







文章目录
Chapter2浏览器中的JavaScript执行机制
07 | 变量提升:JavaScript代码是按顺序执行的吗?
变量提升
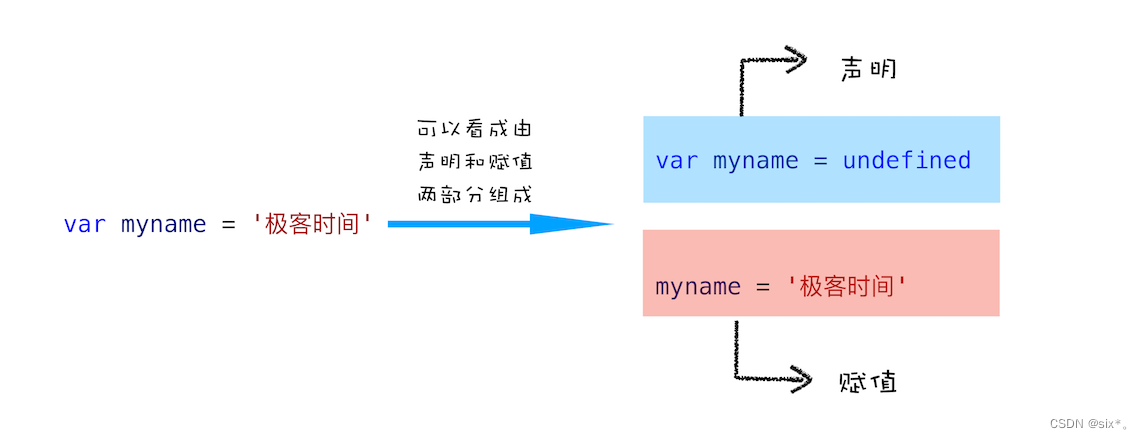

所谓的变量提升,是指在 JavaScript 代码执行过程中,JavaScript 引擎把变量的声明部分和函数的声明部分提升到代码开头的“行为”。变量被提升后,会给变量设置默认值,这个默认值就是我们熟悉的 undefined。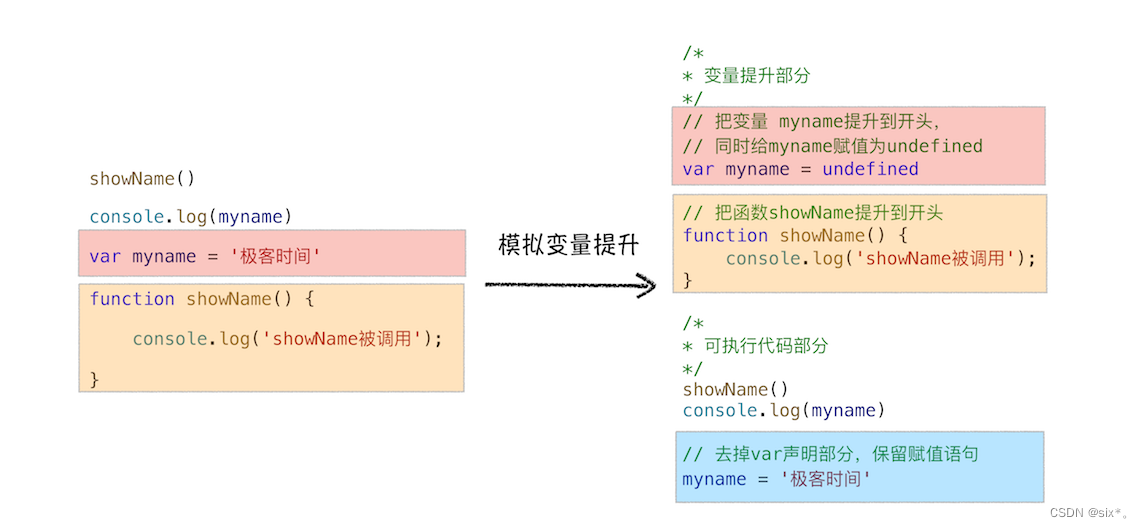
Javascript代码执行流程
从概念的字面意义上来看,“变量提升”意味着变量和函数的声明会在物理层面移动到代码的最前面,正如我们所模拟的那样。但,这并不准确。实际上变量和函数声明在代码里的位置是不会改变的,而且是在编译阶段被 JavaScript 引擎放入内存中。也就是说,一段 JavaScript 代码在执行之前需要被 JavaScript 引擎编译,编译完成之后,才会进入执行阶段。
1. 编译阶段
showName()
console.log(myname)
var myname = '极客时间'
function showName() {
console.log('函数 showName 被执行');
}
以这个代码为例,我们在上面分析的时候已经将它转换成了这个代码
// 变量提升部分
var myname = undefined;
function showName() {
console.log('函数 showName 被执行');
}
// 可执行代码部分
showName()
console.log(myname)
myname = '极客时间'
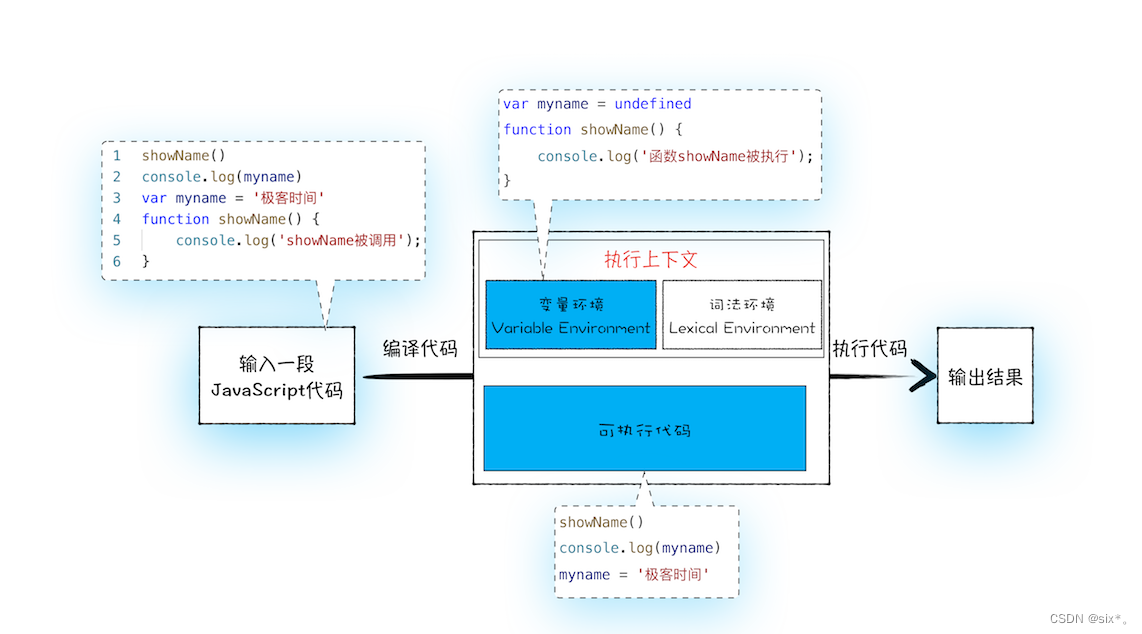
从上图可以看出,输入一段代码,经过编译后,会生成两部分内容:执行上下文(Execution context)和可执行代码。
执行上下文是 JavaScript 执行一段代码时的运行环境,比如调用一个函数,就会进入这个函数的执行上下文,确定该函数在执行期间用到的诸如 this、变量、对象以及函数等。在执行上下文中存在一个变量环境的对象(VariableEnvironment),该对象中保存了变量提升的内容,比如myname和函数showName,都保存在该对象中。
// 变量环境对象
// VariableEnvironment:
myname -> undefined,
showName ->function : {console.log(myname)
再来看这个代码
showName()
console.log(myname)
var myname = '极客时间'
function showName() {
console.log('函数 showName 被执行');
}
- 第一行第二行:可执行代码,js引擎不处理
- 第三行:var声明的,js引擎在VariableEnvironment中创建一个名为myname的属性,并使用undefined对其初始化
- 第四行:js引擎发现了一个通过 function 定义的函数,所以它将函数定义存储到堆 (HEAP)中,并在环境对象中创建一个 showName 的属性,然后将该属性值指向堆中函数的位置
然后我们的VariableEnvironment就生成完毕了。
2.执行阶段
JavaScript 引擎开始执行“可执行代码”,按照顺序一行一行地执行。
- 当执行到showName函数时,js引擎就在VariableEnvironment中查找该函数。因为VariableEnvironment中存在该函数的引用,所以js引擎就开始执行这个函数,并且输出“函数 showName 被执行”结果。
- 接下来打印“myname”信息,JavaScript 引擎继续在变量环境对象中查找该对象,由于变量环境存在 myname 变量,并且其值为 undefined,所以这时候就输出 undefined。
- 接下来执行第 3 行,把“极客时间”赋给 myname 变量,赋值后变量环境中的 myname 属性值改变为“极客时间”,变量环境如下所示:
VariableEnvironment:
myname -> " 极客时间 ",
showName ->function : {console.log(myname)
代码中出现相同的变量或者函数怎么办?
function showName() {
console.log('极客邦');
}
showName();
function showName() {
console.log('极客时间');
}
showName();
- 编译阶段:遇到了第一个 showName 函数,会将该函数体存放到变量环境中。接下来是第二个 showName 函数,继续存放至变量环境中,但是变量环境中已经存在一个 showName 函数了,此时,第二个 showName 函数会将第一个 showName 函数覆盖掉。这样变量环境中就只存在第二个 showName 函数了。
- 执行阶段:先执行第一个 showName 函数,但由于是从变量环境中查找 showName 函数,而变量环境中只保存了第二个 showName 函数,所以最终调用的是第二个函数,打印的内容是“极客时间”。第二次执行 showName 函数也是走同样的流程,所以输出的结果也是“极客时间”。
综上所述,一段代码如果定义了两个相同名字的函数,那么最终生效的是最后一个函数。
我们现在已经知道了,当一段代码被执行时,JavaScript 引擎先会对其进行编译,并创建执行上下文。那么,哪些情况下代码才算是“一段”代码,才会在执行之前就进行编译并创建执行上下文呢?
- 当 JavaScript 执行全局代码的时候,会编译全局代码并创建全局执行上下文,而且在整个页面的生存周期内,全局执行上下文只有一份。
- 当调用一个函数的时候,函数体内的代码会被编译,并创建函数执行上下文,一般情况下,函数执行结束之后,创建的函数执行上下文会被销毁。
- 当使用 eval 函数的时候,eval 的代码也会被编译,并创建执行上下文。
总结
- JavaScript 代码执行过程中,需要先做变量提升,而之所以需要实现变量提升,是因为 JavaScript 代码在执行之前需要先编译。
- 在编译阶段,变量和函数会被存放到变量环境中,变量的默认值会被设置为 undefined;在代码执行阶段,JavaScript 引擎会从变量环境中去查找自定义的变量和函数。
- 如果在编译阶段,存在两个相同的函数,那么最终存放在变量环境中的是最后定义的那个,这是因为后定义的会覆盖掉之前定义的。
08 | 调用栈:为什么JavaScript代码会出现栈溢出?

那为什么会出现这种错误呢?这就涉及到了调用栈的内容。调用栈是用来管理函数调用关系的一种数据结构。
什么是函数调用
函数调用就是运行一个函数
var a = 2
function add(){
var b = 10
return a+b
}
add()
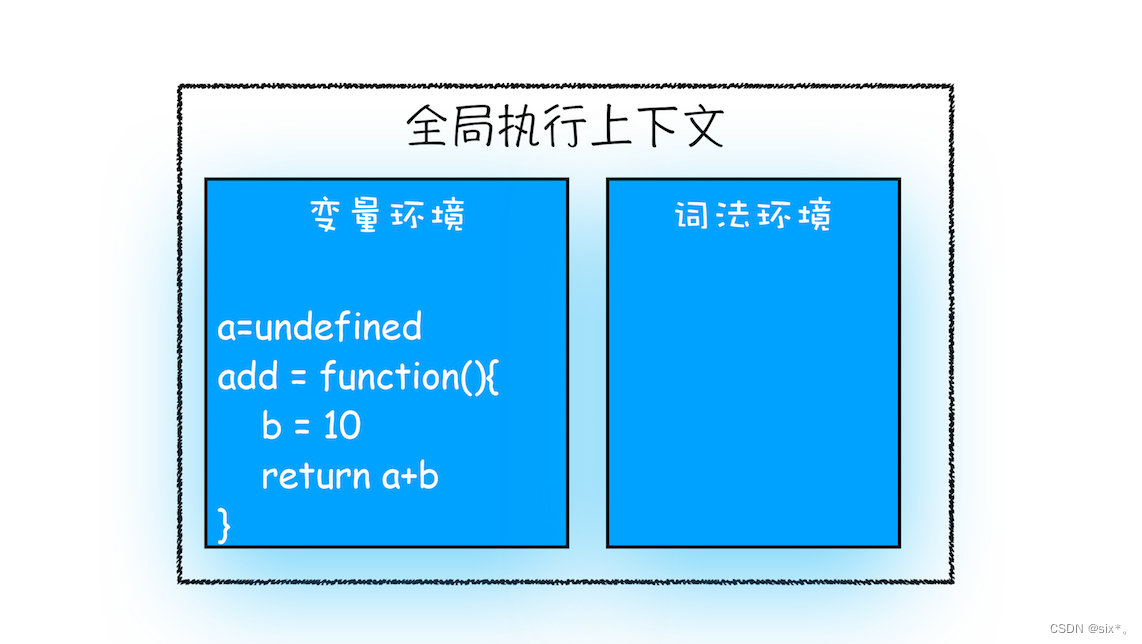
- 首先,从全局执行上下文中,取出 add 函数代码。
- 其次,对 add 函数的这段代码进行编译,并创建该函数的执行上下文和可执行代码。
- 最后,执行代码,输出结果。
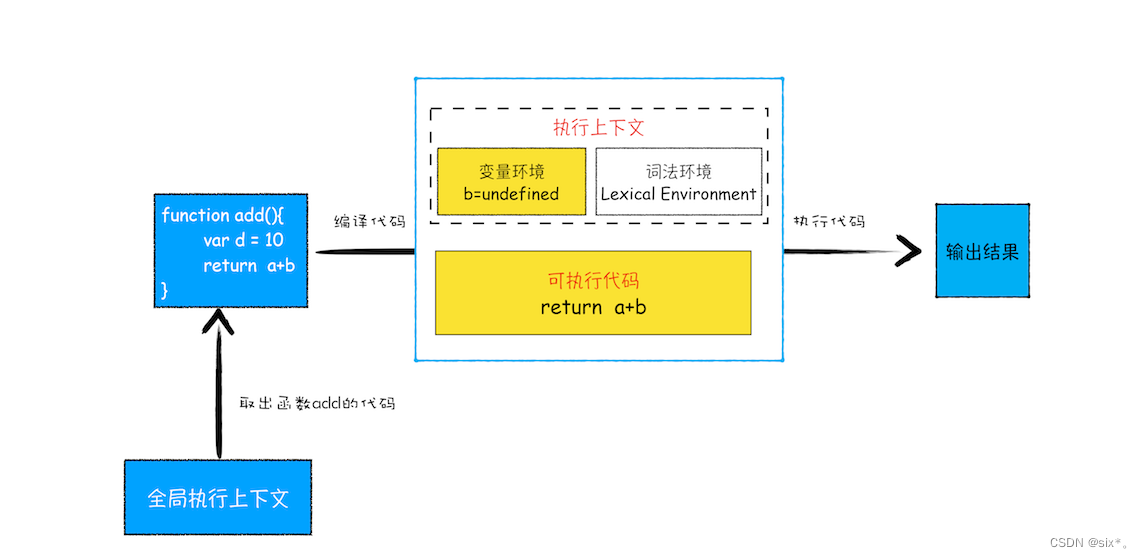
所以,当执行到add函数的时候,我们就有了两个执行上下文,全局执行上下文和 add 函数的执行上下文。也就是说在执行 JavaScript 时,可能会存在多个执行上下文,那么 JavaScript 引擎是如何管理这些执行上下文的呢?
答案是通过一种叫栈的数据结构来管理的。
什么是 JavaScript 的调用栈
JavaScript 引擎是利用栈来管理执行上下文的。在执行上下文创建好后,JavaScript 引擎会将执行上下文压入栈中,通常把这种用来管理执行上下文的栈称为执行上下文栈,又称调用栈。
var a = 2
function add(b,c){
return b+c
}
function addAll(b,c){
var d = 10
result = add(b,c)
return a+result+d
}
addAll(3,6)
第一步,创建全局上下文,并将其压入栈底。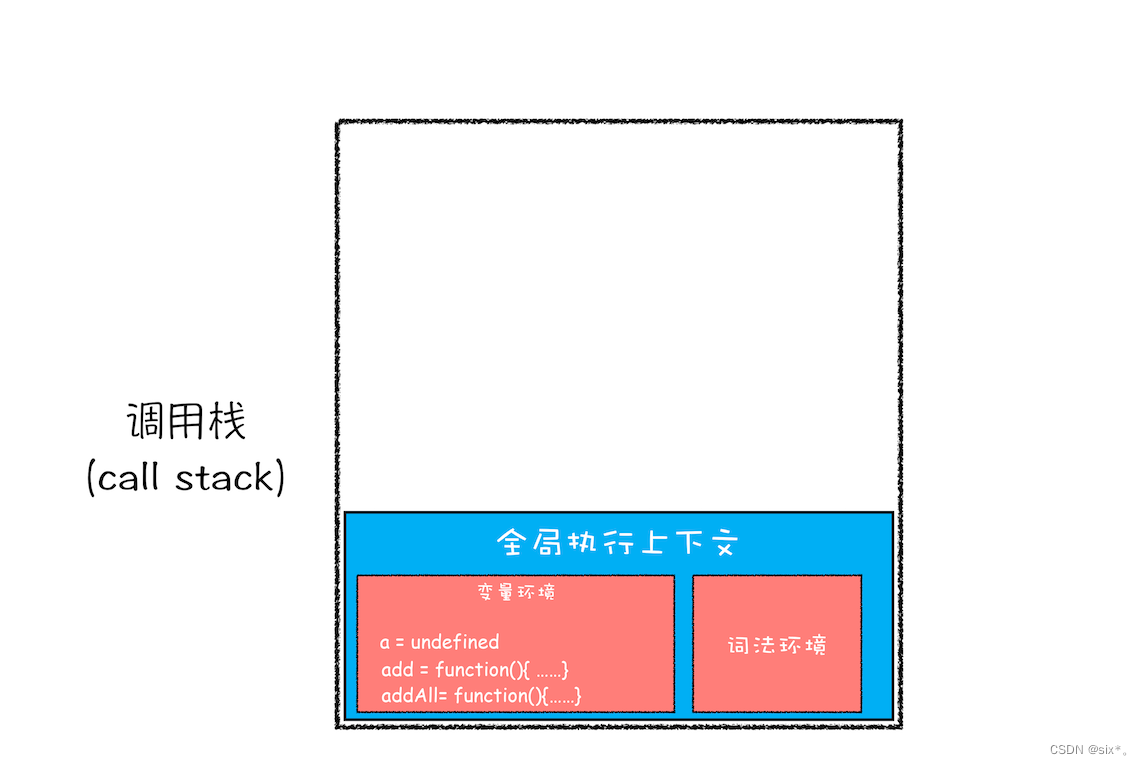
全局执行上下文压入到调用栈后,JavaScript 引擎便开始执行全局代码了。首先会执行 a=2 的赋值操作,执行该语句会将全局上下文变量环境中 a 的值设置为 2。设置后的全局上下文的状态如下图所示: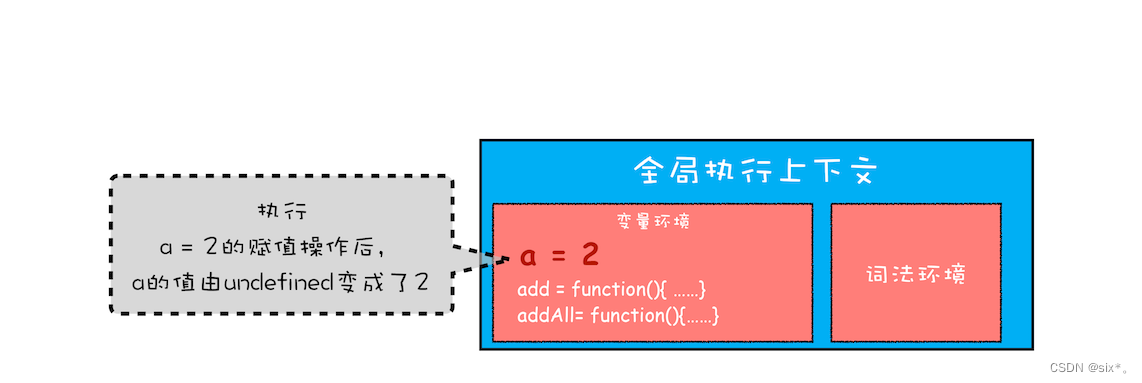
第二步是调用 addAll 函数。当调用该函数时,JavaScript 引擎会编译该函数,并为其创建一个执行上下文,最后还将该函数的执行上下文压入栈中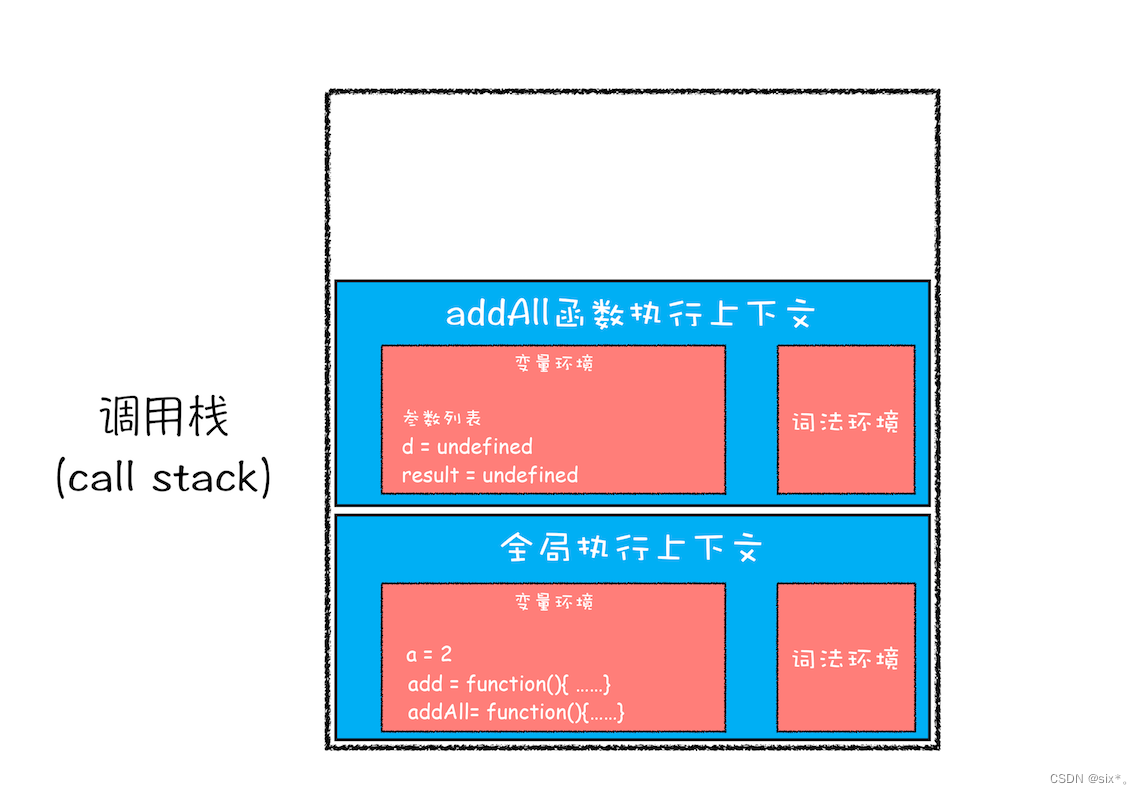
然后js引擎开始进入代码执行阶段。d=10,然后把d改成10;
第三步 当执行到 add 函数调用语句时,同样会为其创建执行上下文,并将其压入调用栈,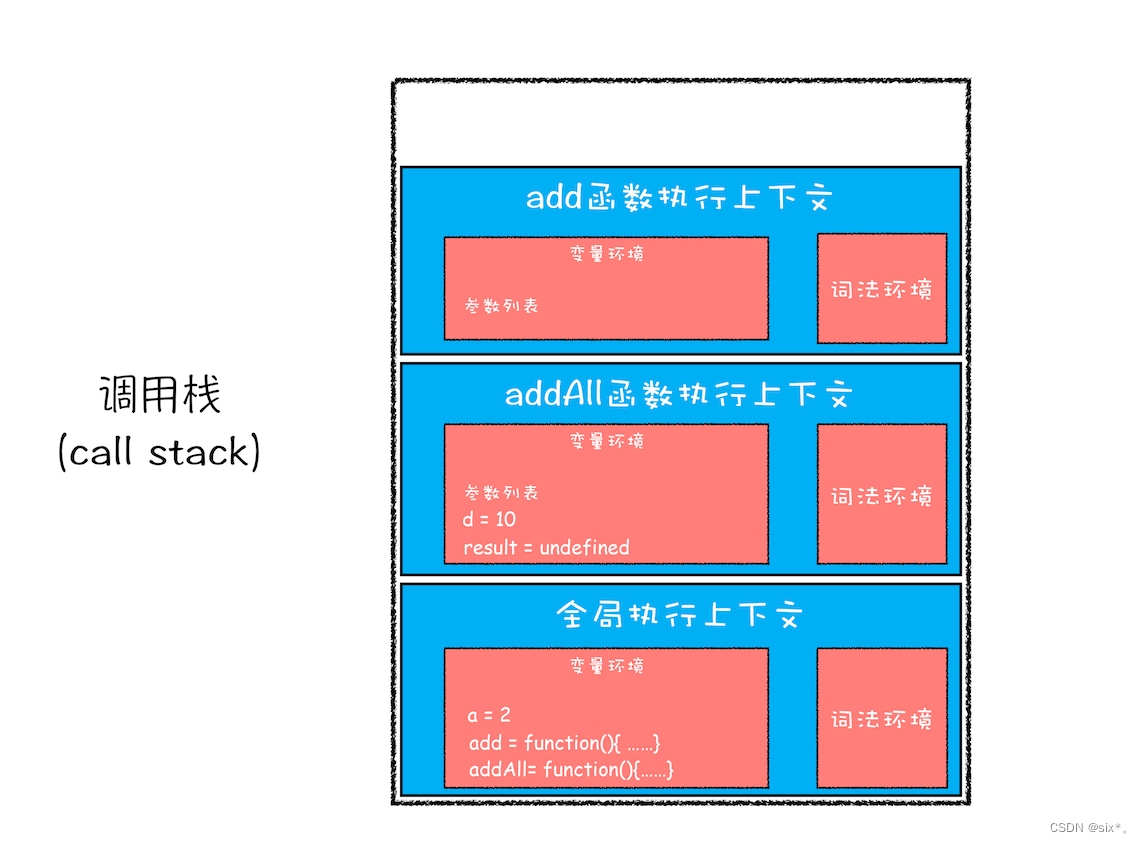
当 add 函数返回时,该函数的执行上下文就会从栈顶弹出,并将 result 的值设置为 add 函数的返回值,也就是 9。
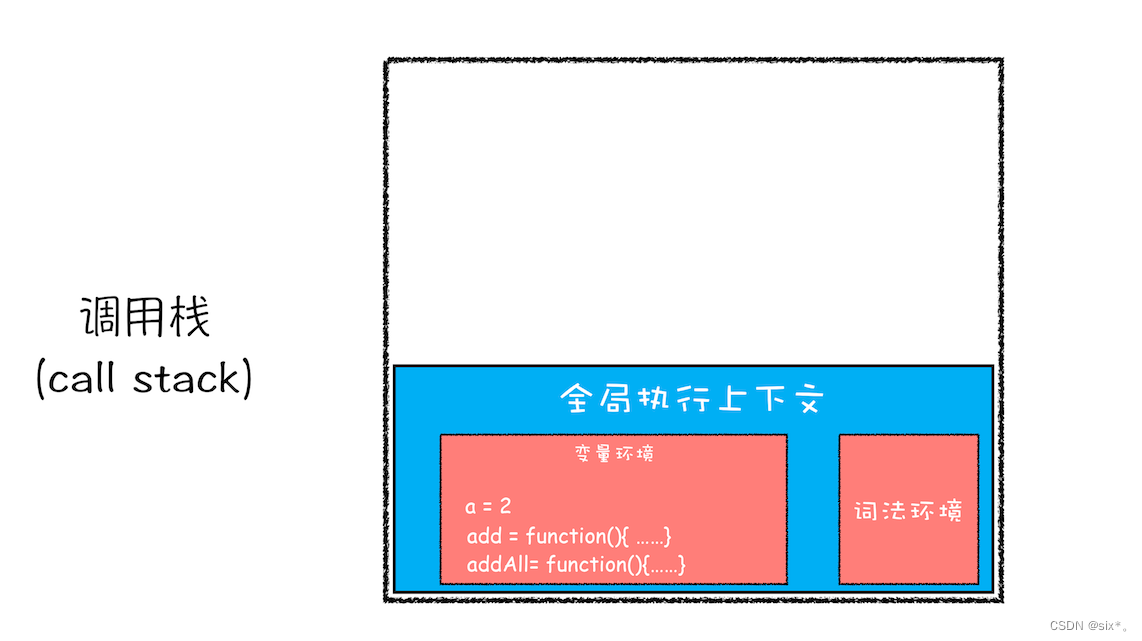
紧接着 addAll 执行最后一个相加操作后并返回,addAll 的执行上下文也会从栈顶部弹出,此时调用栈中就只剩下全局上下文了。
最终如下图所示:
总结
- 每调用一个函数,JavaScript 引擎会为其创建执行上下文,并把该执行上下文压入调用栈,然后 JavaScript 引擎开始执行函数代码。
- 如果在一个函数 A 中调用了另外一个函数 B,那么 JavaScript 引擎会为 B 函数创建执行上下文,并将 B 函数的执行上下文压入栈顶。
- 当前函数执行完毕后,JavaScript 引擎会将该函数的执行上下文弹出栈。
- 当分配的调用栈空间被占满时,会引发“堆栈溢出”问题。
09 | 块级作用域:var缺陷以及为什么要引入let和const?
var缺陷:
- 变量容易在不被察觉的情况下被覆盖掉
var myname = " 极客时间 "
function showName(){
console.log(myname); //undefined
if(0){
var myname = " 极客邦 "
}
console.log(myname);
}
showName()
因为在函数执行过程中,JavaScript 会优先从当前的执行上下文中查找变量,由于变量提升,当前的执行上下文中就包含了变量 myname,而值是 undefined,所以获取到的 myname 的值就是 undefined。
2. 本应销毁的变量没有被销毁
function foo(){
for (var i = 0; i < 7; i++) {
}
console.log(i); //7
}
foo()
在创建执行上下文阶段,变量 i 就已经被提升了,所以当 for 循环结束之后,变量 i 并没有被销毁。
JavaScript 是如何支持块级作用域的
在同一段代码中,ES6 是如何做到既要支持变量提升的特性,又要支持块级作用域的呢?
function foo(){
var a = 1
let b = 2
{
let b = 3
var c = 4
let d = 5
console.log(a)
console.log(b)
}
console.log(b)
console.log(c)
console.log(d)
}
foo()
首先是编译并创建执行上下文。
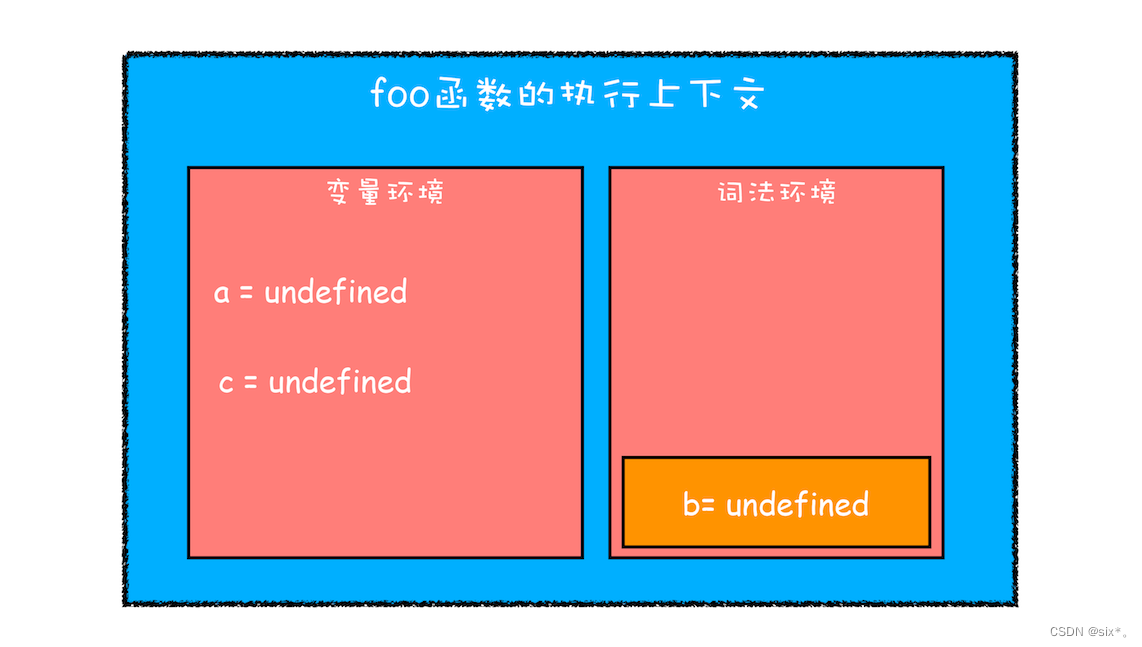
- 函数内部通过var声明的变量,在编译阶段全被存放在变量环境里面了。
- 函数内部通过let声明的变量,在编译时会被存放到语法环境中。
- 在函数的作用域内部,通过 let 声明的变量并没有被存放到词法环境中。
第二步继续执行代码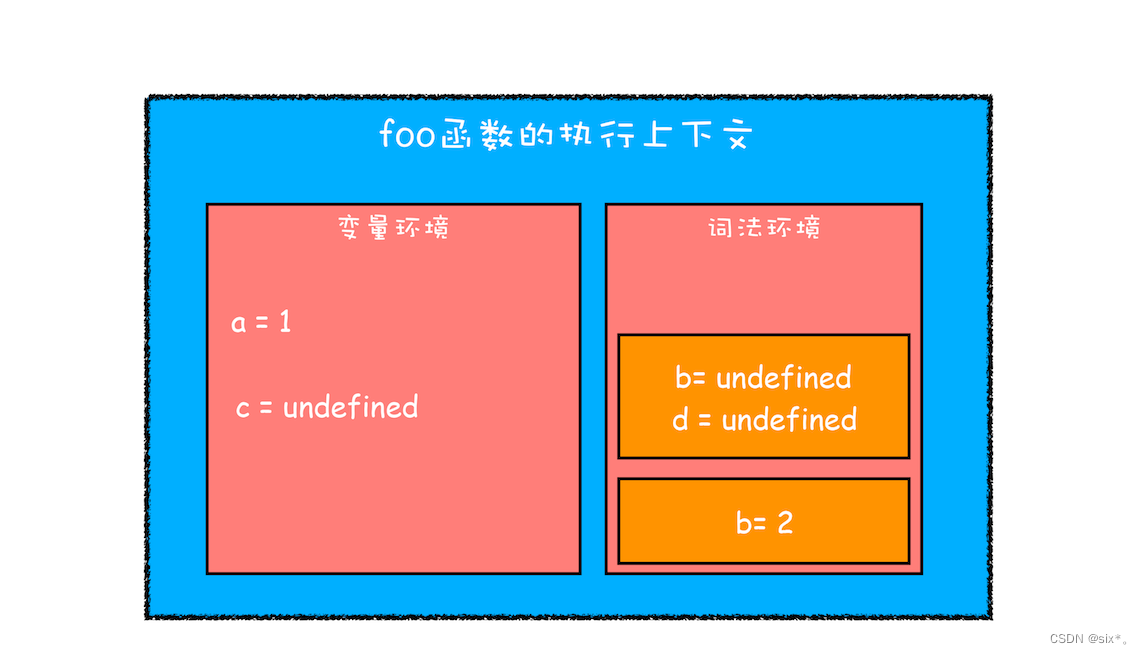
当进入函数的作用域块时,作用域块中通过let声明的变量,会被存放在词法环境的一个单独的区域中,这个区域中的变量并不影响作用域块外面的变量,比如在作用域外面声明了变量 b,在该作用域块内部也声明了变量 b,当执行到作用域内部时,它们都是独立的存在。
词法环境内部其实也是一个栈。栈底是函数最外层的变量。当进入了一个作用域块后,就会把这个作用域块内部的变量压到栈顶。当作用域执行完成之后,该作用域的信息就会从栈顶弹出,这就是词法环境的结构。
在执行的时候会先找词法环境,沿着栈顶向下查询,如果找到了就直接返回,没找到就去变量环境里面找。
当作用域块执行结束之后,其内部定义的变量就会从词法环境的栈顶弹出,最终执行上下文如下图所示: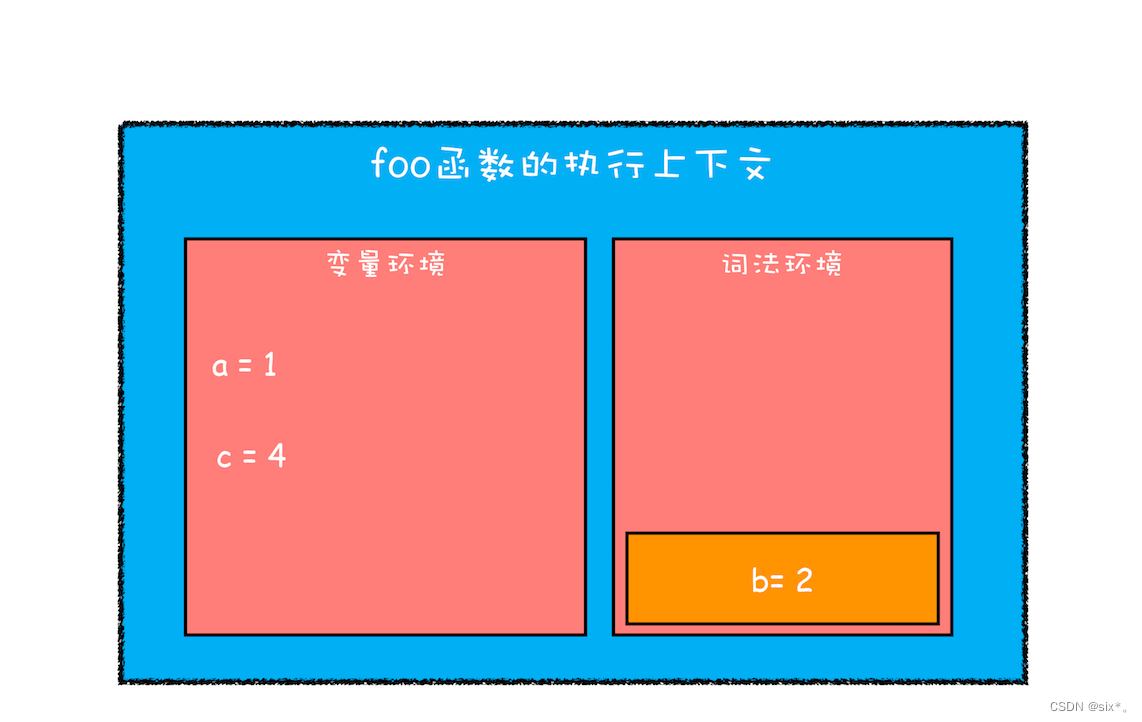
10 | 作用域链和闭包 :代码中出现相同的变量,JavaScript引擎是如何选择的?
function bar() {
console.log(myName)
}
function foo() {
var myName = " 极客邦 "
bar()
}
var myName = " 极客时间 "
foo()
作用域链
在每个执行上下文的变量环境中,都包含了一个外部引用,用来指向外部的执行上下文,我们把这个外部引用称为outer
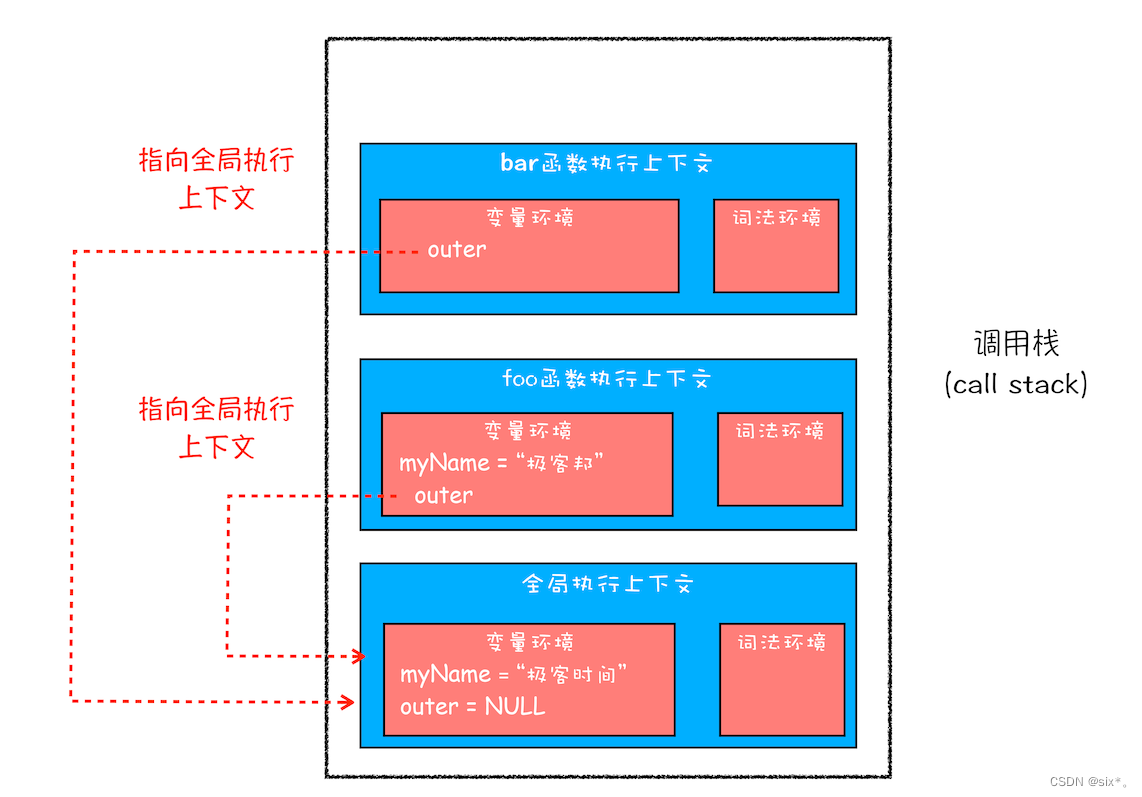
bar函数和foo函数的outer都是指向全局上下文的,那么如果在bar/foo函数中使用了外部变量,那么js引擎就会去全局执行上下文中查找。这个查找的链条就成为作用域链。
词法作用域
词法作用域就是指作用域是由代码中函数声明的位置来决定的,所以词法作用域是静态的作用域,通过它就能够预测代码在执行过程中如何查找标识符。
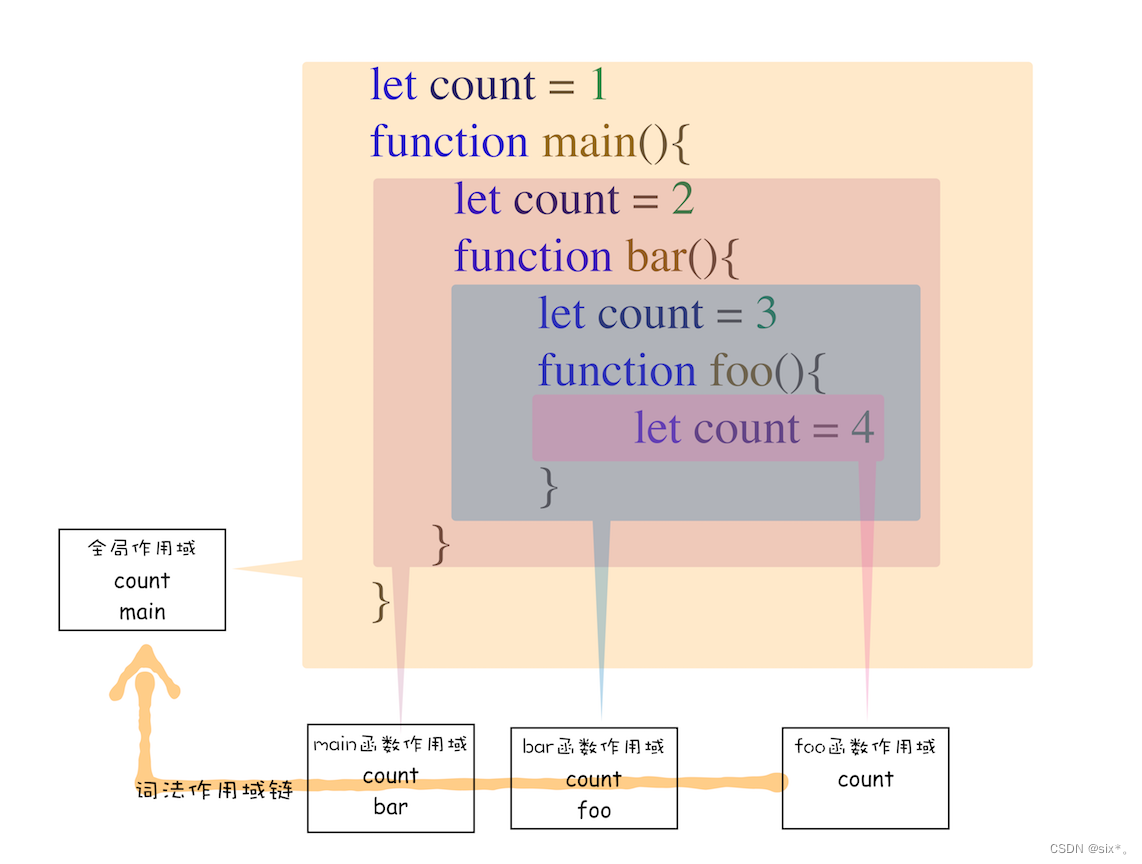
整个词法作用域链的顺序是:foo 函数作用域—>bar 函数作用域—>main 函数作用域—> 全局作用域。
回看开头那段代码,foo函数和bar函数声明的位置,他们的上级作用域都是全局作用域,所以如果 foo 或者 bar 函数使用了一个它们没有定义的变量,那么它们会到全局作用域去查找。也就是说,词法作用域是代码阶段就决定好的,和函数是怎么调用的没有关系。
闭包
function foo() {
var myName = " 极客时间 "
let test1 = 1
const test2 = 2
var innerBar = {
getName:function(){
console.log(test1)
return myName
},
setName:function(newName){
myName = newName
}
}
return innerBar
}
var bar = foo()
bar.setName(" 极客邦 ")
bar.getName()
console.log(bar.getName())
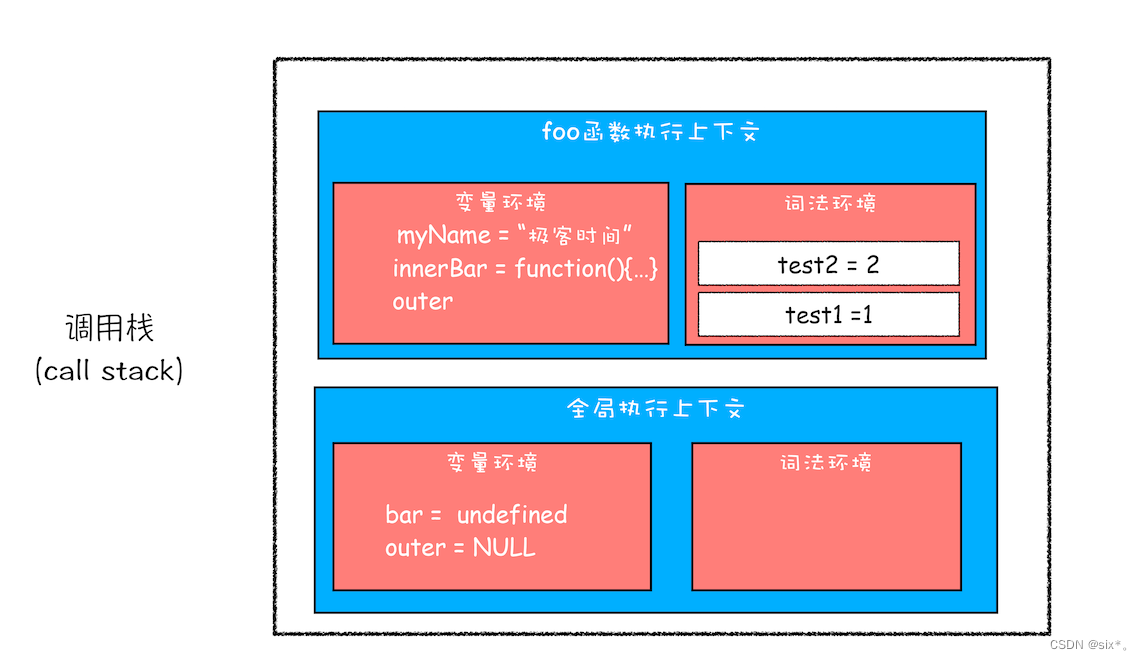
根据词法作用域的规则,内部函数 getName 和 setName 总是可以访问它们的外部函数 foo 中的变量,所以当 innerBar 对象返回给全局变量 bar 时,虽然 foo 函数已经执行结束,但是 getName 和 setName 函数依然可以使用 foo 函数中的变量 myName 和 test1。所以当 foo 函数执行完成之后,其整个调用栈的状态如下图所示:
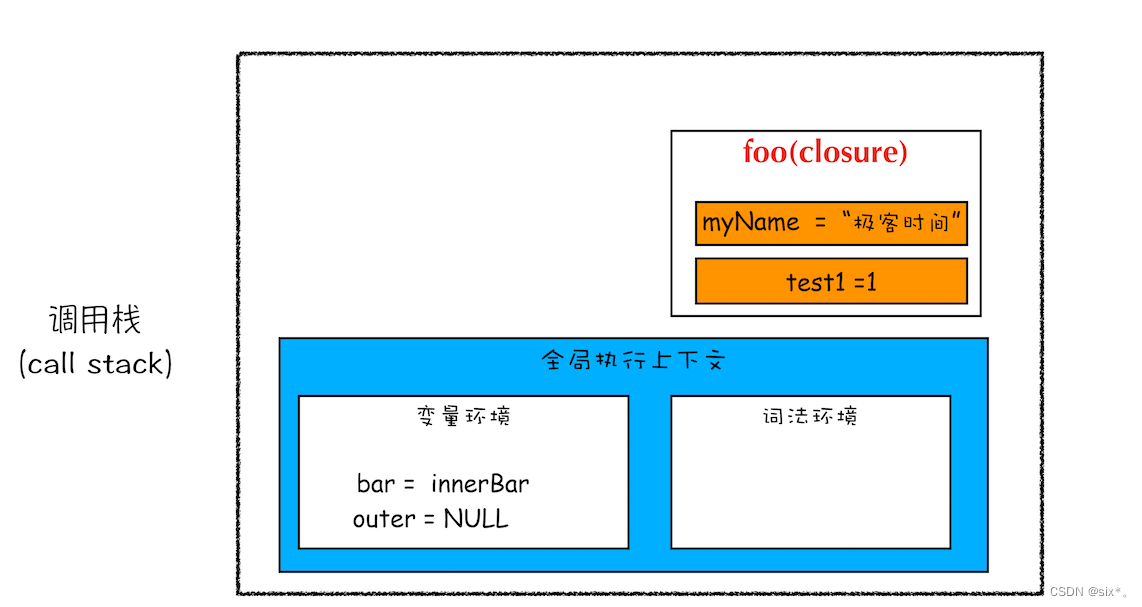
当foo函数执行完毕后,执行上下文就从栈顶弹出了,但是因为setname和getname方法中使用了foo函数内部的变量myname和test1,所以这两个变量依然保存在内存中。这像极了 setName 和 getName 方法背的一个专属背包,无论在哪里调用了 setName 和 getName 方法,它们都会背着这个 foo 函数的专属背包。除了 setName 和 getName 函数之外,其他任何地方都是无法访问该背包的,我们就可以把这个背包称为 foo 函数的闭包。
闭包是怎么回收的
- 引用闭包的函数是全局变量
如果引用闭包的函数是一个全局变量,那么闭包会一直存在直到页面关闭;但如果这个闭包以后不再使用的话,就会造成内存泄漏。 - 引用闭包的函数是局部变量
等函数销毁后,在下次 JavaScript 引擎执行垃圾回收时,判断闭包这块内容如果已经不再被使用了,那么 JavaScript 引擎的垃圾回收器就会回收这块内存。
所以如果该闭包会一直使用,那么它可以作为全局变量而存在;但如果使用频率不高,而且占用内存又比较大的话,那就尽量让它成为一个局部变量。
11 | this:从JavaScript执行上下文的视角讲清楚this

this是和执行上下文绑定的,每个执行上下文种都有一个this。
执行上下文有三种,全局执行上下文、函数执行上下文和eval执行上下文,所以对应的this也就只有这三种——全局执行上下文中的 this、函数中的 this 和 eval 中的 this。
全局执行上下文中的 this
指向window
这也是this和作用域链的唯一交点,作用域链的最底端包含了 window 对象,全局执行上下文中的 this 也是指向 window 对象。
函数执行上下文中的 this
function foo(){
console.log(this) // window
}
foo()
那
怎么设置执行上下文中的this指向其他对象呢?
1.通过函数的call/apply/bind方法设置
let bar = {
myname: 'jxx',
test: '123'
}
function foo() {
this.myname = 'jys'
console.log(this);
console.log(this === bar);
}
foo.call(bar); // { myname: 'jys', test: '123' } true
foo.apply(bar) // { myname: 'jys', test: '123' } true
foo.bind(bar)() // { myname: 'jys', test: '123' } true
2. 通过对象调用方法设置
var myObj = {
name: "jxx",
showThis: function () {
console.log(this === myObj)
}
}
myObj.showThis() // true
使用对象来调用其内部的一个方法,该方法的 this 是指向对象本身的。
3. 通过构造函数中设置
function CreateObj() {
this.name = "jxx"
console.log(this === CreateObj)
}
var myObj = new CreateObj() // false
在执行new CreateObj()时,js引擎进行了如下操作:
var tempObj = {}
CreateObj.call(tempObj)
return tempObj
- 当函数作为对象的方法调用时,函数中的this就是该对象。
- 当函数被正常调用时,在严格模式下,this值是undefined,非严格模式下this指向的是全局对象window
- 嵌套函数中的 this不会继承外层函数的this值。














 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









