






更好的观感可以看这里:https://www.yuque.com/charles-jg62q/evmer7/egf48usuiphpteos?singleDoc# 《扩散模型相关知识》
带VAE与不带VAE的扩散模型的区别
不带VAE的扩散模型很好理解:

从一个形状为[B, C, H, W]的初始噪声图像,在提示词引导下逐步去噪得到生成图像。这里的C就是图像通道数,H和W都是图像等尺寸。
带VAE的扩散模型:
训练阶段:
训练时需要VAE的编码器,将训练集中的图像编码为形状为[B, D]或[B, H', W' C]的潜变量z;
eg:16个64*64的图像➡[16, 128]或[16, 64, 64, 4](有损压缩)D=H'*W'*C
- 在潜空间中,逐步向z添加噪声,生成一系列噪声潜在表示zt;(这里的是高斯噪声)
- 扩散模型学习如何从噪声潜在表示zt中预测噪声,并逐步去噪;
- VAE的解码器从去噪潜变量中生成图像并构建损失;
推理阶段:
- 不需要VAE的编码器,和不带VAE的扩散模型一样,都是随机采样初始噪声,这个初始噪声形状为[B, D]或[B, H', W', C],例如[16, 128]或[1, 64, 64, 4],而且是从标准正态分布中采样的;
- 反向扩散逐步去噪,得到不带噪声的潜变量;
- 使用VAE的解码器从潜变量转为图像;
| 阶段 | 训练 | 推理 |
| 输入 | 真实图像 | 随机噪声 |
| VAE 编码 | 将图像压缩为潜变量 | 无 |
| 扩散过程 | 向潜变量添加噪声,训练模型预测噪声 | 从噪声中逐步恢复潜变量 |
| VAE 解码 | 可选,用于评估生成质量 | 将恢复的潜变量解码为图像 |
| 输出 | 无(更新模型参数) | 生成的图像 |
潜变量和潜空间的关系:
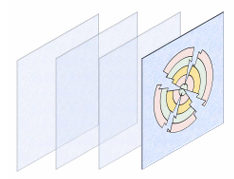
这是stable diffusion的潜空间,一共4通道,每个通道的大小是h*w;而潜变量就是潜空间的一个具体例子,潜变量的维度d = channel * h * w(潜空间)
如何给潜变量加噪?
在时间步 t,向初始潜变量 x 添加噪声,生成带噪声的潜变量 xt
![]()
加噪过程是逐步进行的,但也是线性高斯过程,因此也可以用初始状态表示为:
![]()
其中,αt 是噪声系数,随着时间步 t 的增长,αt 逐渐减小,1-αt 逐渐增大,ϵ 是从标准高斯分布中采样的噪声,形状与初始潜变量 x 相同。
可以看到,加噪过程中,每一步的噪声潜变量 xt 都只与前一步的噪声潜变量xt-1有关,而与再之前的历史无关。(虽然有初始状态x0的推导公式,但是也是由xt-1往前迭代推导出来的,真正的公式只是第一个公式)这一过程也叫做马尔可夫过程,典型的无记忆性。去噪过程同理,因此DDPM的过程较缓慢。
而DDIM却是非马尔可夫过程,其加噪的潜变量不依赖前一步的噪声向量,可以跨步采样(原理没理解),这样的跨步采样可以减少采样步数,提高效率。
扩散模型中提示词的处理流程:
提示词以文本形式输入,先经过tokenizer方法转为token,这一过程包括分词+统一长度+索引化。eg:"A cat on the mat"➡["A", "cat", "on", "the", "mat"]
然后将这些token填充(padding)或截断(truncation)到统一长度便于处理,最后转为➡[101, 234, 123, 456, 789] 这些索引是词汇表中的索引。
所以token中一般包含两个必要信息:索引input_ids+填充指示attention_mask;用于指示哪些 token 是实际文本,哪些是填充。
再将token经过text_ecoder方法(如BERT或GPT预训练模型)转为连续的Embedding向量,这种向量能被神经网络处理而且包含了语义信息。
eg:[101, 234, 123, 456, 789]➡[0.1, 0.3, 0.5, ...]
UNet在扩散模型中的作用:
在训练阶段,UNet用来预测噪声,也就是说给定一个含噪声的数据 xt ,UNet 的目标是预测出噪声 ϵ ,使得
![]()
或
![]()
(根据具体需求设置)。
这样训练好具备预测噪声的UNet网络可以在推理阶段逐步去除噪声,从纯噪声数据 xt 逐步恢复出原始数据 x0
DDIM Inversion生成图像+重建图像的过程
提示词生成图像:
由上文的提示词处理过程,我们得到了无提示词的Embedding(prompt=''),即下面uncond_embeddings,术语叫做null text embedding
uncond_input = model.tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
uncond_embeddings = model.text_encoder(uncond_input.input_ids.to(model.device))[0]接下来如果用户有输入提示词,则将提示词对应的Embedding与uncond_embeddings进行拼接,将当前latent与拼接后的Embedding作为UNet的输入,预测噪声进行去噪:
context = [uncond_embeddings, text_embeddings]
noise_pred = model.unet(latents_input, t, encoder_hidden_states=context)["sample"]
noise_pred_uncond, noise_prediction_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)为什么需要uncond_embeddings?
由上面代码可知,uncond_embeddings的作用是发挥条件强度系数guidance_scale的作用,从而提高生成质量和可控性。这也就是Null-text Inversion技术(NTI)
重建图像:
重建图像时也是使用UNet预测噪声,但是目标不同,此时UNet不需要提示词,因此也就不需要text_embeddings,但是null text embedding是需要的(因为SD中prompt是必需的)。
因此有的论文通过训练优化null text embedding使噪声预测更精准,去噪后的latent更贴近原始latent,达到精准重建的目标。下面是示意代码:
uncond_embeddings.requires_grad_(True)
optimizer = optim.AdamW([uncond_embeddings], lr=1e-1)
out_latents = diffusion_step(model, latents, context, t, guidance_scale)
optimizer.zero_grad()
loss = loss_func(out_latents, inversion_latents[start_step - 1 + ind + 1])
loss.backward()
optimizer.step()注意力图:
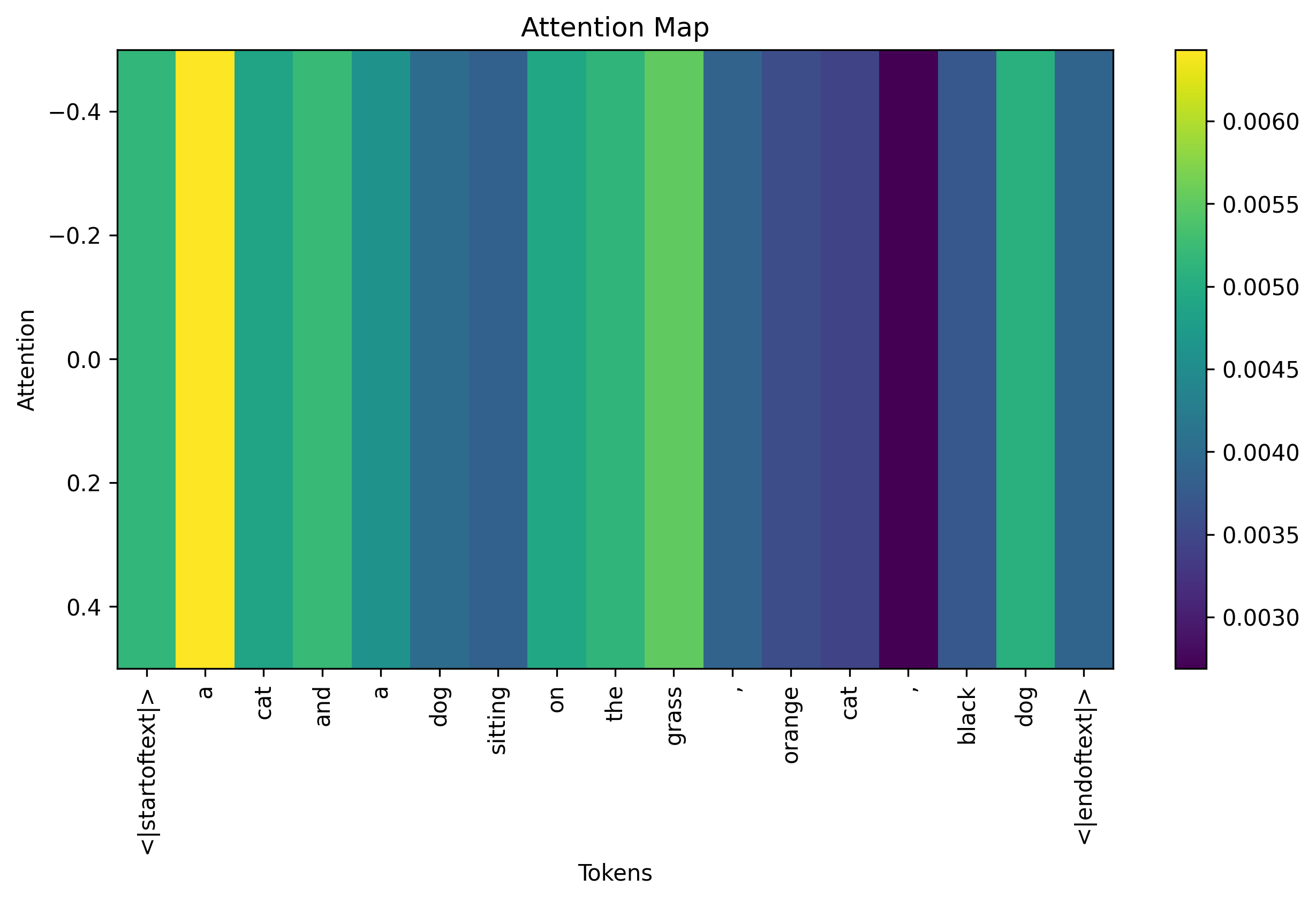
在使用prompt生成图像时,扩散模型对自然语言中的分词关注度不一样,例如:a cat and a dog sitting on the grass, orange cat, black dog.
通过注意力图可以看出扩散模型对名词和冠词的关注度较高(接近黄色的区域)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











