







目录
实验要求:
某一文件中存储一列数字:
100
23
45
44
5644
47
62
40
88
25
33
74
5
83
11
23
78
62
34
28
66
77
44
85
34
26
27
43
现尝试使用MapReduce计算框架从本地读取改文件,找出该列数字中的最大值和最小值,并将结果输出和保存到HDFS中的文件中。
基本思路:
首先导入相关jar包
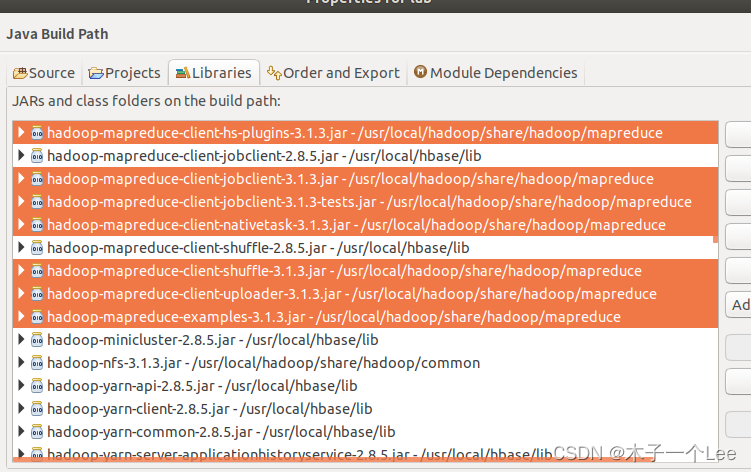
然后编写代码,分为三个类:
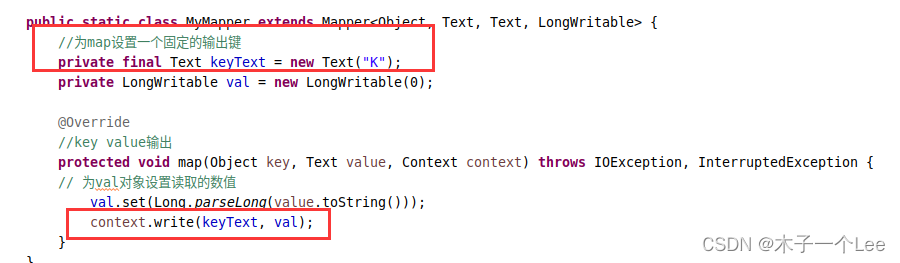
MyMapper类继承Mapper类,执行map任务,输入为读取的数字,形式是<key,value>,key为起始字节偏移量(实际上并未用到),valie为数值;输出为一系列<key,value>,即list(<key,value>),key设置为固定的K,value为数值。
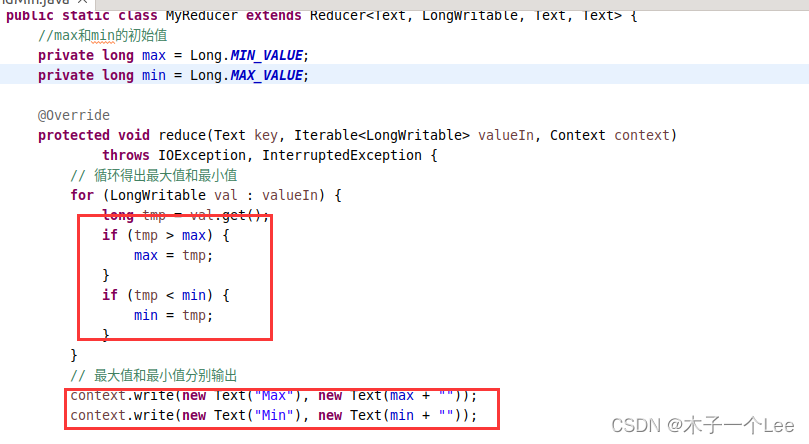
MyReducer类,继承Reducer类,执行reduce任务,输入为<key,list(value)>,key为固定键K,list(value)就是一系列数字,然后循环比较大小,输出为<max,最大的数字>,<min,最小的数字>。
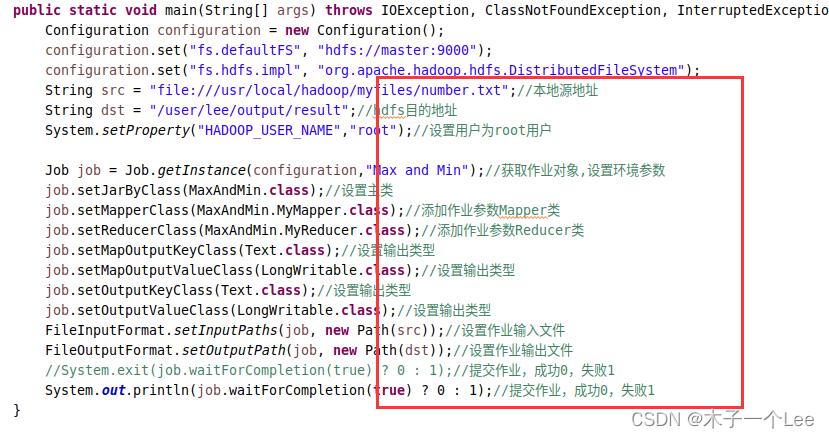
主类,用于设置一些作业参数,包括设置主类,Mapper类和Reducer类,输出类型、输入输出地址和提交作业。
代码参考:
//本地/usr/local/hadoop/myfiles/number.txt
//结果上传到hdfs的/user/hadoop/output/result
package lab3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MaxAndMin {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://master:9000");
configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
String src = "file:///usr/local/hadoop/myfiles/number.txt";//本地源地址
String dst = "/user/hadoop/output/result";//hdfs目的地址
System.setProperty("HADOOP_USER_NAME","root");//设置用户为root用户
Job job = Job.getInstance(configuration,"Max and Min");//获取作业对象,设置环境参数
job.setJarByClass(MaxAndMin.class);//设置主类
job.setMapperClass(MaxAndMin.MyMapper.class);//添加作业参数Mapper类
job.setReducerClass(MaxAndMin.MyReducer.class);//添加作业参数Reducer类
job.setMapOutputKeyClass(Text.class);//设置输出类型
job.setMapOutputValueClass(LongWritable.class);//设置输出类型
job.setOutputKeyClass(Text.class);//设置输出类型
job.setOutputValueClass(LongWritable.class);//设置输出类型
FileInputFormat.setInputPaths(job, new Path(src));//设置作业输入文件
FileOutputFormat.setOutputPath(job, new Path(dst));//设置作业输出文件
//System.exit(job.waitForCompletion(true) ? 0 : 1);//提交作业,成功0,失败1
System.out.println(job.waitForCompletion(true) ? 0 : 1);//提交作业,成功0,失败1
}
public static class MyMapper extends Mapper< LongWritable, Text, Text, LongWritable> {
//为map设置一个固定的输出键
private final Text keyText = new Text("K");
private LongWritable val = new LongWritable(0);
@Override
//key value输出
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 为val对象设置读取的数值
val.set(Long.parseLong(value.toString()));
context.write(keyText, val);
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, Text> {
//max和min的初始值
private long max = Long.MIN_VALUE;
private long min = Long.MAX_VALUE;
@Override
protected void reduce(Text key, Iterable<LongWritable> valueIn, Context context)
throws IOException, InterruptedException {
// 循环得出最大值和最小值
for (LongWritable val : valueIn) {
long tmp = val.get();
if (tmp > max) {
max = tmp;
}
if (tmp < min) {
min = tmp;
}
}
// 最大值和最小值分别输出
context.write(new Text("Max"), new Text(max + ""));
context.write(new Text("Min"), new Text(min + ""));
}
}
}
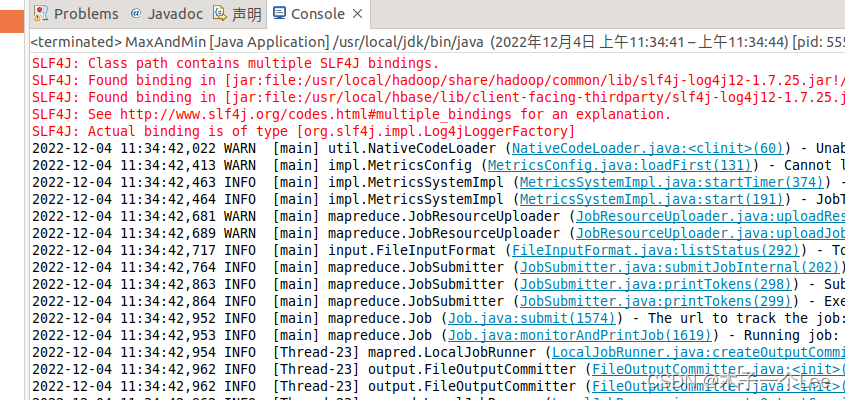
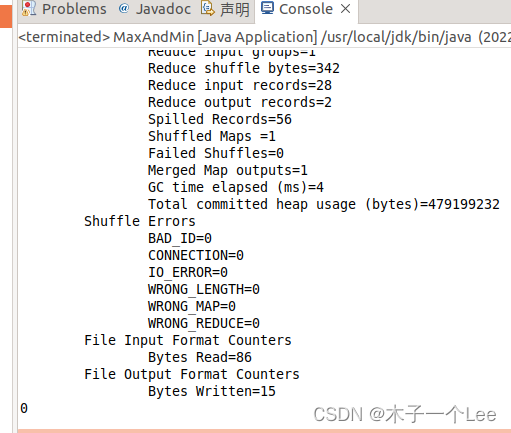
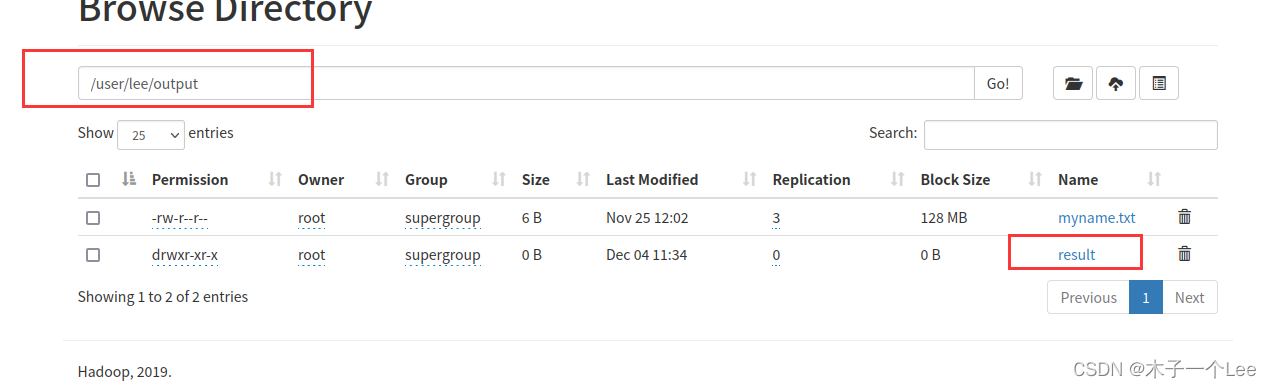
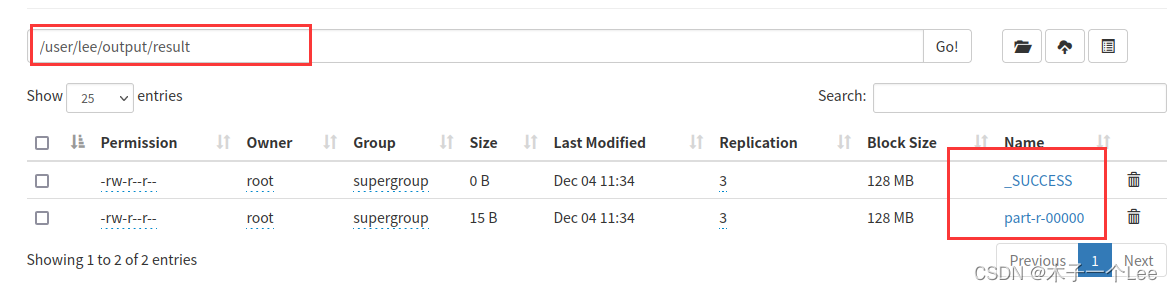
实验结果:
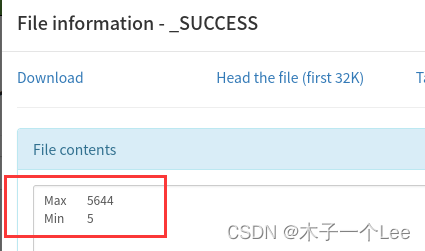
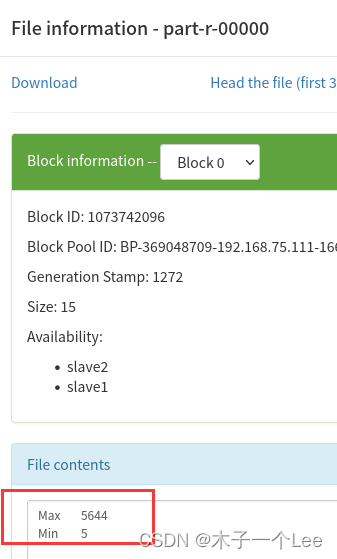















 4530
4530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









