









【深度学习】计算图像数据集的均值和标准差(mean、std)用于 transform 标准化
文章目录
1. 介绍
相信大家对每一个图像数据集预处理时都免不了一个normalize的步骤,在使用pytorch中torchvision.transoforms.Normalize()这个方法很好的帮助我们进行标准化的处理。可是他需要图像各个通道的均值以及标准差的参数,那我们要如何求呢?
- ImageFolder,需要有特定格式
- 自己实现,无需特定格式
2. 方法
2.1 ImageFolder,需要有特定格式
这时候要求我们传参为父目录,下面必须得有子目录。
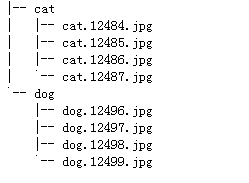
- 比如数据集一共包括两个类别:cat、dog,每个类别包括四张图片。所有的图片按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名。保存如下,dataset下有两个目录如下:
import torch
from torchvision.datasets import ImageFolder
def getStat(train_data):
'''
Compute mean and variance for training data
:param train_data: 自定义类Dataset(或ImageFolder即可)
:return: (mean, std)
'''
print('Compute mean and variance for training data.')
print(len(train_data))
train_loader = torch.utils.data.DataLoader(
train_data, batch_size=1, shuffle=False, num_workers=0,
pin_memory=True)
mean = torch.zeros(3)
std = torch.zeros(3)
for X, _ in train_loader:
for d in range(3):
mean[d] += X[:, d, :, :].mean()
std[d] += X[:, d, :, :].std()
mean.div_(len(train_data))
std.div_(len(train_data))
return list(mean.numpy()), list(std.numpy())
if __name__ == '__main__':
train_dataset = ImageFolder(root='dataset', transform=None)
print(getStat(train_dataset))
2.2 自己实现,无需特定格式
直接传入想要求的数据集目录即可,
import os
from PIL import Image
import numpy as np
import tqdm
def main(path):
# 数据集通道数
img_channels = 3
img_names = os.listdir(path)
cumulative_mean = np.zeros(img_channels)
cumulative_std = np.zeros(img_channels)
for img_name in tqdm.tqdm(img_names, total=len(img_names)):
img_path = os.path.join(path, img_name)
img = np.array(Image.open(img_path)) / 255.
# 对每个维度进行统计,Image.open打开的是HWC格式,最后一维是通道数
for d in range(3):
cumulative_mean[d] += img[:, :, d].mean()
cumulative_std[d] += img[:, :, d].std()
mean = cumulative_mean / len(img_names)
std = cumulative_std / len(img_names)
print(f"mean: {mean}")
print(f"std: {std}")
if __name__ == '__main__':
main("dataset/cat")
3. ImageFolder解析
ImageFolder是一个通用的数据加载器,数据集应当按照指定的格式进行存储。
3.1 数据集构造格式
比如数据集一共包括两个类别:cat、dog,每个类别包括四张图片。所有的图片按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名。dataset下有两个目录如下:
3.2 使用方法
from torchvision.datasets import ImageFolder
dataset=ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
3.2.1 参数
- root:在root指定的路径下寻找图片,比如,
import torchvision.datasets
dataset = ImageFolder('./dataset')
- transform:对PIL Image进行的转换操作,transform的输入是使用loader读取图片的返回对象,比如,
import torchvision.datasets
transform = transforms.Compose([
transforms.Grayscale(),
transforms.Resize([28, 28]),
transforms.ToTensor(),
transforms.Normalize(mean=(0,0,0),std=(1,1,1))
])
dataset = ImageFolder('./dataset',transform=transform)
- target_transform:对label的转换。
3.2.2 成员变量
可以通过成员变量查看ImageFolder返回的内容。
- classes:根据分的文件夹的名字来确定的类别,如[‘cat’, ‘dog’]。
- class_to_idx:按顺序为这些类别定义索引为0,1…,如{‘cat’: 0, ‘dog’: 1}。
- imgs:返回从所有文件夹中得到的图片的路径以及其类别,一个列表,列表中的每个元素都是一个(img-path, class_index)的元组,如
- [(‘./dataset/cat/cat.12484.jpg’, 0), (‘./dataset/cat/cat.12487.jpg’, 0), (‘./dataset/dog/dog.12498.jpg’, 1), (‘./dataset/dog/dog.12499.jpg’, 1)]
3.2.3 ImageFolder返回的对象
如果不进行transform,返回PIL Image对象,进行transform,返回tensor。
- ImageFolder的返回值,
- 第一维代表的是第几张图片(所有类别的图片顺序排列),如dataset[0]代表第0张图片,即(‘./data/cat/cat.12484.jpg’, 0)。
- 第二维只有0和1两个值,0返回图片数据,1返回label。

















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











