






论文链接:Robust Watermarking Using Generative Priors Against Image Editing: From Benchmarking to Adavances
代码链接:https://github.com/Shilin-LU/VINE
这是一篇高质量的水印论文,作者团队来自于新加坡南洋理工大学和苏黎世联邦理工学院,目前生成式水印集中研究抵抗再生攻击或者深度编辑,主要使用的方法也都是“花样”在潜变量(latent)中嵌入水印。这篇论文不仅测试了主流水印方法对再生攻击(随机再生与确定再生)、全局编辑(Instruct-Pix2Pix、MagicBrush)、局部编辑(ControlNet-Inpainting、UltraEdit)以及图生视频(Stable Video Diffusion)的鲁棒性,还更深入分析了这些深度移除攻击主要对水印的破坏区域,最重要的是没有从latent角度出发,仅仅在频域角度设计噪声层就能抵抗这些深度移除攻击。
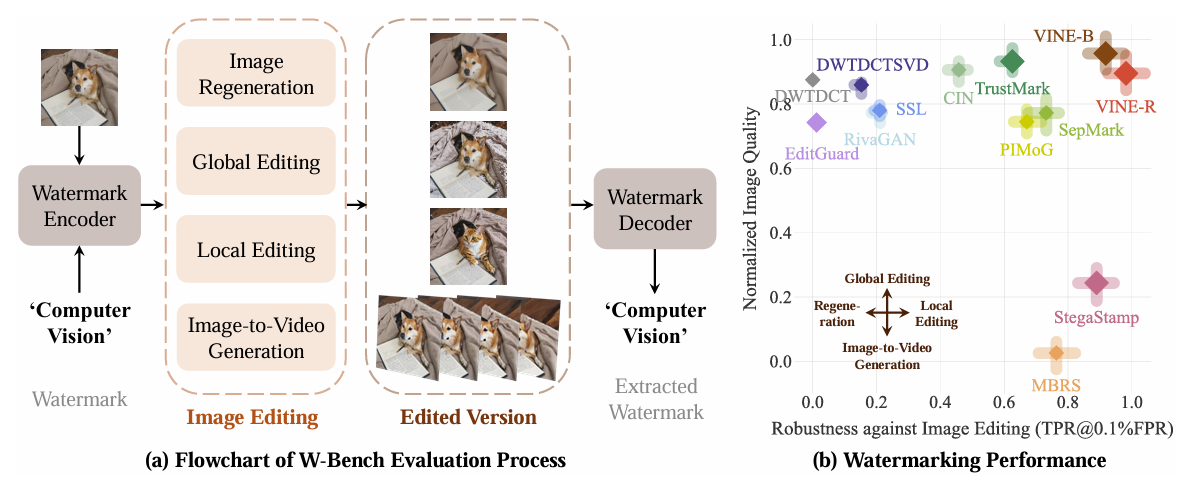
自Hidden以后,端到端水印就很流行,但是却难以抵抗近年新出现的深度移除攻击:例如基于diffusion的再生攻击或图像编辑,这种攻击很难加入到噪声层中对抗训练,端到端水印一度失势。
而作者设计的水印依然采用端到端的框架,巧妙的将深度移除攻击模拟到频域攻击,因为作者发现:这些深度编辑攻击通常会消除高频波段的水印特征,而对低频波段特征影响较小。这一特性恰恰与模糊失真(blurring distortions)很类似,所以作者在噪声层引入多种模糊失真替代模拟深度编辑攻击。
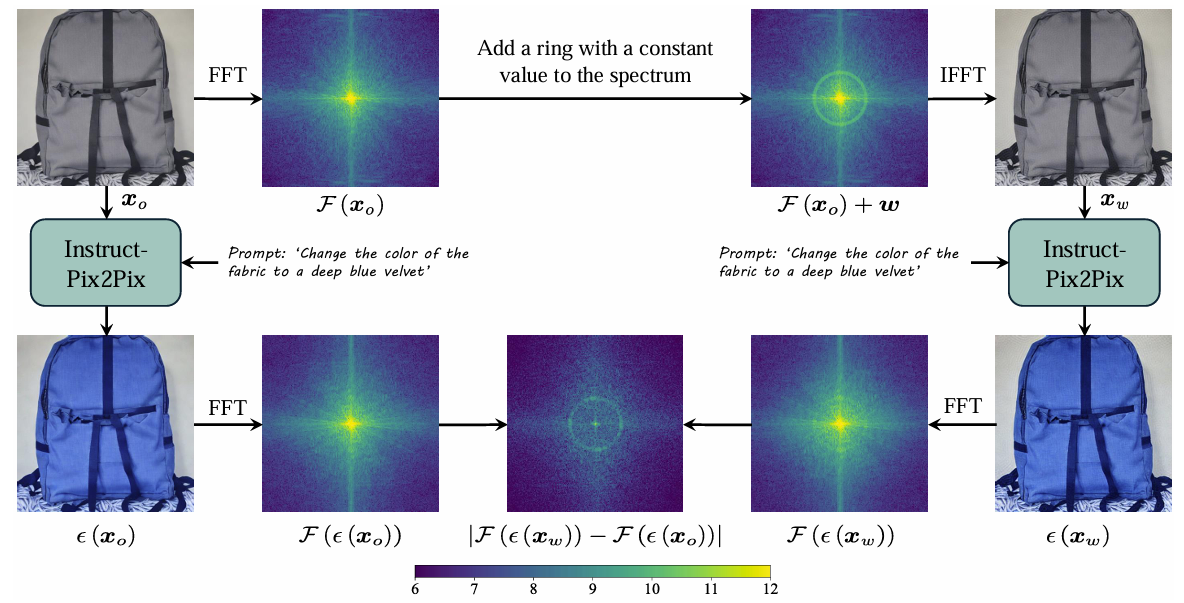
上图描述的很清晰,作者是这样实验的,思路有点类似于树环水印:原始图像 X0 经过快速傅里叶变换转到频域,然后在频域中心(低频区域)加了一个对称的环形 F(X0)+w,再逆傅里叶回图像域得到简易的水印图像 Xw ;然后将原图 X0 与水印图像 Xw 都用深度移除攻击(Instruct-P2P为例)编辑,得到 ϵ(X0)与 ϵ(Xw),最后计算二者在频域的差值,如果对称环形仍存在,就可以验证低频波段受深度移除攻击影响小。
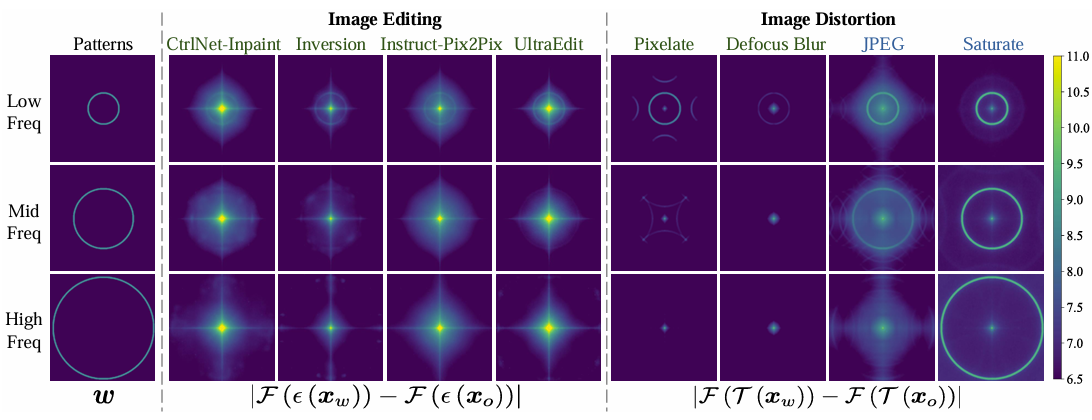
中高频的实验结果如下,中高频的环形确实被攻击去掉了,作者认为可能是因为:Text to Image的模型在训练时会优先捕捉图像的整体语义内容和结构(即低频信息),以便与prompt相匹配。因此,在生成过程中高频部分会被平滑掉。而且从下图还可以看出,pixelation 和 defocus blur 攻击确实比较类似于前面的Editing攻击,而 JPEG 和 saturation 则不相似。
作者提出的水印方法:作者自己设计的水印方法大致框架依然是:编码器+噪声层+解码器,刚刚介绍了噪声层的创新,之后的创新主要集中在编码器,作者设计的编码器本身就是一个生成模型,看到这里我有种既视感:作者好像就是在latent水印流程基础上加了噪声层和解码器。
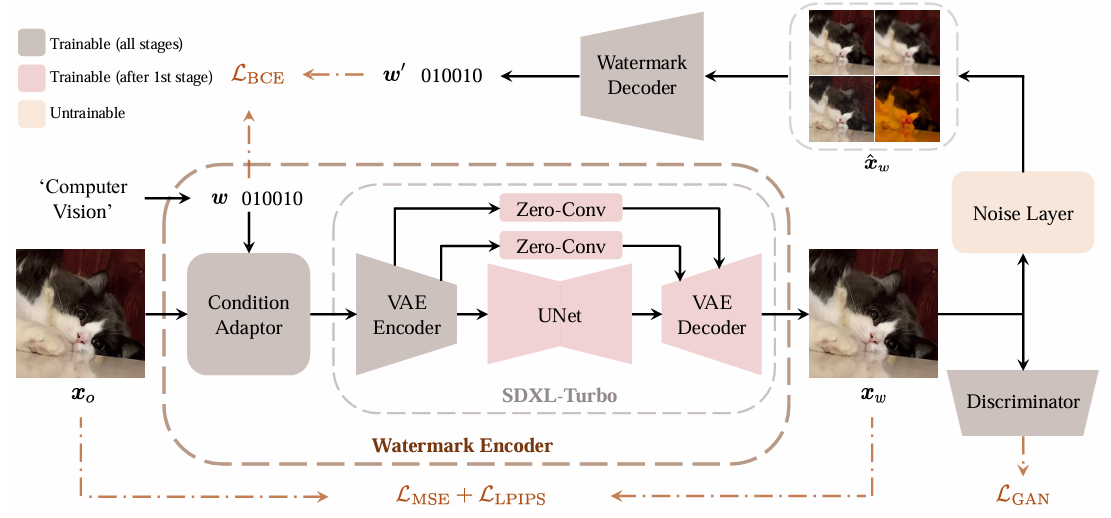
编码器有几个主要的创新:
- 作者使用整个条件生成模型作为编码器,可能是为了方便训练,作者使用的是 one-step 生成模型。
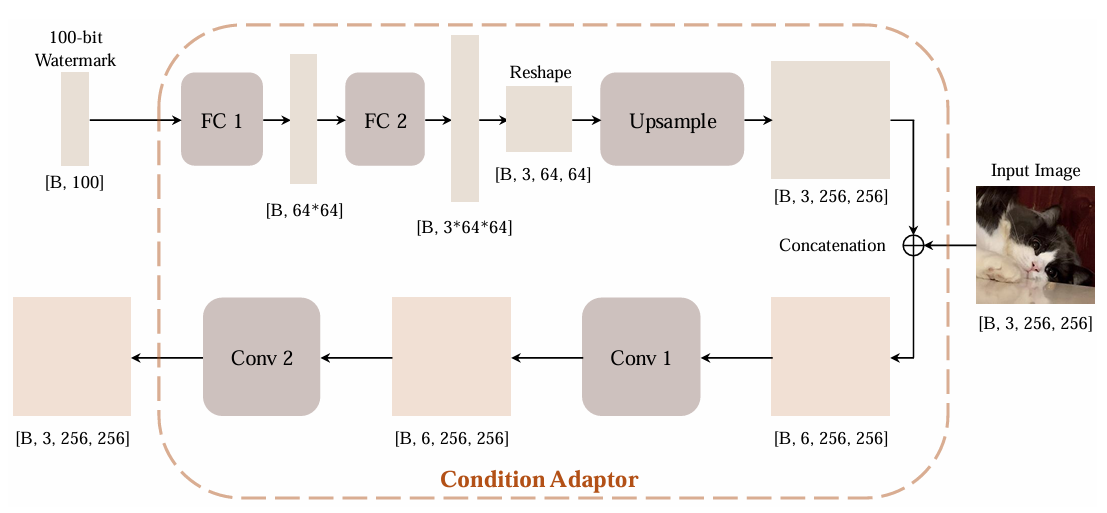
- 在将水印与图像送入生成模型之前,先通过作者设计的条件适配器(condition adaptor)进行融合;
- 作者重新训练了生成模型的VAE,因为作者认为VAE的原始目标是为了平衡重建能力和压缩能力,于是牺牲了重建保真度,因此作者重新训练VAE并在VAE的Encoder与Decoder之间增加了零卷积层方便跳跃连接。
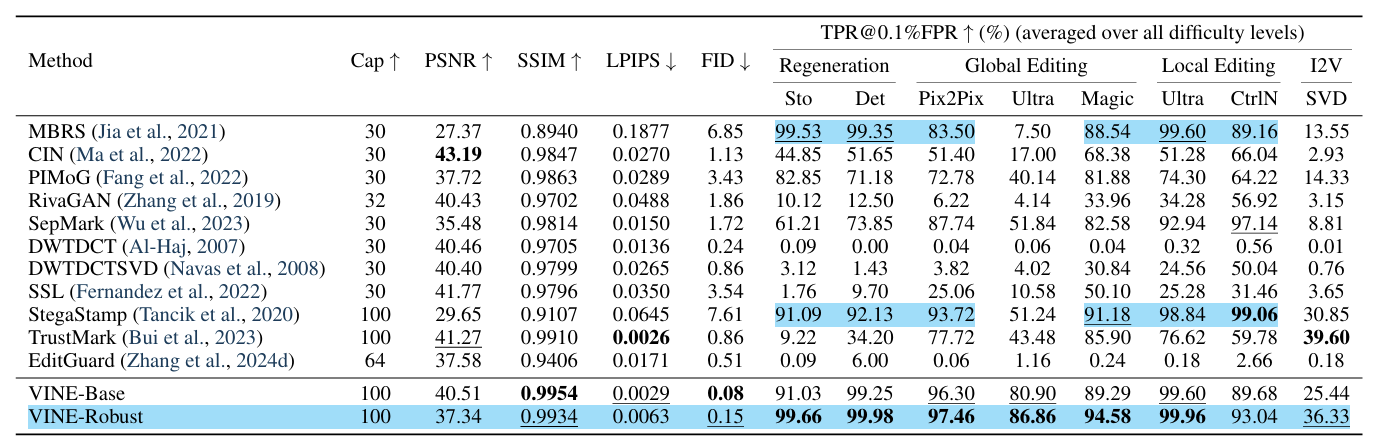
结果:
从这个表来看作者的result蛮不错的,但是缺点就是没有和Robust-Wide进行对比,同样也是抵抗深度移除攻击,但是robust-wide的图像质量比这篇要高的,容量也更高。
消融实验:

这里其实我有一个地方不太理解,就是为什么作者要在嵌入水印后增加一个SDXL模块,因为condition adaptor之后就输出了带水印的图像,为什么还要再经过SD模块呢?后来我把SD去掉之后,单纯依靠condition adaptor输出图像:



上面图一是原图,图二是condition adaptor输出的水印图,图三是再经过SD后的水印图。
可以看到单纯依靠condition adaptor的话,水印图像是无法接受的,可能也是因为condition adaptor的网络结构比较简单,所以作者才增加了SD模块。
但是又有一个疑问,为什么作者不直接参考stegastamp或者robust-wide一样采用UNet结构的网络呢?从上面那个消融实验的表格可以看出,在使用UNet网络作为水印嵌入网络时,图像质量PSNR明显下降(毕竟有blur这个噪声层),尤其再增加了pixel2pixel模型作为噪声层后,PSNR只达到了31。但是用SDXL替换UNet后,图像质量明显上升。
理解错误的地方欢迎指出,欢迎讨论交流~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











