







 本文详细解读了软件开发中的关键度量标准,包括圈复杂度的计算原理、如何利用可维护性指数评估代码易维护性,以及模块耦合度的评估方法。通过实例演示和实用公式,助您理解和优化代码结构.
本文详细解读了软件开发中的关键度量标准,包括圈复杂度的计算原理、如何利用可维护性指数评估代码易维护性,以及模块耦合度的评估方法。通过实例演示和实用公式,助您理解和优化代码结构.
前言
常用的可维护性度量标准有:
- 圈复杂度:
度量代码的结构复杂度。 - 代码行数:
指示代码中的大致行数。 - 可维护性指数:
计算介于0和100之间的索引值,表示维护代码的相对容易性。 高价值意味着更好的可维护性。 - 继承的层次数:
表示扩展到类层次结构的根的类定义的数量。 等级越深,就越难理解特定方法和字段在何处被定义或重新定义。 - 类之间的耦合度:
通过参数,局部变量,返回类型,方法调用,泛型或模板实例化,基类,接口实现,在外部类型上定义的字段和属性修饰来测量耦合到唯一类。 - 单元测试的覆盖度:
指示代码库的哪些部分被自动化单元测试覆盖。
本文将对其中的圈复杂度、可维护性指数、耦合度的计算进行介绍。
一、圈复杂度
1.定义
圈复杂度(Cyclomatic Complexity),用来衡量一个模块判定结构的复杂程度,数量上表现为线性无关的路径条数,即合理的预防错误所需测试的最少路径条数。
圈复杂度大说明程序代码可能质量低且难于测试和维护,根据经验,程序的可能错误和高的圈复杂度有着很大关系。
2.计算方法
公式1: V(G)=e-n+2p(常用公式为e-n+2)。其中,e表示控制流图中边的数量,n表示控制流图中节点的数量,p图的连接组件数目(图的组件数是相连节点的最大集合)。因为控制流图都是连通的,所以p为1。
公式2: V(G)=区域数=判定节点数+1。其实,圈复杂度的计算还有更直观的方法,因为圈复杂度所反映的是“判定条件”的数量,所以圈复杂度实际上就是等于判定节点的数量再加上1,也即控制流图的区域数。
公式3: V(G)=R。其中R代表平面被控制流图划分成的区域数。针对程序的控制流图计算圈复杂度V(G)时,最好还是采用第一个公式,也即V(G)=e-n+2;而针对模块的控制流图时,可以直接统计判定节点数,这样更为简单;针对复杂的控制流图是,使用区域计算公式V(G)=R更为简单。
3.计算示例
有如下程序
//程序原代码,圈复杂度为 2
public String case1(int num) {
String string = null;
if (num == 1) {
string = "String";
}
return string.substring(0);
}
//上面代码的单元测试代码
public void testCase1(){
String test1 = case1(1);
}
在计算圈复杂度时,可以通过程序控制流图方便的计算出来。绘制控制流图: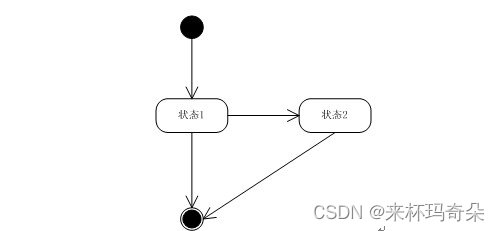
e = 3 ; n = 3;那么全复杂度V(G) = 3 - 3 + 2 = 2
二、可维护性指数
可维护性指数(Maintainability Index)
这个指数用一个公式计算,考虑到了圈复杂性、代码行以及Halstead量,Halstead量也是一个度量,考虑操作符和操作数的总数。该指数的范围是0~100,数值越高就越容易维护。
该指数的计算涉及到以下参数:
- Halstead Volume (HV)——霍尔斯特德量
- Cyclomatic Complexity (CC)——圈复杂度
- The average number of lines of code per module (LOC)——每个模块的平均代码行数
- The percentage of comment lines per module (COM)——每个模块的注释行百分比
具体计算公式: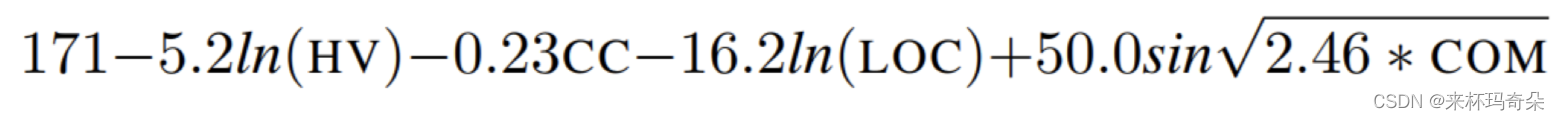
三、模块耦合度
耦合是指模块之间相互联系的紧密程度。高内聚、低耦合是我们在软件设计过程中必须遵循的一个重要原则,在整个软件工程中占有很大的比重。
一般采用以下公式来计算模块耦合度:
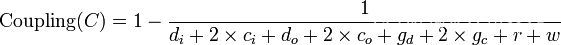
(1)di: 输入数据参数的个数
(2)ci: 输入控制参数的个数
(3)do: 输出数据参数的个数
(4)co: 输出控制参数的个数 全局耦合:
(5)gd: 用来存储数据的全局变量
(6)gc: 用来控制的全局变量 环境耦合:
(7)w: 此模块调用的模块个数(扇出)
(8)r: 调用此模块的模块个数(扇入)
若Coupling数值越大,表示模块耦合的情形越严重
总结
本文给大家介绍了软件设计中常用的可维护性度量标准,对其中的圈复杂度、可维护性指数、耦合度的计算方法进行介绍,便于对可维护性进行量化衡量。

















 2658
2658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









