






流式模型的解析比较简单,相同的地方在此篇不再赘述,都是设置断点后从utils.py经过装饰器stats_wrapper和函数_parse_args_以及_note_one_stat函数最终进入到真正的处理。
【详细代码拆解】PaddleSpeech学习笔记(非流式)_paddlespeech cli-CSDN博客
流式模型结构简介
【飞桨PaddleSpeech语音技术课程】— 语音识别-流式服务_流式语音识别-CSDN博客
更详细的说明在此博客。
相比非流式模型,流式模型在处理音频流时无需等待完整句音频输入,从而提高了处理效率。
在流式语音识别系统中,客户端(client)与服务器(server)之间需要维持一个持久的、长时间的数据交互过程。这一过程中,客户端不断地将音频数据实时传输至服务器,而服务器则负责对这些数据进行即时语音识别,并将识别出的文本结果实时回传给客户端。为了实现这种高效且实时的数据交换,客户端与服务器之间必须保持一个稳定的网络连接。
PaddleSpeech,作为一个强大的语音识别框架,采用了WebSocket协议来确保客户端与服务器之间能够长时间稳定地保持连接。WebSocket协议以其支持全双工通信的特性而著称,这意味着在同一网络连接上,客户端和服务器可以同时发送和接收消息,无需像传统HTTP请求那样频繁地建立和断开连接。
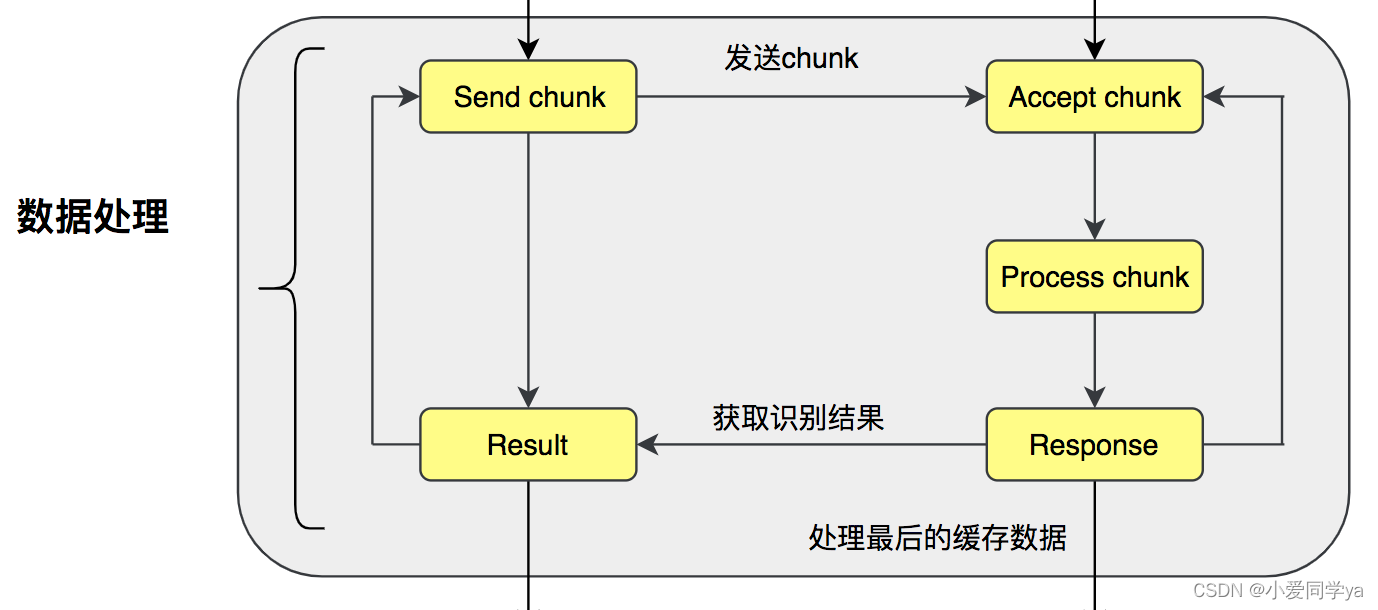
从上面的介绍可以看出来,主要处理都是在服务端,客户端主要是发送读取好的音频数据。这点对于后续的学习理解比较重要。也是由于这个特性,必须要开启两个python文件,或者是开两个终端,把服务器挂好,再去使用客户端请求。
ps:吐槽一下流式模型的代码真的很难找,非流式因为没有采用websocket设断点一下就进去了,也有可能是因为我太菜了。
代码部署
此处参考官方readme文档,可以使用命令行,或者是python文件。
1. 安装
安装 PaddleSpeech 的详细过程请看 安装文档。
推荐使用 paddlepaddle 2.3.1 或以上版本。
你可以从简单,中等,困难 几种方式中选择一种方式安装 PaddleSpeech。
如果使用简单模式安装,需要自行准备 yaml 文件,可参考 conf 目录下的 yaml 文件。
2. 准备配置文件
流式ASR的服务启动脚本和服务测试脚本存放在 PaddleSpeech/demos/streaming_asr_server 目录。 下载好 PaddleSpeech 之后,进入到 PaddleSpeech/demos/streaming_asr_server 目录。 配置文件可参见该目录下 conf/ws_application.yaml 和 conf/ws_conformer_wenetspeech_application.yaml 。
目前服务集成的模型有: DeepSpeech2 和 conformer模型,对应的配置文件如下:
- DeepSpeech:
conf/ws_application.yaml - conformer:
conf/ws_conformer_wenetspeech_application.yaml
这个 ASR client 的输入应该是一个 WAV 文件(.wav),并且采样率必须与模型的采样率相同。
可以下载此 ASR client的示例音频:
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav 3. 服务端使用方法
- 命令行 (推荐使用) 注意: 默认部署在
cpu设备上,可以通过修改服务配置文件中device参数部署在gpu上。
# 在 PaddleSpeech/demos/streaming_asr_server 目录启动服务
paddlespeech_server start --config_file ./conf/ws_conformer_wenetspeech_application.yaml
# 你如果愿意为了增加解码的速度而牺牲一定的模型精度,你可以使用如下的脚本
paddlespeech_server start --config_file ./conf/ws_conformer_wenetspeech_application_faster.yaml- python文件代码
# 在 PaddleSpeech/demos/streaming_asr_server 目录
from paddlespeech.server.bin.paddlespeech_server import ServerExecutor
server_executor = ServerExecutor()
server_executor(
config_file="./conf/ws_conformer_wenetspeech_application",
log_file="./log/paddlespeech.log")4. 客户端使用方法
- 命令行 (推荐使用)
若 127.0.0.1 不能访问,则需要使用实际服务 IP 地址
paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --input ./zh.wav- python文件代码
from paddlespeech.server.bin.paddlespeech_client import ASROnlineClientExecutor
asrclient_executor = ASROnlineClientExecutor()
res = asrclient_executor(
input="./zh.wav",
server_ip="127.0.0.1",
port=8090,
sample_rate=16000,
lang="zh_cn",
audio_format="wav")
print(res)代码拆解
客户端Client
从该处设置断点进入
下一个断点在这里
则进入核心部分,客户端启动websocket服务,handler.run(input)是启动WebSocket连接、发送音频数据到服务器、接收并处理识别结果的异步函数。
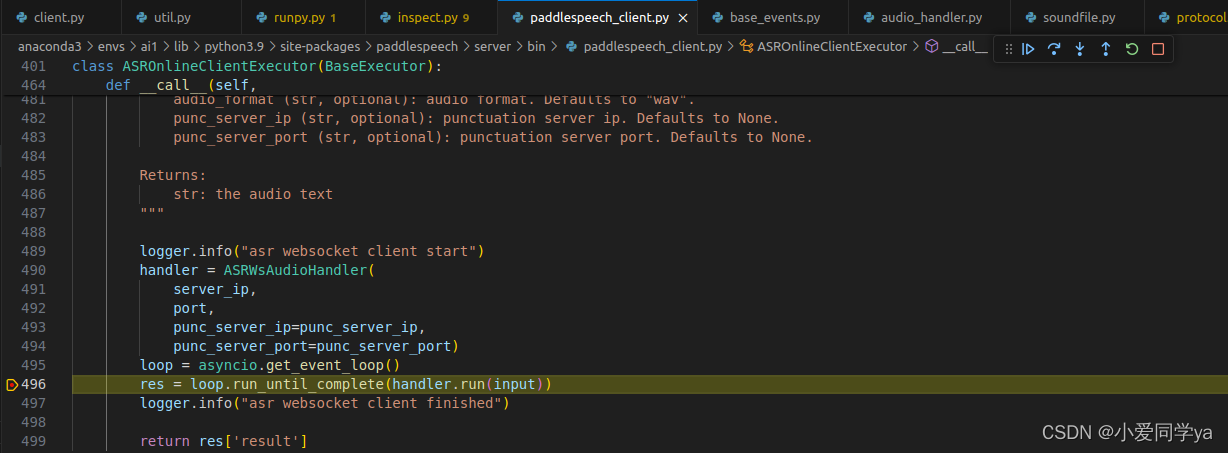
进入断点,主要执行如下代码,分为六段。
- 发送WebSocket握手协议
- 服务器已接收握手协议,客户端开始发送命令
- 客户端通过
self.read_wave(wavfile_path)方法读取音频文件,并分块发送音频数据到服务器。对于每个数据块,客户端都发送数据并等待服务器的响应,然后打印响应内容。 - 当所有音频数据块都发送完毕后,客户端发送一个包含
signal为end的JSON消息,通知服务器音频文件处理结束。 - 客户端将接收到的字节消息解码为JSON对象。如果配置了标点服务器(
self.punc_server),并且识别结果非空,则对识别结果进行标点恢复处理。 - 记录最终结果和统计信息
# 1. send websocket handshake protocal
start_time = time.time()
async with websockets.connect(self.url) as ws:
# 2. server has already received handshake protocal
# client start to send the command
audio_info = json.dumps(
{
"name": "test.wav",
"signal": "start",
"nbest": 1
},
sort_keys=True,
indent=4,
separators=(',', ': '))
await ws.send(audio_info)
msg = await ws.recv()
logger.info("client receive msg={}".format(msg))
# 3. send chunk audio data to engine
for chunk_data in self.read_wave(wavfile_path):
await ws.send(chunk_data.tobytes())
msg = await ws.recv()
msg = json.loads(msg)
logger.info("client receive msg={}".format(msg))
#client start to punctuation restore
if self.punc_server and len(msg['result']) > 0:
msg["result"] = self.punc_server.run(msg["result"])
logger.info("client punctuation restored msg={}".format(msg))
# 4. we must send finished signal to the server
audio_info = json.dumps(
{
"name": "test.wav",
"signal": "end",
"nbest": 1
},
sort_keys=True,
indent=4,
separators=(',', ': '))
await ws.send(audio_info)
msg = await ws.recv()
# 5. decode the bytes to str
msg = json.loads(msg)
if self.punc_server:
msg["result"] = self.punc_server.run(msg["result"])
# 6. logging the final result and comptute the statstics
elapsed_time = time.time() - start_time
audio_info = soundfile.info(wavfile_path)
logger.info("client final receive msg={}".format(msg))
logger.info(
f"audio duration: {audio_info.duration}, elapsed time: 0.0698, RTF={elapsed_time/audio_info.duration}"
)
result = msg服务端Server
与客户端断点类似,进入核心部分。主要在paddlespeech_server.py文件。
首先初始化api,进入模型调用。

 注意有两个asr_engine.py文件,不过是在不同路径下。self.executor初始化了服务端执行器。
注意有两个asr_engine.py文件,不过是在不同路径下。self.executor初始化了服务端执行器。

而该类又继承了ASRExecutor,声明在infer.py。就是之前非流式同一个模型,U2Model。这个还是稍微有些不同的。

这里多嘴一下,我找他的模型类是为了对官方模型做微调训练,因为官方的预训练工具paddlehub不支持对asr进行训练,只能自己找封装接口,流式的比较难找,找了好久发现还是同一个。之所以怀疑流式和非流式官方没给同一个封装是因为流式(online)模型的参数文件大小有490M,非流式460M,我拿流式训练完用官方paddle.save保存也是460M。为了验证,我直接在官方代码处存了一份参数,490M存完也变成460M,很奇怪,但是我用460M的取代490M的参数文件,模型能正常用。如果用懂的佬可以评论区解答一下。

初始化完模型之后,再进行系列websocket的初始化,就开始准备接受客户端数据了。最终循环会在__call__函数的unicorn.run处。使用uvicorn.run(app, host=config.host, port=config.port)启动uvicorn服务器,其中app是ASGI应用实例,host和port分别从config对象中获取服务器的地址和端口号。这样,uvicorn就会根据提供的配置信息启动服务器,并运行app应用。


服务端正常运行~
如何微调PPASR后续会出总结帖,可以蹲蹲更新。
















 3266
3266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









