









1.在某种形式上,机器学习就是做出预测。
2.经典统计学习技术中的线性回归和softmax回归可以视为 线性 神经网络。
3.权重决定了每个特征对我们预测值的影响。偏置是指当所有特征都取值为0时,预测值应该为多少。如果没有偏置项,我们模型的表达能力将受到限制。
4.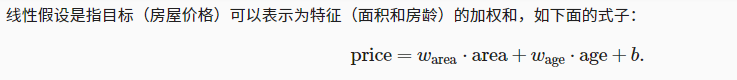
是输入特征的一个仿射变换(affine transformation)。仿射变换的特点是通过加权和对特征进行线性变换(linear transformation),并通过偏置项来进行平移(translation)。
开始寻找最好的 模型参数(model parameters) w 和 b 之前,我们还需要两个东西:(1)一种模型质量的度量方式(5.损失函数);(2)一种能够更新模型以提高模型预测质量的方法(6梯度下降)。
5.损失函数可以确定一个拟合程度的度量,能够量化目标的实际值与预测值之间的差距。通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。回归问题中最常用的损失函数是平方误差函数。
用公式简单表示的线性回归的解叫做解析解,
首先,我们将偏置 b 合并到参数 w 中。合并方法是在包含所有参数的矩阵中附加一列。我们的预测问题是最小化 ∥y−Xw∥2 。这在损失平面上只有一个临界点,这个临界点对应于整个区域的损失最小值。将损失关于 w 的导数设为0,得到解析解(闭合形式):
w∗=(X⊤X)−1X⊤y.
像线性回归这样的简单问题存在解析解,但并不是所有的问题都存在解析解。解析解可以进行很好的数学分析,但解析解的限制很严格,导致它无法应用在深度学习里。
6.梯度下降(gradient descent)的方法,这种方法几乎可以优化所有深度学习模型。它通过不断地在降低损失的方向上更新参数来降低误差。

7.在训练了预先确定的若干迭代次数后(或者直到满足某些其他停止条件后),我们记录估计的模型参数,表示为 w,b 。但是,即使我们的函数真是线性的且无噪声。我们估计得到的参数也不会是损失的精确最小值。因为算法会使得损失向最小值缓慢收敛,但不能在有限的步数内非常精确地达到最小值。
8.
利用均方误差损失函数(简称均方损失)可以用于线性回归的一个原因是:假设观测中包含噪声,其中噪声服从正态分布。















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









