






一、子查询(Sub Query)
1. 子查询相关知识
子查询概念:一条select查询语句的结果作为另一条select语句的一部分
子查询的特点:
- 子查询一般作为查询条件使用。
- 使用子查询, 必须将子查询放在小括号中使用。
- 一条SQL语句含有多个select,一般是先执行子查询,再执行外查询。
子查询分类:单行子查询和多行子查询。
2. 单行子查询
单行子查询: 查询出的结果为一列一行(一个数据) 如: 最高,最低,平均等,可以使用判断符号 如: >,< ,= ,!= 等。
语法格式:select 字段 from 表 where 字段 判断符号 (子查询)。
#1 查询价格最高的商品信息
select * from products where price = (select max(price) from products);
#2 查询化妆品分类下的 商品名称 商品价格
select pname, price from products where cid=(select cid from category where cname='化妆品');
#3 查询小于平均价格的商品信息
select * from products where price < (select avg(price) from products);
3. 多行子查询
多行子查询: 查询出的结果为一列多行(多个数据) ,可以使用判断符号 如: in, all, any。
| in | 等于任意一个 | 使用式: in(值1,值2 ...) |
| all | 所有 | 使用方式: 字段 > | <all(值1,值2 ...) 大于所有的值 |
| any | 任意一个 | 字段 > | < any(值1,值2 ...) 大于任意一个值。 字段 = any(值1,值2 ...) 等于任意一个值 效果等同于 in。 |
格式:select 字段 from 表 where 字段 判断符号 (in , any ,all) (子查询);
#1 查询化妆品类别中的商品价格和鞋服类别中的商品价格一样的 鞋服商品信息
-- 查询化妆品类别中的商品价格
select price from products where cid = (select cid from category where cname='化妆品'); -- 800 200
select * from products where price in(select price from products where cid = (select cid from category where cname='化妆品'));
select * from products where price in(select price from products where cid = (select cid from category where cname='化妆品'))
and cid = (select cid from category where cname='鞋服');
#2 查询价格比所有鞋服类别中商品的价格都高的商品信息
-- 方式1:多行子查询实现
select * from products where price > all(select price from products where cid = (select cid from category where cname='鞋服'));
-- 方式2:单行子查询实现
select * from products where price > (select max(price) from products where cid = (select cid from category where cname='鞋服'))
#3 查询价格比任意一个鞋服类别中商品的价格高的商品信息
-- 方式1:多行子查询实现
select * from products where price > any(select price from products where cid = (select cid from category where cname='鞋服'));
-- 方式2:单行子查询实现
select * from products where price > (select min(price) from products where cid = (select cid from category where cname='鞋服'));
二、存储引擎
- 数据库存储引擎:是数据库管理系统中的重要组成部分。数据库管理系统(DBMS)使用存储引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得特定的功能。现在许多不同的数据库管理系统都支持多种不同的数据引擎。
- MySQL的核心就是插件式存储引擎。
- MySQL 可以通过 show engines 查看所有支持的存储引擎。
各个引擎的介绍:
| InnoDB | 默认的存储引擎,也是所有存储引擎中唯一支持事务、XA协议的存储引擎。 |
| MyISAM | 基于ISAM(Indexed Sequential Access Method目前已经废弃)的存储引擎,特点是查询效率较高。但不支持事务和容错性。 |
| MEMORY | 纯内存型型存储引擎。所有数据都在内存中,硬盘只存储.frm文件。所以当MySQL宕机或非法关闭时只生效表结构。由于所有数据都在内存上,所以相对来说性能较高。 |
| MRG_MYISAM | 以前也叫MERGE,简单理解就是对MyISAM表做了特殊的封装,对外提供单一访问入口,减少程序的复杂性。 |
| ARCHIVE | 主要用于通过较小的存储空间来存放过期的很少访问的历史数据。 ARCHIVE表不支持索引,通过一个.frm的结构定义文件,一个.ARZ的数据压缩文件还有一个.ARM的meta信息文件。由于其所存放的数据的特殊性,ARCHIVE表不支持删除,修改操作,仅支持插入和查询操作。 |
| BLACKHOLE | 俗称“黑洞”存储引擎。是一个非常有意思的存储引擎。所有的数据都是有去无回。 |
| CSV | 实际上操作的就是一个标准的CSV文件,不支持索引。主要用途就是可以通过先在数据库中建立一张CSV表,然后将生成的报表信息插入到该表,即可得到一份CSV报表文件了。 |
| PERFORMANCE_SCHEMA | 从MySQL 5.6新增的存储引擎。主要用于收集一些系统参数。 |
三、数据库事务控制(TCL)
1. 事务的概念
事务是一个整体,由一条或者多条SQL语句组成,这些SQL语句要么都执行成功,要么就失败,只要有一条SQL出现异常,整个操作就会回滚。
回滚: 就是事务运行的过程中发生了某种故障,或者SQL出现了异常,事务不能继续执行,系统将事务中对数据库的所有已完成的操作全部取消,回滚到事务开始时的状态。
常用的存储引擎有InnoDB(MySQL5.5以后默认的存储引擎)和MyISAM(MySQL5.5之前默认的存储引擎),其中InnoDB支持事务处理机制,而MyISAM不支持。
2. MySQL事务操作
MySQL 中可以有两种方式进行事务的操作:
自动提交事务(MySQL默认)
手动提交事务
2.1 手动提交事务
| 功能 | 语句 |
| 开启事务 | start transaction; 或 begin; |
| 提交事务 | commit; |
| 回滚事务 | rolldack; |
-
start transaction 或 begin 这个语句显式地标记一个事务的起始点。手动开启事务后,事务不再是自动提交。
-
commit 表示提交事务,即提交事务的所有操作,就是将事务中所有对数据库的更新都写到磁盘上的物理数据库中,事务正常结束。
-
rolldack 表示撤销事务,即在事务运行的过程中发生了某种故障,事务不能继续执行,系统将事务中对数据库的所有已完成的操作全部撤销,回滚到事务开始时的状态。
2.2 手动提交事务的流程

手动开启事务 start transaction。手动开启事务后,事务不再是自动提交。
提交事务 commit。没有出现任何问题,提交事务 数据就会持久化到本地磁盘。
回滚事务 rollback。出现问题回滚事务,回滚事务要在提交事务之前操作,一旦事务完成了提交,就不能再回滚. 如出现宕机等情况事务会自动回滚。
示例 :
-- 开启事务
start transaction;
-- 执行多条SQL语句
update account set money = money-500 where name = 'tom';
update account set money = money+500 where name = 'jack';
-- 提交事务(没发生任何问题提交)
commit;
-- 回滚事务(出现问题回滚,如果出现宕机等原因事务会自动回滚)
rollback;2.3 事务的四大特性 ACID(重点)
| 原子性 (Atomicity) | 一个事务要么全部提交成功,要么全部失败回滚,不能只执行其中的一部分操作,这就是事务的原子性 。 |
| 一致性(Consistency) | 指事物必须是数据库从一个一致性状态到另一个一致性状态。一致性规定事务提交前后只存在两个状态,提交前的状态和提交后的状态。事务按照预期生效,数据的状态是预期的状态。 |
| 隔离性 (Isolation) | 事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 |
| 持久性 (Durability) | 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。 |
3. MySQL事务的问题及解决
3.1 并发访问产生的问题(重点)
事务在操作时的理想状态:所有的事务之间保持隔离,互不影响。因为并发操作,多个用户同时访问同一个数据,可能引发并发访问的问题,破坏数据的完整性 。
| 脏读 | A事务读取B事务尚未提交的数据并在此基础上操作,而B事务执行回滚,那么A读取到的数据就是脏数据。 |
| 不可重复读 | 一个事务中两次读取的数据内容不一致,要求的是在一个事务中多次读取时数据是一致的.这是进行update操作时引发的问题。 |
| 幻读 | 事务A重新执行一个查询,返回一系列符合查询条件的行,发现其中插入了被事务B提交的行。 |
3.2 四种隔离级别
通过设置隔离级别,可以防止上面的三种并发问题. MySQL数据库有四种隔离级别级别高低从上到下。
1.串行化
当数据库系统使用SERIALIZABLE隔离级别时,一个事务在执行过程中完全看不到其他事务对数据库所做的更新。当两个事务同时操作数据库中相同数据时,如果第一个事务已经在访问该数据,第二个事务只能停下来等待,必须等到第一个事务结束后才能恢复运行。因此这两个事务实际上是串行化方式运行。脏读,不可重复读,幻读都不会出现
2.可重复读
当数据库系统使用REPEATABLE READ隔离级别时,一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,但是不能看到其他事务对已有记录的更新。会出现幻读的情况。
3.读已提交
当数据库系统使用READ COMMITTED隔离级别时,一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,而且还能看到其他事务已经提交的对已有记录的更新。不可重复读,幻读可能会出现。
4.读未提交
当数据库系统使用READ UNCOMMITTED隔离级别时,一个事务在执行过程中可以看到其他事务没有提交的新插入的记录,而且还能看到其他事务没有提交的对已有记录的更新。会出现脏读的问题。脏读,不可重复读,幻读可能会出现。
注意事项:
- 隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。
- MVCC多版本控制机制,读取时采用快照读,读取的内容来源于快照,解决不可重复读,幻读。
- Oracle和SQLServer默认隔离级别为读已提交。Mysql默认隔离级别为可重复读。
3.3 隔离级别相关命令
- 查看隔离级别 :select @@transaction_isolation;
- 设置隔离级别
-- 设置隔离级别语法格式
set session transaction isolation level 隔离级别名称;
-- 如: 设置为读未提交
set session transaction isolation level read uncommitted;
-- read uncommitted 读未提交
-- read committed 读已提交
-- repeatable read 可重复读
-- serializable 串行化四、索引
1. 索引介绍
- 索引类似图书的目录,一种数据结构,通过索引可以快速的找到需要查询的内容。
- 索引和数据都是存储在.idb文件(InnoDB引擎)。
- 索引和数据存储在不同的文件中(MyISAM引擎)。
2. 索引的结构
索引在数据库底层有两种结构:BTREE和HASH。默认使用的是BTREE。
2.1 HASH结构
Hash底层实现是由Hash表来实现的,是根据键值 <key,value> 存储数据的结构。非常适合根据key查找value值,也就是单个key查询,或者说等值查询。

缺点:
哈希表这种结构是不支持模糊查找,只能遍历这个表(哈希表是把索引字段映射成对应的哈希码然后再存放在对应的位置)。
适合于精确的查找,不适合范围查询。
2.2 BTREE结构
BTree分为B-Tree和B+Tree,MySQL数据库索引采用的B+Tree,B+Tree是在B-Tree上做了优化改造。
B-Tree结构:
索引值和data(数据)分布在整棵树结构中
每个节点可以存放多个索引值以及对应的data(数据)
树节点中的多个索引值从左到右升序排列
缺点:所有的节点都存放数据,数据会占用空间,导致存放的索引变少。
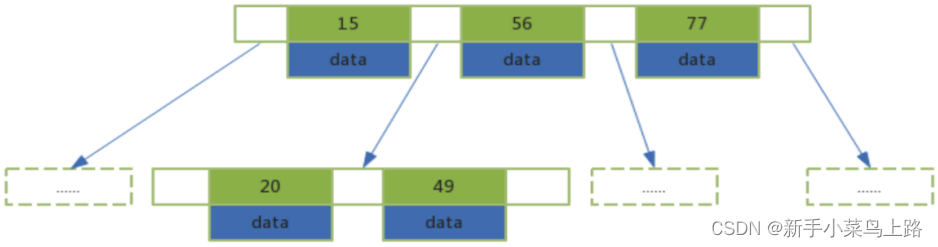
B+Tree结构
非叶子节点不存储data数据,只存储索引值,这样便于存储更多的索引值。
叶子节点包含了所有的索引值和data数据。
叶子节点用指针连接,提高区间的访问性能。
B+树进行范围查找时,只需要查找定位两个节点的索引值,然后利用叶子节点的指针进行遍历即可。B-树需要遍历范围内所有的节点和数据,显然B+Tree效率高。

2.3 其它树结构回顾
| 树结构 | 优点 | 缺点 |
|---|---|---|
| 二叉树 | 可以进行范围查询 | 树会失去平衡,在进行数据查询的时候需要比较N多次才行 |
| 平衡二叉树 | 可以通过算法自动的平衡 | AVL树对平衡的要求比较严格,稍微有一点失衡直接就使用算法进行平衡,这个过程是比较耗费时间 |
| 红黑树 | 相当于二叉树和AVL树的中间产物,红黑树会追求绝对的平衡,所以不会有很多次的裂变 | 树特别深的话,比较起来还是很耗时的 |
3. 索引的优点
创建索引可以大大提高系统的查询性能。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 可以加速表和表之间的连接,特别是在实现数据的完整性方面特别有意义。
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
- 通过使用索引,可以在查询的过程中 ,使用查询优化器,提高系统的性能。
4. 索引的缺点
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
- 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间。如果要建立聚簇索引,那么需要的空间就会更大。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
5. 什么样的字段适合创建索引
一般来说,应该在具备下述特性的列上创建索引:
- 在经常需要搜索的列上,可以加快搜索的速度;
- 在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
- 在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
- 在经常需要排序的列上创建索引,可加快排序查询时间;
- 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
建立索引,一般按照select的where条件来建立,
比如: select的条件是where f1 and f2,那么如果我们在字段f1或字段f2上建立索引是没有用的,只有在字段f1和f2上同时建立索引才有用等。
6. 什么样的字段不适合创建索引
一般来说,不应该创建索引的这些列具有下述特点:
- 对于那些在查询中很少使用或者参考的列不应该创建索引。
- 对于那些只有很少数据值的列也不应该增加索引。
- 对于那些定义为text,image和bit数据类型的列不应该增加索引。
- 当修改性能远远大于检索性能时,不应该创建索引。
7. 索引分类
7.1 索引种类
索引分为单列索引和组合索引。
- 单列索引就是只是给某个列加索引;
- 组合索引是给表中大于等于两个列添加索引。
7.2 单列索引
单列索引又分为:主键索引、普通索引和唯一索引。
7.2.1 主键索引
特点:添加了主键约束,自动创建主键索引。唯一 + 非空
创建主键索引的方式:
-- 1. 创建表时指定主键约束
create table 表名(
字段1 类型 primary key,
...
);
-- 2. 为创建好表,但是并没有指定主键约束的表添加主键约束
alter table 表名 add primary key(字段名);
-- 3. 查看某张表中的所有索引
show index from 表名;7.2.2 唯一索引
特点:添加了唯一约束,自动创建索引索引。手动添加唯一索引。唯一 可以为null。
创建索引的方式:
-- 创建表时指定唯一约束,会自动创建唯一索引
create table 表名(
字段1 类型 unique,
...
);
-- 为创建好的表添加唯一索引
alter table 表名 add unique index [索引名称](字段名);
-- 为创建好的表添加唯一索引
create unique index <索引名称> on 表名(字段名);7.2.3 普通索引
特点:建立在非主键约束,外键约束,唯一约束的列上。不唯一可以为null。
创建索引的方式:
-- 1. 创建表时创建普通索引
create table 表名(
字段1 类型,
...,
index [索引名称](字段名) -- 不指定索引名称,自动生成
);
-- 2. 为创建好的表添加普通索引
alter table 表名 add index [索引名称](字段名); -- 不指定索引名称,自动生成
-- 3. 为创建好的表添加普通索引
create index <索引名称> on 表 (字段名); -- 必须指定索引名称7.3 组合索引
也叫联合索引,给表中大于等于两个列添加索引。
但是需要满足最左前缀,创建组合索引相当于创建了多个索引,一般把最常用的放在最左边。
创建索引的方式:
-- 语法格式:
create index 索引名 on 表名(列1,列2...)
create index index3 on demo(col1,col2,col3)
create index index3 on demo(col1,col2)
相当于创建col1、col1-col2、col1-col2-col3、col1-col3四个索引。可以通过执行计划查询,如果执行计划类型为ref表示使用索引,如果类型为index表示没有匹配到合适索引。
查看MySQL的执行计划:
const(主键查询) > ref (非唯一性索引扫描)> range (索引范围扫描)> index(扫描全部索引) > all(全表扫描)
7.4 全文索引
7.4.1创建
-- 创建表
create table tb_fulltext(
id int(11) primary key auto_increment,
name varchar(100),
address varchar(200),
-- 方式1
FULLTEXT index_name (name)
);
-- 方式2
ALTER TABLE table_name ADD FULLTEXT index_name(name);7.4.2 使用
创建好的全文索引需要配合match(列,列) against(‘内容’)使用。
match中列必须和创建全文索引的列一样。例如创建全文索引是(id,name)(相当于组合索引),match(id)可以使用全文索引,match(name)无法使用全文索引,必须单独建立name列的全文索引。因为组合索引的最左前缀原则
-- 创建表
create table t8(
id int(11) primary key auto_increment,
name varchar(100),
address varchar(200),
FULLTEXT index_name (name) with parser ngram -- 手动指定的拆词器,默认两个字符进行拆分
);
insert into t8 values(default, '你多大了呀', 'sh');
insert into t8 values(default, '你多大', 'sh');
insert into t8 values(default, '大了呀', 'sh');
insert into t8 values(default, '了呀', 'sh');
select * from t8 where match(name) against("多大");
against中内容有三种模式:
自然语言模式:IN NATURAL LANGUAGE MODE
布尔模式:IN BOOLEAN MODE
查询扩展模式:WITH QUERY EXPANSION
自然语言模式:拆分出来的关键字必须严格匹配。例如beijing只能通过beijing搜索,不能通过bei搜索。
select * from t8 where match(name) against("你多"); -- 自然模式布尔模式:支持特殊符号。即使对没有全文索引的列也可以进行搜索,但是非常慢。查询时必须从最左开始查询。
| 特殊符号 | 说明 |
|---|---|
| + | 一定要有(不含有该关键词的数据条均被忽略) |
| - | 不可以有(排除指定关键词,含有该关键词的均被忽略) |
| > | 提高该条匹配数据的权重值 |
| < | 降低该条匹配数据的权重值 |
| ~ | 将其相关性由正转负,表示拥有该字会降低相关性(但不像 - 将之排除),只是排在较后面权重值降低 |
| * | 万用字,不像其他语法放在前面,这个要接在字符串后面。 因为搜索时只能满足最左前缀搜索like ‘内容%’,不能实现类似like ‘%内容%’这种 |
| "" | 用双引号将一段句子包起来表示要完全相符,不可拆字 |
# 多* 可以搜索到内容。 多 不能搜索到内容
select * from t8 where match(name) against("多*" in boolean mode); -- 布尔模式查询扩展:查询时进行扩展查询,发现和条件有关系的内容都查询出来
select * from t8 where match(name) against("你多" with query expansion); -- 拓展模式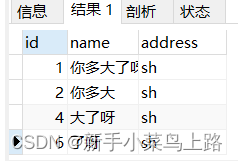
7.4.3 中文拆词器
由于中文是没有空格的,MySQL 从5.7.6开始内置ngram中文分词插件。可以设置把整个中文按照指定大小进行拆词。设置步骤如下:
-
在my.ini中[mysqld]下添加参数,设置拆词长度(根据自己的需求进行完成即可
ngram_token_size=2
2. 给address创建全文索引。注意后面的with parser ngram
create fulltext index index3 on ft(address) with parser ngram;8. 聚集索引和非聚集索引(面试题)
1. Innodb存储引擎:(索引和数据在同一个文件中)
- 聚集索引 (聚簇索引):并不是索引的分类,索引值和行数据存储在一起,数据会按照索引的顺序进行存储。
- 主键索引为聚集索引的一种,也可以自定义聚集索引(很少自定义)。
- 表中没有主键索引,自动找一个唯一非空的索引作为聚集索引,自动创建一个隐藏的字段作为聚集索引。
- 非聚集索引 (非聚簇索引,二级索引 ,辅助索引):并不是索引的分类,索引值和主键值存储在一起,根据索引值找到主键, 根据主键找到行数据(回表查询)
2. MyISAN存储引擎:(索引和数据在不同的文件中)
- 非聚集索引:索引值和行数据的地址存储在一起。
五、count(*),count(列),count(1)的区别
执行效果上:
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略为NULL的值。
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略为NULL的值。
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为null的计数,即某个字段值为NULL时,不统计。
执行效率上:
- 列名为主键,count(列名)会比count(1)快
- 列名不为主键,count(1)会比count(列名)快
- 如果表多个列并且没有主键,则 count(1 的执行效率优于 count(*)
- 如果有主键,则 select count(主键)的执行效率是最优的
- 如果表只有一个字段,则 select count(*)最优。
-
在InnoDB引擎中count(*)和count(1)性能没有什么差别
-
count(列)需要看列和count(*)优化后的列情况,如果count(列)使用了非索引列,而表中包含索引列则count(*)更快。如果count(列)和count(*)优化后的是同一个列则性能没有什么差别。如果表中没有索引则count(列)和count(*)性能也没有什么差别。
六、索引优化
1 优化案例
-
使用短索引(前缀索引)
对串列进行索引,如果可能应该指定一个前缀长度。
例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是唯一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
CREATE INDEX index_name ON table_name (column(length)); -
索引列排序
MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
-
like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引,而like “aaa%”(非前导模糊查询)可以使用索引。使用后,优化到range级别。
explain select * from teacher where address like '%oracle%'; -
不要在列上进行运算
例如:select * from users where YEAR(adddate)<2007,将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成:select * from users where adddate<’2007-01-01′。
应该把计算放在业务代码上完成,而不是交给数据库。
-
范围列可以使用索引
范围条件有:<、<=、>、>=、between等。
范围列可以用到索引(联合索引必须是最左前缀),但是范围列后面的列无法用到索引,索引最多用于一个范围列,如果查询条件中有两个范围列则无法全用到索引。所以where中把最主要的查询条件放在第一个。
alter table teacher add column (age int(3)); alter table teacher add column (weight int(3)); select * from teacher; update teacher set age=10,weight=90 where id = 1; update teacher set age=20,weight=100 where id = 2; update teacher set age=30,weight=110 where id = 3; create index age_index on teacher(age); create index weight_index on teacher(weight); select * from teacher where age between 10 and 20 and weight between 90 and 100; -
类型转换会导致索引无效
当列是文本类型时,把数值类型当作列的条件会弃用索引。
explain select * from teacher where name = 20;
2. 总结
索引的级别: const(主键查询) > ref (非唯一性索引扫描)> range (索引范围扫描)> index(扫描全部索引) > all(全表扫描)。
-
不要在where后的条件中进行列的运算和函数操作
-
模糊查询时,like‘%xxx%’,放弃使用索引二进行全表扫描。like‘xxx%’,可以使用索引索引级别为range。
-
类型转换会导致索引无效
MySQL只对以下操作符才使用索引:<,<=,=,>,>=,between,in,以及某些时候的like(不以通配符%或_开头的情形)。而理论上每张表里面最多可创建16个索引,不过除非是数据量真的很多,否则过多的使用索引也不是那么好玩的。
建议:一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
七、视图
1. 什么是视图
-
视图是一种虚拟表
-
视图建立在已有表的基础上,视图建立依赖的这些表称为基表
-
向视图提供数据内容的语句为 SELECT 语句,可以将视图理解为存储起来的 SELECT 语句
-
视图向用户提供基表数据的另一种表现形式
2. 视图的作用
简化复杂的查询
-
视图本身就是一条查询SQL,我们可以将一次复杂的查询构建成一张视图,用户只要查询视图就可以获取想要得到的信息(不需要再编写复杂的SQL),可以理解为查询视图就相当于将创建视图的SQL再次执行一次
-
视图主要就是为了简化复杂查询
3. 视图的使用
语法格式:
-- 创建视图
create view 视图名称 as select语句;
-- view: 表示视图
-- as: 表示视图要执行的操作
-- select: 向视图提供数据内容
-- 查询视图和查询表一样
select * from 视图名称;
-- 删除视图
drop view 视图名称;示例:
#1 显示所有类别名称以及其对应的商品名称,商品价格
select * from category c left join products p on c.cid = p.cid;
#2 把上边的查询语句,创建为一张试图
create view category_products_view
as
select c.cname,p.pname,p.price from category c left join products p on c.cid = p.cid;
#3 查询视图(相当于执行 #1的操作)
select * from category_products_view;
-- 需求: 将查询各个分类下的商品平均价格和类别名称,创建为一张视图.
create view cate_dep_view as
select c.cname,avg(price) from category c left join products p
on c.cid = p.cid group by c.cname;4. 视图与表的区别
-
视图是建立在表的基础上,表存储数据库中的数据,而视图只是做一个数据的展示
-
通过视图不能改变表中数据(一般情况下视图中的数据都是表中的列 经过计算得到的结果,不允许 更新)
-
删除视图,表不受影响,而删除表,视图不再起作用
八、存储过程
1. 存储过程介绍
存储过程就是数据库中保存(Stored)的一系列SQL命令(Procedure)的集合。也可以将其看作相互之间有关系的SQL命令组织在一起形成的一个方法。
2. 存储过程的优点
-
提高执行性能。
-
可减轻网络负担
-
可将数据库的处理黑匣子化。
3. 案例
-- 定义一个存储过程
DELIMITER //
create procedure myproc1(in name varchar(10))
begin
if name is null or name = '' then
select * from emp;
else
select * from emp where ename like concat('%',name,'%');
end if;
end;
//
DELIMITER ;
-- 运行存储过程
call myproc1('');
call myproc1('精');
-- 删除存储过程
drop procedure myproc1;
-- 定义存储过程,有返回值
DELIMITER //
create procedure myproc2(in name varchar(10),out num int(4))
begin
if name is null or name = '' then
select * from emp;
else
select * from emp where ename like concat('%',name,'%');
end if;
select found_rows() into num;
end
//
DELIMITER ;
-- 运行存储过程
call myproc2('精',@num);
select @num;create procedure 存储过程名称(参数);//可以无参,也可以带参数,和java的方法名差不多
有参数的设置:(in|out|inout 参数名称 数据类型)
in:输入参数,表示该参数的值必须调用存储过程时指定
out:输出参数,表示可以被存储过程改变,并且可以返回
inout:输入输出参数,在调用时指定,可以被改变和返回
说明:
分隔符
MySQL默认以";"为分隔符,如果没有声明分割符,则编译器会把存储过程当成SQL语句进行处理,因此编译过程会报错,所以要事先用“DELIMITER //”声明当前段分隔符,让编译器把两个"//"之间的内容当做存储过程的代码;“DELIMITER ;”的意思是把分隔符还原。
局部变量
在mysql中声明局部变量使用@+变量名。(两个@是系统变量)
九、数据控制语言(DCL)
1. 用户管理
MySQL中可创建不同的用户,并分配不同的权限,保证MySQL中数据的安全性。
MySQL用户主要包括两种:
- root用户:为超级管理员拥有MySQL提供的所有权限。
- 普通用户::权限取决于该用户在创建时被赋予的权限有哪些. 没有赋予任何权限,只有可以登录mysql的权限。用户表存在于mysql库中的user表中,要先选择mysql库再进行操作
语法格式:
-- 查询所有用户
use mysql;
select * from user;
-- 创建用户
create user '用户名'@'主机名' identified by '密码';
-- 主机名: localhost 只能本机连接 % 所有都可以连接
-- 修改用户密码
alter user '用户名'@'主机名' identified by '密码';
-- 删除用户
drop user '用户名'@'主机名'; 2. 权限管理
-
MySQL通过权限管理机制可以给不同的用户授予不同的权限,从而确保数据库中数据的安全性
-
只能给存在的用户授权
-
新创建的用户只有登录的权限(USAGE)
语法格式:
-- 为某个用户授权
grant 权限1,权限2 ... on 数据库名.表名 to '用户名'@'主机名';
-- 查看某个用户有哪些权限
show grants for '用户名'@'主机名';
-- 撤销用户权限
revoke 权限1,... on 数据库名.表名 from '用户名'@'主机名';
-- 刷新权限(添加,撤销授权之后一定要刷新权限)
flush privileges;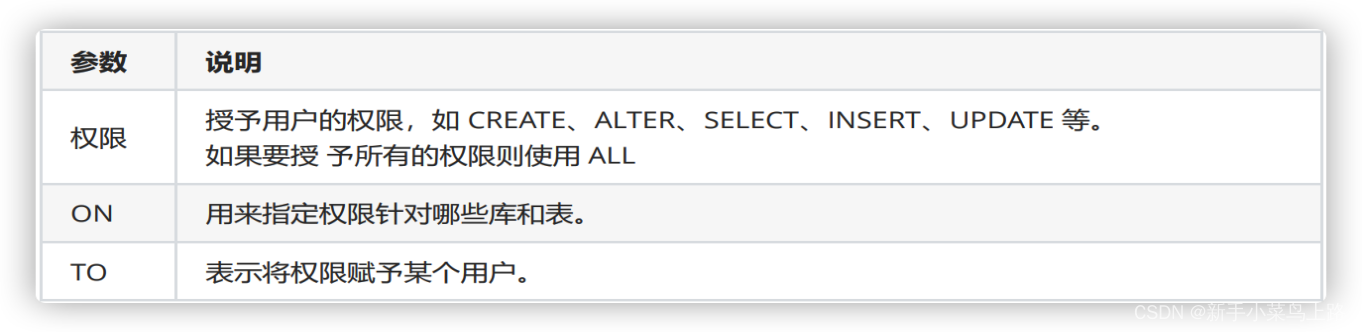
3. 角色管理
角色是指定的权限集合,和用户帐户一样可以对角色进行权限的授予和撤销。如果用户被授予角色,则该用户就拥有了该角色的权限。
语法格式:
-- 创建角色
create role '角色名称',...;
-- 为角色授权
grant 权限1,权限2,... on 数据库名.表名 to '角色名称';
-- 为用户分配角色
grant '角色名称' to '用户名'@'主机名';
-- 撤销角色的权限
revoke 权限1,... on 数据库名.表名 from '角色名称';4. 开启远程连接
# 创建用户
create user 'cy'@'%' identified by '123456';
#授权
#grant all on *.* to 'cy'@'%';
grant select on *.* to 'cy'@'%';
#刷新权限
flush privileges;














 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









