







写在前面
在机器学习中,监督学习依赖大量带标签的数据进行训练,而非监督学习则完全基于无标签数据发掘结构信息。然而,在实际应用中,获取标签往往代价高昂,纯无监督方法又难以保证准确性。半监督学习正是在两者之间建立桥梁,通过少量标注数据引导大量未标注数据参与训练,既降低了标注成本,又提升了模型的泛化能力,成为数据稀缺场景下的重要解决方案。
- 1.python基础;
- 2.ai模型概念+基础;
- 3.数据预处理;
- 4.机器学习模型--1.编码(嵌入);2.聚类;3.降维;4.回归(预测);5.分类;
- 5.正则化技术;
- 6.神经网络模型--1.概念+基础;2.几种常见的神经网络模型;
- 7.对回归、分类模型的评价方式;
- 8.简单强化学习概念;
- 9.几种常见的启发式算法及应用场景;
- 10.机器学习延申应用-数据分析相关内容--1.A/B Test;2.辛普森悖论;3.蒙特卡洛模拟;
- 11.数据挖掘--关联规则挖掘
- 12.数学建模--决策分析方法,评价模型
- 13.主动学习(半监督学习)
- 以及其他的与人工智能相关的学习经历,如数据挖掘、计算机视觉-OCR光学字符识别、大模型等。
目录
半监督学习(Semi-Supervised Learning)
基于分歧的方法(多视图学习muti-view-learning)
主动学习
主动学习(Active Learning)是机器学习的一种训练范式,其核心思想是让模型主动选择最有价值的样本进行标注,而非被动接受随机标注的数据。通过减少标注成本(时间、金钱)的同时最大化模型性能,特别适用于标注昂贵的场景(如医学图像、语音转录、专业文本等)。
核心思想
- 关键问题:标注所有数据成本高,但随机标注部分数据效率低。
- 解决思路:模型在训练过程中主动提问(查询最不确定或信息量最大的样本),由专家标注后迭代优化。
- 不确定性高的样本:模型对其预测结果信心不足(例如分类任务中各类别概率接近),说明模型在这些样本上存在“知识盲区”。
- 标注价值高:通过人工标注这些样本,可以快速纠正模型的错误认知,显著提升模型性能。
- 避免冗余:如果选择模型已经很确定的样本(如概率接近1或0),标注它们对模型改进的贡献很小。
from modAL.uncertainty import uncertainty_sampling
learner = ActiveLearner(
estimator=LogisticRegression(),
query_strategy=uncertainty_sampling, # 关键:选择最不确定的样本
X_training=X_train,
y_training=y_train
)
# 每次查询时,模型会返回最不确定的样本索引
query_idx, query_instance = learner.query(X_pool)主动学习的基本流程
- 初始训练:用少量已标注数据训练初始模型。
- 样本选择:对未标注池(Pool)中的样本,根据某种策略选择最有价值的样本。
- 专家标注:人工或外部系统标注选中的样本。
- 模型更新:将新标注数据加入训练集,重新训练模型。
- 重复:直到满足停止条件(如标注预算耗尽或模型性能达标)。
常见的查询策略(Query Strategies)
(1) 不确定性采样(Uncertainty Sampling)
选择模型预测最不确定的样本,具体方法包括:
- 最小置信度(Least Confidence):选择预测概率最大的类别置信度最低的样本。
- 边缘采样(Margin Sampling):选择预测概率第一和第二接近的样本。
- 熵采样(Entropy Sampling):选择预测类别分布熵最大的样本(不确定性最高)。
适用场景:分类任务(如文本分类、图像识别)。
(2) 基于委员会的查询(Query-by-Committee, QBC)
训练多个模型(委员会),选择模型间分歧最大的样本(如投票差异大)。方法:
- 投票熵(Vote Entropy):统计不同模型的预测不一致性。
- KL散度(KL Divergence):衡量模型预测分布的差异。
from modAL.disagreement import vote_entropy_sampling
# 初始化委员会(多个分类器)
from sklearn.ensemble import RandomForestClassifier
committee = [
LogisticRegression(max_iter=1000),
RandomForestClassifier(n_estimators=50)
]
learner = ActiveLearner(
estimator=committee,
query_strategy=vote_entropy_sampling,
X_training=X_train,
y_training=y_train
)适用场景:集成学习或模型不确定性高的任务。
(3) 期望模型变化(Expected Model Change)
选择能最大程度改变模型参数的样本(如梯度下降时的梯度幅度)。
示例:在线学习中,选择使模型权重更新最大的样本。
(4) 基于多样性的采样(Diversity Sampling)
避免选择相似样本,覆盖数据分布的空间,例如:
- 聚类采样:在未标注数据中聚类,从不同簇中选择样本。
from sklearn.cluster import KMeans from modAL.density import information_density # 计算样本密度(聚类相似性) density = information_density(X_pool, metric='cosine') learner = ActiveLearner( estimator=LogisticRegression(), query_strategy=lambda *args: np.argmax(density), # 选择密度高的样本 X_training=X_train, y_training=y_train ) - 核心集(Coreset):选择覆盖整个数据分布的代表性样本。
(5) 混合策略
结合不确定性和多样性,如:
- 密度加权不确定性采样:在不确定性高的区域选择数据密集处的样本。
主动学习的应用场景
| 领域 | 应用案例 |
|---|---|
| 医学影像 | 标注CT/MRI切片(专家标注耗时,主动学习减少标注量)。 |
| 自然语言处理 | 命名实体识别(NER)、情感分析(标注专业文本成本高)。 |
| 语音识别 | 转录稀有语言或专业术语(如医疗对话)。 |
| 工业检测 | 缺陷检测(如半导体晶圆缺陷,标注样本稀少)。 |
| 推荐系统 | 冷启动问题(主动选择用户对哪些商品评分能最大化推荐效果)。 |
| 任务类型 | 主动学习策略 | 目标 |
|---|---|---|
| 分类 | 不确定性采样、委员会查询 | 明确决策边界 |
| 回归 | 方差采样、预期误差减少 | 降低预测误差 |
| 聚类 | 边界样本标注、约束传播 | 优化聚类结构 |
| 强化学习 | 专家动作查询、奖励函数学习 | 加速策略收敛 |
| 生成任务 | 多样化采样、对抗训练 | 提升生成质量 |
示例代码:基于不确定性的文本分类主动学习
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from modAL.models import ActiveLearner
from modAL.uncertainty import uncertainty_sampling
# 加载数据集(示例:20 Newsgroups,选取两类)
categories = ['sci.space', 'rec.sport.baseball']
data = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, random_state=42)
X_raw = data.data
y_true = data.target
# 文本向量化(TF-IDF)
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(X_raw)
# 初始训练集:随机选择20个样本
n_initial = 20
initial_idx = np.random.choice(range(len(X_raw)), size=n_initial, replace=False)
X_train, y_train = X[initial_idx], y_true[initial_idx]
# 剩余数据作为未标注池(模拟真实场景)
X_pool = np.delete(X, initial_idx, axis=0)
y_pool = np.delete(y_true, initial_idx, axis=0)
X_pool_raw = np.delete(X_raw, initial_idx, axis=0)
# 初始化主动学习器
learner = ActiveLearner(
estimator=LogisticRegression(max_iter=1000),
query_strategy=uncertainty_sampling,
X_training=X_train,
y_training=y_train
)
# 主动学习循环(每次选择1个样本标注)
n_queries = 10 # 标注预算
for i in range(n_queries):
# 选择最不确定的样本
query_idx, query_instance = learner.query(X_pool)
# 模拟专家标注(这里用真实标签代替人工)
y_new = y_pool[query_idx]
# 更新模型
learner.teach(X_pool[query_idx], y_new)
# 从未标注池中移除已标注样本
X_pool = np.delete(X_pool, query_idx, axis=0)
y_pool = np.delete(y_pool, query_idx, axis=0)
X_pool_raw = np.delete(X_pool_raw, query_idx, axis=0)
# 打印当前模型性能(在测试集上)
accuracy = learner.score(X_pool, y_pool)
print(f"Query {i+1}: 新增样本标签 = {y_new}, 模型准确率 = {accuracy:.2f}")
# 最终模型评估
final_accuracy = learner.score(X_pool, y_pool)
print(f"最终模型准确率: {final_accuracy:.2f}")Query 1: 新增样本标签 = 1, 模型准确率 = 0.85
Query 2: 新增样本标签 = 0, 模型准确率 = 0.88
...
Query 10: 新增样本标签 = 1, 模型准确率 = 0.92
最终模型准确率: 0.92- 模拟专家标注(实际应用中需人工介入)。
模型主动选择样本 → 专家标注 → 迭代优化。通过modAL库可快速实现不同查询策略(如不确定性、委员会投票等),适用于文本、图像等多种任务。
回归任务示例
import numpy as np
from sklearn.gaussian_process import GaussianProcessRegressor
from modAL.models import ActiveLearner
from modAL.disagreement import max_std_sampling
# 生成回归数据
X = np.random.rand(100, 1) * 10
y = np.sin(X).ravel() + np.random.normal(0, 0.1, size=100)
# 初始训练集(随机选择5个点)
initial_idx = np.random.choice(range(100), size=5, replace=False)
X_train, y_train = X[initial_idx], y[initial_idx]
# 初始化主动学习器
learner = ActiveLearner(
estimator=GaussianProcessRegressor(),
query_strategy=max_std_sampling, # 选择预测标准差最大的点
X_training=X_train,
y_training=y_train
)
# 主动学习循环
n_queries = 10
for _ in range(n_queries):
query_idx, _ = learner.query(X)
X_train = np.vstack((X_train, X[query_idx]))
y_train = np.append(y_train, y[query_idx]) # 假设y已知(实际需人工标注)
learner.teach(X_train, y_train)
print(f"新增样本 x={X[query_idx][0]:.2f}, y={y[query_idx]:.2f}")半监督学习(Semi-Supervised Learning)
TSVM
Transductive Support Vector Machine (TSVM) 是一种半监督学习算法,扩展了传统支持向量机(SVM)的框架,同时利用标注数据和未标注数据进行模型训练,特别适用于标注数据稀缺的场景。其核心思想是通过未标注数据的分布信息优化决策边界,提升模型泛化能力。
核心思想
- 转导学习(Transductive Learning):不同于归纳学习(Inductive Learning,从训练集泛化到全局分布),TSVM 直接针对测试集(未标注数据)优化模型,假设测试数据在训练时已知(但无标签)。
- 目标:找到能将标注数据正确分类且与未标注数据分布一致的决策边界。
数学形式

代码实现
以下是使用 scikit-learn 和 TSVM 的简化示例(需安装 sklearn-semi-supervised 扩展库):
import numpy as np
from sklearn.svm import SVC
from sklearn.semi_supervised import SelfTrainingClassifier
from sklearn.datasets import make_classification
# 生成可分离的数据(100个样本,2类)
X, y_true = make_classification(
n_samples=100, n_features=2, n_classes=2,
n_informative=2, n_redundant=0, n_repeated=0,
random_state=42
)
y = np.copy(y_true)
y[10:] = -1 # 仅前10个点标注(5正+5负)
# 使用自训练SVM(高置信度阈值)
base_svm = SVC(kernel='linear', probability=True, random_state=42)
tsvm = SelfTrainingClassifier(base_svm, threshold=0.9) # 提高阈值避免单类问题
tsvm.fit(X, y)
# 输出伪标签结果
print("未标注数据的伪标签分布:", np.unique(tsvm.transduction_[10:], return_counts=True))未标注数据的伪标签分布: (array([-1, 0, 1]), array([35, 31, 24], dtype=int64))array([-1, 0, 1])表示在未标注数据中,被分配的伪标签包括-1、0和1:-1:仍未被模型分配伪标签(即模型置信度不够,不愿意分类);0:被模型分配为第0类;1:被模型分配为第1类;
array([35, 31, 24])表示上述三个标签的数量:- 35 个数据仍然是
-1,说明模型没有对它们打上伪标签; - 31 个被打上了伪标签
0; - 24 个被打上了伪标签
1。
- 35 个数据仍然是
- 这说明设定的
threshold=0.9起到了作用:只有模型非常有信心时才打伪标签,否则就保留原样-1。这有助于减少“单类伪标签过多”的问题。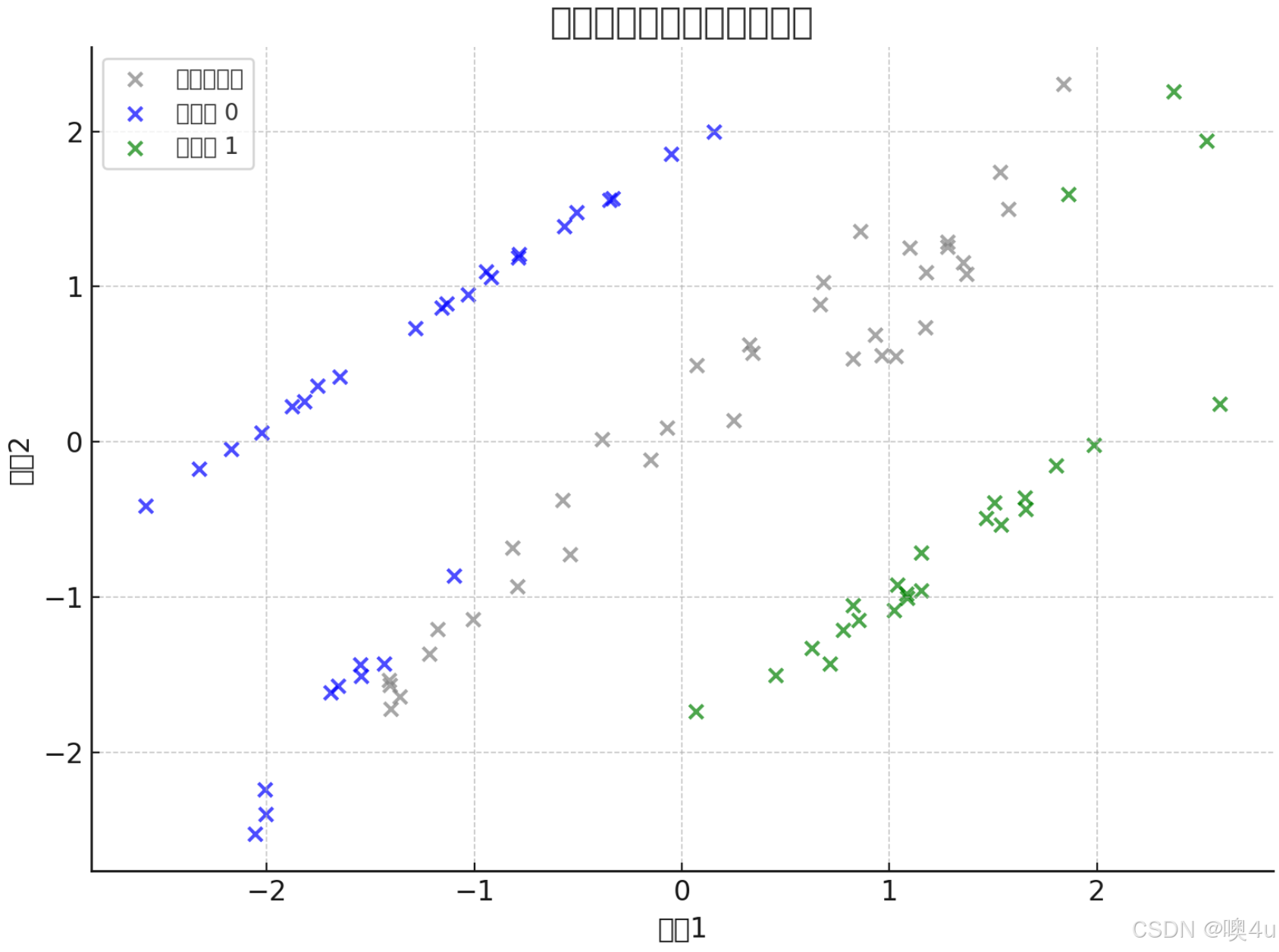
应用场景
- 文本分类:少量标注文章 + 大量未标注网页。
- 图像识别:医学图像标注成本高时,利用未标注扫描结果。
- 生物信息学:基因表达数据中标注样本有限。
局限性
- 对噪声敏感:未标注数据中的噪声可能导致伪标签错误传播。
- 假设强依赖:低密度分离假设在复杂分布中可能不成立。
- 计算成本高:大规模未标注数据时优化困难。
图半监督学习
图半监督学习是一种利用数据间的图结构关系(如相似性、连接性)和少量标注数据共同训练模型的方法。其核心假设是相邻节点在图上具有相似的标签(平滑性假设),适用于标注成本高但数据关系明确的场景(如社交网络、蛋白质相互作用)。
核心思想
- 将数据表示为图:节点=样本,边=样本间的关系(如相似度、距离)。
- 标签传播(Label Propagation):标注节点的标签通过图结构传递到未标注节点。
- 目标:最小化标注数据的预测误差,同时保证图上相邻节点的标签一致性。
数学形式

训练步骤
- 构建图:计算所有样本对的相似度矩阵 W。
- 初始化标签矩阵 Y:已标注节点固定标签,未标注节点设0。
- 迭代传播:
- 更新未标注节点的标签。
- 重复直至收敛(或固定迭代次数)。
- 输出预测:未标注节点的最终标签 Fj。
特点
| 特性 | 说明 |
|---|---|
| 数据驱动 | 依赖图结构的质量(相似度计算需合理)。 |
| 低密度分离 | 假设决策边界位于图上的低密度区域。 |
| 计算复杂度 | 邻接矩阵存储为 O(n2)O(n2),适合中小规模数据。 |
| 无需模型假设 | 不预设分布形式,直接利用图结构。 |
代码实现
使用 scikit-learn 的 LabelPropagation:
import numpy as np
from sklearn.semi_supervised import LabelPropagation
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# 生成数据(2个月牙形类别,仅标注4个点)
X, y_true = make_moons(n_samples=200, noise=0.1, random_state=42)
y = np.copy(y_true)
y[10:] = -1 # 未标注样本标记为-1(仅前10个点有标签)
# 训练标签传播模型
model = LabelPropagation(kernel='rbf', gamma=10, max_iter=100)
model.fit(X, y)
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=model.transduction_, cmap='viridis', alpha=0.5)
plt.scatter(X[y_true != -1, 0], X[y_true != -1, 1], c='red', marker='x', label="Labeled")
plt.legend()
plt.title("Label Propagation Result")
plt.show()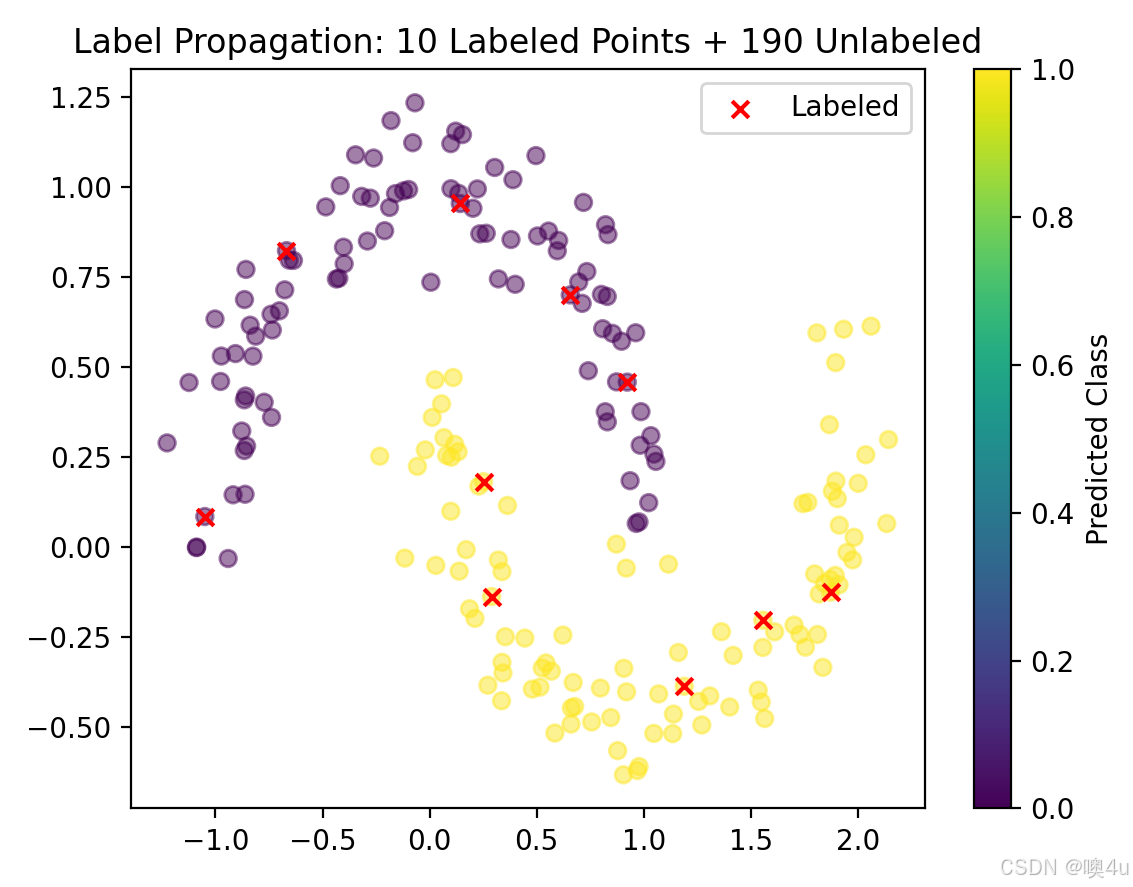
应用场景
| 领域 | 应用案例 |
|---|---|
| 社交网络 | 用户分类(如政治倾向预测,基于好友关系)。 |
| 生物信息学 | 蛋白质功能预测(基于相互作用网络)。 |
| 推荐系统 | 冷启动问题(利用用户-商品交互图传播标签)。 |
| 计算机视觉 | 图像分割(像素相似性构图,少量标注区域传播到全图)。 |
局限性
- 图构建敏感性:相似度计算(如高斯核的 σ)影响性能。
- 标注数据不足时失效:若初始标注节点位于噪声区域,传播结果可能错误。
- 计算瓶颈:邻接矩阵需要 O(n^2)存储,难以扩展到超大规模数据。
- 异质图挑战:若节点/边类型复杂(如多模态数据),需更复杂的图神经网络(GNN)。
基于分歧的方法(多视图学习muti-view-learning)
多视图学习(Multi-View Learning)是一种利用数据的多个特征表示(视图)进行建模的方法,通过不同视图间的互补性和一致性提升模型性能。基于分歧的方法(如协同训练)是其核心范式之一,特别适用于标注数据稀缺但多源数据丰富的场景(如网页分类中的文本和链接、医学影像的多模态数据)。
核心思想
- 多视图假设:数据可以从多个独立或互补的视角(视图)描述,每个视图提供部分信息。
- 例如:网页数据 = 文本内容(视图1) + 超链接结构(视图2)。
- 分歧驱动:不同视图训练的模型对未标注样本的预测可能存在分歧,通过利用这些分歧选择高信息量的样本进行标注或协同训练。
- 目标:结合多个视图的优势,提升模型的泛化能力和鲁棒性。
数学形式

训练步骤(以协同训练为例)
- 初始化:对每个视图分别训练初始分类器 h1 和 h2(使用少量标注数据)。
- 迭代过程:
- 步骤1:每个分类器对未标注数据预测伪标签。
- 步骤2:选择两个分类器分歧最大的样本(如预测结果不一致的样本)。
- 步骤3:将高置信度的伪标签样本加入另一个分类器的训练集。
- 重复:直到收敛或达到标注预算。
- 输出:最终模型为两个分类器的集成(如投票或加权平均)。
特点
| 特性 | 说明 |
|---|---|
| 数据需求 | 需要多源/多模态数据,且视图间满足条件独立性假设。 |
| 标注效率 | 通过分歧选择高价值样本,显著减少标注成本。 |
| 鲁棒性 | 对单一视图的噪声或缺失更具容错性。 |
| 计算复杂度 | 高于单视图方法,需训练多个模型并协调分歧。 |
代码实现
使用 sklearn 实现协同训练(模拟双视图数据):
import numpy as np
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 生成模拟双视图数据(视图1=特征前2维,视图2=特征后2维)
X, y = make_classification(n_samples=100, n_features=4, n_classes=2, random_state=42)
view1 = X[:, :2] # 视图1
view2 = X[:, 2:] # 视图2
# 初始标注数据(10个点)
labeled_idx = np.random.choice(range(100), size=10, replace=False)
y_train = y[labeled_idx]
y_full = -np.ones(100) # 未标注标记为-1
y_full[labeled_idx] = y_train
# 初始化两个视图的分类器
clf1 = LogisticRegression(random_state=42)
clf2 = LogisticRegression(random_state=42)
# 协同训练迭代
n_queries = 20
for _ in range(n_queries):
# 训练两个分类器
clf1.fit(view1[labeled_idx], y_train)
clf2.fit(view2[labeled_idx], y_train)
# 预测未标注数据
pred1 = clf1.predict(view1[y_full == -1])
pred2 = clf2.predict(view2[y_full == -1])
# 选择分歧最大的样本(预测不一致的样本)
disagreement = np.where(pred1 != pred2)[0]
if len(disagreement) == 0:
break # 无分歧则停止
query_idx = disagreement[0]
# 模拟人工标注(这里用真实标签代替)
true_label = y[y_full == -1][query_idx]
labeled_idx = np.append(labeled_idx, np.where(y_full == -1)[0][query_idx])
y_train = np.append(y_train, true_label)
y_full[labeled_idx[-1]] = true_label
# 评估最终模型
final_pred = (clf1.predict_proba(view1)[:, 1] + clf2.predict_proba(view2)[:, 1]) / 2
final_pred = (final_pred > 0.5).astype(int)
print("协同训练准确率:", accuracy_score(y, final_pred))应用场景
| 领域 | 应用案例 |
|---|---|
| 网页分类 | 文本内容(视图1) + 超链接结构(视图2)协同训练。 |
| 医学诊断 | CT影像(视图1) + 病理报告文本(视图2)联合分析。 |
| 推荐系统 | 用户行为日志(视图1) + 社交网络关系(视图2)优化推荐。 |
| 多模态学习 | 图像(视图1) + 语音描述(视图2)的跨模态检索。 |
局限性
- 视图独立性假设:实际数据中视图间可能不完全独立,导致性能下降。
- 计算成本:需维护多个模型,对大规模数据不友好。
- 初始标注敏感:若初始标注数据不能覆盖视图特性,协同训练可能失效。
主动学习 vs 半监督学习
| 维度 | 主动学习 | 半监督学习 |
|---|---|---|
| 数据使用 | 主动选择少量样本标注 | 利用大量未标注数据辅助训练 |
| 标注成本 | 需要专家交互 | 无需额外标注 |
| 核心目标 | 减少标注量 | 利用未标注数据提升性能 |
| 典型方法 | 不确定性采样、QBC | 自训练、一致性正则化 |
| 适用场景 | 标注昂贵但专家可用 | 未标注数据丰富但标注稀缺 |
总结
主动学习与半监督学习都是在标注数据有限的条件下提升模型性能的重要手段。主动学习通过让模型主动选择最具信息价值的样本进行人工标注,从而最大化每个标注样本的效用,常用策略包括不确定性采样(如最小置信度、边缘采样、熵采样)、基于委员会的投票分歧、期望模型变化、样本多样性和混合策略,广泛应用于医学图像、语音识别、推荐系统等高标注成本场景;而半监督学习则侧重于利用大量未标注数据的结构信息,如TSVM通过引入未标注样本优化分类边界、图半监督学习依靠相似图结构进行标签传播、协同训练在多视图数据中通过分歧引导伪标签生成。两者的核心区别在于,主动学习强调“选哪些标”,而半监督学习则是“怎么用未标”。在实际应用中,这两种方法往往可以结合使用,以更高效地构建高性能模型。

















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









