









目录
实验目的:
加深对汉语文本信息处理基础理论及方法的认识和了解,锻炼和提高分析问题、解决问题的能力。通过对具体项目的任务分析、数据准备、算法设计和编码实现以及测试评价几个环节的练习,基本掌握实现一个自然语言处理系统的基本过程。
实验要求:
1.将199801.txt处理成单字与4个构词位置标记的分词语料。4个构词位置标记为:B:词首,M:词中,E:词尾,S:单独成词。
2.将语料分成测试集与训练集(一般为4:1的比例)。在训练集上统计估算初始概率、发射概率、转移概率所需的参数。
3.利用Viterbi算法, 实现基于HMM的字标注的分词程序。
参考代码:
任务1
with open("199801.txt") as f1:
str1=f1.read()
list1=str1.split('/')
with open("临时.txt",'w+',encoding='utf-8') as f2:
for i in list1:
str2=i.strip('/abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
'[]《》,;:、●19980131-04-013-0045672“”()『』①②③④⑤⑥').strip("\n")
f2.write(str2)
f2.seek(0)
list2=f2.readlines()
# 去除空格:
for i in range(0, list2.__len__(), 1): # (开始/左边界, 结束/右边界, 步长)
list0 = [] ## 空列表, 将第i行数据存入list中
for word in list2[i].split():
word = word.strip(' ')
list0.append(word)
with open("分词语料.txt", 'w+',encoding='utf-8') as f3:
for i in list0:
list1 = list(i)
if len(i) == 1:
list1[0] += "/S "
elif len(i) == 2:
list1[0] += "/B "
list1[1] += "/E "
else:
list1[0] += "/B "
list1[-1] += "/E "
for i in range(1, len(list1)):
list1[i] += "/M "
for i in list1:
f3.write(i+'')
任务2
def split_data(file,r,ftrain,ftest):
f=open(file,'r',encoding='utf-8')
s=f.read()
l=s.split(' ')
# l_train=l[:int(r*len(l))]
# l_test=l[int(r*len(l)):]
# for i in l_train:
# with open(ftrain, 'w', encoding='utf-8') as f1:
# f1.write(i+' ')
# for i in l_test:
# with open(ftest, 'w', encoding='utf-8') as f2:
# f2.write(i+' ')
k=0
with open(ftrain,'w+',encoding='utf-8')as f1:
with open(ftest,'w+',encoding='utf-8')as f2:
for i in l:
if k<int(r*len(l)):#训练集
f1.write(i+' ')
k+=1
else:#测试集
f2.write(i+' ')
k+=1
f.close()
# 设置划分比例 (ratio为训练集占比)
r = 0.8
# 划分数据集
split_data('分词语料.txt',r,'train_data.txt','test_data.txt')
#start 句子数
#ts /S在句子开头的个数 te tb tm也是一样
#ns /S的总个数 nb nm ne 也是一样
#nbs 为前一个标记为/S,后一个标记为/B的个数 其他的以此类推
with open("train_data.txt",encoding='utf-8') as f1:
s1=f1.read()
start=s1.count('。')+s1.count('?')+s1.count('!')#计算句子数
l1=s1.split(' ')#将带有字标记的词表按空格分开,列表每个元素格式是:字/标记
# x=dict()
# l1.count('/S')
# x.update(S=l1.count('/S'))
# print(s1[1])
#初始概率
ts=tb=tm=te=0
#统计第一个字是哪个标记
if '/S' in l1[0]:
ts += 1
elif '/B' in l1[0]:
tb += 1
elif '/E' in l1[0]:
te += 1
elif '/M' in l1[0]:
tm += 1
for i in range(0,len(l1)):
if l1[i]=='。/S'or l1[i]=='!/S'or l1[i]=='?/S':
if '/S' in l1[i+1]:
ts+=1
elif '/B' in l1[i+1]:
tb+=1
elif '/E' in l1[i+1]:
te+=1
elif '/M' in l1[i+1]:
tm+=1
with open("初始概率.txt",'w+',encoding='utf-8') as f2:
f2.write("分子\t分母\n")
f2.write('ts='+str(ts)+"\t"+'start='+str(start)+'\n')
f2.write('te='+str(te)+"\t"+'start='+str(start)+'\n')
f2.write('tb='+str(tb)+"\t"+'start='+str(start)+'\n')
f2.write('tm='+str(tm)+"\t"+'start='+str(start))
# f2.write('start='+str(start)+' ts='+str(ts)+' tb='+str(tb)+' te='+str(te)+' tm='+str(tm))
# print("初始概率:")
# print('P(/S|start)='+str(ts/start))
# print('P(/B|start)='+str(tb/start))
# print('P(/E|start)='+str(te/start))
# print('P(/M|start)='+str(tm/start))
#转移概率
ns=nb=ne=nm=0
nss=nse=nsm=nsb=0
nee=nes=neb=nem=0
nmm=nme=nmb=nms=0
nbb=nbe=nbm=nbs=0
for i in range(0,len(l1)):
if '/S' in l1[i]:
ns+=1
if '/S' in l1[i+1]:
nss+=1
elif '/B' in l1[i+1]:
nbs+=1
elif '/E' in l1[i+1]:
nes+=1
elif '/M' in l1[i+1]:
nms+=1
elif '/E' in l1[i]:
ne+=1
if '/S' in l1[i+1]:
nse+=1
elif '/B' in l1[i+1]:
nbe+=1
elif '/E' in l1[i+1]:
nee+=1
elif '/M' in l1[i+1]:
nme+=1
elif '/B' in l1[i]:
nb+=1
if '/S' in l1[i+1]:
nsb+=1
elif '/B' in l1[i+1]:
nbb+=1
elif '/E' in l1[i+1]:
neb+=1
elif '/M' in l1[i+1]:
nmb+=1
elif '/M' in l1[i]:
nm+=1
if '/S' in l1[i+1]:
nsm+=1
elif '/B' in l1[i+1]:
nbm+=1
elif '/E' in l1[i+1]:
nem+=1
elif '/M' in l1[i+1]:
nmm+=1
with open("转移概率.txt",'w+',encoding='utf-8')as f3:
f3.write("分子\t分母\n")
f3.write('nss='+str(nss)+'\t'+"ns="+str(ns)+'\n')
f3.write('nbs='+str(nbs)+'\t'+"ns="+str(ns)+'\n')
f3.write('nes='+str(nes)+'\t'+"ns="+str(ns)+'\n')
f3.write('nms='+str(nms)+'\t'+"ns="+str(ns)+'\n')
f3.write('nse='+str(nse)+'\t'+"ne="+str(ne)+'\n')
f3.write('nbe='+str(nbe)+'\t'+"ne="+str(ne)+'\n')
f3.write('nee='+str(nee)+'\t'+"ne="+str(ne)+'\n')
f3.write('nme='+str(nme)+'\t'+"ne="+str(ne)+'\n')
f3.write('nsb='+str(nsb)+'\t'+"nb="+str(nb)+'\n')
f3.write('nbb='+str(nbb)+'\t'+"nb="+str(nb)+'\n')
f3.write('neb='+str(neb)+'\t'+"nb="+str(nb)+'\n')
f3.write('nmb='+str(nmb)+'\t'+"nb="+str(nb)+'\n')
f3.write('nsm='+str(nsm)+'\t'+"nm="+str(nm)+'\n')
f3.write('nbm='+str(nbm)+'\t'+"nm="+str(nm)+'\n')
f3.write('nem='+str(nem)+'\t'+"nm="+str(nm)+'\n')
f3.write('nmm='+str(nmm)+'\t'+"nm="+str(nm)+'\n')
# f3.write("nb="+str(nb)+" ns="+str(ns)+" nm="+str(nm)+" ne="+str(ne)+'\n'+'nss='+str(nss)
# +' nbs='+str(nbs)+' nes='+str(nes)+' nms='+str(nms)+' nss='+str(nss)+' nse='+str(nse)+' nbe='+str(nbe)+' nee='+str(nee)
# +' nme='+str(nme)+' nsb='+str(nsb)+' nbb='+str(nbb)+' neb='+str(neb)+' nmb='+str(nmb)+' nsm='+str(nsm)
# +' nbm='+str(nbm)+' nem='+str(nem)+' nmm='+str(nmm))
# print("转移概率:")
# print('P(/S|/S)=' + str(nss / ns))
# print('P(/B|/S)=' + str(nbs / ns))
# print('P(/E|/S)=' + str(nes / ns))
# print('P(/M|/S)=' + str(nms / ns))
# print('P(/S|/B)=' + str(nss / nb))
# print('P(/B|/B)=' + str(nbb / nb))
# print('P(/E|/B)=' + str(neb / nb))
# print('P(/M|/B)=' + str(nmb / nb))
# print('P(/S|/E)=' + str(nse / ne))
# print('P(/B|/E)=' + str(nbe / ne))
# print('P(/E|/E)=' + str(nee / ne))
# print('P(/M|/E)=' + str(nme / ne))
# print('P(/S|/M)=' + str(nsm / nm))
# print('P(/B|/M)=' + str(nbm / nm))
# print('P(/E|/M)=' + str(nem / nm))
# print('P(/M|/M)=' + str(nmm / nm))
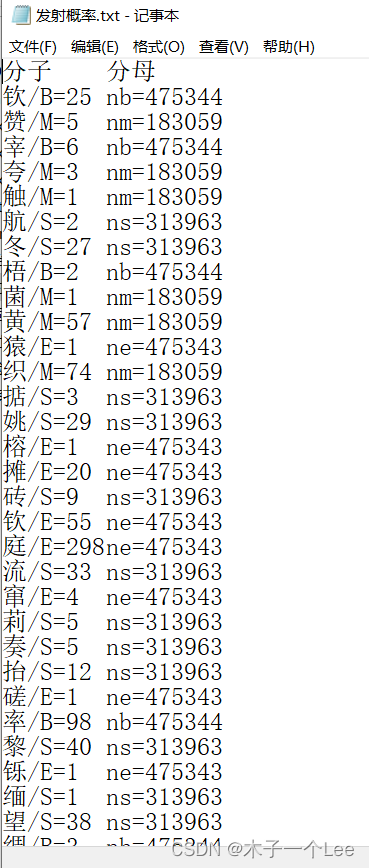
#发射概率
# print("发射概率:")
with open("发射概率.txt", 'w+',encoding='utf-8') as f4:
f4.write("分子\t分母\n")
# f4.write("nb="+str(nb)+" ns="+str(ns)+" nm="+str(nm)+" ne="+str(ne)+'\n')
set1=set(l1)#剔除重复
l2=[]
for i in set1:
if '/S' in i:
f4.write(i+'='+str(l1.count(i))+"\tns="+str(ns)+'\n')
elif '/B' in i:
f4.write(i+'='+str(l1.count(i))+"\tnb="+str(nb)+'\n')
elif '/E' in i:
f4.write(i+'='+str(l1.count(i))+"\tne="+str(ne)+'\n')
elif '/M' in i:
f4.write(i+'='+str(l1.count(i))+"\tnm="+str(nm)+'\n')任务3:
import json
import pandas as pd
class Hmm:
def __init__(self):
self.trans_p = {'S': {}, 'B': {}, 'M': {}, 'E': {}}
self.emit_p = {'S': {}, 'B': {}, 'M': {}, 'E': {}}
self.start_p = {'S': 0, 'B': 0, 'M': 0, 'E': 0}
self.state_num = {'S': 0, 'B': 0, 'M': 0, 'E': 0}
self.state_list = ['S', 'B', 'M', 'E']
self.line_num = 0
self.smooth = 1e-6
@staticmethod
def __state(word):
"""获取词语的BOS标签,标注采用 4-tag 标注方法,
tag = {S,B,M,E},S表示单字为词,B表示词的首字,M表示词的中间字,E表示词的结尾字
Args:
word (string): 函数返回词语 word 的状态标签
"""
if len(word) == 1:
state = ['S']
else:
state = list('B' + 'M' * (len(word) - 2) + 'E')
return state
def train(self, filepath, save_model=False):
"""训练hmm, 学习发射概率、转移概率等参数
Args:
save_model: 是否保存模型参数
filepath (string): 训练预料的路径
"""
print("正在训练模型……")
with open(filepath, 'r',encoding='utf-8') as f:
for line in f.readlines():
self.line_num += 1
line = line.strip().split()
# 获取观测(字符)序列
char_seq = list(''.join(line))
# 获取状态(BMES)序列
state_seq = []
for word in line:
state_seq.extend(self.__state(word))
# 判断是否等长
assert len(char_seq) == len(state_seq)
# 统计参数
for i, s in enumerate(state_seq):
self.state_num[s] = self.state_num.get(s, 0) + 1.0
self.emit_p[s][char_seq[i]] = self.emit_p[s].get(
char_seq[i], 0) + 1.0
if i == 0:
self.start_p[s] += 1.0
else:
last_s = state_seq[i - 1]
self.trans_p[last_s][s] = self.trans_p[last_s].get(
s, 0) + 1.0
# 归一化:
self.start_p = {
k: (v + 1.0) / (self.line_num + 4)
for k, v in self.start_p.items()
}
self.emit_p = {
k: {w: num / self.state_num[k]
for w, num in dic.items()}
for k, dic in self.emit_p.items()
}
self.trans_p = {
k1: {k2: num / self.state_num[k1]
for k2, num in dic.items()}
for k1, dic in self.trans_p.items()
}
print("训练完成!")
# 保存参数
if save_model:
parameters = {
'start_p': self.start_p,
'trans_p': self.trans_p,
'emit_p': self.emit_p
}
jsonstr = json.dumps(parameters, ensure_ascii=False, indent=4)
param_filepath = "HmmParam_Token.json"
with open(param_filepath, 'w') as jsonfile:
jsonfile.write(jsonstr)
def viterbi(self, text):
"""Viterbi 算法
Args:
text (string): 句子
Returns:
list: 最优标注序列
"""
text = list(text)
dp = pd.DataFrame(index=self.state_list)
# 初始化 dp 矩阵 (prop,last_state)
dp[0] = [(self.start_p[s] * self.emit_p[s].get(text[0], self.smooth),
'_start_') for s in self.state_list]
# 动态规划地更新 dp 矩阵
for i, ch in enumerate(text[1:]): # 遍历句子中的每个字符 ch
dp_ch = []
for s in self.state_list: # 遍历当前字符的所有可能状态
emit = self.emit_p[s].get(ch, self.smooth)
# 遍历上一个字符的所有可能状态,寻找经过当前状态的最优路径
(prob, last_state) = max([
(dp.loc[ls, i][0] * self.trans_p[ls].get(s, self.smooth) *
emit, ls) for ls in self.state_list
])
dp_ch.append((prob, last_state))
dp[i + 1] = dp_ch
# 回溯最优路径
path = []
end = list(dp[len(text) - 1])
back_point = self.state_list[end.index(max(end))]
path.append(back_point)
for i in range(len(text) - 1, 0, -1):
back_point = dp.loc[back_point, i][1]
path.append(back_point)
path.reverse()
return path
def cut(self, text):
"""根据 viterbi 算法获得状态,根据状态切分句子
Args:
text (string): 待分词的句子
Returns:
list: 分词列表
"""
state = self.viterbi(text)
cut_res = []
begin = 0
for i, ch in enumerate(text):
if state[i] == 'B':
begin = i
elif state[i] == 'E':
cut_res.append(text[begin:i + 1])
elif state[i] == 'S':
cut_res.append(text[i])
cut_res.append(text[-1])
return cut_res
if __name__ == "__main__":
hmm = Hmm()
hmm.train('train_data.txt', save_model=True)
n=input("输入文本:")#中央电视台收获一批好剧本
cutres = hmm.cut(n)
print(cutres)
实验结果:
1.字标注
2.训练集、测试集、参数
 训练集
训练集 
测试集


3.维特比算法

















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









