









【力扣】2003. 每棵子树内缺失的最小基因值
1. 题目介绍
有一棵根节点为 0 的 家族树 ,总共包含 n 个节点,节点编号为 0 到 n - 1 。
- 给你一个下标从 0 开始的整数数组 parents ,其中 parents[i] 是节点 i 的父节点。由于节点 0 是 根 ,所以 parents[0] == -1 。
- 给你一个下标从 0 开始的整数数组 nums ,其中 nums[i] 是节点 i 的基因值,且基因值 互不相同 。总共有 105 个基因值,每个基因值都用 闭区间 [1, 10^5] 中的一个整数表示。
请你返回一个数组 ans ,长度为 n ,其中 ans[i] 是以节点 i 为根的子树内 缺失 的 最小 基因值。
- 节点 x 为根的 子树 包含节点 x 和它所有的 后代 节点。
示例:
- 1
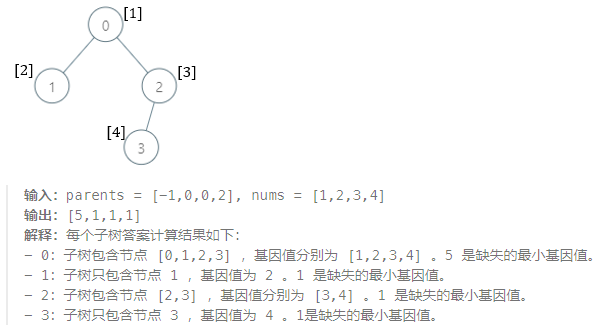
- 2
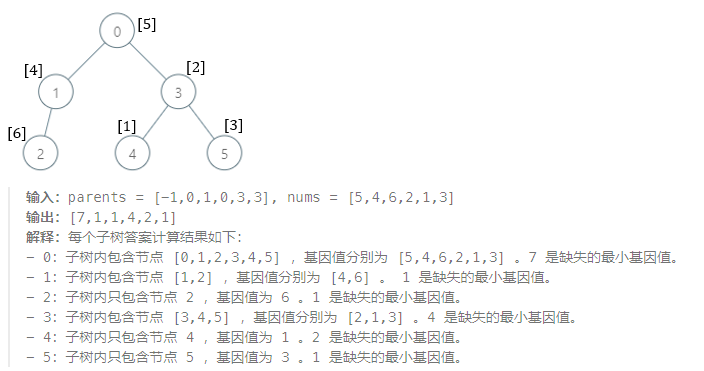
- 3

提示:

2. 思路
-
方法一:深度优先搜索 + 启发式合并
- 为了优化时间复杂度,基于启发式合并的原理(参考 OIWiki 树上启发式合并),在合并子节点基因值集合时,需要将小集合合并到大集合。
- 时间复杂度:O(nlogn),其中 n 是树的节点数目。基于启发式合并的基因值集合合并需要 O(nlogn)。
- 空间复杂度:O(nlogn)。
-
方法二:深度优先搜索
- 根据题意,所有基因值互不相同,因此最多只有一个基因值为 1 的节点。
- 首先,如果不存在基因值为 1 的节点,那么 1 就是以任一节点为根的子树缺失的最小基因值。
- 如果存在基因值为 1 的节点,那么可以把所有节点分成两种类型:
- 以该节点为根的子树不包含基因值为 1 的节点;
- 以该节点为根的子树包含基因值为 1 的节点。
- 对于第一种类型,类似地,1 就是以任一节点为根的子树缺失的最小基因值。
- 对于第二种类型,这类节点是基因值为 1 的节点的祖先节点(充分必要条件)。
- 我们可以先找到基因值为 1 的节点,然后可以通过 parents 数组依次遍历它的祖先节点(类似于遍历链表)。在遍历过程中,我们对节点 node 执行一次深度优先搜索(使用 visited 来记录已经访问过的节点,避免重复搜索),将访问过的节点的基因值加入到集合 geneSet 中,然后不断枚举基因值(类似于方法一,枚举值为上一次枚举的缺失的最小基因值),直到找到节点 node 为根的子树缺失的最小基因值。
- 时间复杂度:O(n),
- 空间复杂度:O(n)。
3. 解题代码
class Solution:
def smallestMissingValueSubtree(self, parents: List[int], nums: List[int]) -> List[int]:
n = len(parents)
childs = [[] for _ in range(n)]
for i in range(1, n):
childs[parents[i]].append(i)
res = [1] * n
def dfs(node):
geneSet = {nums[node]} # 当前节点基因
for child in childs[node]:
childGeneSet, y = dfs(child)
res[node] = max(res[node], y)
if len(childGeneSet) > len(geneSet):
geneSet, childGeneSet = childGeneSet, geneSet
geneSet.update(childGeneSet)
while res[node] in geneSet: # 从1开始搜索,如果存在一直累加,直到不存在为止
res[node] += 1
return geneSet, res[node]
dfs(0)
return res
class Solution:
def smallestMissingValueSubtree(self, parents: List[int], nums: List[int]) -> List[int]:
n = len(parents)
children = [[] for _ in range(n)]
for i in range(1, n):
children[parents[i]].append(i)
geneSet = set()
visited = [False] * n
def dfs(node):
if visited[node]:
return
visited[node] = True
geneSet.add(nums[node])
for child in children[node]:
dfs(child)
node = nums.index(1) if 1 in nums else -1
res, iNode = [1] * n, 1
while node != -1:
dfs(node)
while iNode in geneSet:
iNode += 1
res[node], node = iNode, parents[node]
return res
4. Danger
力扣(LeetCode)是领扣网络旗下专注于程序员技术成长和企业技术人才服务的品牌。源自美国硅谷,力扣为全球程序员提供了专业的IT技术职业化提升平台,有效帮助程序员实现快速进步和长期成长。此外,力扣(LeetCode)致力于解决程序员技术评估、培训、职业匹配的痛点,逐步引领互联网技术求职和招聘迈向专业化。
- 据了解到的情况,Easy题和Medium 题在面试中比较常见,通常会以手写代码之类的形式出现,您需要对问题进行分析并给出解答,并于面试官进行交流沟通,有时还会被要求分析时间复杂度8与空间复杂度°,面试官会通过您对题目的分析解答,了解您对常用算法的熟悉程度和您的程序实现功底。
- 而在一些对算法和程序实现功底要求较高的岗位,Hard 题也是很受到面试官的青睐,如果您在面试中成功Bug-Free出一道Hard题,我们相信您一定会给面试官留下很深刻的印象,并极大增加拿到Offer的概率,据相关人士统计,如果您在面试成功解出一道Hard题,拿不到Offer的概率无限接近于0。
- 所以,力扣中Easy和Medium相当于面试中的常规题,而Hard 则相当于面试中较难的题,解出—道Hard题,Offer可以说是囊中之物。
参考
【1】https://leetcode.cn/problems/smallest-missing-genetic-value-in-each-subtree/?envType=daily-question&envId=2023-10-31

















 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











