






Oslab1 LLM的部署
一、模型部署
1.1下载模型
from modelscope.hub.file_download import model_file_download
model_dir = model_file_download(model_id='qwen/Qwen1.5-0.5B- ChatGGUF',file_path='qwen1_5-0_5b-chatq5_k_m.gguf',revision='master',cache_dir='path/to/local/dir')
注意:将’path/to/local/dir’中,path前的地址补全
下载成功截图:
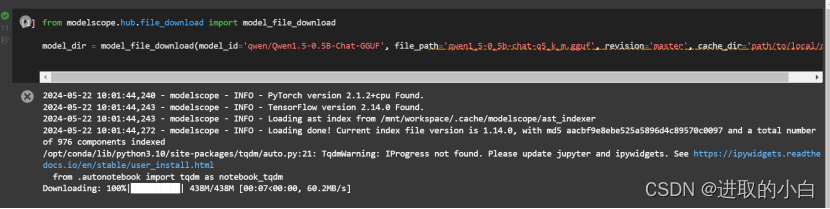
1.2 下载llama.cpp
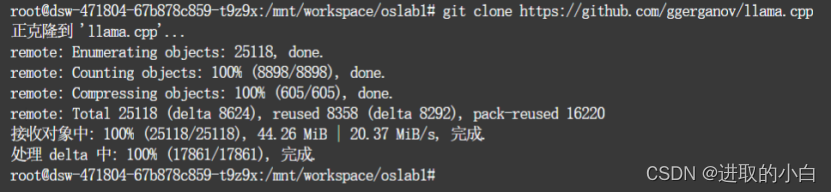
使⽤git命令克隆llama.cpp项⽬
git clone https://github.com/ggerganov/llama.cpp
编译llama.cpp项⽬
cd llama.cpp
make -j
1.3加载模型并运行
在llama.cpp⽬录中执⾏命令。
./main -m /path/to/local/dir/qwen/Qwen1.5-0.5B-Chat-GGUF/qwen1_5-0_5b-chatq5_k_m.gguf -n 512 --color -i -cml
执行截图: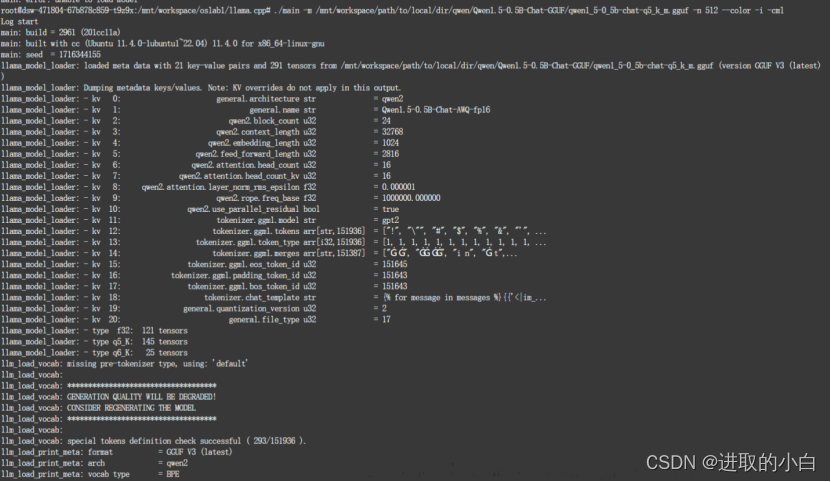
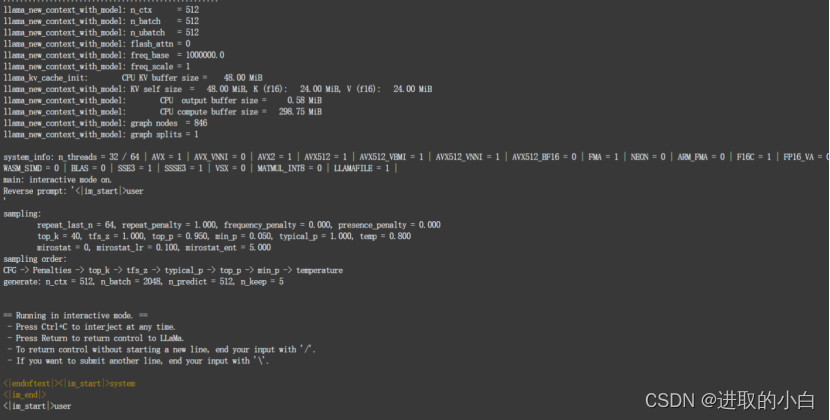
1.4 向LLM模型提问
二、基于OpenVINO的模型量化实践
###2.1 (1)创建⽬录qwen-ov
具体依赖的requirements.txt, 参⻅ https://github.com/OpenVINO-dev-contest/Qwen2.openvino

创建Python虚拟环境:
python -m venv qwenVenv
source qwenVenv/bin/activate

安装依赖的包:
pip install wheel setuptools
pip install -r requirements.txt

2.2 下载模型
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download --local-dir-use-symlinks False Qwen/Qwen1.5-0.5B-Chat --
local-dir {your_path}/Qwen1.5-0.5B-Chat
注意:将{your_path}替换为本地地址
2.3 转换模型
python3 convert.py --model_id Qwen/Qwen1.5-0.5B-Chat --precision int4 --output {your_path}/Qwen1.5-
0.5B-Chat-ov
注意:将{your_path}替换为本地地址
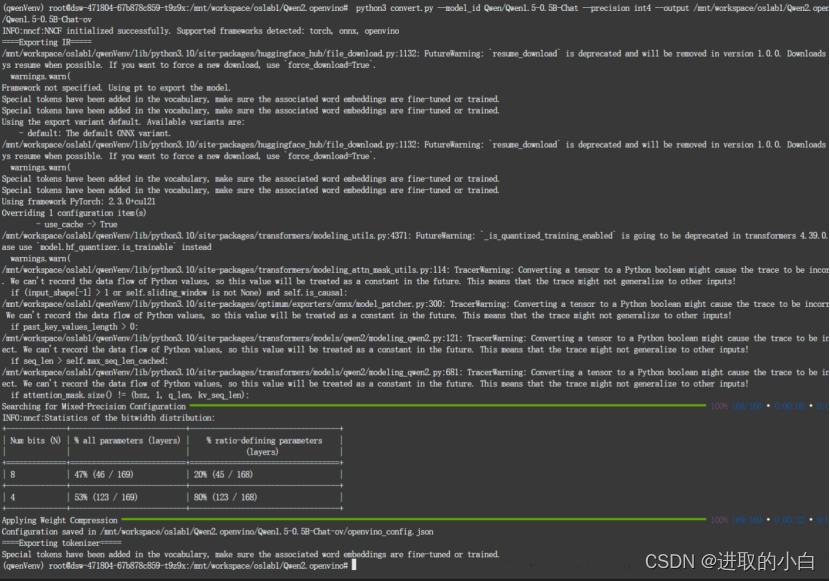
2.4 加载模型并执行
python3 chat.py --model_path {your_path}/Qwen1.5-0.5B-Chat-ov --max_sequence_length 4096 --device CPU
注意:将{your_path}替换为本地地址
















 1901
1901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









