







目录
1. 引言与背景
在机器学习领域,数据标注是一项耗时且昂贵的工作,尤其是在大规模数据集和高维特征空间中。半监督学习旨在利用有限的标注样本与大量未标注样本共同进行模型训练,以降低对标注数据的依赖。Label Propagation(标签传播)算法作为半监督学习的一种重要方法,巧妙地利用图论中的信息扩散原理,将标注信息从已知标签节点传播至未标注节点,实现对未标注数据的分类。本文将围绕Label Propagation算法,详细介绍其背景、理论基础、算法原理、实现细节、优缺点分析、实际应用案例、与其他算法的对比,并展望其未来发展方向。
2. 图论与拉普拉斯矩阵
Label Propagation算法的理论基础是图论中的拉普拉斯矩阵(Laplacian Matrix)。给定一个带权重的无向图G=(V,E),其中V代表节点集合,E代表边集合,拉普拉斯矩阵L定义为:
其中,D是对角矩阵,其对角线元素为节点的度(即与该节点相连的边的权重之和),W为图的邻接矩阵,其元素表示节点i与节点j之间的边的权重。拉普拉斯矩阵具有良好的性质,如对称、半正定等,是图谱理论中的核心概念。
3. Label Propagation算法原理
Label Propagation算法的核心思想是将数据集视为一个完全图,其中节点代表数据点,边的权重反映数据点间的相似度。已标注节点初始携带其真实标签,算法通过迭代过程,使未标注节点的标签逐渐趋近于其邻居节点标签的加权平均,直至标签分布稳定。具体步骤如下:
初始化:构建完全图,赋予已标注节点其真实标签,未标注节点初始标签可设为随机值或全局平均标签。
迭代传播:
-
计算节点i的当前标签分布向量
,其中
表示节点i被赋予标签k的概率。
-
更新节点i的标签分布向量为邻居节点标签分布的加权平均:
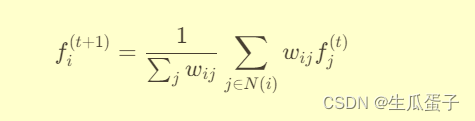
其中,N(i)表示节点i的邻居集合,
为节点i与节点j之间的边权重。
-
重复步骤1和2,直到标签分布收敛(如标签分布的变动小于某个阈值或达到最大迭代次数)。
最终分类:对于每个未标注节点,选取其最终标签分布向量中概率最大的标签作为其预测标签。
4. Label Propagation算法实现
实现Label Propagation算法通常包括以下关键步骤:
数据预处理:计算数据点之间的相似度(如余弦相似度、欧氏距离等),构建完全图并赋予权重。
初始化标签分布:为已标注节点分配真实标签,为未标注节点分配初始标签分布。
迭代传播:使用上述算法原理中的迭代公式更新节点标签分布,直到满足停止条件。
预测标签:对每个未标注节点,根据其最终标签分布向量选择最可能的标签。
以下是一个使用Python实现Label Propagation算法的示例,以Jupyter Notebook的形式展示,包含详细的代码和解释。假设已经有一个数据集,其中包含特征矩阵X和对应的标签Y(部分标注),我们将使用scikit-learn库中的LabelPropagation类来实现该算法。
# 导入所需库
import numpy as np
from sklearn import datasets
from sklearn.semi_supervised import LabelPropagation
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 1. 加载或生成数据集
# 以sklearn内置的鸢尾花数据集为例
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 假设只有部分数据被标注,这里模拟一个简单的场景:前50个样本有标签,其余无标签
y_partially_labeled = np.copy(y)
y_partially_labeled[50:] = -1 # 将后50个样本的标签设为-1,表示未标注
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_partially_labeled, test_size=0.3, random_state=42)
# 3. 初始化LabelPropagation模型
lp = LabelPropagation(kernel='rbf', alpha=0.8) # 使用RBF核,设置alpha参数
# 4. 拟合模型(训练)
lp.fit(X_train, y_train)
# 5. 预测测试集标签
y_pred = lp.predict(X_test)
# 6. 评估模型性能
print(classification_report(y_test[:50], y_pred[:50])) # 只评估有标签的测试集样本
# 7. 输出未标注样本的预测标签
print("Predicted labels for unlabeled samples:")
print(y_pred[50:])代码讲解:
-
导入库:我们使用
numpy处理数组和矩阵操作,sklearn.datasets加载数据集,sklearn.semi_supervised中的LabelPropagation实现标签传播算法,train_test_split划分训练集和测试集,classification_report评估模型性能。 -
加载或生成数据集:这里以sklearn内置的鸢尾花数据集为例,加载后得到特征矩阵X和标签向量y。为了模拟部分标注数据集,我们将y的后50个样本标签设为-1,表示未标注。
-
划分训练集和测试集:使用
train_test_split将数据集划分为训练集和测试集,通常比例为7:3或8:2。 -
初始化LabelPropagation模型:创建
LabelPropagation对象,设置核函数为RBF(径向基函数),alpha参数控制标签传播的平滑程度。alpha越大,模型越倾向于保留原始标签;反之,alpha越小,模型越倾向于将标签传播至相似样本。 -
拟合模型:使用训练集数据
X_train和部分标注的标签y_train调用fit方法训练模型。 -
预测测试集标签:使用训练好的模型对测试集
X_test进行预测,得到预测标签y_pred。 -
评估模型性能:由于只有测试集的前50个样本是有标签的,我们只对这部分样本进行评估,使用
classification_report输出各项性能指标(如精确率、召回率、F1分数等)。 -
输出未标注样本的预测标签:最后,我们打印出测试集中未标注样本的预测标签,这些标签是通过标签传播算法从有标签样本传播得到的。
以上代码实现了Label Propagation算法在部分标注数据集上的训练、预测和评估过程。实际应用中,需要根据自己的数据集和任务需求调整数据预处理、模型参数和评估方式。
5. 优缺点分析
优点:
-
利用数据内在结构:通过构建完全图并利用节点间的相似度传播标签,Label Propagation能有效利用数据的内在结构和分布特性。
-
无需复杂的参数调整:算法本身没有太多可调参数,易于实现和应用。
-
适合大规模数据集:由于仅需计算节点间的相似度和标签分布的迭代更新,Label Propagation在处理大规模数据集时具有较好的效率。
缺点:
-
对初始标签敏感:算法的最终结果对未标注节点的初始标签分布有一定依赖,不同的初始化方式可能导致不同的分类结果。
-
容易陷入局部最优:迭代过程中标签分布可能过早收敛于局部最优解,导致分类性能受限。
-
对噪声和异常值敏感:如果相似度计算或图构建过程中包含大量噪声或异常值,可能会影响标签传播的效果。
6. 案例应用
图像分类:在大规模图像数据集中,Label Propagation可用于利用少量标注样本对剩余大量未标注图像进行分类。
社交网络分析:在社交网络中,Label Propagation可用于用户兴趣标签传播、社区发现等任务,通过已标注用户的标签信息推断未标注用户的兴趣或所属社区。
生物信息学:在基因表达数据或蛋白质相互作用网络中,Label Propagation可用于基因功能注释、疾病亚型识别等任务,通过已知功能基因的标签信息推断未标注基因的功能或患者的疾病亚型。
7. 对比与其他算法
与SVM对比:SVM是一种监督学习算法,需要大量标注样本进行训练。Label Propagation利用未标注样本信息,对少量标注样本进行有效扩展,适用于标注数据稀缺的场景。
与Deep Learning对比:深度学习模型如CNN、RNN等在有足够标注数据时能学习复杂特征表示,但对标注数据需求大。Label Propagation则利用数据内在结构,适用于标注数据不足的情况。
与Transductive SVM对比:Transductive SVM也是一种半监督学习算法,它在最大化间隔的同时考虑了未标注样本的影响。Label Propagation通过迭代传播标签信息,侧重于利用数据相似性进行标签传播。
8. 结论与展望
Label Propagation算法作为一种基于图论的半监督学习方法,有效地利用了数据的内在结构和未标注样本信息,降低了对标注数据的依赖。尽管存在对初始标签敏感、易陷入局部最优等局限性,但在图像分类、社交网络分析、生物信息学等领域展现了良好的应用前景。未来的研究方向可能包括:探索更稳健的标签初始化策略、设计抗噪声和异常值的相似度计算方法、结合深度学习模型提升模型表示能力等。随着半监督学习理论和技术的不断发展,Label Propagation及其变种算法将在更大范围内推动机器学习在标注数据有限情况下的应用。














 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









