






一、Nginx
nginx安装
【1】安装pcre依赖
1.下载压缩包:wget http://downloads.sourceforge.net/project/pcre/pcre/8.37/pcre-8.37.tar.gz 2.解压压缩包:tar -xvf pcre-8.37.tar.gz 3.安装gcc:yum install gcc 4.安装gcc:yum install -y gcc gcc-c++ 5.在pcre-8.37目录输入:./configure 6.在pcre-8.37目录输入:make && make install【2】安装 openssl 、zlib 、 gcc 依赖
yum -y install make zlib zlib-devel gcc-c++ libtool openssl openssl-devel
【3】安装nginx
1.将nginx压缩包上传到usr/local目录下
2.解压到当前目录:tar -xvf nginx-1.12.2.tar.gz
3.进入nginx-1.12.2目录输入:./configure
4.进入nginx-1.12.2目录输入:make && make install【4】启动nginx
1.进入sbin目录:cd /usr/local/nginx/sbin
2.启动服务:./nginx【5】关闭防火墙
1.及时生效关闭防火墙: systemctl stop firewalld
2.重启永久生效:systemctl disable firewalld
Nginx常用命令
【1】查看nginx版本号 ./nginx -v
【2】启动nginx ./nginx
【3】停止nginx ./nginx -s stop
【4】重新加载nginx ./nginx -s reload
Nginx配置文件
Nginx配置文件的位置在: /usr/local/nginx/conf/nginx.conf
Nginx配置文件主要分为如下三部分
【1】全局块:配置服务器整体运行的配置指令,比如 worker_processes 1;处理并发数的配置
【2】events 块:影响 Nginx 服务器与用户的网络连接,比如 worker_connections 1024; 支持的最大连接数为 1024。
【3】http 块包含两部分: http 全局块、server 块

Nginx中的正则表达式
Nginx中的localtion语法如下:
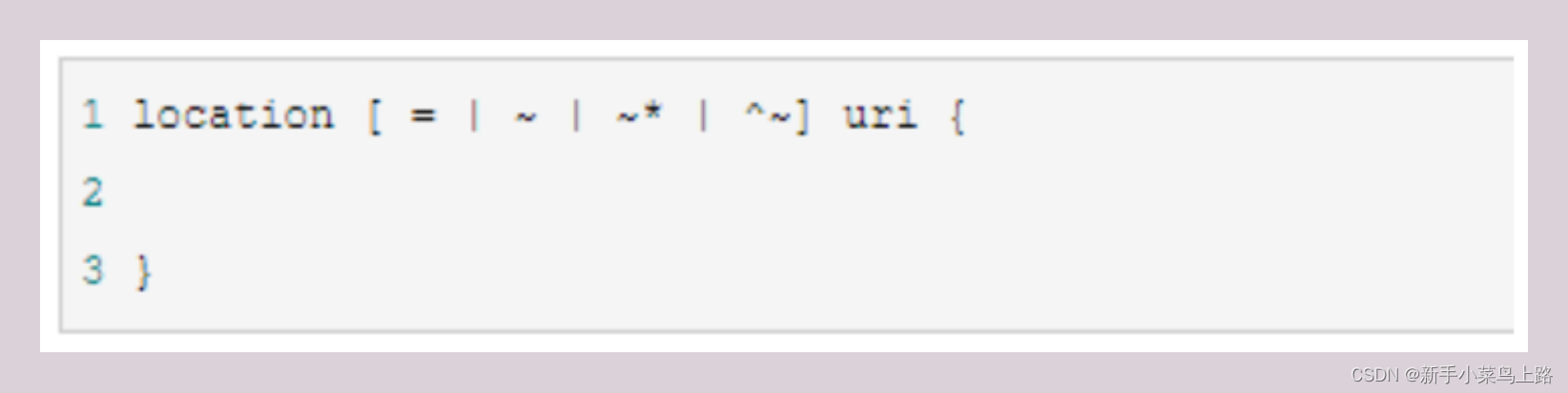
1、= :用于不含正则表达式的 uri 前,要求请求字符串与 uri 严格匹配,如果匹配成功,就停止继续向下搜索并立即处理该请求。
2、~:用于表示 uri 包含正则表达式,并且区分大小写。
3、~*:用于表示 uri 包含正则表达式,并且不区分大小写。
4、^~:用于不含正则表达式的 uri 前,要求 Nginx 服务器找到标识 uri 和请求字符串匹配度最高的 location 后, 立即使用此 location 处理请求,而不再使用 location 块中的正则 uri 和请求字符串做匹配。
注意:如果 uri 包含正则表达式,则必须要有 ~ 或者 ~* 标识。
负载均衡的几种配置
【1】轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器 down 掉,能自动剔除。
【2】 weight
weight 代表权重默认为 1,权重越高被分配的客户端越多
【3】 ip_hash
每个请求按访问 ip 的 hash 结果分配,这样每个访客固定访问一个后端服务器 ,可以解决session共享问题。
【4】 fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
总结
【1】什么是nginx服务器,nginx服务器是干什么用的,你都用过哪些功能?
答:nginx是http服务器,也是反向代理服务器,可以做静态网站资源服务器,也可以做反向代理服务器。用过负均衡、反向代理、动静分离、http服务器等功能。
nginx并发是50000,tomcat(500是理论值)大概300左右。
【2】nginx的常用命令
答:./nginx 启动 ./nginx -v 查看版本 ./nginx -s stop 关闭 ./nginx -s reload 重新加载配置文件
3】nginx如何配置静态服务
答:在/nginx/conf/nginx.conf中做如下配置(动静分离)
location /imgs/ {
root /data/;
autoindex on;
}
location /page/ {
root /data/;
autoindex on;
}
【4】如何配置反向代理
答:在/nginx/conf/nginx.conf做如下配置
location ~ /vod {
proxy_pass http://127.0.0.1:8082;
}
反向代理支持表达式如下:
location [= | ~ | ~* | ^~] /uri{ }
【5】负载均衡配置
在nginx/conf/nginx.conf做如下配置
upstream mystream {
server 127.0.0.1:8080 ;
server 127.0.0.1:8081 ;
}location ~ /edu {
proxy_pass http://mystream;
}
【6】什么是反向代理
正向代理代理的是客户端访问服务端,反向代理代理的是服务端,等待客户端访问代理服务。
具体配置:
location ~ /edu {
proxy_pass http://mystream;
}
【7】什么是动静分离
静态资源配置到nginx服务器中,动态资源通过nginx反向代理到tomcat。
二、docker虚拟化容器
Docker是什么
Docker 是一个开源的应用容器引擎,基于go语言并遵从apache2协议开源。
Docker可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化。
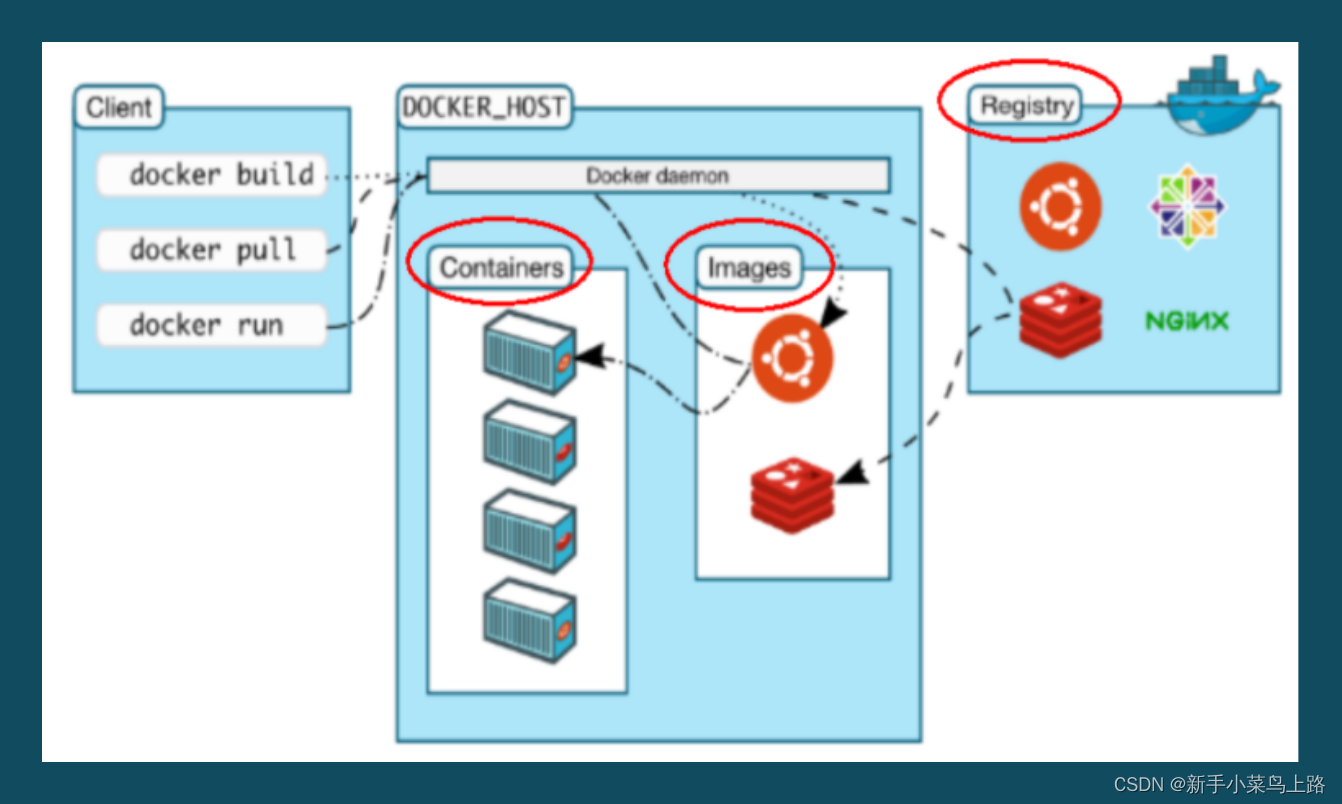
Docker的三要素和架构图
Docker的三要素:镜像、容器、仓库
Centos7上安装docker
如果之前安装过旧版本的Docker,可以使用下面命令卸载:
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine \
docker-ce
1)首先需要虚拟机联网,安装yum工具
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2 --skip-broken
2)然后更新本地镜像源:
# 设置docker镜像源
yum-config-manager \
--add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i 's/download.docker.com/mirrors.aliyun.com\/docker-ce/g' /etc/yum.repos.d/docker-ce.repoyum makecache fast
3)然后输入命令:
yum install -y docker-ce
启动docker前,一定要关闭防火墙后!!
# 关闭和禁止开机启动防火墙
systemctl stop firewalld
systemctl disable firewalld
通过命令启动docker:
systemctl start docker # 启动docker服务
systemctl stop docker # 停止docker服务
systemctl restart docker # 重启docker服务
docker -v #查看docker版本
配置镜像加速
docker官方镜像仓库网速较差,我们需要设置国内镜像服务:
参考阿里云的镜像加速文档:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台
#直接输入
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://q3hvejpu.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
Docker常用命令
镜像操作
-
镜名称一般分两部分组成:[repository]:[tag]。
常见的镜像操作如下:
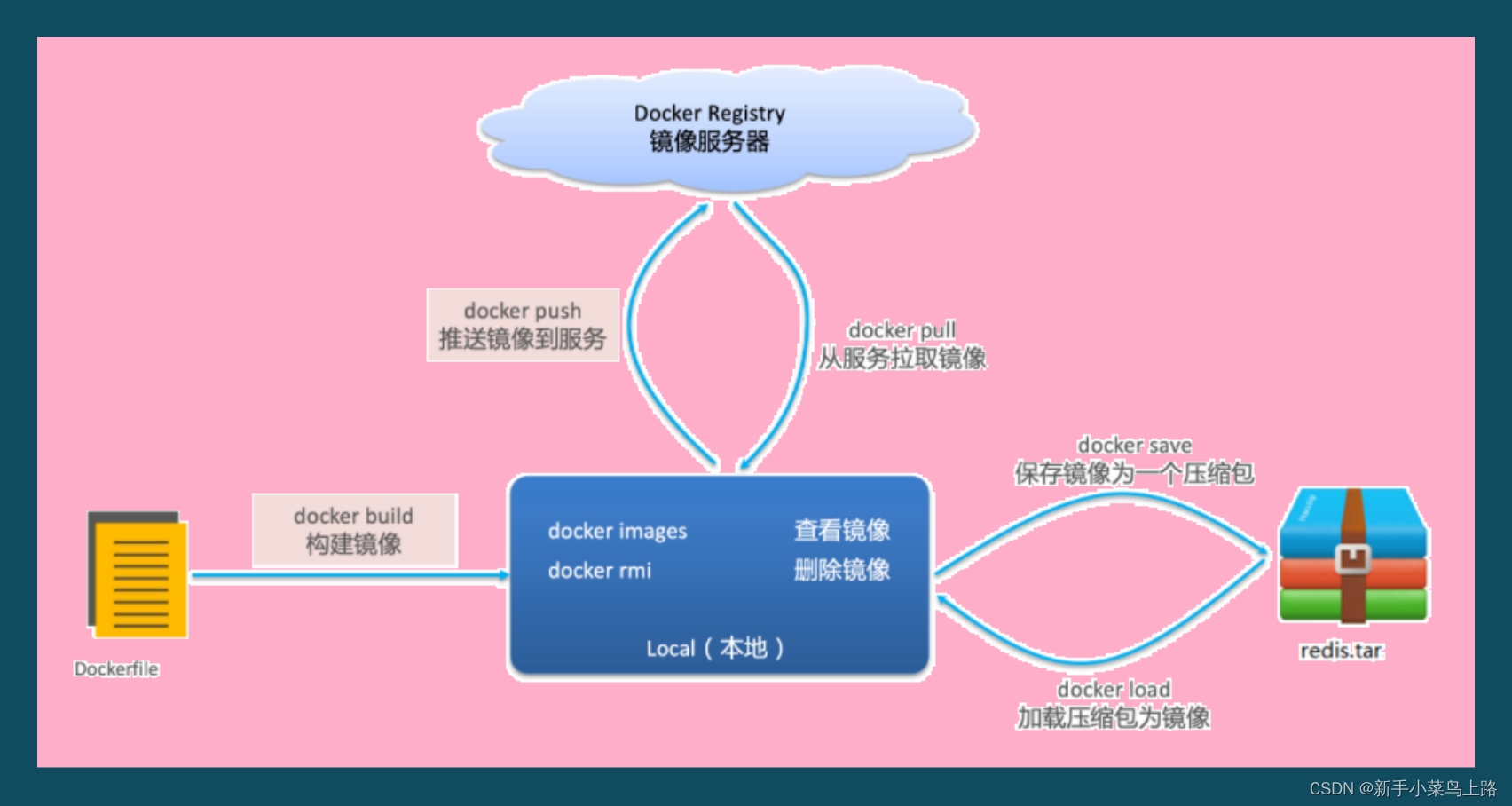
docker pull 镜像名 拉取自己需要的镜像,默认是最新tag版
docker images 查看已经获取的镜像
docker save -o /usr/local/nginx.tar nginx 保存镜像到磁盘(nginx 是镜像名)
docker rmi nginx 删除镜像
docker load -i /usr/local/nginx.tar 加载镜像
容器操作
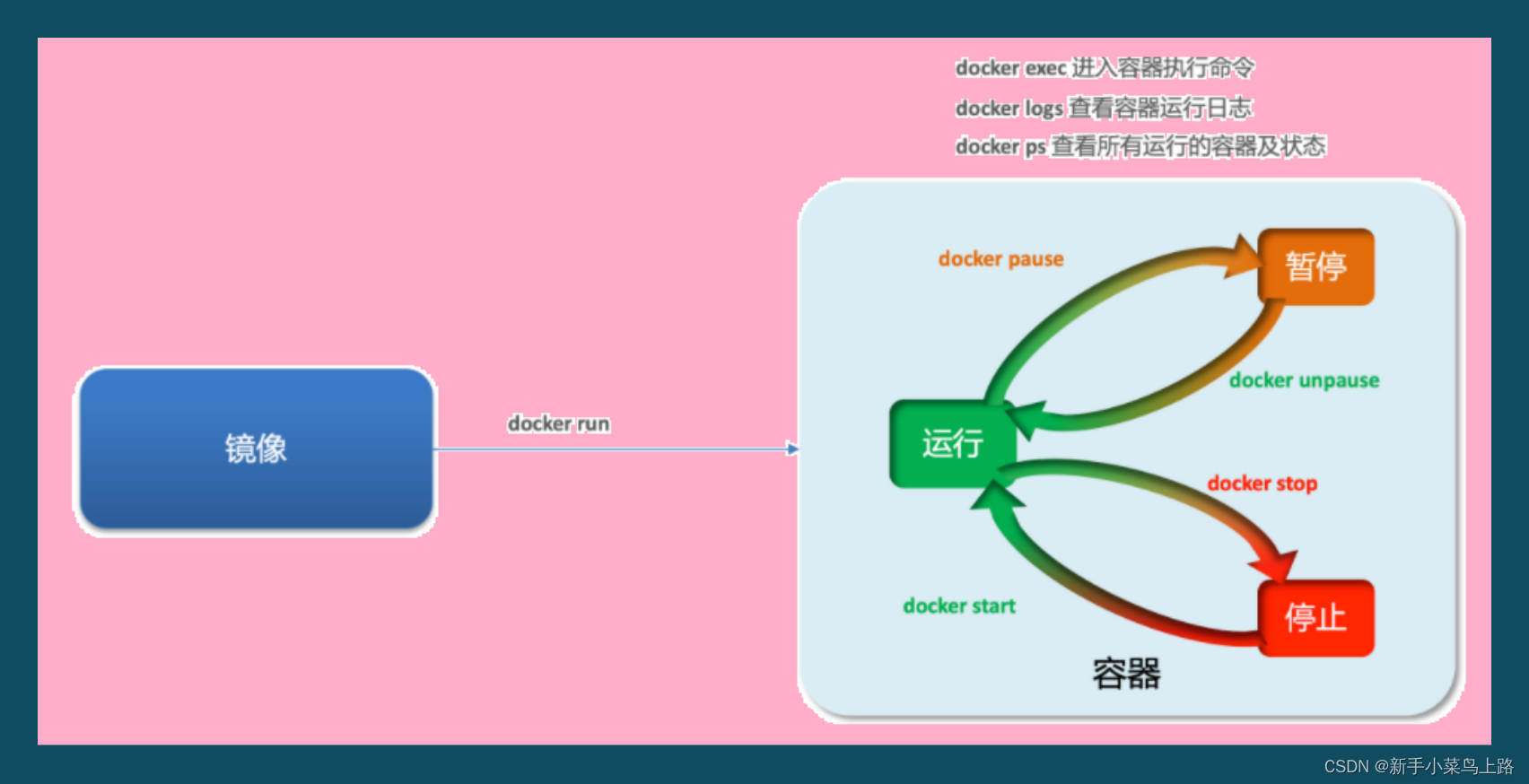
容器保护三个状态:
运行:进程正常运行
暂停:进程暂停,CPU不再运行,并不释放内存
停止:进程终止,回收进程占用的内存、CPU等资源
docker run:创建并运行一个容器,处于运行状态
docker pause:让一个运行的容器暂停
docker unpause:让一个容器从暂停状态恢复运行
docker stop:停止一个运行的容器
docker start:让一个停止的容器再次运行
docker rm:删除一个容器
docker run --name mynginx -p 80:80 -d nginx
命令解读:
docker run :创建并运行一个容器
--name : 给容器起一个名字,比如叫做mynginx
-p :将宿主机端口与容器端口映射,冒号左侧是宿主机端口,右侧是容器端口
-d:后台运行容器
nginx:镜像名称,例如nginx
查看启动的容器
docker ps # 查看所有运行的容器
docker ps -a # 查看所有容器包含关闭的查看日志信息-f持续查看日志
docker logs -f mynginx
进入容器内部
docker exec -it mynginx bash
命令解读:
docker exec :进入容器内部,执行一个命令
-it : 给当前进入的容器创建一个标准输入、输出终端,允许我们与容器交互
mynginx :要进入的容器的名称
bash:进入容器后执行的命令,bash是一个linux终端交互命令
复制命令
docker cp 容器:路径 宿主机路径 容器文件复制到宿主机
docker cp 宿主机路径 容器:路径 宿主机文件复制到容器
数据卷
数据卷(volume)是一个虚拟目录,指向宿主机文件系统中的某个目录。
一旦完成数据卷挂载,对容器的一切操作都会作用在数据卷对应的宿主机目录,操作宿主机的/var/lib/docker/volumes/html目录,就等于操作容器内的/usr/share/nginx/html目录。

数据卷的作用:
-
将容器与数据分离,解耦合,方便操作容器内数据,保证数据安全
数据卷的操作命令
数据卷操作:
docker volume create:创建数据卷
docker volume ls:查看所有数据卷
docker volume inspect:查看数据卷详细信息,包括关联的宿主机目录位置
docker volume rm:删除指定数据卷
docker volume prune:删除所有未使用的数据卷
挂载数据卷
创建容器时,可以通过 -v 参数来挂载一个数据卷到某个容器内目
docker run \
--name mynginx \
-v html:/root/html \
-p 80:80 \
-d \
nginx \
容器不仅仅可以挂载数据卷,也可以直接挂载到宿主机目录上 :
带数据卷模式:宿主机目录 --> 数据卷 ---> 容器内目录
直接挂载模式:宿主机目录 ---> 容器内目录
目录挂载与数据卷挂载的语法是类似的:
-v [宿主机目录]:[容器内目录]
-v [宿主机文件]:[容器内文件]

Dockerfile 自定义镜像
Dockerfile是一个文本格式的配置文件,用户可以使用Dockerfile快速创建自定义的镜像。
示例:
【1】编写镜像 #基础镜像 FROM centos #维护者 MAINTAINER psjj<psjj@163.com> #启动容器运行命令 CMD echo "hello Dockerfile" 【2】构建镜像 docker build -t 镜像名:版本 .注意: .代表当前目录去找Dockerfile
Dockerfile的13指令


注意
- 通过WORKDIR设置工作目录后,Dockerfile中其后的命令RUN、CMD、ENTRYPOINT、ADD、COPY等命令都会在该目录下执行。在使用docker run运行容器时,可以通过-w参数覆盖构建时所设置的工作目录。
- RUN指令创建的中间镜像会被缓存,并会在下次构建中使用。 如果不想使用这些缓存镜像,可以在构建时指定--no-cache参数。
- COPY功能类似ADD,但是是不会自动解压文件,也不能访问网络资源。
- CMD不同于RUN,CMD用于指定在容器启动时所要执行的命令,而RUN用于指定镜像构建时所要执行的命令。
- ENTRYPOINT与CMD非常类似,不同的是通过docker run执行的命令不会覆盖ENTRYPOINT,而docker run命令中指定的任何参数,都会被当做参数再次传递给ENTRYPOINT。Dockerfile 中只允许有一个ENTRYPOINT命令,多指定时会覆盖前面的设置,而只执行最后的ENTRYPOINT指令。
- 使用USER指定用户后,Dockerfile中其后的命令RUN、CMD、 ENTRYPOINT都将使用该用户。镜像构建完成后,通过 docker run 运行容器时,可以通过-u参数来覆盖所指定的用户。
Dockerfile综合案例
【1】编写镜像
# 基础镜像
FROM java:8
# 维护者
MAINTAINER psjj<psjj@163.com>
# copy tomcat包
ADD ./apache-tomcat-7.0.70.tar.gz /usr/local
# 设置工作目录
WORKDIR /usr/local
# 设置tomcat环境变量
ENV TOMCAT_HOME=/usr/local/apache-tomcat-7.0.70
ENV PATH=$PATH:$TOMCAT_HOME/bin
# 保留端口
EXPOSE 8080
# 启动容器运行命令
CMD startup.sh && tail -F catatlina.out【2】构建镜像
docker build -t mytomcat:v1
【3】运行容器
docker run --name tomcat1 -d -p 80:8080 mytomcat:v1
Docker 网络管理
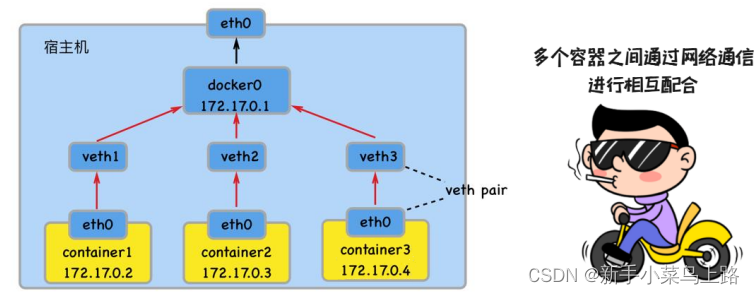
注意: 每启动一个docker容器, docker就会给容器分配一个ip,只要安装docker就会有一个docker0 网卡。
Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。
Docker容器互联
语法格式 : --link <name or id>:alias
name和id是源容器的name和id,alias是源容器在link下的别名。
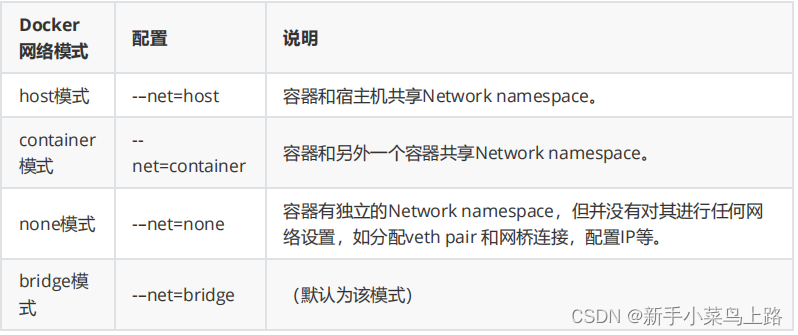
四种网络模式
自定义网路
1)基础命令
docker network --help
docker network connect 将容器连接到网络
docker network create 创建一个网络
docker network disconnect 断开容器的网络
docker network inspect 显示一个或多个网络的详细信息
docker network ls 列出网络
docker network prune 删除所有未使用的网络
docker network rm 删除一个或多个网络
2)创建局域网
docker network create --driver bridge --subnet 192.168.0.0/16 --gateway 192.168.0.1 mynet
3)容器连接新网络并查看容器网络情况
docker network connect 网络名 容器名
docker network inspect 网络名
4)指定网络模式
docker run创建Docker容器时,可以用 --net 选项指定容器的网络模式
5)启动容器时加入指令网络
docker run 创建Docker 容器时,可以用--network加入指定网络。
docker run --name t3 -p 8083:8080 -d --network mynet mytomcat:v1
Docker-Compose
Docker Compose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器!
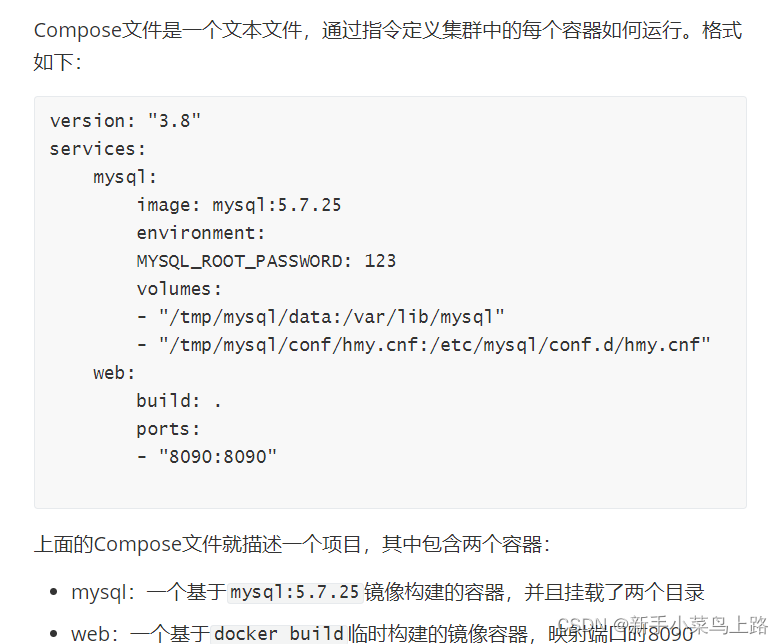
DockerCompose的详细语法参考官网:Overview | Docker DocsOverview | Docker Docs
安装 Docker-Compose
1)下载
curl -L https://github.com/docker/compose/releases/download/1.23.1/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
2)修改权限
# 修改权限
chmod +x /usr/local/bin/docker-compose
3)补全命令
# 补全命令
curl -L https://raw.githubusercontent.com/docker/compose/1.29.1/contrib/completion/bash/docker-compose > /etc/bash_completion.d/docker-compose
如果这里出现错误,需要修改hosts文件:
echo "199.232.68.133 raw.githubusercontent.com" >> /etc/hosts
docker-compose.yml 结构
docker-compose.yml文件分为三个主要部分:services、networks、volumes
services主要用来定义各个容器。
networks定义需要使用到的network.
volumes定义services使用到的volume.
| build | 使用当前目录下的Dockerfile进行构建: |
| image | 指定运行容器使用的镜像。以下格式都可以。
|
| container_name | 指定容器名。 |
| command | 覆盖容器启动后默认执行的命令(Dockerfile定义的CMD)。当Dockerfile定义了entrypoint的时候,docker-comose.yml定义的command会被覆盖。 |
| entrypoint | 可以覆盖Dockerfile中定义的entrypoint命令。 |
| ports | 将容器的端口80映射到宿主机的端口8080 ports: |
| volumes | 挂载一个目录或者一个已存在的数据卷容器, HOST:CONTAINER 格式定义共享的目录 HOST:CONTAINER:RO 定义容器只读的目录 volumes: |
| networks | 加入指定网络 networks: |
【1】什么是Docker,说说你理解的Docker,不要背八股文,说你自己的理解。
答:Docker是虚拟化容器技术,解决软件安装兼容问题,解决方案带环境安装软件,带的是残缺版软件需要的linux系统。Docker使用一般的步骤为
从仓库下载镜像或自定义镜像
根据镜像启动容器
关闭系统防火墙
应用程序连接容器。
【2】你用的Docker是什么版本。
答:Docker分为社区版和企业版,我用的社区版。
【3】你都用过哪些docker命令
答:我都用过镜像、容器、数据卷、网络等命令
镜像:
docker images
docker rmi
docker save
docker load
docker pull
容器
docker run --name 名字 -p 端口映射 -d后台启动 -v数据挂载 -e设置环境 --network 加入网路等
docker rm 删除容器
docker start 启动容器
docker stop 关闭容器
数据卷
docker volume create 创建
docker volume ls 查看列表
docker volume inspect 查看数据卷详情
docker volume rm 删除数据卷
网络
docker network create 创建网络
docker network ls 网络列表
docker network connect 网络 容器 连接网络
docker network inspect 网络 网络详情
【4】Docker容器网络管理的四种模型
答:docker网络管理四种模型:网络共享,网络容器、无网络、网络桥接。
网络共享:容器和主机共享ip。
网络容器:子容器之间共享ip,宿主机和容器桥接。
无网络:容器内没有虚拟网卡,无法连接容器。
桥接:容器之间用evth-pair技术进行桥接,所有容器都在一个虚拟局域网下,局域网和docker0是通过evth-pair技术连接。key:value 与 value:key的方式配对连接。
三、Zookeeper
分布式相关概念
分布式系统分为:
-
单机架构:一个项目一个服务器
-
集群架构:同一个项目由多个服务器构成集群共同处理相同业务。
-
分布式架构:将一个项目拆分成n个模块,每个模块都能独立运行,都是独立的系统,由这些独立系统相互调用构成完整的项目。
什么是分布式
分布式架构就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在分布式结构中每个子系统就被称为“服务”。这些子系统能够独立运行在web容器中,它们之间通过RPC方式通信。
分布式的优势:
系统之间的耦合降低,可以独立开发、独立部署、独立测试,系统与系统之间的边界非常明确,排错也变得相当容易,开发效率大大提升。系统更易于扩展。我们可以针对性地扩展某些服务。服务的复用性更高。
CAP 定理
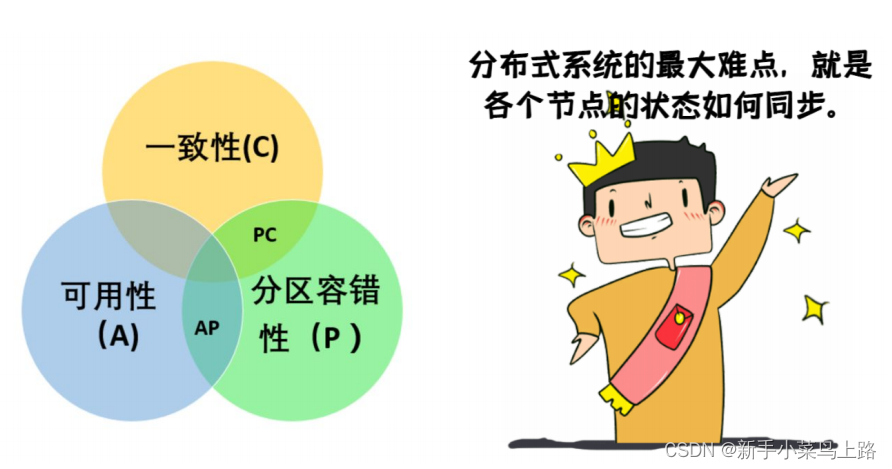
分布式系统的三个指标Consistency(一致性),Availability (可用性),Partition tolerance (分区容错性)。
这三个指标不可能同时做到。这个结论就叫做 CAP 定理。
分区容错性
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区。分区容错的意思是,区间通信可能失败。 分区容错无法避免,因此可以认为 CAP 的 P 总是成立。
一致性
写操作之后的读操作,必须返回该值。
举例:某条记录是 v0,用户向 G1 发起一个写操作,将其改为 v1。接下来,用户的读操作就会得到 v1。这就叫一致性。 为了让 G2 也变为 v1,就要在 G1 写操作的时候,让 G1 向 G2 发送一条消息,要求 G2 也改成 v1。
可用性
只要收到用户的请求,服务器就必须给出回应。
一致性和可用性的矛盾
如果保证 G2 的一致性,那么 G1 必须在写操作时,锁定 G2 的读操作和写操作。只有数据同步后,才能重新开放读写。锁定期间,G2 不能读写,没有可用性。
Zookeeper 概述
ZooKeeper是一个开放源代码的分布式协调服务。ZooKeeper的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
Zookeeper 应用场景
数据发布/订阅
数据发布/订阅的一个常见的场景是配置中心,发布者把数据发布到ZooKeeper 的一个或一系列的节点上,供订阅者进行数据订阅,达到动态获取数据的目的。
ZooKeeper 采用的是推拉结合的方式。
负载均衡
负载均衡是一种手段,用来把对某种资源的访问分摊给不同的设备,从而减轻单点的压力。
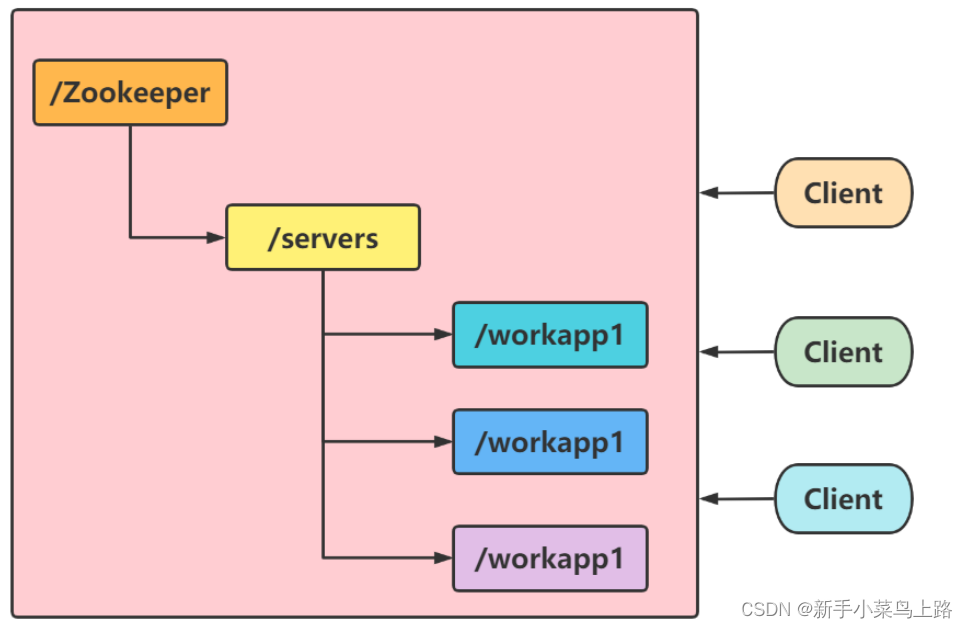
命名服务
命名服务就是提供名称的服务。ZooKeeper 的命名服务有两个应用方面。
-
提供类 JNDI 功能,可以把系统中各种服务的名称、地址以及目录信息存放在 ZooKeeper, 需要的时候去 ZooKeeper 中读取。
-
制作分布式的序列号生成器。
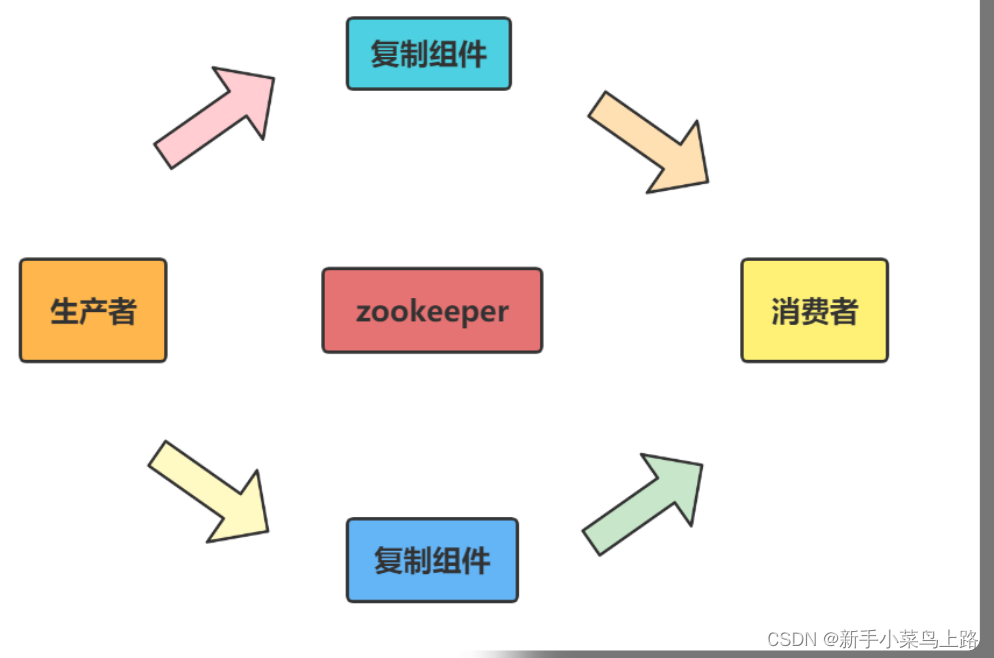
分布式协调/通知
分布式协调/通知服务是将不同的分布式组件有机结合起来的关键所在。对于一个在多台机器上部署运行的应用而言,通常需要一个协调者(Coordinator)来控制整个系统的运行流程。
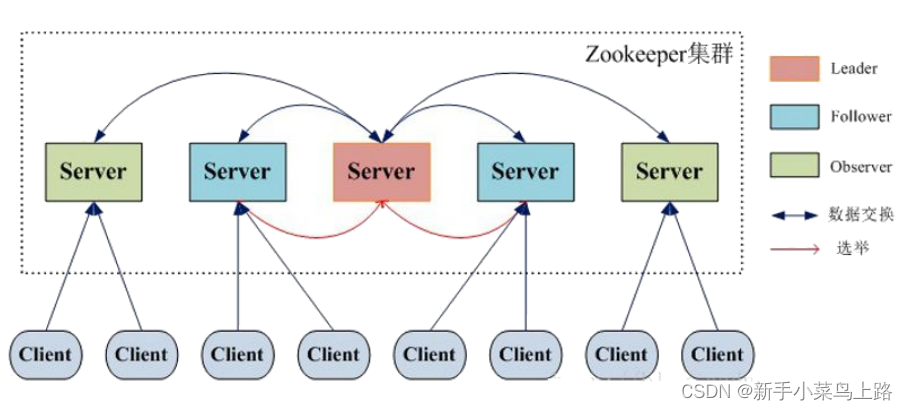
Zookeeper基本概念
集群角色
在分布式系统中,构成一个集群的每一台机器的都有自己的角色,最典型的集群模式Master/Slave模式(主备模式)。此模式中处理写操作的机器称为Master机器,所有通过异步复制方式获取最新数据,并提供读服务的机器称为Slave机器。
在ZooKeeper中,而是引入了Leader、Follower和 Observer三种角色。
数据节点
在ZooKeeper中节点分为两类:
机器节点:构成集群的机器。
数据节点:数据模型中的数据单元。
Watcher监听机制
ZooKeeper 允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是ZooKeeper实现分布式协调服务的重要特性。
ACL权限控制
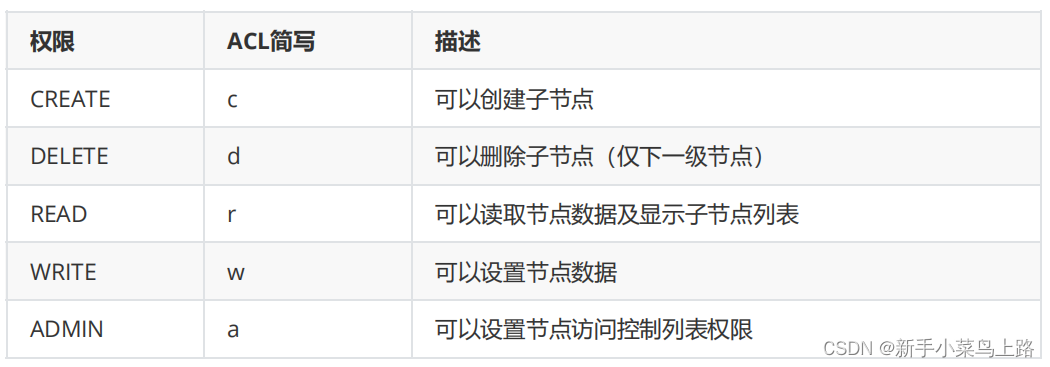
ZooKeeper 采用ACL (Access Control Lists)策略来进行权限控制。ZooKeeper定义了如下5种权限。
CREATE:创建子节点的权限
READ:获取节点数据和子节点列表的权限
WRITE:更新节点数据的权限
DELETE:删除子节点的权限
ADMIN:设置节点ACL的权限
Zookeeper 下载安装
Apache ZooKeeper 下载Zookeeper。
1)解压zookeeper
tar -xvf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local mv apache-zookeeper-3.7.0-bin zookeeper2)修改配置文件
进入zookeeper的安装目录的conf目录,修改zoo.cfg。
cp zoo_sample.cfg zoo.cfg # The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/zookeeper/zkdata dataLogDir=/usr/local/zookeeper/zklogs # the port at which the clients will connect clientPort=21813)创建数据持久化目录
mkdir /usr/local/zookeeper/zkdata mkdir /usr/local/zookeeper/zklogs4)安装jdk环境
5)启动zookeeper,并查看状态
./zkServer.sh start ./zkServer.sh status
Zookeeper 集群运行
1)准备环境
在三个服务器上准备好jdk和zookeeper软件(虚拟机之间复制命令: scp -r ./jdk1.8.0_144/ 192.168.184.131:$PWD )。
2)解压zookeeper
tar -xvf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local mv apache-zookeeper-3.7.0-bin zookeeper
3)修改配置文件
进入zookeeper的安装目录的conf目录,修改zoo.cfg
cp zoo_sample.cfg zoo.cfg # The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/zookeeper/zkdata dataLogDir=/usr/local/zookeeper/zklogs # the port at which the clients will connect clientPort=2181 #autopurge.purgeInterval=1 server.1=192.168.184.130:2888:3888 server.2=192.168.184.131:2888:3888 server.3=192.168.184.132:2888:3888
4)创建数据持久化目录
对3台节点,都创建zkdata目录 。
mkdir /usr/local/zookeeper/zkdata mkdir /usr/local/zookeeper/zklogs
5)在工作目录中生成myid文件
第一台机器上: echo 1 > /usr/local/zookeeper/zkdata/myid 第二台机器上: echo 2 > /usr/local/zookeeper/zkdata/myid 第三台机器上: echo 3 > /usr/local/zookeeper/zkdata/myid
6)启动集群
zookeeper没有提供自动批量启动脚本,需要手动一台一台地起zookeeper进程。
在每一台节点上,运行命令:./zkServer.sh start
注意:
启动后,用jps应该能看到一个进程:QuorumPeerMain。光有进程不代表zk已经正常服务,需要用命令检查状态: ./zkServer.sh status 能看到角色模式:为leader或 follower,即正常了。
Zookeeper 服务管理

1)配置环境变量
修改文件 vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/bin
生效环境变量
source /etc/profile
2)启动服务 zkServer.sh start
3)查看服务状态 zkServer.sh status
Zookeeper 基本操作
Zookeeper 的数据模型
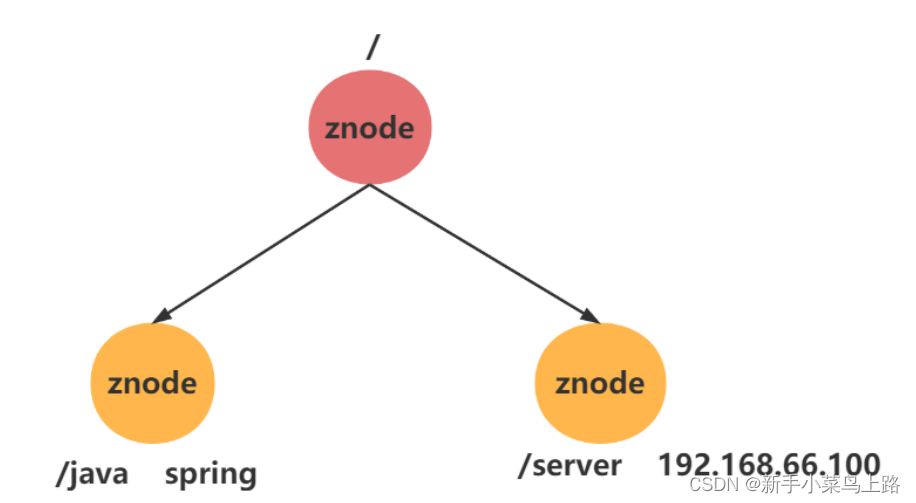
在Zookeeper中,可以说 Zookeeper中的所有存储的数据是由znode组成的,节点也称为 znode,并以 key/value 形式存储数据。
树:整体结构类似于 linux 文件系统的模式以树形结构存储。其中根路径以 / 开头。
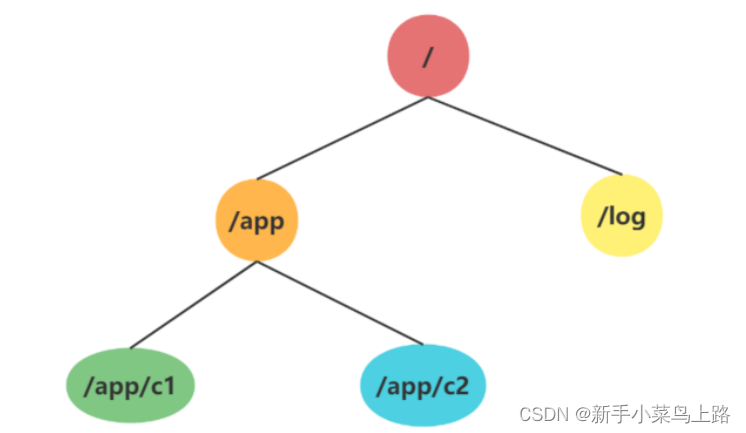
保存数据:以 key/value 形式存储数据。key就是znode的节点路径,比如 /java , /server。
Zookeeper 节点特性

持久节点:
数据节点被创建后,就会一直存于与zookeeper服务器上, 直到有删除操作来主动清除这个节点。
临时节点:
该节点数据不会一直存储在 ZooKeeper 服务器上。和持久节点不同的是,临时节点的生命周期和客户端会话绑定。如果客户端会话失效(不是连接断开 ),那么这个节点就会自动被清除掉。 另外,在临时节点下面不能创建子节点。
顺序节点:
每个父节点会为他的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序。

Zookeeper 节点操作命令
| create | create [-s] [-e] path data acl 参数: -s:顺序节点 -e:临时节点 默认情况下,不添加-s或者-e参数的,创建的是持久节点。 |
| ls | ls path [watch] 获取节点的名称 get path [watch] 获取节点中数据 |
| set | set path data [version] version参数用于指定本次更新操作是基于ZNode的哪一个数据版本进行的。 |
| delete | delete path [version] 如果节点包含子节点就报错。 |
Zookeeper 节点数据信息
示例:
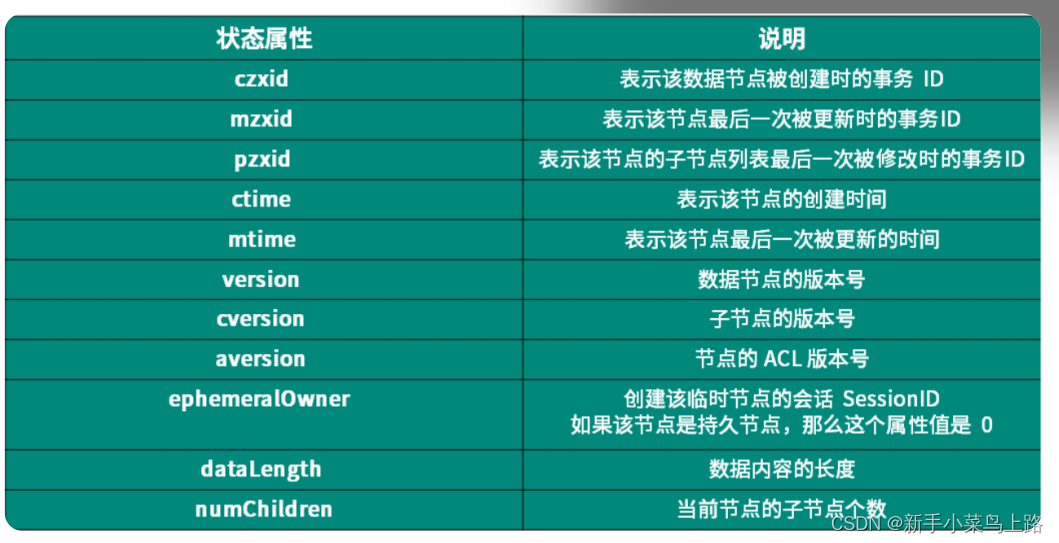
[zk: localhost:2181(CONNECTED) 12] stat /java cZxid = 0x100000002 ctime = Sun Dec 17 13:15:29 CST 2023 mZxid = 0x100000007 mtime = Sun Dec 17 15:51:25 CST 2023 pZxid = 0x100000008 cversion = 1 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 5 numChildren = 1
参数具体含义
Zookeeper Watch 监听机制(重要)
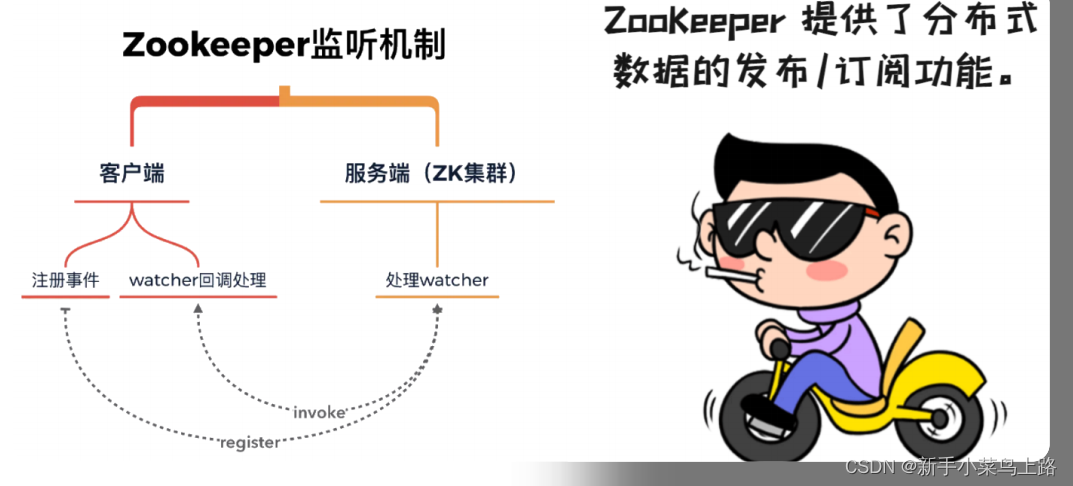
监听节点变化:ls -w path。
监听节点值的变化:get -w path。
Watcher 特性总结
一次性:
无论是服务端还是客户端,一旦一个 Watcher 被触发,ZooKeeper 都会将其从相应的存储中移除。这样的设计有效地减轻了服务端的压力。
客户端串行执行:
客户端 Watcher 回调的过程是一个串行同步的过程,保证了顺序。
轻量
WatcherEvent 是 ZooKeeper 整个 Watcher 通知机制的最小通知单元,这个数据结构中只包含:通知状态、事件类型和节点路径。
Zookeeper 权限控制 ACL
权限介绍
在ZooKeeper的实际使用中,往往是搭建一个共用的ZooKeeper集群,统一为若干个应用提供服务。在这种情况下,不同的应用之间不存在共享数据的使用场景,因此需要解决不同应用之间的权限问题。
ACL 权限控制:
权限模式(Schema)
授权对象(ID)
权限(Permission)
注意
ZooKeeper的权限控制是基于每个znode节点的,需要对每个节点设置权限。
每个znode支持设置多种权限控制方案和多个权限。
子节点不会继承父节点的权限,客户端无权访问某节点,但可能可以访问它的子节点。
语法结构:
setAcl /java ip:128.0.0.1:crwda
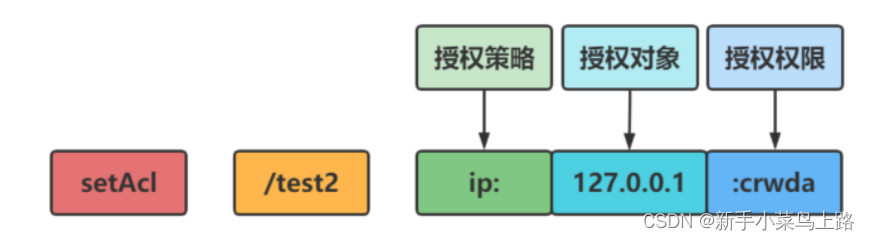
权限模式(Schema)

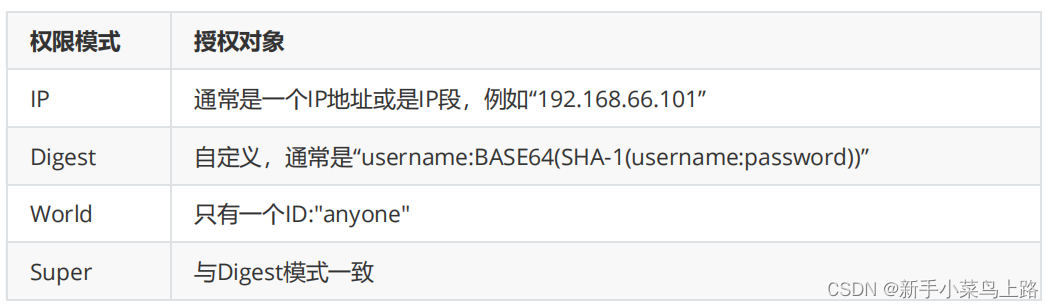
授权对象(ID)
授权对象ID是指,权限赋予的用户或者一个实体,例如:IP 地址或者机器。授权模式 schema 与 授权对象 ID 之间关系:
权限permission
权限相关命令
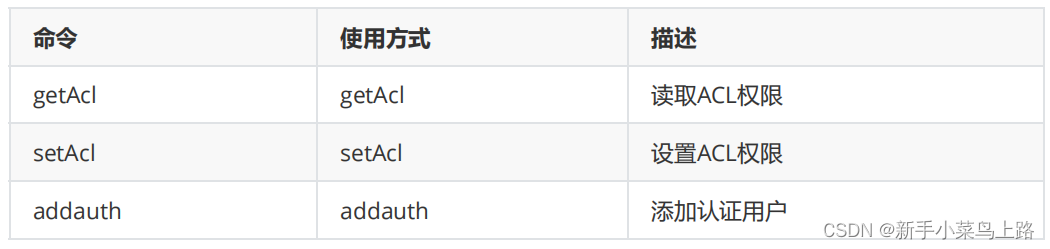
addauth digest <user>:<password>
Zookeeper Java客户端操作
原生API操作
1)引入依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.8</version>
</dependency>2) 示例代码
package top.psjj.zookeeperstudy;
import org.apache.zookeeper.*;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
/**
* @Auther: 胖叔讲java
* @Date: 2023/12/19 - 12 - 19 - 16:38
* @Decsription: top.psjj.zookeeperstudy
* @version: 1.0
*/
@SpringBootTest
public class ZookeeperCli {
@Test
public void test1() throws Exception{
//1.创建会话:ip:端口、超时时间毫秒,watcher监视器
ZooKeeper zooKeeper = new ZooKeeper("192.168.184.130:2181", 50000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println("正在监听");
}
});
System.out.println(zooKeeper.getState());
//2.创建连接,参数:节点名字、节点值、ACL策略、节点类型
/*String result = zooKeeper.create("/node1", "1".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println(result);*/
//3.删除节点
//zooKeeper.delete("/node1",-1);
//4.修改节点
zooKeeper.setData("/node1","111".getBytes(),-1);
//5.获取节点数据
byte[] data = zooKeeper.getData("/node1", null, null);
System.out.println(new String(data));
}
}zkclient 客户端操作
zkclient是Github上一个开源的Zookeeper客户端,在Zookeeper原生 API接口之上进行了包装,是一个更加易用的Zookeeper客户端。同时Zkclient在内部实现了诸如Session超时重连,Watcher反复注册等功能,从而提高开发效率。、
1)添加依赖
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.10</version>
</dependency>2)示例
public class ZkClientTest {
private ZkClient zk;
@BeforeEach
public void before(){
//创建会话
zk = new ZkClient("192.168.184.130");
System.out.println(zk);
}
@Test //获取所有子节点
public void test1(){
List<String> children = zk.getChildren("/");
System.out.println(children);
}
@Test //创建节点
public void test2(){
String node = zk.create("/node2", "2", CreateMode.PERSISTENT);
System.out.println(node);
}
@Test //修改节点
public void test3(){
zk.writeData("/node2","22");
}
@Test //获取数据
public void test4(){
Object result = zk.readData("/node2");
System.out.println(result);
}
@Test //删除节点
public void test5(){
boolean delete = zk.delete("/node2");
System.out.println(delete);
}
@Test //注册子节点事件
public void test6() throws Exception{
zk.subscribeChildChanges("/node1", new IZkChildListener() {
@Override
public void handleChildChange(String s, List<String> list) throws Exception {
System.out.println("子节点变了");
System.out.println(list);
}
});
Thread.sleep(500000);
}
@Test //注册节点值变化事件
public void test7() throws Exception{
zk.subscribeDataChanges("/node1", new IZkDataListener() {
@Override
public void handleDataChange(String s, Object o) throws Exception {
System.out.println(s);
System.out.println(o);
System.out.println("数据改变了");
}
@Override
public void handleDataDeleted(String s) throws Exception {
System.out.println("数据删除了");
}
});
Thread.sleep(50000000);
}
}Apache Curator 客户端操作
Curator是 Netflix公司开源的一套ZooKeeper客户端框架。和ZkClient一样,Curator解决了很多ZooKeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等,目前已经成为了Apache的顶级项目, 是全世界范围内使用最广泛的ZooKeeper客户端之一。
Curator包
curator-framework:对zookeeper的底层api的一些封装。
curator-client:提供一些客户端的操作,例如重试策略等。
curator-recipes:封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等。
maven依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.2.0</version>
</dependency>示例:
public class CuratorTest {
public static void main(String[] args) throws Exception {
// 1. 创建会话
String connStr = "192.168.184.130:2181,192.168.184.131:2181,192.168.184.132:2181";
CuratorFramework cur = CuratorFrameworkFactory
.builder()
.connectString(connStr)
.connectionTimeoutMs(5000)
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
// 连接
cur.start();
//2. 创建节点
// cur.create().withMode(CreateMode.PERSISTENT).forPath("/node3","3".getBytes());
//3. 获取数据
// byte[] bytes = cur.getData().forPath("/node3");
// System.out.println(new String(bytes));
//4. 删除一个节点
// cur.delete().forPath("/node3");
// 5. 删除节点但是这个节点里面有子节点 递归删除
// cur.delete().deletingChildrenIfNeeded().forPath("/node3");
// 6. 修改节点
// cur.setData().forPath("/node3","333".getBytes());
// 7. 获取某个节点的所有子节点
// List<String> strings = cur.getChildren().forPath("/node3");
// for (String string : strings) {
// System.out.println(string);
// }
// 8. 监听机制
NodeCache nodeCache = new NodeCache(cur, "/node3");
nodeCache.getListenable().addListener(()->{
System.out.println("被修改了。。。。。。。");
});
nodeCache.start();
Thread.sleep(Long.MAX_VALUE);
}
}Zookeeper 选举机制
核心选取原则
Zookeeper集群中只有超过半数以上的服务器启动,集群才能正常工作;
在集群正常工作之前,myid小的服务器给myid大的服务器投票,直到集群正常工作,选出Leader;
半数机制;
选取机制流程
服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息, 服务器1的状态一直属于Looking(选举状态)。
服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
服务器5启动,后面的逻辑同服务器4成为小弟。
选择机制中的概念
Serverid: 服务器ID,编号越大在选择算法中的权重越大。
Zxid: 数据ID,值越大说明数据越新,在选举算法中数据越新权重越大。
分布式框架Dubbo
Apache Dubbo是一款高性能、轻量级的开源服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。
Dubbo 能做什么
透明化的远程方法调用,就像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入。
软负载均衡及容错机制,可在内网替代F5等硬件负载均衡器,降低成本,减少单点。
服务自动注册与发现,不再需要写死服务提供方地址,注册中心基于接口名查询服务提供者的IP地址,并且能够平滑添加或删除服务提供者。
采用全Spring配置方式,透明化接入应用,对应用没有任何API侵入,只需用Spring加载Dubbo的配置即可。















 58
58











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









