_size
batch, channel, height, width = img.shape
target_h = int(height * max_size)
target_w = int(width * max_size)
crop_h = (crop_size * height).type(torch.int64).tolist()
crop_w = (crop_size * width).type(torch.int64).tolist()
patches = []
for c_h, c_w in zip(crop_h, crop_w):
c_y = random.randrange(0, height - c_h)
c_x = random.randrange(0, width - c_w)
cropped = img[:, :, c_y: c_y + c_h, c_x: c_x + c_w]
cropped = F.interpolate(
cropped, size=(target_h, target_w), mode="bilinear", align_corners=False
)
patches.append(cropped)
patches = torch.stack(patches, 1).view(-1, channel, target_h, target_w)
return patches(五)stylegan2-model.py
这部分和前面的models.py需要区分开(gpt已经生成了,就顺带贴在这里了)
1、PixelNorm 模块
# PixelNorm 模块
class PixelNorm(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
return input * torch.rsqrt(torch.mean(input ** 2, dim=1, keepdim=True) + 1e-8)PixelNorm类是一个自定义的PyTorch模块,用于对输入特征图进行像素归一化。该模块没有可学习参数,仅在前向传播中进行操作。
__init__方法:初始化模块,调用父类的初始化方法。forward方法:实现前向传播。
- 计算输入张量的平方并在第一个维度上求均值(
dim=1)。- 加上一个非常小的值
1e-8以防止除零错误。- 对均值取平方根的倒数(
rsqrt),并与输入张量逐元素相乘,实现归一化。
2、make_kernel 函数
def make_kernel(k):
k = torch.tensor(k, dtype=torch.float32)
if k.ndim == 1:
k = k[None, :] * k[:, None]
k /= k.sum()
return kmake_kernel函数将一维或二维的核(kernel)转换为二维卷积核,并进行归一化处理。
- 将输入的核转换为
torch.float32类型的张量。- 如果输入是一维的,将其转换为二维的外积形式。
- 对核进行归一化,使其元素和为1。
3. Upsample 模块
class Upsample(nn.Module):
def __init__(self, kernel, factor=2):
super().__init__()
self.factor = factor
kernel = make_kernel(kernel) * (factor ** 2)
self.register_buffer("kernel", kernel)
p = kernel.shape[0] - factor
pad0 = (p + 1) // 2 + factor - 1
pad1 = p // 2
self.pad = (pad0, pad1)
def forward(self, input):
out = upfirdn2d(input, self.kernel, up=self.factor, down=1, pad=self.pad)
return outUpsample类用于对输入特征图进行上采样操作。
__init__方法:初始化模块。
- 调用
make_kernel函数生成并归一化卷积核,并乘以factor的平方以调整核的强度。- 使用
register_buffer方法将卷积核注册为不可学习的缓冲区。- 计算填充(padding)的大小,并保存为实例变量
self.pad。forward方法:实现前向传播。
- 调用
upfirdn2d函数进行上采样,传入输入特征图、卷积核、上采样因子、下采样因子和填充。
4. Downsample 模块
class Downsample(nn.Module):
def __init__(self, kernel, factor=2):
super().__init__()
self.factor = factor
kernel = make_kernel(kernel)
self.register_buffer("kernel", kernel)
p = kernel.shape[0] - factor
pad0 = (p + 1) // 2
pad1 = p // 2
self.pad = (pad0, pad1)
def forward(self, input):
out = upfirdn2d(input, self.kernel, up=1, down=self.factor, pad=self.pad)
return outDownsample类用于对输入特征图进行下采样操作。
__init__方法:初始化模块。
- 调用
make_kernel函数生成并归一化卷积核。- 使用
register_buffer方法将卷积核注册为不可学习的缓冲区。- 计算填充(padding)的大小,并保存为实例变量
self.pad。forward方法:实现前向传播。
- 调用
upfirdn2d函数进行下采样,传入输入特征图、卷积核、上采样因子、下采样因子和填充。
5、Blur 模块
class Blur(nn.Module):
def __init__(self, kernel, pad, upsample_factor=1):
super().__init__()
kernel = make_kernel(kernel)
if upsample_factor > 1:
kernel = kernel * (upsample_factor ** 2)
self.register_buffer("kernel", kernel)
self.pad = pad
def forward(self, input):
out = upfirdn2d(input, self.kernel, pad=self.pad)
return out
Blur类继承自nn.Module,用于应用模糊操作。__init__方法初始化模块,接受kernel(核大小)、pad(填充大小)、upsample_factor(上采样因子,默认为 1)作为参数。make_kernel函数用于生成核。- 如果
upsample_factor大于 1,则扩展核的大小。- 使用
register_buffer方法注册kernel为模块的缓冲区。self.pad保存填充大小。forward方法实现模块的前向传播,调用了upfirdn2d函数,对输入input应用二维上采样卷积操作,并返回结果out。
6、EqualConv2d 模块
class EqualConv2d(nn.Module):
def __init__(
self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True
):
super().__init__()
self.weight = nn.Parameter(
torch.randn(out_channel, in_channel, kernel_size, kernel_size)
)
self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
self.stride = stride
self.padding = padding
if bias:
self.bias = nn.Parameter(torch.zeros(out_channel))
else:
self.bias = None
def forward(self, input):
out = F.conv2d(
input,
self.weight * self.scale,
bias=self.bias,
stride=self.stride,
padding=self.padding,
)
return out
def __repr__(self):
return (
f"{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]},"
f" {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})"
)EqualConv2d 类继承自 nn.Module,实现了具有权重均匀初始化的二维卷积操作。
__init__方法初始化模块,接受in_channel(输入通道数)、out_channel(输出通道数)、kernel_size(核大小)、stride(步长,默认为 1)、padding(填充大小,默认为 0)、bias(是否使用偏置,默认为 True)作为参数。- 使用
nn.Parameter创建权重self.weight,其形状为(out_channel, in_channel, kernel_size, kernel_size),使用标准正态分布随机初始化。- 计算
self.scale作为权重的缩放系数,用于保证权重初始化的数值稳定性。- 设置
self.stride和self.padding为类属性。- 如果
bias为 True,则创建偏置self.bias,其形状为(out_channel,),初始化为零。forward方法实现模块的前向传播,调用了 PyTorch 中的F.conv2d函数,对输入input应用二维卷积操作,并返回结果out。__repr__方法定义了模块的字符串表示形式,用于打印模块的信息,包括权重的形状、步长和填充大小。
7、EqualLinear 模块
class EqualLinear(nn.Module):
def __init__(
self, in_dim, out_dim, bias=True, bias_init=0, lr_mul=1, activation=None
):
super().__init__()
self.weight = nn.Parameter(torch.randn(out_dim, in_dim).div_(lr_mul))
if bias:
self.bias = nn.Parameter(torch.zeros(out_dim).fill_(bias_init))
else:
self.bias = None
self.activation = activation
self.scale = (1 / math.sqrt(in_dim)) * lr_mul
self.lr_mul = lr_mul
def forward(self, input):
if self.activation:
out = F.linear(input, self.weight * self.scale)
out = fused_leaky_relu(out, self.bias * self.lr_mul)
else:
out = F.linear(
input, self.weight * self.scale, bias=self.bias * self.lr_mul
)
return out
def __repr__(self):
return (
f"{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})"
)EqualLinear 类继承自 nn.Module,实现了具有均匀初始化权重的全连接层。
__init__方法初始化模块,接受in_dim(输入维度)、out_dim(输出维度)、bias(是否使用偏置,默认为 True)、bias_init(偏置初始值,默认为 0)、lr_mul(学习率倍增因子,默认为 1)、activation(激活函数,默认为 None)作为参数。- 使用
nn.Parameter创建权重self.weight,其形状为(out_dim, in_dim),并进行缩放。- 如果
bias为 True,则创建偏置self.bias,其形状为(out_dim,),初始化为bias_init。self.activation保存激活函数。- 计算
self.scale作为权重的缩放系数,用于保证权重初始化的数值稳定性。- 设置
self.lr_mul为类属性。forward方法实现模块的前向传播,如果存在激活函数,则先进行线性变换,再应用激活函数;否则直接进行线性变换。__repr__方法定义了模块的字符串表示形式,用于打印模块的信息,包括权重的形状。
8、ScaledLeakyReLU 模块
class ScaledLeakyReLU(nn.Module):
def __init__(self, negative_slope=0.2):
super().__init__()
self.negative_slope = negative_slope
def forward(self, input):
out = F.leaky_relu(input, negative_slope=self.negative_slope)
return out * math.sqrt(2)ScaledLeakyReLU 类继承自 nn.Module,实现了带有缩放系数的 Leaky ReLU 激活函数。
__init__方法初始化模块,接受negative_slope(负斜率,默认为 0.2)作为参数。self.negative_slope保存负斜率。forward方法实现模块的前向传播,调用了 PyTorch 中的F.leaky_relu函数,对输入input应用 Leaky ReLU 激活函数,并进行缩放。- 返回值为应用激活函数和缩放后的输出。
9、ModulatedConv2d 模块
class ModulatedConv2d(nn.Module):
def __init__(
self,
in_channel,
out_channel,
kernel_size,
style_dim,
demodulate=True,
upsample=False,
downsample=False,
blur_kernel=[1, 3, 3, 1],
):
super().__init__()
self.eps = 1e-8
self.kernel_size = kernel_size
self.in_channel = in_channel
self.out_channel = out_channel
self.upsample = upsample
self.downsample = downsample
if upsample:
factor = 2
p = (len(blur_kernel) - factor) - (kernel_size - 1)
pad0 = (p + 1) // 2 + factor - 1
pad1 = p // 2 + 1
self.blur = Blur(blur_kernel, pad=(pad0, pad1), upsample_factor=factor)
if downsample:
factor = 2
p = (len(blur_kernel) - factor) + (kernel_size - 1)
pad0 = (p + 1) // 2
pad1 = p // 2
self.blur = Blur(blur_kernel, pad=(pad0, pad1))
fan_in = in_channel * kernel_size ** 2
self.scale = 1 / math.sqrt(fan_in)
self.padding = kernel_size // 2
self.weight = nn.Parameter(
torch.randn(1, out_channel, in_channel, kernel_size, kernel_size)
)
self.modulation = EqualLinear(style_dim, in_channel, bias_init=1)
self.demodulate = demodulate
def __repr__(self):
return (
f"{self.__class__.__name__}({self.in_channel}, {self.out_channel}, {self.kernel_size}, "
f"upsample={self.upsample}, downsample={self.downsample})"
)
def forward(self, input, style):
batch, in_channel, height, width = input.shape
style = self.modulation(style).view(batch, 1, in_channel, 1, 1)
weight = self.scale * self.weight * style
if self.demodulate:
demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
weight = weight * demod.view(batch, self.out_channel, 1, 1, 1)
weight = weight.view(
batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size
)
if self.upsample:
input = input.view(1, batch * in_channel, height, width)
weight = weight.view(
batch, self.out_channel, in_channel, self.kernel_size, self.kernel_size
)
weight = weight.transpose(1, 2).reshape(
batch * in_channel, self.out_channel, self.kernel_size, self.kernel_size
)
out = F.conv_transpose2d(input, weight, padding=0, stride=2, groups=batch)
_, _, height, width = out.shape
out = out.view(batch, self.out_channel, height, width)
out = self.blur(out)
elif self.downsample:
input = self.blur(input)
_, _, height, width = input.shape
input = input.view(1, batch * in_channel, height, width)
out = F.conv2d(input, weight, padding=0, stride=2, groups=batch)
_, _, height, width = out.shape
out = out.view(batch, self.out_channel, height, width)
else:
input = input.view(1, batch * in_channel, height, width)
out = F.conv2d(input, weight, padding=self.padding, groups=batch)
_, _, height, width = out.shape
out = out.view(batch, self.out_channel, height, width)
return outModulatedConv2d 类继承自 nn.Module,实现了具有调制功能的二维卷积层。
__init__方法初始化模块,接受多个参数:in_channel(输入通道数)、out_channel(输出通道数)、kernel_size(核大小)、style_dim(样式维度)、demodulate(是否去调制,默认为 True)、upsample(是否上采样,默认为 False)、downsample(是否下采样,默认为 False)、blur_kernel(模糊核,默认为[1, 3, 3, 1])。- 根据是否上采样或下采样,计算填充大小,并创建模糊层
self.blur。- 计算
fan_in和self.scale用于权重初始化的缩放。- 使用
nn.Parameter创建权重self.weight,其形状为(1, out_channel, in_channel, kernel_size, kernel_size)。- 创建调制层
self.modulation,使用EqualLinear实现。self.demodulate保存是否去调制。__repr__方法定义了模块的字符串表示形式,用于打印模块的信息,包括输入通道数、输出通道数和核大小。forward方法实现模块的前向传播:
- 计算样式
style的调制值,并调整权重。- 如果需要去调制,则计算去调制因子,并调整权重。
- 根据是否上采样、下采样或正常卷积,分别进行相应的卷积操作。
- 返回值为应用卷积和调制后的输出。
10、NoiseInjection 模块
class NoiseInjection(nn.Module):
def __init__(self):
super().__init__()
self.weight = nn.Parameter(torch.zeros(1))
def forward(self, image, noise=None):
if noise is None:
batch, _, height, width = image.shape
noise = image.new_empty(batch, 1, height, width).normal_()
return image + self.weight * noiseNoiseInjection 类继承自 nn.Module,实现噪声注入操作。
NoiseInjection类继承自nn.Module,实现了噪声注入操作。__init__方法初始化模块,创建一个可学习的参数self.weight,并初始化为零。forward方法实现模块的前向传播:
- 接受输入图像
image和可选的噪声noise作为参数。- 如果没有提供噪声
noise,则根据输入图像的形状生成一个与输入图像大小相同的随机噪声。- 将输入图像和噪声按
self.weight进行加权和,并返回结果。
11、ConstantInput 模块
class ConstantInput(nn.Module):
def __init__(self, channel, size=4):
super().__init__()
self.input = nn.Parameter(torch.randn(1, channel, size, size))
def forward(self, input):
batch = input.shape[0]
out = self.input.repeat(batch, 1, 1, 1)
return outConstantInput 类继承自 nn.Module,实现了一个常数输入的模块。
__init__方法初始化模块,接受channel(通道数)和size(大小,默认为 4)作为参数。- 创建一个形状为
(1, channel, size, size)的可学习参数self.input,并初始化为标准正态分布的随机值。forward方法实现模块的前向传播:
- 返回结果。
- 将
self.input重复批量大小次,以匹配输入的批量大小。- 接受输入
input作为参数,用于获取批量大小。
12、StyledConv 模块
class StyledConv(nn.Module):
def __init__(
self,
in_channel,
out_channel,
kernel_size,
style_dim,
upsample=False,
blur_kernel=[1, 3, 3, 1],
demodulate=True,
):
super().__init__()
self.conv = ModulatedConv2d(
in_channel,
out_channel,
kernel_size,
style_dim,
upsample=upsample,
blur_kernel=blur_kernel,
demodulate=demodulate,
)
self.noise = NoiseInjection()
# self.bias = nn.Parameter(torch.zeros(1, out_channel, 1, 1))
# self.activate = ScaledLeakyReLU(0.2)
self.activate = FusedLeakyReLU(out_channel)
def forward(self, input, style, noise=None):
out = self.conv(input, style)
out = self.noise(out, noise=noise)
# out = out + self.bias
out = self.activate(out)
return outStyledConv 类继承自 nn.Module,实现了一个带有样式调制的卷积层。
__init__方法初始化模块,接受多个参数:in_channel(输入通道数)、out_channel(输出通道数)、kernel_size(核大小)、style_dim(样式维度)、upsample(是否上采样,默认为 False)、blur_kernel(模糊核,默认为[1, 3, 3, 1])、demodulate(是否去调制,默认为 True)。- 创建一个
ModulatedConv2d模块self.conv,用于样式调制的卷积操作。- 创建一个
NoiseInjection模块self.noise,用于注入噪声。- 创建一个
FusedLeakyReLU模块self.activate,用于激活操作(注意,这里用的是FusedLeakyReLU,注释掉了ScaledLeakyReLU和bias)。forward方法实现模块的前向传播:
- 接受输入
input、样式style和可选的噪声noise作为参数。- 调用
self.conv对输入进行样式调制的卷积操作。- 调用
self.noise对卷积输出添加噪声。- 调用
self.activate对添加噪声后的输出进行激活操作。- 返回结果。
13、StyledConv_without_noise 模块
StyledConv_without_noise 类似于之前定义的 StyledConv 模块,但不包含噪声注入部分。
class StyledConv_without_noise(nn.Module):
def __init__(
self,
in_channel,
out_channel,
kernel_size,
style_dim,
upsample=False,
blur_kernel=[1, 3, 3, 1],
demodulate=True,
):
super().__init__()
self.conv = ModulatedConv2d(
in_channel,
out_channel,
kernel_size,
style_dim,
upsample=upsample,
blur_kernel=blur_kernel,
demodulate=demodulate,
)
#self.noise = NoiseInjection()
# self.bias = nn.Parameter(torch.zeros(1, out_channel, 1, 1))
# self.activate = ScaledLeakyReLU(0.2)
self.activate = FusedLeakyReLU(out_channel)
def forward(self, input, style, noise=None):
out = self.conv(input, style)
#out = self.noise(out, noise=noise)
# out = out + self.bias
out = self.activate(out)
return out
__init__方法:
- 接受多个参数:
in_channel(输入通道数)、out_channel(输出通道数)、kernel_size(卷积核大小)、style_dim(样式维度)、upsample(是否上采样,默认为 False)、blur_kernel(模糊核,默认为[1, 3, 3, 1])、demodulate(是否去调制,默认为 True)。- 创建一个
ModulatedConv2d实例self.conv,用于样式调制的卷积操作。- 创建一个
FusedLeakyReLU实例self.activate,用于激活操作。
forward方法:
- 接受输入
input和样式style作为参数。- 使用
self.conv对输入进行样式调制的卷积操作。- 使用
self.activate对卷积输出进行激活操作。- 返回激活后的结果。
14、ToRGB 模块
class ToRGB(nn.Module):
def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
super().__init__()
if upsample:
self.upsample = Upsample(blur_kernel)
self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False)
self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
def forward(self, input, style, skip=None):
out = self.conv(input, style)
out = out + self.bias
if skip is not None:
skip = self.upsample(skip)
out = out + skip
return outToRGB 模块用于将特征图转换为 RGB 图像。
__init__方法:
- 接受多个参数:
in_channel(输入通道数)、style_dim(样式维度)、upsample(是否上采样,默认为 True)、blur_kernel(模糊核,默认为[1, 3, 3, 1])。- 如果
upsample为 True,则创建一个Upsample实例self.upsample。- 创建一个
ModulatedConv2d实例self.conv,用于样式调制的卷积操作,输出通道数为 3。- 创建一个可学习的偏置参数
self.bias,并初始化为零。
forward方法:
- 接受输入
input、样式style和可选的skip作为参数。- 使用
self.conv对输入进行样式调制的卷积操作。- 将卷积输出与
self.bias相加。- 如果提供了
skip,则对skip进行上采样,并与卷积输出相加。- 返回结果。
15、Generator 模块
Generator 模块实现了整个生成器网络。
class Generator(nn.Module):
# __init__方法:接受多个参数:size(生成图像的大小)、style_dim(样式维度)、n_mlp(MLP 层数)、channel_multiplier(通道数乘数,默认为 2)、blur_kernel(模糊核,默认为 [1, 3, 3, 1])、lr_mlp(MLP 的学习率乘数,默认为 0.01)。
def __init__(
self,
size,
style_dim,
n_mlp,
channel_multiplier=2,
blur_kernel=[1, 3, 3, 1],
lr_mlp=0.01,
):
super().__init__()
self.size = size
self.style_dim = style_dim
# # 创建一个 PixelNorm 实例,并添加到 layers 列表中。
layers = [PixelNorm()]
# 使用 EqualLinear 创建多个 MLP 层,并添加到 layers 列表中,最后将 layers 列表构造成一个 nn.Sequential 实例 self.style。
for i in range(n_mlp):
layers.append(
EqualLinear(
style_dim, style_dim, lr_mul=lr_mlp, activation="fused_lrelu"
)
)
self.style = nn.Sequential(*layers)
# 定义不同分辨率下的通道数,并存储在 self.channels 字典中。
self.channels = {
4: 512,
8: 512,
16: 512,
32: 512,
64: 256 * channel_multiplier,
128: 128 * channel_multiplier,
256: 64 * channel_multiplier,
512: 32 * channel_multiplier,
1024: 16 * channel_multiplier,
}
# 创建一个 ConstantInput 实例 self.input。
self.input = ConstantInput(self.channels[4])
# 创建第一个卷积层 self.conv1 和第一个 ToRGB 层 self.to_rgb1。
self.conv1 = StyledConv(
self.channels[4], self.channels[4], 3, style_dim, blur_kernel=blur_kernel
)
self.to_rgb1 = ToRGB(self.channels[4], style_dim, upsample=False)
# 计算日志大小和层数,并存储在 self.log_size 和 self.num_layers 中。
self.log_size = int(math.log(size, 2))
self.num_layers = (self.log_size - 2) * 2 + 1
# 创建卷积层列表 self.convs、上采样层列表 self.upsamples、ToRGB 层列表 self.to_rgbs 和噪声层列表 self.noises。
self.convs = nn.ModuleList()
self.upsamples = nn.ModuleList()
self.to_rgbs = nn.ModuleList()
self.noises = nn.Module()
in_channel = self.channels[4]
for layer_idx in range(self.num_layers):
res = (layer_idx + 5) // 2
shape = [1, 1, 2 ** res, 2 ** res]
self.noises.register_buffer(f"noise_{layer_idx}", torch.randn(*shape))
for i in range(3, self.log_size + 1):
out_channel = self.channels[2 ** i]
self.convs.append(
StyledConv(
in_channel,
out_channel,
3,
style_dim,
upsample=True,
blur_kernel=blur_kernel,
)
)
self.convs.append(
StyledConv(
out_channel, out_channel, 3, style_dim, blur_kernel=blur_kernel
)
)
self.to_rgbs.append(ToRGB(out_channel, style_dim))
in_channel = out_channel
self.n_latent = self.log_size * 2 - 2
# 生成一组随机噪声,用于不同分辨率下的噪声注入
def make_noise(self):
device = self.input.input.device
noises = [torch.randn(1, 1, 2 ** 2, 2 ** 2, device=device)]
for i in range(3, self.log_size + 1):
for _ in range(2):
noises.append(torch.randn(1, 1, 2 ** i, 2 ** i, device=device))
return noises
# 计算多个潜在向量的平均值,用于样式平均
def mean_latent(self, n_latent):
latent_in = torch.randn(
n_latent, self.style_dim, device=self.input.input.device
)
latent = self.style(latent_in).mean(0, keepdim=True)
return latent
# 将输入映射到样式空间
def get_latent(self, input):
return self.style(input)
# 实现生成器网络的前向传播,接受多个参数:
# styles:样式向量。 return_latents:是否返回潜在向量。
# inject_index:样式混合的插入索引。 truncation:截断超参数。
# truncation_latent:截断潜在向量。 input_is_latent:输入是否为潜在向量。
# noise:噪声。 randomize_noise:是否随机化噪声。
def forward(
self,
styles,
return_latents=False,
inject_index=None,
truncation=1,
truncation_latent=None,
input_is_latent=False,
noise=None,
randomize_noise=True,
):
# 根据 input_is_latent 判断是否需要将输入映射到样式空间
if not input_is_latent:
styles = [self.style(s) for s in styles]
if noise is None:
if randomize_noise:
noise = [None] * self.num_layers
else:
noise = [
getattr(self.noises, f"noise_{i}") for i in range(self.num_layers)
]
# 根据 truncation 和 truncation_latent 进行样式截断
if truncation < 1:
style_t = []
for style in styles:
style_t.append(
truncation_latent + truncation * (style - truncation_latent)
)
styles = style_t
# 处理样式混合逻辑
if len(styles) < 2:
inject_index = self.n_latent
if styles[0].ndim < 3:
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
else:
latent = styles[0]
else:
if inject_index is None:
inject_index = random.randint(1, self.n_latent - 1)
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
latent2 = styles[1].unsqueeze(1).repeat(1, self.n_latent - inject_index, 1)
latent = torch.cat([latent, latent2], 1)
# 按层级结构进行卷积操作、上采样操作和 ToRGB 操作。
# 将潜在向量 latent 输入到 ConstantInput 层,生成初始输入特征图。
out = self.input(latent)
# 使用第一个 StyledConv 层对输入特征图进行卷积操作,并应用样式latent[:, 0] 和噪声 noise[0]。
out = self.conv1(out, latent[:, 0], noise=noise[0])
# 将初始卷积输出 out 转换为 RGB 图像,并应用样式 latent[:, 1]。结果存储在 skip 中。
skip = self.to_rgb1(out, latent[:, 1])
i = 1
# 使用 for 循环遍历 self.convs(卷积层列表)、noise(噪声列表)和 self.to_rgbs(ToRGB 层列表)。
for conv1, conv2, noise1, noise2, to_rgb in zip(
# self.convs 按照两个一组的方式进行处理,因此使用 self.convs[::2] 和 self.convs[1::2] 来获取偶数和奇数索引的卷积层
self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2], self.to_rgbs
):
# conv1 卷积操作:应用样式 latent[:, i] 和噪声 noise1;conv2 卷积操作:应用样式 latent[:, i + 1] 和噪声 noise2;to_rgb 操作:将卷积输出转换为 RGB 图像,并应用样式 latent[:, i + 2] 和 skip 图像。
out = conv1(out, latent[:, i], noise=noise1)
out = conv2(out, latent[:, i + 1], noise=noise2)
skip = to_rgb(out, latent[:, i + 2], skip)
i += 2
# 循环结束后,最终生成的图像存储在 image 中。
image = skip
# 返回生成的图像和潜在向量(如果需要)。
if return_latents:
return image, latent
else:
return image, None16、ConvLayer模块
该模块继承自 nn.Sequential。这个类的主要作用是根据给定的参数构建一个包含卷积操作、可选的下采样(downsample)操作、以及激活函数(activate)的卷积层。
class ConvLayer(nn.Sequential):
# in_channel:输入通道数。 out_channel:输出通道数。
# kernel_size:卷积核大小。 downsample:是否进行下采样,默认值为 False。
# blur_kernel:用于模糊操作的内核,默认值为 [1, 3, 3, 1]。
# bias:是否在卷积操作中使用偏置,默认值为 True。
# activate:是否添加激活函数,默认值为 True。
def __init__(
self,
in_channel,
out_channel,
kernel_size,
downsample=False,
blur_kernel=[1, 3, 3, 1],
bias=True,
activate=True,
):
# 定义卷积层列表
layers = []
# 如果是下采样操作
if downsample:
# 计算 pad0 和 pad1 以确定填充
factor = 2
p = (len(blur_kernel) - factor) + (kernel_size - 1)
pad0 = (p + 1) // 2
pad1 = p // 2
# 添加模糊层 Blur
layers.append(Blur(blur_kernel, pad=(pad0, pad1)))
# 设置卷积步幅 stride 为 2,并将填充设置为 0
stride = 2
self.padding = 0
else:
# 如果不是下采样操作
# 设置卷积步幅 stride 为 1,并计算填充
stride = 1
self.padding = kernel_size // 2
# 将卷积层 EqualConv2d 添加到 layers 列表中
layers.append(
EqualConv2d(
in_channel,
out_channel,
kernel_size,
padding=self.padding,
stride=stride,
bias=bias and not activate,
)
)
# 如果 activate 为 True,则添加激活函数到 layers 列表中
# FusedLeakyReLU:如果 bias 为 True,则使用融合的 Leaky ReLU 激活函数。
# ScaledLeakyReLU:如果 bias 为 False,则使用缩放的 Leaky ReLU 激活函数。
if activate:
if bias:
layers.append(FusedLeakyReLU(out_channel))
else:
layers.append(ScaledLeakyReLU(0.2))
# 调用父类 nn.Sequential 的构造函数,并将 layers 列表传递给它
super().__init__(*layers)17、ResBlock模块
ResBlock 继承自 nn.Module,表示一个残差块,它包含两个卷积层和一个跳跃连接(skip connection)。
class ResBlock(nn.Module):
def __init__(self, in_channel, out_channel, blur_kernel=[1, 3, 3, 1]):
super().__init__()
self.conv1 = ConvLayer(in_channel, in_channel, 3)
self.conv2 = ConvLayer(in_channel, out_channel, 3, downsample=True)
self.skip = ConvLayer(
in_channel, out_channel, 1, downsample=True, activate=False, bias=False
)
def forward(self, input):
out = self.conv1(input)
out = self.conv2(out)
skip = self.skip(input)
out = (out + skip) / math.sqrt(2)
return out初始化方法
__init__
参数:
in_channel:输入通道数。out_channel:输出通道数。blur_kernel:用于模糊操作的内核,默认值为[1, 3, 3, 1]。卷积层
conv1和conv2:
conv1:一个普通的卷积层。conv2:一个带有下采样操作的卷积层。跳跃连接
skip:
- 一个 1x1 卷积层,也带有下采样操作,但没有激活函数和偏置。
前向传播方法
forward
- 输入通过
conv1和conv2进行卷积操作。- 跳跃连接通过
skip进行卷积操作。- 最后,将
conv2的输出和跳跃连接的输出相加,并除以 sqrt{2}。
18、Discriminator模块
Discriminator 继承自 nn.Module,表示一个鉴别器。它包含多个残差块和一些卷积层,用于判别输入图像。
class Discriminator(nn.Module):
# size:输入图像的尺寸(假设为正方形)。channel_multiplier:通道数的倍增因子。
# blur_kernel:用于模糊操作的内核,默认值为 [1, 3, 3, 1]。
def __init__(self, size, channel_multiplier=2, blur_kernel=[1, 3, 3, 1]):
super().__init__()
# 通道数字典 channels:为不同尺寸的图像定义了不同的通道数。
channels = {
4: 512,
8: 512,
16: 512,
32: 512,
64: 256 * channel_multiplier,
128: 128 * channel_multiplier,
256: 64 * channel_multiplier,
512: 32 * channel_multiplier,
1024: 16 * channel_multiplier,
}
# 卷积层列表 convs:第一个卷积层将输入的 3 通道图像转换为相应的通道数。
convs = [ConvLayer(3, channels[size], 1)]
# 根据输入图像的尺寸添加多个残差块 ResBlock 和卷积层
log_size = int(math.log(size, 2)) #计算输入图像的对数尺寸
# 初始化输入通道数
in_channel = channels[size]
# 根据输入图像的尺寸添加残差块 ResBlock 和卷积层
for i in range(log_size, 2, -1):
out_channel = channels[2 ** (i - 1)]
convs.append(ResBlock(in_channel, out_channel, blur_kernel))
in_channel = out_channel
# 将所有卷积层和残差块组合成一个顺序容器 nn.Sequential,以便在前向传播中依次执行。
self.convs = nn.Sequential(*convs)
# stddev_group 和 stddev_feat 用于计算标准差。
self.stddev_group = 4
self.stddev_feat = 1
self.final_conv = ConvLayer(in_channel + 1, channels[4], 3)
self.final_linear = nn.Sequential(
EqualLinear(channels[4] * 4 * 4, channels[4], activation="fused_lrelu"),
EqualLinear(channels[4], 1),
)
def forward(self, input):
out = self.convs(input)
batch, channel, height, width = out.shape
group = min(batch, self.stddev_group)
stddev = out.view(
group, -1, self.stddev_feat, channel // self.stddev_feat, height, width
)
stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
stddev = stddev.mean([2, 3, 4], keepdims=True).squeeze(2)
stddev = stddev.repeat(group, 1, height, width)
out = torch.cat([out, stddev], 1)
# final_conv:一个卷积层,用于合并标准差特征。
out = self.final_conv(out)
out = out.view(batch, -1)
#final_linear:两个全连接层,用于最终的判别。
out = self.final_linear(out)
return out
(六)参数配置train_config.txt
- 实验名称:./experiments/1
- 数据集路径:../classroom_train
- 数据集类型:普通数据集(normal)
- 迭代次数:80000
- TensorExtractor 模型的输出张量中的通道数N:1
- lambda_Ex:10(
lambda_Ex是一个超参数,通常用于控制损失函数中的正则化项的权重。)- 检查点路径:None
- 学习率:0.002
- 批量大小:1
- 图像尺寸:256
- 真实图像梯度惩罚因子(real_r1):10
- 纹理图像梯度惩罚因子(texture_r1):1
- 分布图像梯度惩罚因子(dist_r1):1
- 参考图像裁剪数目(ref_crop):4
- 图像裁剪数目(n_crop):8
- 每隔多少次迭代进行判别器正则化(d_reg_every):16
- 通道数(channel):32
- 通道倍增因子(channel_multiplier):1
- 结构通道数(structure_channel):8
- 纹理通道数(texture_channel):2048
- 每隔多少次迭代记录日志(log_every):200
- 每隔多少次迭代显示结果(show_every):1000
- 每隔多少次迭代保存模型(save_every):200000
- 起始迭代次数:0
- 模糊核大小:(1, 3, 3, 1)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









