






目录
1.读取数据data_utils/featurizer/audio_featurizer.py
看此篇之前最好已经安装完paddlespeech环境,并且已经调用过api进行尝试,也对内部代码有一定了解。
什么是微调
ASR(Automatic Speech Recognition,自动语音识别)微调是指对已经训练好的ASR模型进行进一步的调整和优化,以提高其在特定任务或数据集上的性能。这种微调通常涉及到对模型参数的细微调整,以适应新的或更具体的应用场景。以下是关于ASR微调的一些详细解释:
- 提高识别准确率:通过微调,可以使ASR模型更好地适应特定的语音环境、口音、噪声条件等,从而提高语音识别的准确率。
- 优化性能:针对特定的应用场景,如智能家居、智能客服等,微调可以优化ASR模型的响应速度和稳定性,提升用户体验。
官方文档
在官网下载示例文件,即PaddleSpeech,关于如何训练一个ASR模型,ReadMe中有比较详细的解释。
PaddleSpeech/examples/aishell/asr1/README.md
所有你需要的文件,都在asr1文件夹下。
官方教程
最重要的一个文件:
gpus表示想要使用的GPU数量。如果将gpus=设置为空,则表示仅使用CPU。stage表示希望从哪个阶段开始实验。stop_stage表示希望在哪个阶段结束实验。conf_path表示模型的配置文件路径。avg_num表示想要平均的前K个模型的数量K,以获得最终模型。audio_file表示在阶段5中想要进行推断的单个文件的文件路径。ckpt表示模型的检查点前缀,例如"conformer"。
例如你只想要处理数据:
bash run.sh --stage 0 --stop_stage 0source path.sh
set -e
gpus=0,1,2,3
stage=0
stop_stage=50
conf_path=conf/conformer.yaml
ips= #xx.xx.xx.xx,xx.xx.xx.xx
decode_conf_path=conf/tuning/decode.yaml
avg_num=10
audio_file=data/demo_01_03.wav
source ${MAIN_ROOT}/utils/parse_options.sh || exit 1;
avg_ckpt=avg_${avg_num}
ckpt=$(basename ${conf_path} | awk -F'.' '{print $1}')
echo "checkpoint name ${ckpt}"
if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
# prepare data
bash ./local/data.sh || exit -1
fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${ips}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
# avg n best model
avg.sh best exp/${ckpt}/checkpoints ${avg_num}
fi
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# test ckpt avg_n
CUDA_VISIBLE_DEVICES=0 ./local/test.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} || exit -1
fi
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
# ctc alignment of test data
CUDA_VISIBLE_DEVICES=0 ./local/align.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} || exit -1
fi
# Optionally, you can add LM and test it with runtime.
if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then
# test a single .wav file
CUDA_VISIBLE_DEVICES=0 ./local/test_wav.sh ${conf_path} ${decode_conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${audio_file} || exit -1
fi
# Not supported at now!!!
if [ ${stage} -le 51 ] && [ ${stop_stage} -ge 51 ]; then
# export ckpt avg_n
CUDA_VISIBLE_DEVICES=0 ./local/export.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} exp/${ckpt}/checkpoints/${avg_ckpt}.jit
fi
# Need further installation! Read the install.md to complete further installation
if [ ${stage} -le 101 ] && [ ${stop_stage} -ge 101 ]; then
echo "warning: deps on kaldi and srilm, please make sure installed."
# train lm and build TLG
./local/tlg.sh --corpus aishell --lmtype srilm
fi
这个脚本文件将功能主要分为了:
| 0 | 处理数据。包括: (1) 下载数据集 (2) 计算训练数据集的CMVN(倒谱均值和方差归一化)(3) 获取词汇表文件 (4) 获取训练、开发和测试数据集的清单文件 |
| 1 | 训练模型 |
| 2 | 通过平均前k个模型来获取最终模型,设置k=1意味着选择最佳模型 |
| 3 | 测试最终模型性能 |
| 4 | 使用最终模型获取测试数据的CTC对齐结果 |
| 5 | 推断单个音频文件 |
最重要的就是stage0和stage1。
这篇是官方给出的微调示例链接:
https://github.com/PaddlePaddle/PaddleSpeech/discussions/1972
微调训练主要更改的地方,就是在数据准备。
stage0
需要在官网上先下载下来你想要微调训练的模型,他的参数文件pdparams和mean_std,词表等。
如下代码的路径在:PaddleSpeech/examples/aishell/asr1/local/data.sh
脚本将使用Python脚本aishell.py来下载Aishell数据集并生成相应的清单文件(manifest files)。这些清单文件是后续数据处理和模型训练的重要输入。在这里要更改代码改成自己的数据集。
数据集放在PaddleSpeech/dataset。


先生成自己的 manifest 文件,但是自己构建的 manifest 文件使用的词表长度和预训练模型的词表长度不一致,那么要在生成 manifest 文件的时候使用预训练模型的词表。也就是说,处理数据的时候,使用如下脚本(跳过生成自己词表的一步):
bash local/data.sh --stage -1 --stop_stage -1 # 生成你使用数据的 manifest 文件
bash local/data.sh --stage 0 --stop_stage 0 # 生成你使用数据的 mean_std
bash local/data.sh --stage 2 --stop_stage 2 # 跳过构建你的 vocab.txt, 使用预训练模型的词表生成正式的 manifest 文件
根据我自己的经验,如果你自己的数据集比较小,而且内容不够丰富,mean_std文件也可以用预训练模型的,避免过拟合现象,调优的时候可以都试一试。
stage1
在训练部分,脚本文件在PaddleSpeech/examples/aishell/asr1/local/train.sh
调用的训练文件在PaddleSpeech/paddlespeech/s2t/exps/u2/bin/train.py
要把之前下载好的预训练模型参数导入到里面。如果不进行更改,原本的逻辑是从一个全部默认参数的网络框架开始,设定训练轮数,最后导出最好的k个的模型的平均。所有轮数保存的模型都在PaddleSpeech/examples/aishell/asr1/exp/conformer/checkpoints。
微调的话需要将默认模型替换为预训练模型。
替换原接口模型文件
最后确认自己训练的模型没有问题之后,可以将得到的模型参数文件在paddlespeech的官方文件夹下进行替换,原本的所有接口都可以继续正常使用。
模型的替换在.paddlespeech文件夹下,默认是隐藏文件夹,如果找不到需要先把隐藏文件夹设置为可见。
以coformer这个模型为例子,我们一般可以进行替换的文件有下面三个。
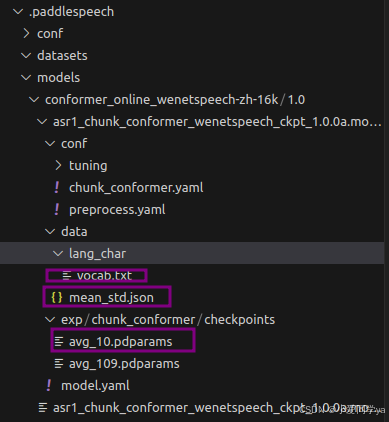
但是根据官方文档微调我还没有完全走过,我是根据下面非官方文档自己改出来的。如果需要调整参数就找到配置文件进行更改。
流程都是差不多的:
1.准备自己的数据集
2.生成manifest.test/manifest.train/mean_std文件
3.加载预训练模型
4.开始训练
5.替换模型,进行预测
当时官方的readme文档里都是根据他自己的aishell数据集进行训练,更偏向于从0到1完全训练一个自己的模型,并且给出的信息很少,刚接触的时候还是个小白,完全是一头雾水。
官方给出的微调参考连接还是个别人发的github帖子,内容很少,当我看见这个帖子的时候我已经微调完了。
非官方文档微调
参考文档
可以先跟随这两个帖子,下载源工程,熟悉一下流程。这两篇使用的都是deepspeech2的模型,而且网络架构都是自己搭建的,我们还是要做一下比较大的改动。
PPASR语音识别(进阶级)_swig-decoders==1.1-CSDN博客
详细步骤
1.读取数据data_utils/featurizer/audio_featurizer.py
deepspeech2的特征为161,而conformer的特征为80,我们需要更改两个地方。同时不使用源工程提供的特征提取函数,而使用官方的提取函数,我这里没有单独提出来,而是直接用了。不明白的可以看看之前的拆解文档。【详细代码拆解】PaddleSpeech学习笔记(非流式)_paddlespeech cli-CSDN博客
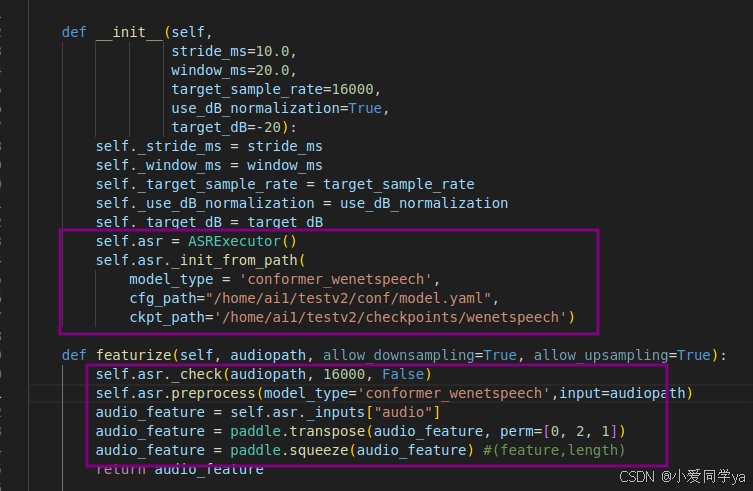
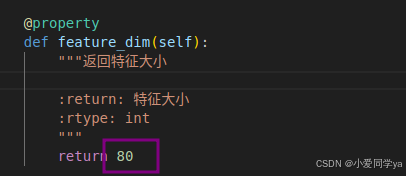
2.准备数据create_data.py
2.1基础准备
注意,在这里一定要注意,如果一处地方你使用了相对路径,就一直使用相对路径,使用绝对路径也是一样,不要换着来,一般出现读取数据线程崩溃都是因为路径不对。由于我使用的是命令行运行文件,一定要cd切换到对应的文件夹。
将自己的音频文件都放在一个文件夹下,同时需要准备一个与音频文件对应的txt文件。
我的标注文件txt是这样的。
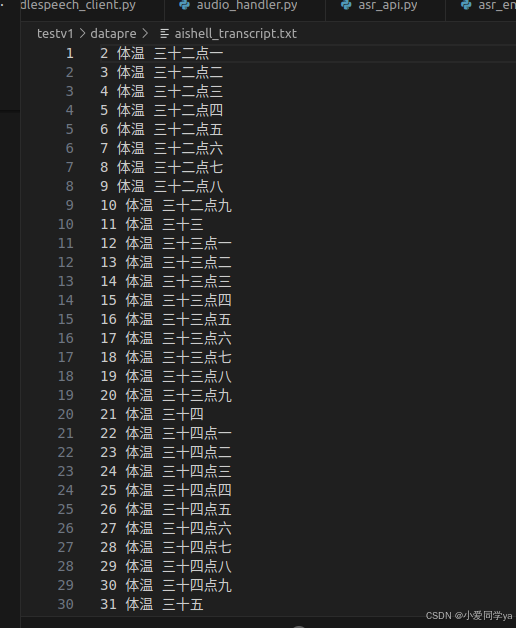
为了达到源工程的格式要求,我自己编写了一个文件。
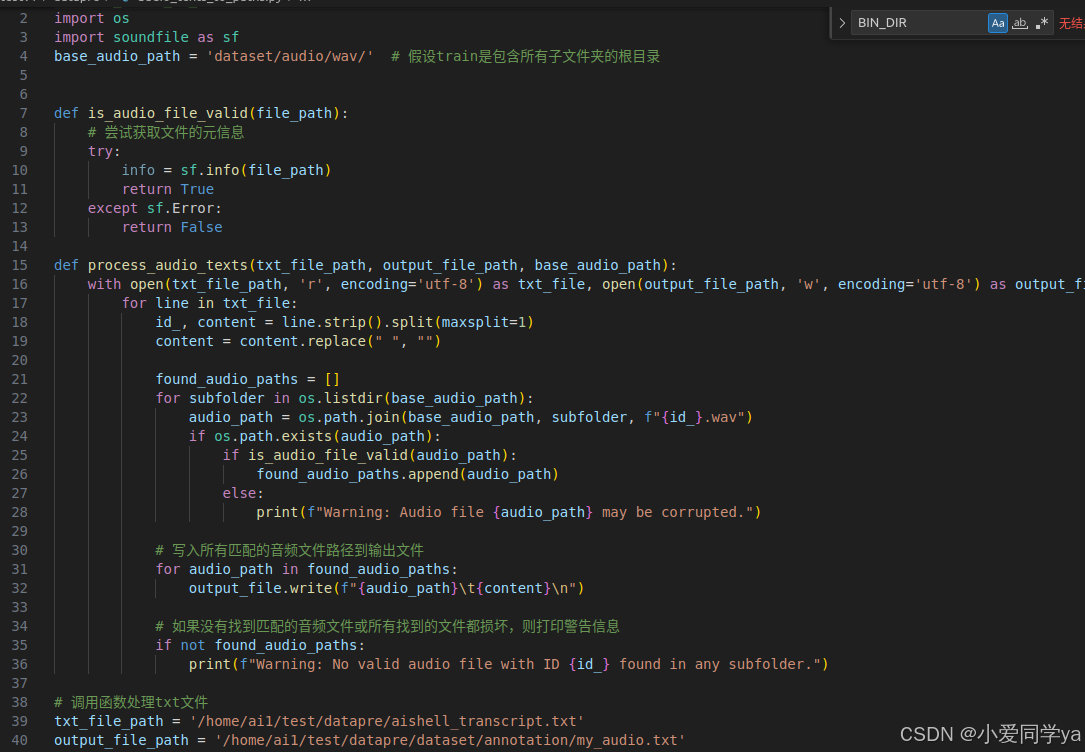 最后的效果:
最后的效果: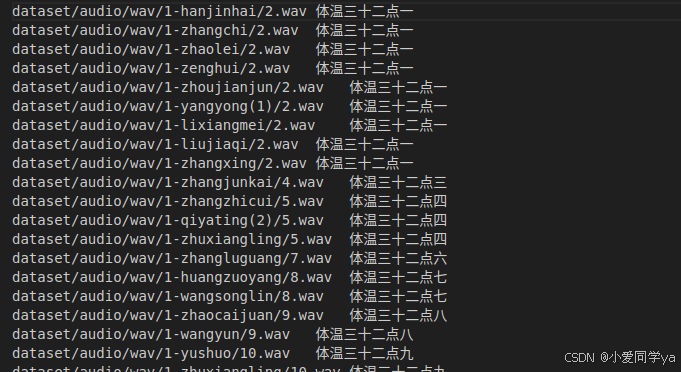
这一步会生成紫色标注的的文件,还会抽取10%的数据生成manifest.test文件,除了manifest文件,别的对微调都没什么作用。
2.2 掺入原本预训练模型数据集(可选
由于是微调,很容易出现过拟合,也就是比如我后面输入什么都很容易出现“体温”,减少训练轮数和学习率就可以,看你自己的数据集大小,也可以掺入原来预训练模型的数据进行训练。
比如我写了个pathpre.py将原本aishell数据集的数据都填入txt。
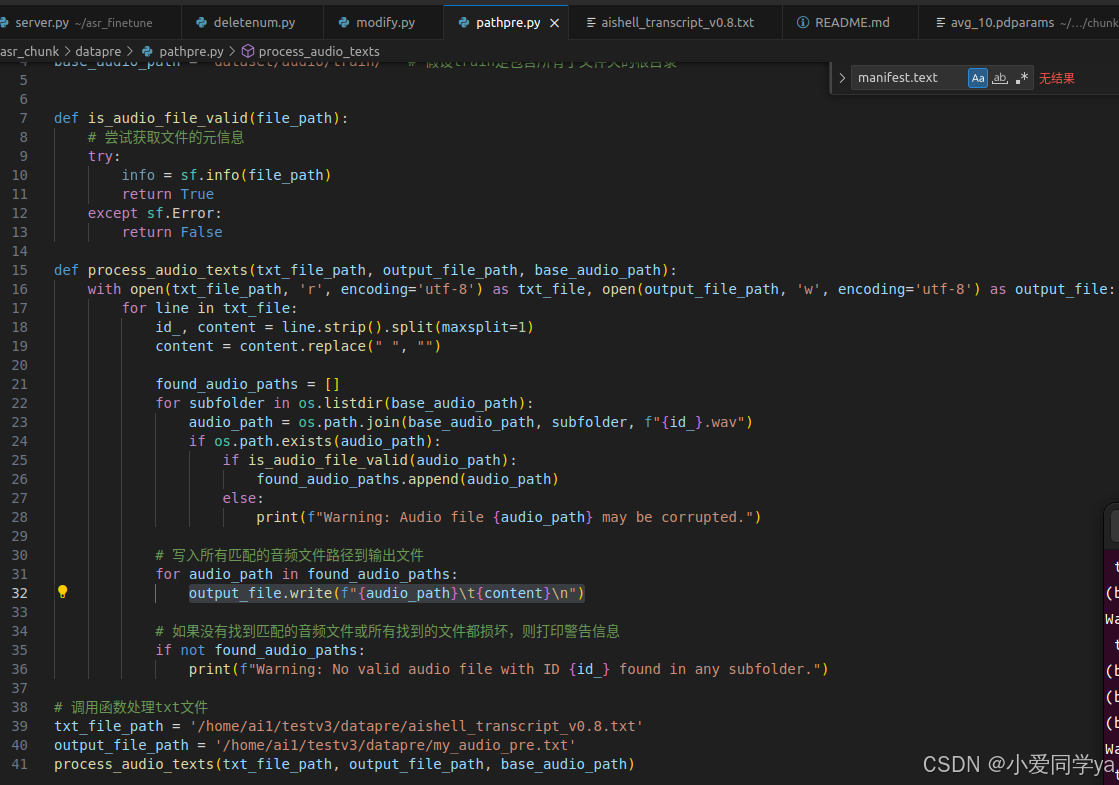
再通过一个随机筛选的py文件,将我的数据集与源数据集掺入接近到1:1的比例。
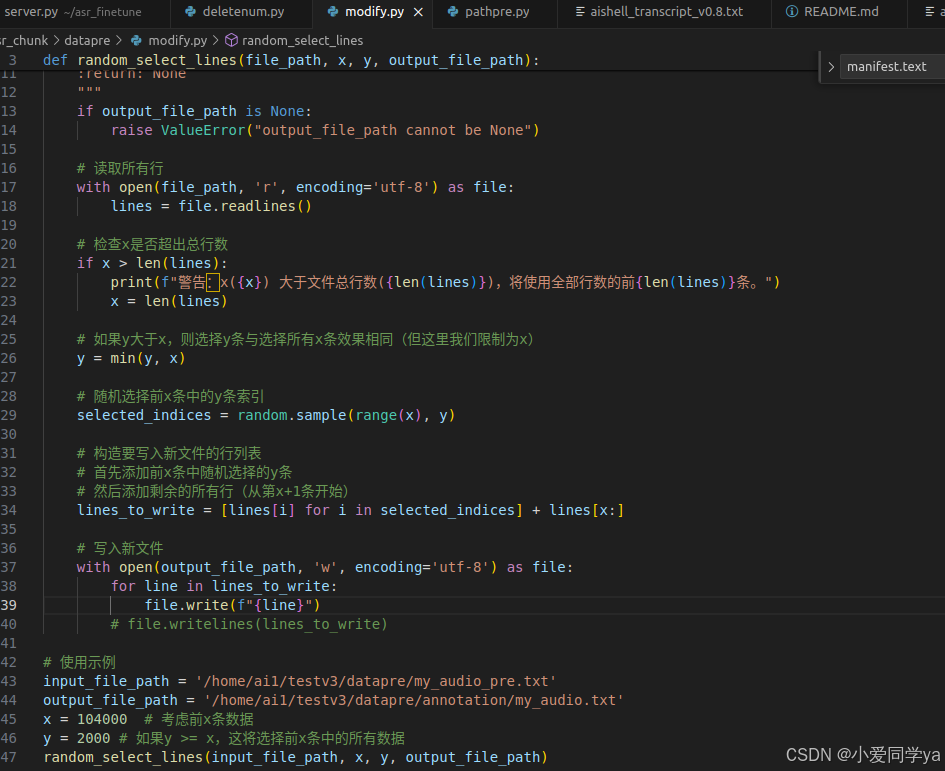
我自己的数据集大概有三千多条,放在末尾,文件大概107080条,这个文件就是从前104000数据中随机选出2000条进行掺入。
3.训练数据train.py
这是当时问ai得到的,普遍的微调流程。我们根据这个流程对源工程代码进行更改。一共五个步骤。这个大概看看了解即可。
# 1. 加载配置文件和预训练模型
config = paddle.load('path_to_config.yml') # 加载YAML配置文件
model_class = dynamic_import_asr_model(config.model)
asr_model = model_class.from_config(config.model)
asr_model.set_state_dict(paddle.load('path_to_pretrained_model.pdparams'))
asr_model.eval()
# 2. 准备数据加载器
# 假设有一个名为MyAudioDataset的自定义数据集类
from your_dataset_module import MyAudioDataset
# 初始化特征归一化
cmvn = CMVN(norm_mean=None, norm_var=None, eps=1e-8) # 或者从统计文件中加载参数
# 创建数据集实例
train_dataset = MyAudioDataset('path_to_train_data', cmvn=cmvn)
collate_fn = lambda batch: get_feats_and_labels(batch)
batch_sampler = BatchSampler(train_dataset, batch_size=config.batch_size, shuffle=True)
train_loader = DataLoader(train_dataset, batch_sampler=batch_sampler, collate_fn=collate_fn)
# 3. 定义优化器和损失函数
optimizer = paddle.optimizer.Adam(learning_rate=config.learning_rate, parameters=asr_model.parameters())
criterion = paddle.nn.CTCLoss(blank=config.ctc_blank, reduction='mean')
# 4. 开始微调
asr_model.train()
for epoch in range(config.epochs):
for batch_id, (feats, feats_lengths, labels, labels_lengths) in enumerate(train_loader()):
# 前向传播
outputs = asr_model(feats, feats_lengths)
# 计算损失
loss = criterion(outputs, labels, feats_lengths, labels_lengths)
# 反向传播和优化
loss.backward()
clip_grad_norm_(asr_model.parameters(), config.grad_clip_norm)
optimizer.step()
optimizer.clear_grad()
# 打印训练信息(可选)
if batch_id % config.log_interval == 0:
print(f"Epoch {epoch}, Batch {batch_id}, Loss: {loss.numpy()}")
# 5. 保存微调后的模型
paddle.save(asr_model.state_dict(), 'path_to_finetuned_model.pdparams')注意,paddle的conformer/Transformer/u2pp基本都是基于U2Model来的,如果你要训练deepspeech2,之前的模型特征值就不用改,但是特征提取函数最好还是换成官方的去训练比较好。最后因为我只能找到U2Model,和原本预训练模型大小就会有所不同,但是最后推理用的也是U2Model进行参数的加载,使用是没有问题的,有这个疑问的朋友或许可以自己跟着官方的训练一下看看是不是也这样。
在这里可以对参数进行更改。
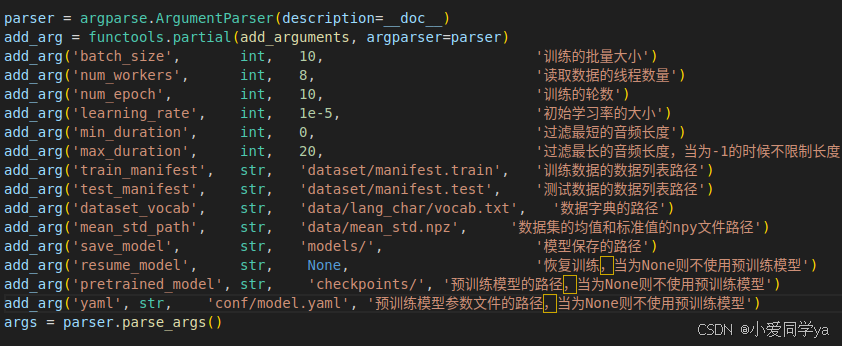
还要注意,如果一直有报错,注释掉paddle.summary试试,这个函数是展示模型结构的,可能是版本不兼容,但是不影响训练。
3.1 获取模型参数
# 读取 conf 文件并获取结构化模型
config = CfgNode(new_allowed=True)
config.merge_from_file(args.yaml)
model = U2Model.from_config(config) 3.2 加载训练数据
测试我是另外有文件,这部分把测试删除了。训练完成后,我直接替换原paddle模型文件,读取我的测试数据进行测试。
train_dataset = PPASRDataset(args.train_manifest, args.dataset_vocab,
mean_std_filepath=args.mean_std_path,
min_duration=args.min_duration,
max_duration=args.max_duration,
augmentation_config='{}')3.3 定义优化器和损失函数
scheduler = paddle.optimizer.lr.ExponentialDecay(learning_rate=args.learning_rate, gamma=0.83, last_epoch=last_epoch - 1)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(),
learning_rate=scheduler,
weight_decay=paddle.regularizer.L2Decay(1e-5),
grad_clip=grad_clip)3.4 开始训练
# 开始训练
for epoch in range(last_epoch, args.num_epoch):
epoch += 1
start_epoch = time.time()
for batch_id, (inputs, labels, input_lens, label_lens) in enumerate(train_loader()):
start = time.time()
# print(inputs.shape, input_lens.shape, labels.shape, label_lens.shape)
# 新的顺序是:第一个轴保持不变(0),第三个轴变为第二个轴(2),第二个轴变为第三个轴(1)
inputs_tran = paddle.transpose(inputs, perm=[0, 2, 1])
# out, out_lens = model(inputs_tran, input_lens, labels, label_lens)
loss,_,_= model.forward(inputs_tran, input_lens, labels, label_lens)
loss = loss / paddle.shape(inputs)[0]
loss.backward()
optimizer.step()
optimizer.clear_grad()
# 多卡训练只使用一个进程打印
if batch_id % 100 == 0 and local_rank == 0:
eta_sec = ((time.time() - start) * 1000) * (sum_batch - (epoch - 1) * len(train_loader) - batch_id)
eta_str = str(timedelta(seconds=int(eta_sec / 1000)))
print('训练[{}] Train epoch: [{}/{}], batch: [{}/{}], loss: {:.5f}, learning rate: {:>.8f}, eta: {}'.format(
datetime.now(), epoch, args.num_epoch, batch_id, len(train_loader), float(loss), scheduler.get_lr(), eta_str))
writer.add_scalar('Train loss', loss, train_step)
trainloss.append(float(loss))
train_step += 1
# 固定步数也要保存一次模型
if batch_id % 2000 == 0 and batch_id != 0 and local_rank == 0:
save_model(args=args, epoch=epoch, model=model, optimizer=optimizer)3.5 保存模型
这部分主要就是paddle.save函数,但是还有一些保存文件删除文件的逻辑,这个就是会一直保存最新的三个训练参数文件。
def save_model(args, epoch, model, optimizer):
model_path = os.path.join(args.save_model, 'epoch_%d' % epoch)
if not os.path.exists(model_path):
os.makedirs(model_path)
paddle.save(model.state_dict(), os.path.join(model_path, 'model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(model_path, 'optimizer.pdopt'))
# 删除旧的模型
old_model_path = os.path.join(args.save_model, 'epoch_%d' % (epoch - 3))
if os.path.exists(old_model_path):
shutil.rmtree(old_model_path)4. 测试
主要是1.文件读取的处理逻辑 2.model类型要和你之前微调的预训练模型一致。
def cer(s1, s2):
"""
通过计算两个字符串的距离,得出字错率
Arguments:
s1 (string): 比较的字符串
s2 (string): 比较的字符串
"""
s1, s2, = s1.replace(" ", ""), s2.replace(" ", "")
return Lev.distance(s1, s2)
# 初始化ASRExecutor(可能需要添加其他配置参数)
asr = ASRExecutor()
# 音频文件都在 "audio" 文件夹下,并且按照 1.wav, 2.wav, ... 的格式命名
# 每行包含 "编号 文本" 的格式
transcription_file = Path("/home/ai1/testv2/dataset/annotation/my_audio.txt")
# 用于计算识别错误的变量
total_errors = 0
total_words = 0
err = []
# 创建一个空字典来存储错误单词及其出现次数
word_error_dict = {}
cnt = 0
# 读取文本文件并处理每一行
with transcription_file.open('r', encoding='utf-8') as f:
for line_num, line in enumerate(f, start=1):
# 分割行内容,假设编号和文本之间由空格分隔
transcription_id, correct_transcription = line.strip().split('\t')
audio_file = Path(transcription_id)
# 检查音频文件是否存在
if not audio_file.exists():
cnt = cnt+1
# print(f"Audio file {audio_file} does not exist. Skipping...")
continue # 跳过当前循环,处理下一行
# 使用ASRExecutor处理音频文件
result = asr(audio_file=audio_file,model = 'conformer_wenetspeech')
# 这里假设 result 是一个字符串,包含识别到的文本
correct_transcription = correct_transcription.replace(" ", "")
print("line39.......", transcription_id,result,correct_transcription)
# 计算单词错误数
recognized_words = list(jieba.cut(result))
correct_words = list(jieba.cut(correct_transcription))
# 找出 recognized_words 中但不在 correct_words 中的单词
error_words = set(recognized_words) - set(correct_words)
err.append(cer(result , correct_transcription) / float(len(correct_transcription)))
# 遍历错误单词并更新字典
for word in error_words:
if word in word_error_dict:
word_error_dict[word] += 1
else:
word_error_dict[word] = 1
aver_err = float(sum(err) / len(err))
# 打印字典以查看结果
print('line67.......',word_error_dict)
print('line68.......',aver_err)
如果是流式的模型,挂起服务端和客户端进行测试。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









