






线性回归
本节课用于搭建一个简单的线性回归模型。
换句话来说就是找到一个最佳多元一次函数使得预测模型得到的结果和真实结果误差尽可能的小。如图:
其中y代表最终数据,X和w则均为大小为n的向量(图中例子n=3)并进行内积,即向量点乘。
假设函数y为我们模拟出来的模型,Y则为真实的数据,我们希望我们得到的模型y,最后与Y之间的差值尽可能的小,也就是要尽可能的准确。

上图就是一种衡量模型准确性的一种函数,其中的1/2是为了求导之后能保证变量前常数为1,方便计算
数据集搭建
在此,我们可以先人工制造一个数据集:
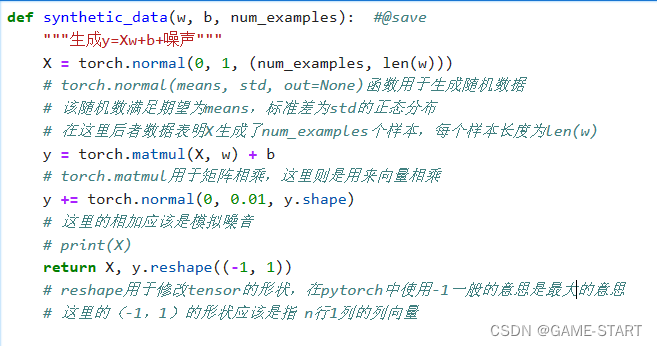
此处synthetic_data函数的作用应该是,给定一个模型,即w给定。而后按标准正态分布随机生成对应数据,即函数中的X,并且返回该模型给出的值,即函数中的y。
注意,这里的X和y均为向量。
而后我们可以利用该函数先模拟一千组数据:

而后我们生成第二个特征features[:, 1]和labels的散点图, 可以直观观察到两者之间的线性关系。
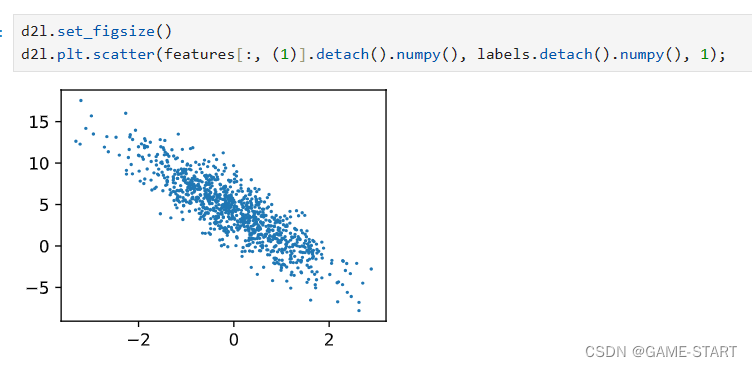
这里的图像生成函数暂时不太清楚,就先放在这里。
读取数据集
这里我们定义一个函数,将我们上述随机得到的一千份数据按照小批量的分割。这样可以将这些小批量数据分成不同的进程利用cpu和gpu并发运算来快点把整个数据处理完。

我们可以选取十组作为一份,打印第一份来看看

当然,听说这种迭代对于教学来说是很好的,但是在实际上这样的执行效率很低,我们在处理实际问题上的时候并不是上述的手法。我们在深度学习框架中一般就是直接使用内置的迭代器,效率会高很多。
其他的一些数据以及需要的函数
我们先定义一些初始化模型参数,当然是随机定义的

然后简单的定义一个线性回归的模型,其实就是函数计算的式子啦

再定义一个损失函数,这里也就是我们文章开头提出的平方损失函数

这里我们着重的再来说一下优化算法
对于深度学习的模型中,我们没有办法通过现有的数据看出或者是快速的计算出最优的模型,我们采取的方案是,先假设出的一个模型,算出其结果并且与真实解进行误差的计算,也就是运用我们的损失函数算出损失值。并且通过对损失函数进行求导,让我们每一步走向更优解,这里的最优解一般就是最小值。即进行梯度下降,一步步走向当前梯度指的反方向,即对于该点函数值下降最快的方向。

η:标量,表示学习率,代表沿着负梯度方向一次走多远,即步长。他是一个超参数(需要人为的指定值)
学习率的选择不能太小,也不能太大(太小会导致计算量大,求解时间长;太大的话或导致函数值振荡,并没有真正的下降)
这里对于梯度下降的理解,我个人感觉可以参考高数中可微二元函数的某一区域内的极值问题,即通过某一点的偏导数,不断逼近最值所在的点,当走到某一点的偏导数均为0的时候就说明该点为极值,即一步步得到了最优解。当然二元函数可解,所以我们直接算得,而深度学习中的函数过于复杂甚至可能根本就没有办法算出来,所以我们选用这种方式一步步试探出来。
很幸运对于这一块知识点我在网上找到了一篇不错的博客介绍,同时也很开心该文作者的切入点和我一致。点击这里
然后让我们定义一下优化算法函数

至此,我们基本上大体的函数,预准备的参数模型都已经搭建好了,可以开始简单的跑一跑模型了。
开始训练模型

然后我们可以运行一下看一看最后的结果

可见的我们的损失是越来越小的
至此,我们的第一个简单模型的训练就完成了!可喜可贺可喜可贺!
对本文中一些零碎知识点的备注
1. pytorch的广播机制
对于pytorch中的向量或者矩阵进行运算时,可能会出现两个矩阵的形状不一致的情况。某些情况下pytorch不会报错而是会按照广播机制将两者的形状变成一致的然后进行运算。
其原则如下:
-
如果两个张量的维度数不同,那么较低维度的张量会通过在前面添加尺寸为1的维度进行扩展,直到两个张量的维度数相同。
-
如果两个张量在某个维度上的尺寸不同,并且其中一个张量的尺寸为1,那么这个尺寸为1的维度会在该维度上自动扩展,以匹配另一个张量的尺寸。
-
如果两个张量在某个维度上的尺寸既不相等也不等于1,那么会引发一个错误,无法进行广播。
如下图:

但如果x的形状是2行4列,y的形状是3行4列,这里进行运算便会报错,即原则2。
2. 计算图
params = torch.tensor([1.0, 0.0], requires_grad=True)
我们可通过这样的方式定义一组变量,或者说叫做初始化一个参数张量,即随机选择一组参数来开始训练我们的模型。注意其中的requires_grad=True这一句话,这个参数告诉PyTorch跟踪由对params张量进行操作后产生的张量的整个系谱树(计算图)。
计算图很像我们高数进行链式求导时画的图。















 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









