







本文主要是pytorch个人学习的一个笔记和记录,输出往往比输入更重要,我希望通过输出的模式来加深印象。(本文是基于深度之眼Pytorch框架班课程的学习记录)
第一章 张量(Tensor)
1.1张量的基本介绍
张量:是一个多维数组,它是标量、向量、矩阵的高位拓展。
用图片更能直观的感受到张量和标量、向量、矩阵的区别:
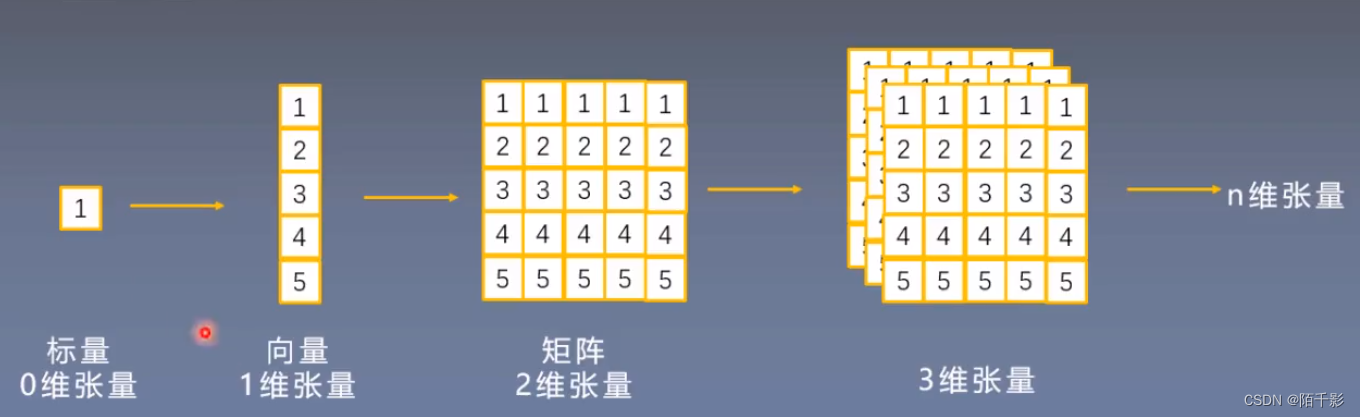
标量是一个0维的数据,它没有方向。
向量是一维的数据,数据沿着一个方向顺序存放。
矩阵是一个二维的数组,常见的如灰度图像就是用矩阵存储。
RGB图像没法用矩阵进行存储,这时就需要引入更高维,例如使用三维的张量来存储数据。
Pytorch中有专门用来存储张量的数据类型:torch.Tensor
它主要包括七个属性:
(1)data:张量的数据
(2)dtype:张量的数据类型,例如torch.FloatTensor,torch.cuda.FloatTensor
(3)shape:张量的形状,如(64, 3, 224, 224)
(4)device:张量所在的设备,GPU/CPU,是加速的关键
(5)grad:data的梯度
(6)grad_fn:创建Tensor的Function,是自动求导的关键
(6)requires_grad:表示是否需要梯度
(7)is_leaf:表示是否是叶子节点
1.2张量的创建
一、直接创建
torch.tensor(data, dtype=None, device=None, requires_grad=False, pin_memory=False )
其中 data是数据,它可以是list,也可以是numpy;dtype是数据的类型,默认与data保持一致;device是指该张量所在的设备,cuda或者gpu,requires_grad则表示当前张量是否需要梯度;
pin_memory则表示是否存于锁页内存(不太清楚)。
下面是代码实现创建一个张量:
import torch
import numpy as np
arr = np.ones((3, 3))
print("ndarray的数据类型:", arr.dtype)
t = torch.tensor(arr)
print(t)最终的输出结果如下:
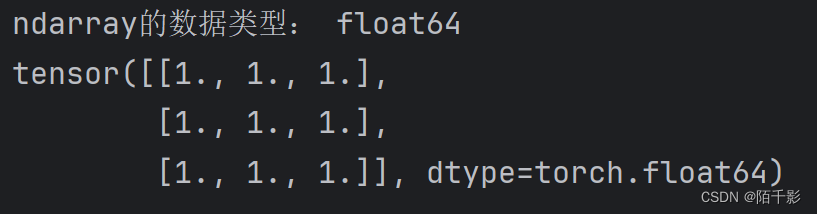
该张量是基于numpy创建出来的一个二维张量,它的dtype和arr的数据类型一样是float64。
注意:从torch.from_numpy创建的tensor同原ndarray共享内存,当修改其中一个的数据,另一个数据也会被改动。
二、依据数值创建
torch.zeros(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
其中,size是张量的形状,如(3, 3),(3,224,224)等;out为输出的张量;layout是内存中的布局形式,有strided,sparse_coo等。
代码实现:
out_t = torch.tensor([1])
t = torch.zeros((3, 3), out=out_t)
print(t, '\n', out_t)结果:

torch.zeros_like(input, dtype=None, layout=None, device=None, requires_grad=False)
它的功能是依据input的形状来创建一个全0的张量。
torch.ones_like(input, dtype=None, layout=None, device=None, requires_grad=False)
它的功能则是依据input的形状来创建一个全1的张量。
torch.full(size, fill.value, out=None, dtype=None, layout=torch.strided, device=None,requires_grad=False)
其中size是张量的形状,fill_value是张量的值。
torch.arange(start=0, end, step=1, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
功能是创建等差的一维张量,数值区间为[start, end)
其他还包括torch.linspace(),用来创建均分的一维张量,数值区间为[start, end]
torch.logspace(),创建对数均分的一维张量,长度为steps,底为base
torch.eye(),功能是创建单位对角矩阵(二维张量),默认为方阵。其中n为行数,m为列数。
三、依据概率分布创建张量
torch.normal(mean, std, out=None)
mean:均值,std:标准差
它具有四种模式:mean为标量,std为标量
mean为标量,std为张量
mean为张量,std为标量
mean为张量,std为张量
通过代码理解更加清晰:
#mean:张量 std:张量
mean = torch.arange(1, 5, dtype=torch.float)
std = torch.arange(1, 5, dtype=torch.float)
t_normal = torch.normal(mean, std)
print("mean:{}\nstd:{}".format(mean, std))
print(t_normal)

# mean:标量 std:标量
t_normal = torch.normal(0, 1, size=(4,))
print(t_normal)
# mean: 张量 std:标量
mean = torch.arange(1, 5, dtype=torch.float)
std = 1
t_normal = torch.normal(mean, std)
print("mean:{}\nstd:{}".format(mean, std))
print(t_normal)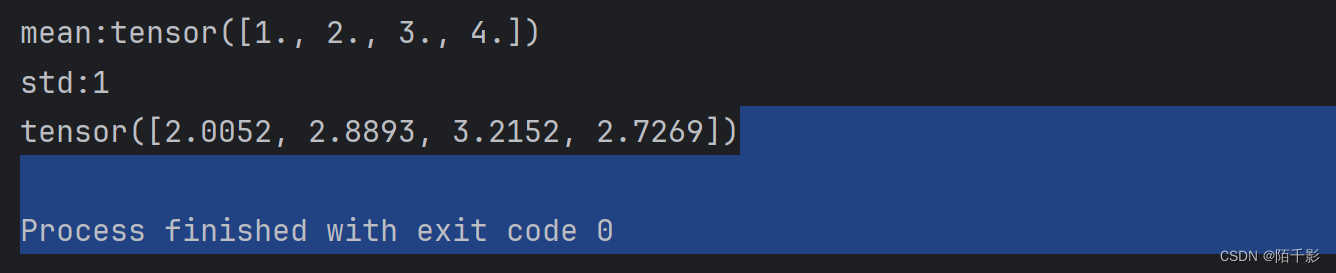
torch.randn() torch.randn_like()功能是生产标准正态分布。
torch.rand() torch.rand_like()功能是在[0, 1)生成均匀分布。
torch.randint() torch.randint_like() 是在区间[low, high)生成整数均匀分布。
torch.randperm() 功能是生成从0到n-1的随机排列
torch.bernoulli() 功能是以input为概率,生成伯努利分布(0-1分布, 两点分布)
1.3张量的操作
张量的操作主要包括了拼接、切分、索引以及变换。
1.3.1张量的拼接
张量的拼接主要包括两个方法,一个是cat,一个是stack。
torch.cat(tensors, dim=0, out=None)
功能是将张量按维度dim进行拼接;tensors表示张量的序列,dim为要拼接的维度。
torch.stack(tensors, dim=0, out=None)
功能是在新创建的维度dim上进行拼接。
两者的区别主要是cat不会扩张张量的维度,而stack会扩张张量的维度。
t = torch.ones((3, 3))
t_0 = torch.cat([t, t], dim=0)
t_1 = torch.cat([t, t], dim=1)
print("t_0:{} shape;{}\nt_1;{} shape;{}".format(t_0, t_0.shape, t_1, t_1.shape))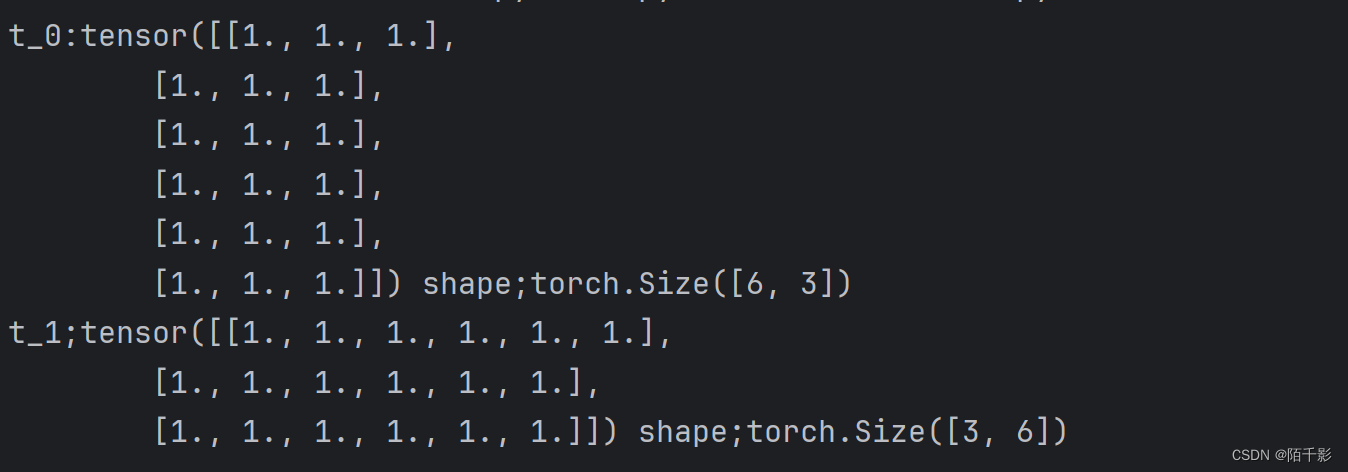
t = torch.ones((2, 3))
t_stack = torch.stack([t, t], dim=2)
print("\nt_stack;{} shape;{}".format(t_stack, t_stack.shape))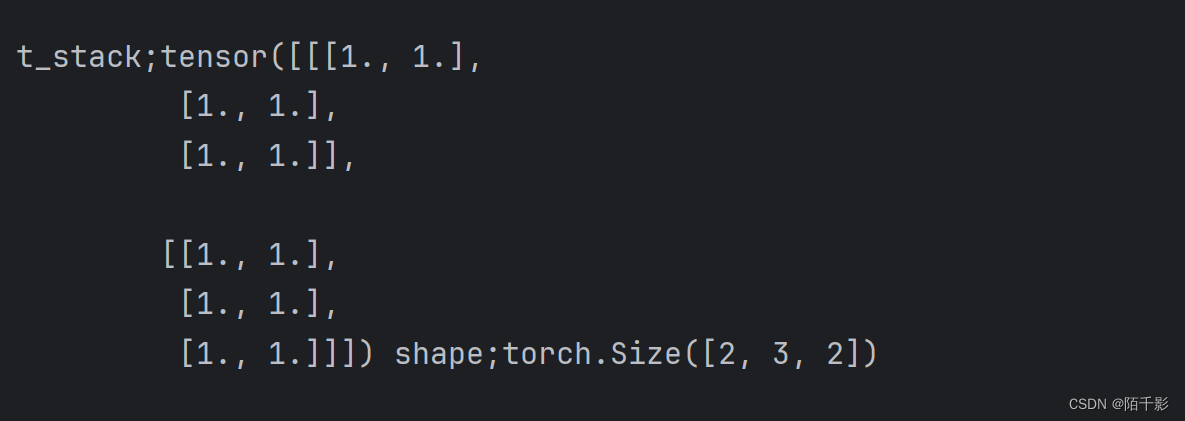
1.3.2 张量的切分
torch.chunk(input, chunks, dim=0)
功能是将张量按维度dim进行平均切分,若不能整除,则最后一份张量小于其他张量。
input是要切分的张量,chunks是要切分的份数,dim是要切分的维度。
具体的代码实现:
a = torch.ones((2, 5))
list_of_tensors = torch.chunk(a, dim=1, chunks=2)
for idx, t in enumerate(list_of_tensors):
print("第{}个张量:{},shape is {}".format(idx+1, t, t.shape)) torch.split(tensor, split_size_or_sections, dim=0)
torch.split(tensor, split_size_or_sections, dim=0)
split_size_or_sections为int是,表示每一份的长度;为list时,按list元素进行切分。当使用list是,list之和一定要等于dim的长度,否则会报错。
1.3.3 张量的索引
torch.index_select(input, dim, index, out=None)
功能是在维度dim上,按index索引数据。返回值:依index索引数据所拼接的张量。
input是要索引的张量,dim是要索引的维度,index是要索引的序号。
下面是具体的代码实现:
t = torch.randint(0, 9, size=(3, 3))
idx = torch.tensor([0, 2], dtype=torch.long)
t_select = torch.index_select(t, dim=0, index=idx)
print("t:\n{}\nt_select:\n{}".format(t, t_select)) 
torch.masked_select(input, mask, out=None)
功能是按mask中的True进行索引,返回值是一个一维的张量。
1.3.4 张量的变换
torch.reshape(input, shape)
功能是变换张量的形状。注意:当张量在内存中是连续的时,新的张量与input共享数据内存。
代码实现:
t = torch.randperm(8)
t_reshape = torch.reshape(t, (2, 4))
print("t:{}\nt_reshape:\n{}".format(t, t_reshape))
torch.transpose(input, dim0, dim1)
功能:交换张量的两个维度。
torch.squeeze(input, dim=None, out=None)
功能:压缩长度为1的维度,dim:如果为None,移除所有长度为1的轴;若指定维度,当且仅当该轴长度为1时,可以被移除。
torch.unsqueeze(input, dim, out=None)
功能:依据dim扩展维度。
1.4 张量的数学运算
张量的数学运算主要包括加减乘除、对数、指数、幂函数、三角函数等。
torch.add() torch.addcdiv() torch.addcmul() torch.sub() torch.div() torch.mul()
torch.log(input, out=None) torch.log10(input, out=None) torch.log2(input, out=None)
torch.exp(input, out=None)
torch.pow()
torch.abs(input, out=None) torch.acos(input, out=None) torch.cosh(input, out=None)
torch.cos(input, out=None) torch.asin(input, out=None) torch.atan(input, out=None) 等。
篇幅有限,就不一一演示。
1.5 线性回归
基于以上的张量学习内容,我们来构造一个一元线性回归模型来检验学习成果。
先简单介绍一下线性回归。线性回归就是分析一个变量与另外一个或者多个变量之间关系的方法。
举个简单的例子: 因变量:y 自变量:x 他们的关系是:线性
y = wx + b
分析:求解w, b
求解的步骤:
1.确定模型: Model: y = wx + b
2.选择损失函数: MSE(函数公式太难打就放弃了)
3.求解梯度并且更新w,b w = w - LR * w.grad
b = b - LR * w.grad
具体实现:
import torch
import matplotlib.pyplot as plt
torch.manual_seed(10)
lr = 0.05 # 学习率 20191015修改
# 创建训练数据
x = torch.rand(20, 1) * 10 # x data (tensor), shape=(20, 1)
y = 2*x + (5 + torch.randn(20, 1)) # y data (tensor), shape=(20, 1)
# 构建线性回归参数
w = torch.randn((1), requires_grad=True)
b = torch.zeros((1), requires_grad=True)
for iteration in range(1000):
# 前向传播
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# 计算 MSE loss
loss = (0.5 * (y - y_pred) ** 2).mean()
# 反向传播
loss.backward()
# 更新参数
b.data.sub_(lr * b.grad)
w.data.sub_(lr * w.grad)
# 清零张量的梯度 20191015增加
w.grad.zero_()
b.grad.zero_()
# 绘图
if iteration % 20 == 0:
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-', lw=5)
plt.text(2, 20, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.xlim(1.5, 10)
plt.ylim(8, 28)
plt.title("Iteration: {}\nw: {} b: {}".format(iteration, w.data.numpy(), b.data.numpy()))
plt.pause(0.5)
if loss.data.numpy() < 1:
break 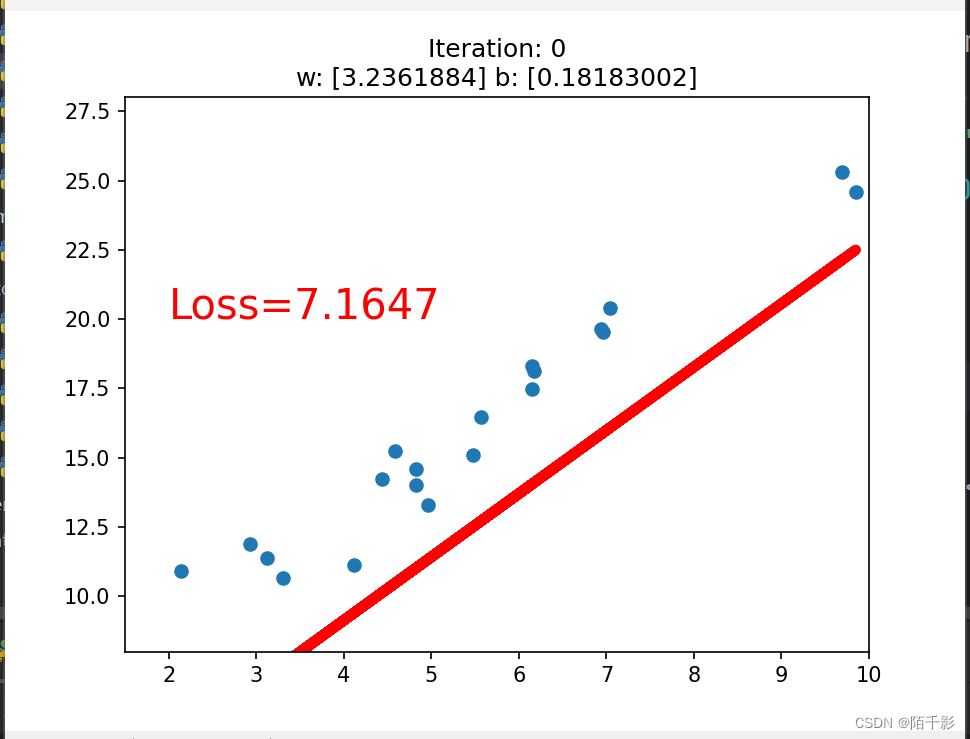
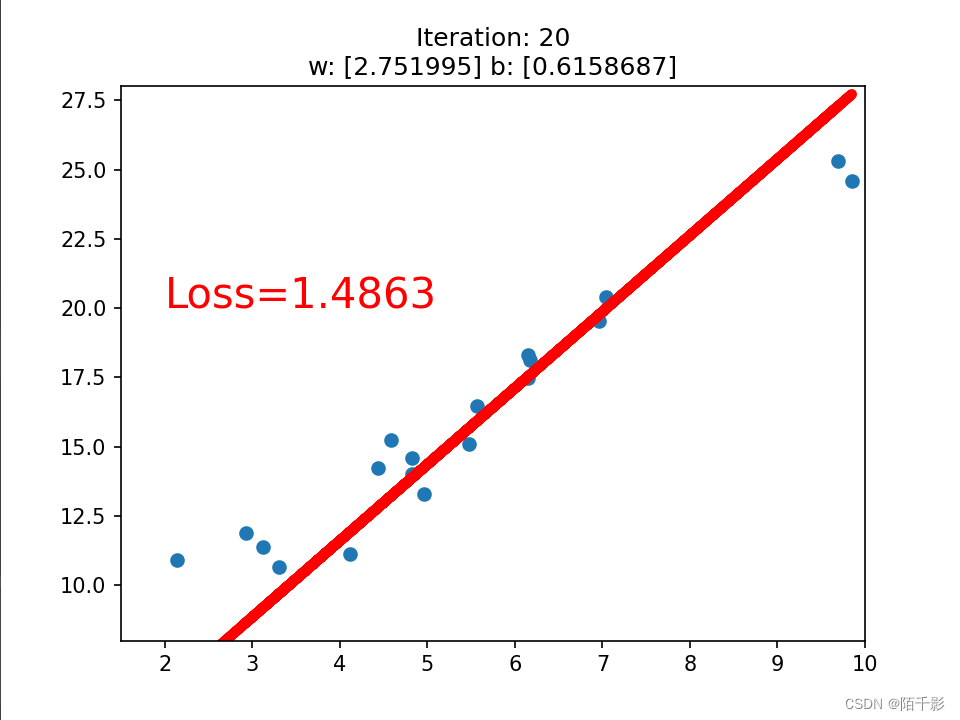
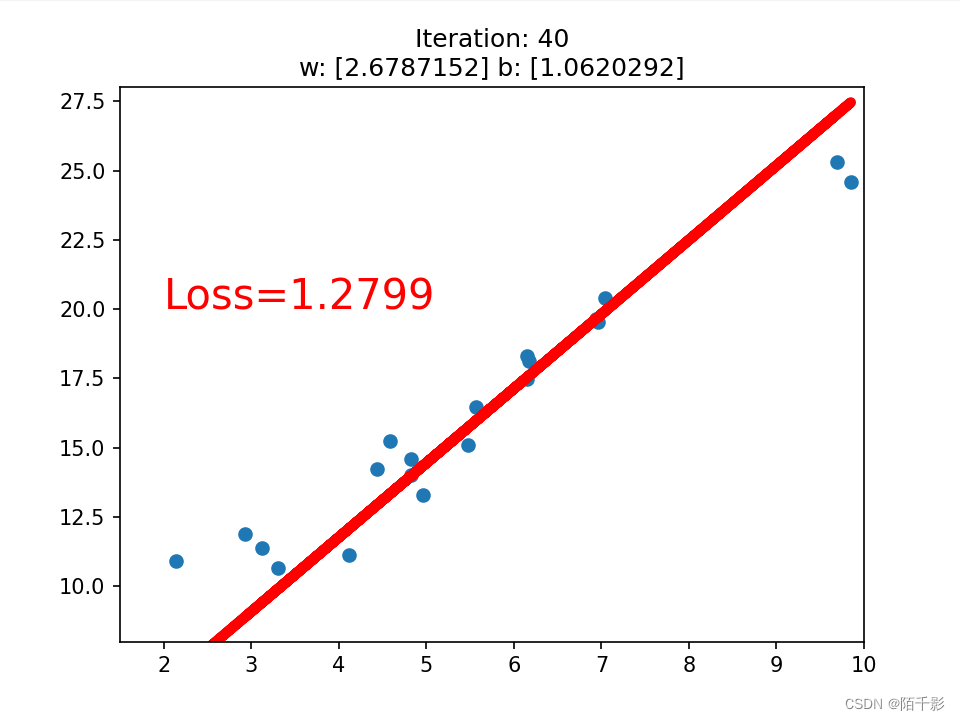
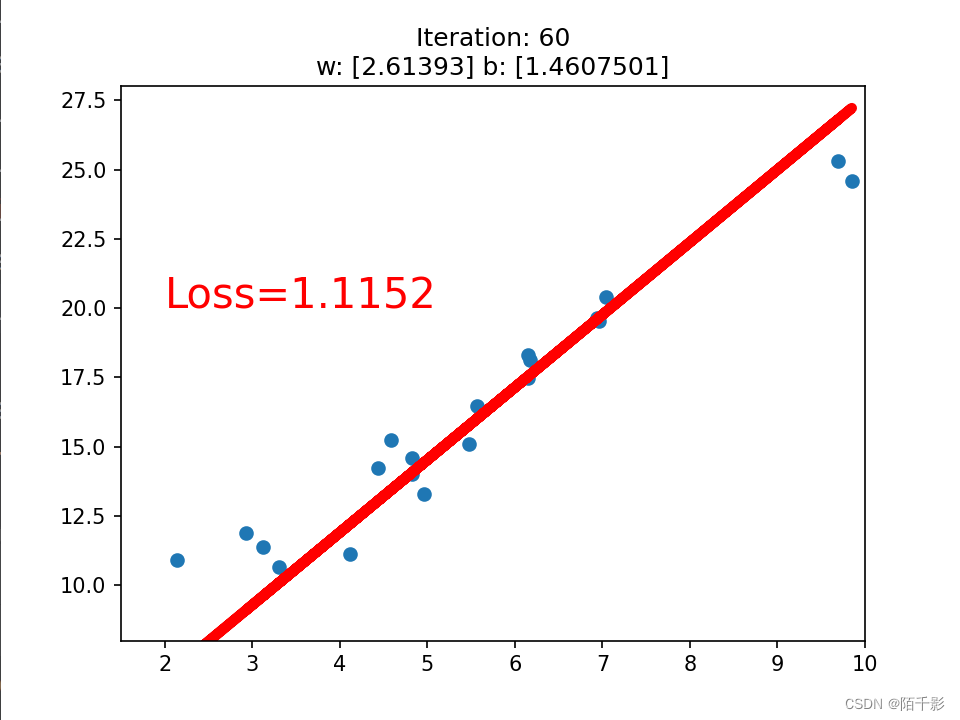
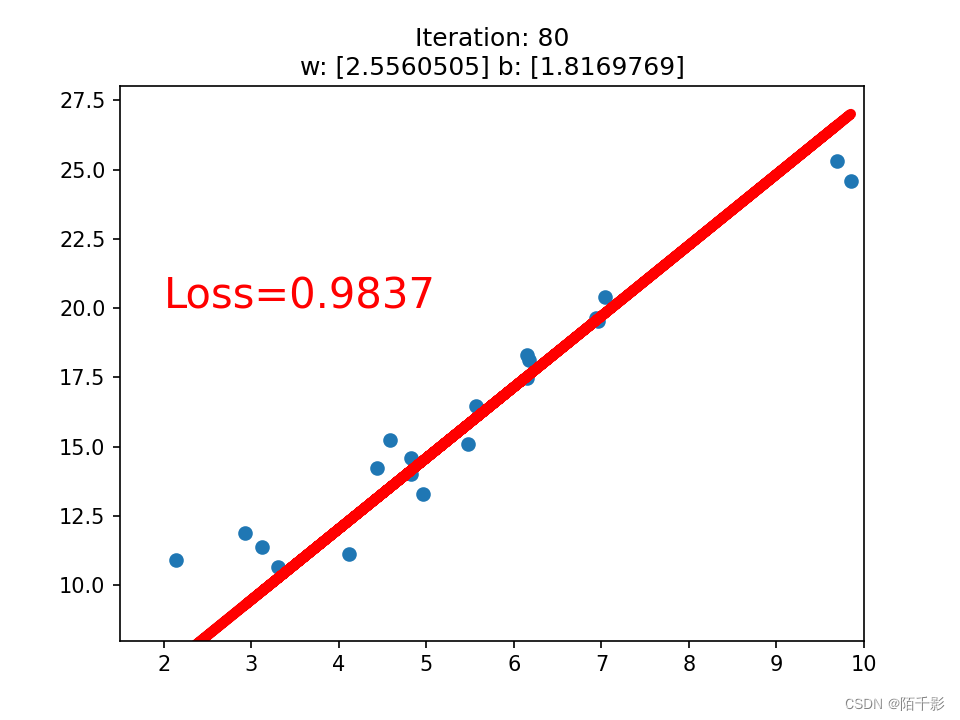
最终仅训练八十次左右就可以达到一个LOSS<1的先来拟合函数。
第二章 DataLoader与Dataset
2.1 DataLoader
DataLoader是在torch.utils.data.DataLoader下面。
DataLoder(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False,drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None)
参数比较多,下面一一叙述:
dataset是Dataset类,决定了数据从哪里读取以及如何读取。
batch_size:批大小。
num_workers:是否多进程读取数据。
shuffle:每个epoch是否是乱序的。
drop_last:当样本数不能呗batch_size整除时,是否舍弃最后一批的数据。
名词解释:
epoch:所有训练样本都已输入到模型中,成为一个Epoch
iteration:一批样本输入到模型中,称之为一个Iteration
batchsize:批大小,决定一个Epoch有多少个Iteration
例如:样本总数为80,batchsize为8
1 Epoch = 10 Iteration
2.2 Dataset
Dataset的功能是所有自定义的Dataset都需要继承他,并且复写__getitem__。
class Dataset(torch.utils.data.Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return len(self.data)
def __add__(self, other):
return Dataset(self.data + other.data)其中getitem功能是接收一个索引,然后返回一个样本。
具体实现就不过多赘述,许多代码里都会用到。
第三章 transforms
3.1 transforms介绍
transforms包括了许多常用的图像预处理方法:
数据中心化、数据标准化、缩放、裁剪、旋转、翻转、填充、噪声添加、灰度变换、线性变换、仿射变换、亮度、饱和度及对比度变换。
3.1.1 transforms.Normalize
transforms.Normalize(mean, std, inplace=False)
功能是逐channel的对图像进行标准化, output = (input - mean)/ std
mean:各通道的均值;std:各通道的标准差; inplace:是否进行原地操作
3.2 transforms数据预处理方法
3.2.1 数据增强
数据增强又称为数据增广,它是对训练集进行变换,使得训练集更丰富,让模型更具泛化能力。
3.2.2 裁剪(Crop)
1. transforms.CenterCrop 功能是从图像中心进行裁剪图片,参数size是所需裁剪图片的尺寸。
transforms.CenterCrop(196)通过该操作我将一个原本是255*255的图片转换为196*196.效果如下:

2.transmforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
功能是从图片中随机裁剪出尺寸为size的图片。size是所需裁剪图片尺寸,padding设置填充大小,当为a时,上下左右均填充a个像素,当为(a,b)时,上下填充b个像素,左右填充a个像素;当为(a,b,c,d)时,左上右下分别填充a,b,c,d。pad_if_need是若像素小于设定size,则会进行填充操作。
padding_mode:填充模式,一共有四种(1)constant:像素值由fill设定(2)edge:像素值由图像边缘像素决定(3)reflect:镜像填充,最后一个像素不镜像(4)symmetric:镜像填充,最后一个像素也镜像。
transforms.RandomCrop(224, padding=(16, 64))得到图像效果如下:

transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric')

3. RandomResizedCrop(size, scale=(0.08, 10.), ratio=(3/4, 4/3), interpolation)
功能是随机大小、长宽比裁剪图片。size是所需裁剪图片尺寸,scale是随机裁剪面积比例,默认是(0.08,1),ratio随机长宽比,默认(3/4, 4/3),interpolation是插值方法。
transforms.RandomResizedCrop(size=224, scale=(0.08, 1))得到的效果如下:

4. FiveCrop和TenCrop,篇幅有限,不过多赘叙。
3.3 翻转、旋转
3.3.1 Flip(翻转)
RandomHorizontalFlip(p=0.5) RandomVerticalFlip(p=0.5)
分别为图像的水平翻转和垂直翻转,其中p为翻转概率。
transforms.RandomHorizontalFlip(p=1) 效果如下:

3.3.2 Rotation(旋转)
RandomRotation(degrees, resample=False, expand=False, center=None)
功能是随机旋转图片,degreees是旋转角度,当为a时,在(-a,a)之间选择旋转角度,当为(a,b)时,在(a,b)之间选择旋转角度;resample:重采样方法;expand:是否扩大图片,以保持原图信息。center时旋转点设置,默认时中心旋转。
transforms.RandomRotation(30, center=(0, 0)), transforms.RandomRotation(30, center=(0, 0), expand=True),效果图如下:

















 235
235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









