






一、《Learning Anatomically Consistent Embedding for Chest Radiography》
1、Abstract:
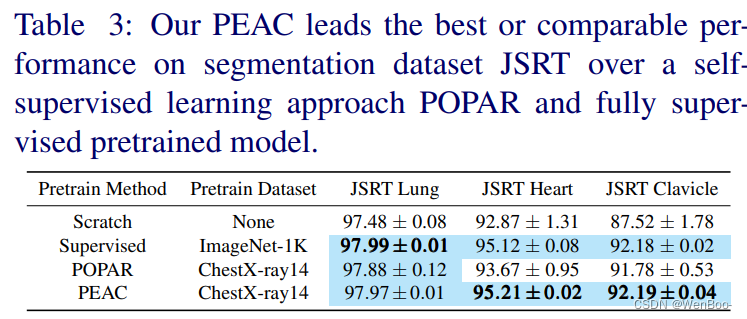
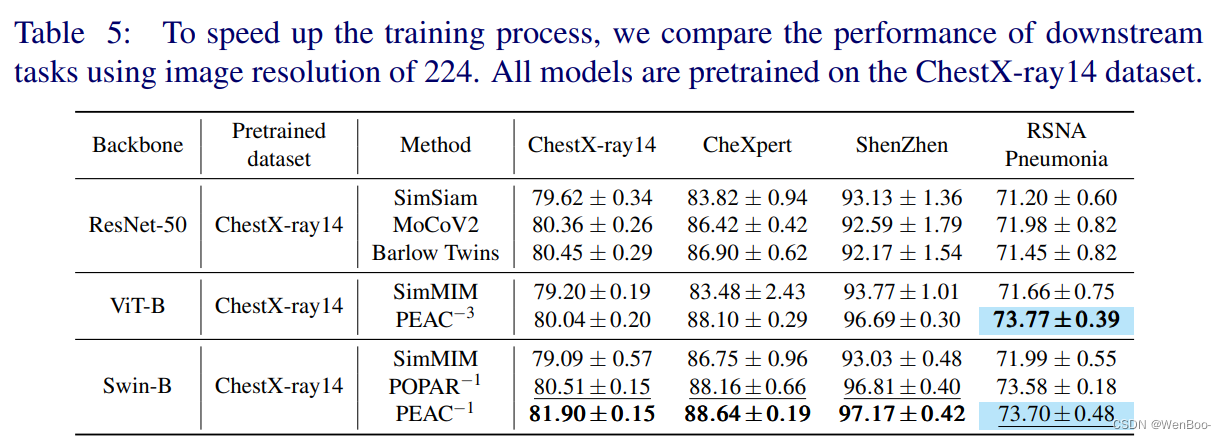
自监督学习(SSL)方法最近在从未注释的图像中学习视觉表示方面取得了实质性的成功。与摄影图像相比,使用相同成像协议获取的医学图像在解剖学上表现出高度一致性。为了利用这种解剖结构的一致性,本文介绍了一种新的SSL方法,称为PEAC(补丁嵌入解剖结构的一致性),用于医学图像分析。具体来说,在本文中,我们提出通过稳定的基于网格的匹配来学习全局和局部优化,将预训练的PEAC模型转移到不同的下游任务中,并广泛地证明了(1)PEAC比现有的最先进的完全/自监督方法实现了更好的性能,以及(2)PEAC捕获跨同一患者的视图以及跨不同性别、体重和健康状态的患者的解剖结构一致性,这增强了我们用于医学图像分析的方法的可解释性。
2、Conclusion:
我们提出了一种新颖的自我监督学习方法,称为PEAC,旨在增强医学图像中解剖结构视觉表征学习的一致性。PEAC中的关键技术是我们新颖但可靠的基于网格的匹配,保证了解剖学中的全局和局部一致性。通过广泛的实验,我们展示了我们的方案的有效性。通过准确识别不同性别和体重的患者以及不同种族和文化的患者之间的每个共同区域,对于同一患者的图像,PEAC在医学图像分析中显示出增强人工智能的潜力。
3、Result:

二、《Continual Self-supervised Learning: Towards Universal Multi-modal Medical Data Representation Learning》
1、Abstract:
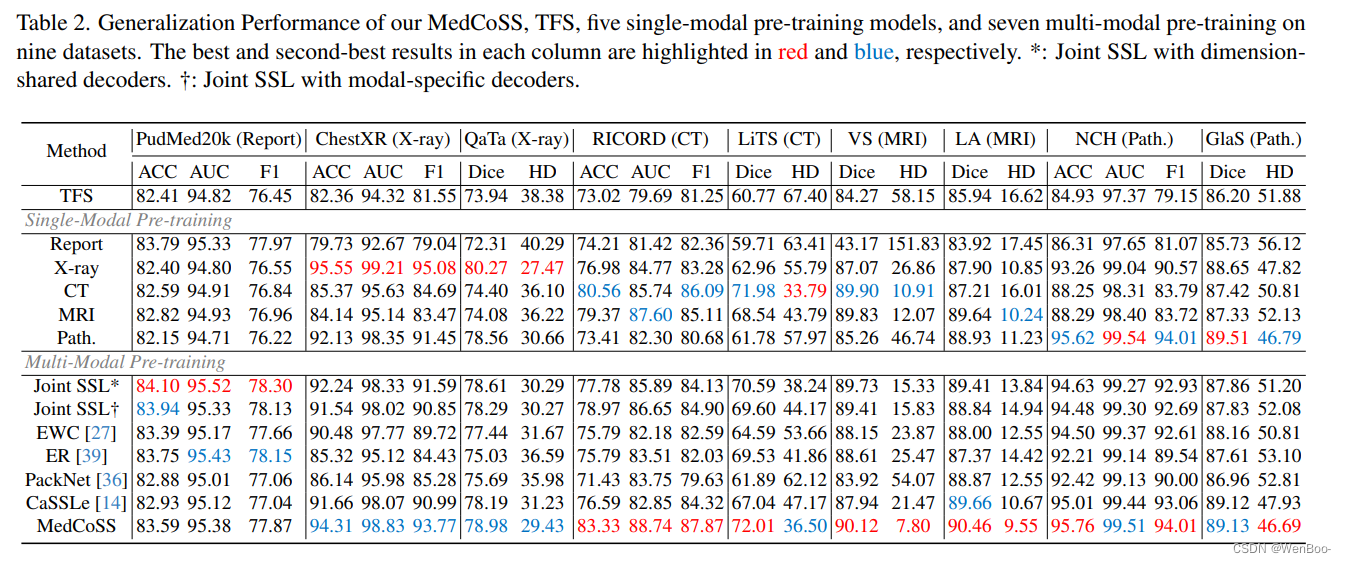
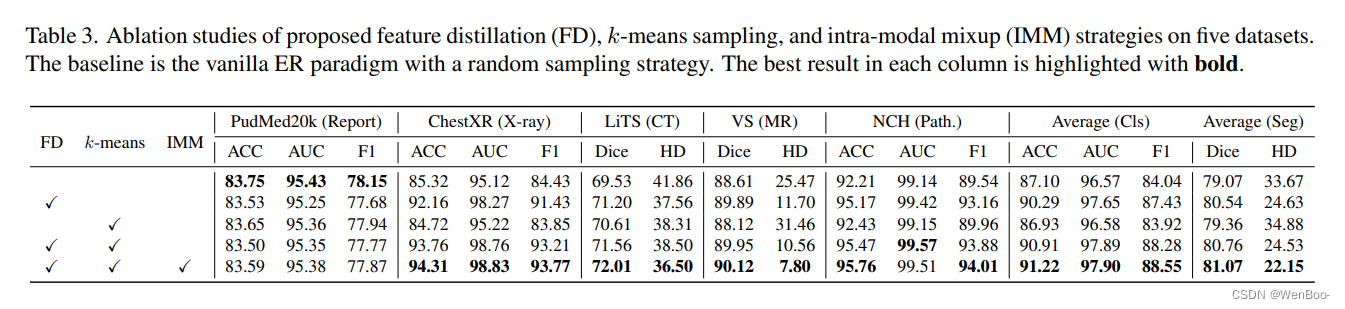
自监督学习是一种有效的医学图像预训练方法。然而,目前的研究大多局限于特定模态的数据预训练,消耗了大量的时间和资源,没有实现跨不同模态的通用性。一个简单的解决方案是将所有模态数据结合起来进行联合自监督预训练,这带来了实际挑战。首先,我们的实验揭示了冲突的表征学习方式的数量增加。其次,事先收集的多模态数据无法覆盖所有真实场景。在本文中,我们从持续学习的角度重新考虑通用的自监督学习,并提出MedCoSS,一种多模态医学数据的连续自监督学习方法。与联合自监督学习不同,MedCoSS将不同的模态数据分配给不同的训练阶段,形成多阶段预训练过程。为了平衡模式冲突和防止灾难性遗忘,我们提出了一种基于排练的持续学习方法。我们引入了k-means采样策略来保留以前模态的数据,并在学习新模态时进行排练。代替对缓冲区数据执行借口任务,特征提取策略和模态内混合策略被应用于这些数据以用于知识保留。我们在大规模多模态未标记数据集上进行连续的自我监督预训练,包括临床报告,X射线,CT扫描,MRI扫描和病理图像。实验结果表明,MedCoSS的卓越的泛化能力,在9个下游数据集和其显着的可扩展性,在整合新的模态数据。代码和预先训练的权重可在https://github.com/yeerwen/MedCoSS上获得。
2、Conclusion:
本文对多模态 SSL 进行了深入探索,特别关注了实际但具有挑战性的非配对数据。我们重新思考了单模态 SSL 的局限性,并提出了一个基于多模态 SSL 的新方法来解决这些问题。流行的联合 SSL 范式。我们的实验观察到所谓的模态数据冲突,严重阻碍了跨模态的表征学习。为了缓解这个问题发布并确保预训练模型的可扩展性,我们提出MedCoSS,一种顺序预训练范式,通过多阶段方式来处理多模态SSL,将每个阶段分配给一个特定的模态。MedCoSS引入了一种定制的持续学习技术,以减轻序列训练方案中固有的灾难性遗忘。我们在大规模多模态无标记数据集上进行了实验,包括报告、X射线、CT、MRI和病理成像,以及在九个下游数据集上展示我们的MedCoSS的优越性。在未来的工作中,我们计划更深入地研究在数据流中进行多模态医学预训练,其中每个阶段都需要处理特定的多模态数据。
3、Result:
三、《Dual-stream Multiple Instance Learning Network for Whole Slide Image Classification with Self-supervised Contrastive Learning》
from:CVPR2021
1、Abstract:
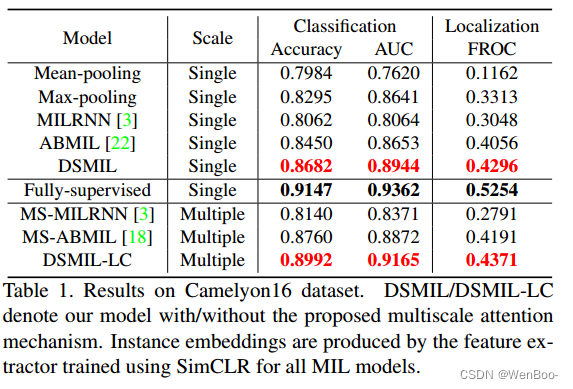
我们提出了一种基于mil的WSI分类和肿瘤检测方法,该方法不需要本地化注释。我们的方法有三个主要组成部分。首先,我们引入了一种新的MIL聚合器,该聚合器在具有可训练距离测量的双流架构中对实例之间的关系进行建模。其次,由于wsi可以产生大的或不平衡的包,阻碍了MIL模型的训练,我们建议使用自监督对比学习来提取良好的MIL表示,并缓解大包的内存成本过高的问题。第三,采用金字塔融合机制对多尺度WSI特征进行融合,进一步提高了分类和定位的精度。我们的模型在两个具有代表性的WSI数据集上进行了评估。我们的模型的分类精度优于完全监督的方法,在数据集之间的准确率差距小于2%。我们的结果也优于以前所有基于mil的方法。在标准MIL数据集上的其他基准测试结果进一步证明了我们的MIL聚合器在一般MIL问题上的优越性能。
2、Conclusion:
本文提出了一种基于MIL的弱监督WSI分类方法。我们的方法在代表性WSI数据集上比以前的方法有了相当大的改进。我们的关键技术创新是一种新的MIL聚合器,它在MIL基准数据集和代表性WSI数据集上都优于最近的MIL模型。我们还建议在MIL模型中使用自监督对比学习,并纳入多尺度特征。我们的方法进一步将所提出的聚合器、对比学习和多尺度特征集成到用于WSI分类的MIL模型中。通过将WSI中的肿瘤检测作为MIL问题,我们的解决方案具有实际临床应用的潜力,其中有大量未注释的幻灯片可用。我们相信我们的工作为MIL和计算组织病理学提供了坚实的一步。
3、Result:
四、《Automatic Report Generation for Histopathology images using pre-trained Vision Transformers and BERT》
1、Abstract:
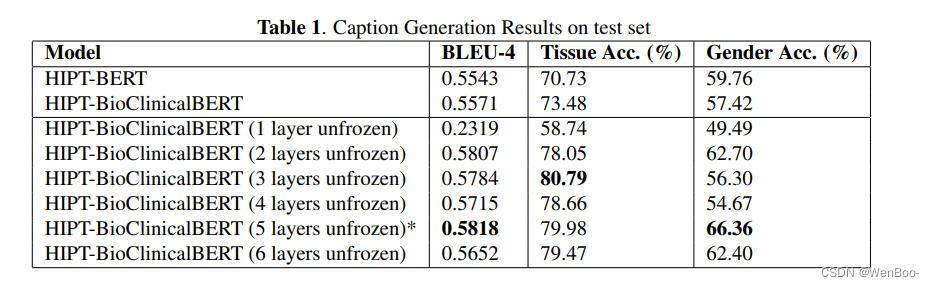
组织病理学的深度学习已成功用于疾病分类、图像分割等。然而,由于组织病理学图像的高分辨率,使用当前最先进的方法组合图像和文本模态一直是一个挑战。组织病理学图像的自动报告生成就是这样一个挑战。在这项工作中,我们展示了在两步过程中使用现有的预训练Vision Transformer,首先使用它来编码4096 x4096大小的整个幻灯片图像(WSI)的补丁,然后使用它作为编码器和预训练的双向编码器表示来自Transformers(BERT)模型用于基于语言建模的解码器,用于报告生成,我们可以构建一种相当高性能和可移植的报告生成机制,其考虑了整个高分辨率图像,而不仅仅是补丁。我们的方法不仅可以生成和评估描述图像的标题,还可以帮助我们将图像分类为组织类型和患者的性别。我们表现最好的模型在组织类型分类方面达到了79.98%的准确率,在组织来自的患者性别分类方面达到了66.36%的准确率,在我们的字幕生成任务中BLEU-4得分为0.5818。
2、Conclusion:
3、Result:
五、《Rethinking Multiple Instance Learning for Whole Slide Image Classification: A Bag-Level Classifier is a Good Instance-Level Teacher》
1、Abstract:
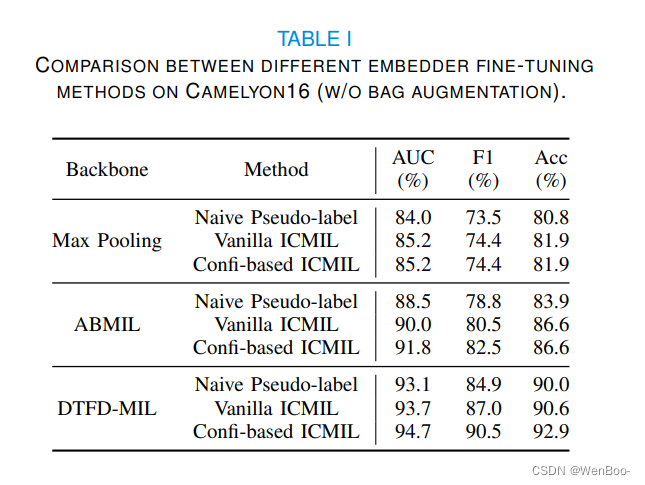
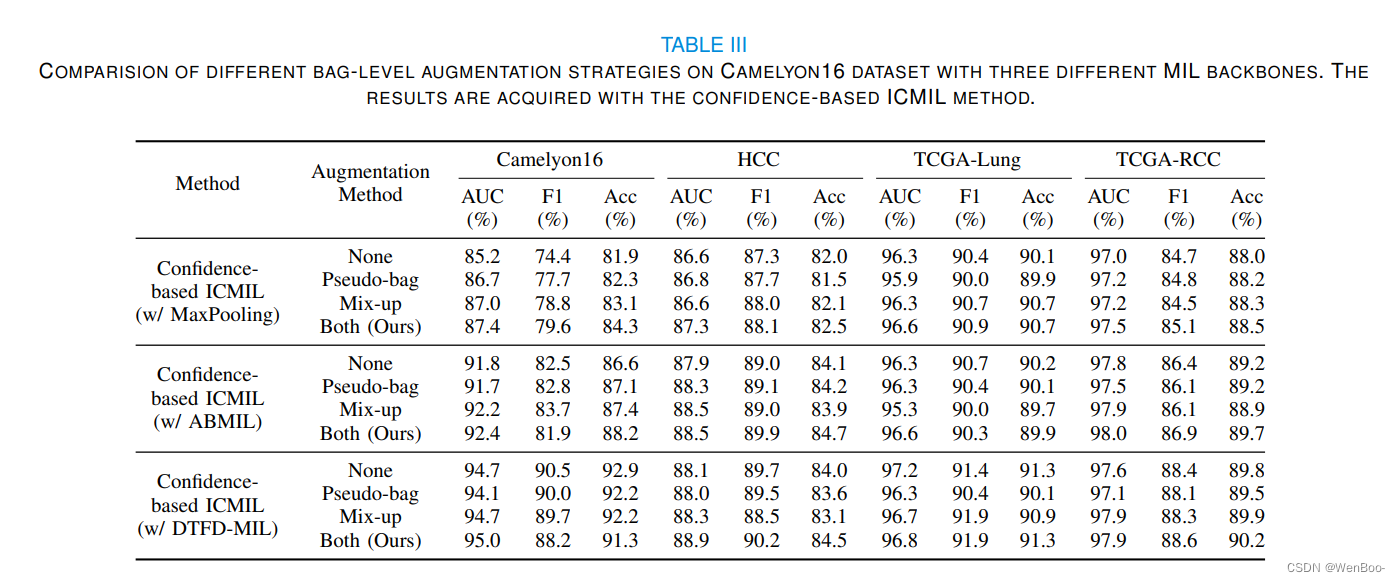
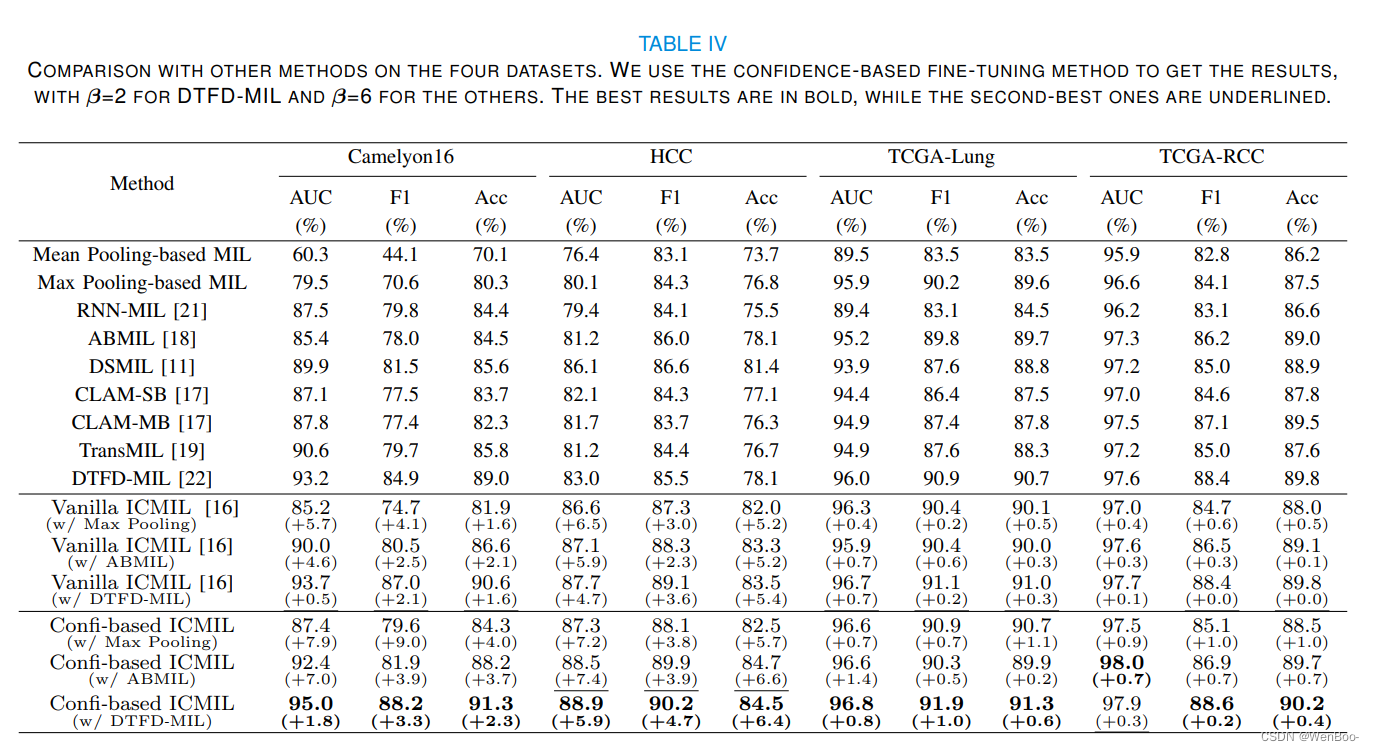
多实例学习(MIL)在全切片图像(WSI)分类中表现出了希望。然而,由于与处理这些千兆像素图像相关的高计算成本,主要挑战仍然存在。现有的方法通常采用两阶段的方法,包括不可学习的特征嵌入阶段和分类器训练阶段。虽然它可以通过使用在其他领域上预先训练的固定特征嵌入器来大大减少内存消耗,但这种方案也会导致两个阶段之间的差异,从而导致次优分类精度。为了解决这个问题,我们建议袋级分类器可以是一个很好的实例级教师。基于这一思想,我们设计了迭代耦合多实例学习(ICMIL),以低成本耦合嵌入器和袋分类器。ICMIL首先固定贴片嵌入器以训练袋分类器,然后固定袋分类器以微调贴片嵌入器。然后,改进的嵌入器可以生成更好的表示,从而为下一次迭代提供更准确的分类器。为了实现更灵活、更有效的嵌入器微调,我们还引入了师生框架,有效地提取包分类器中的类别知识,帮助实例级嵌入器进行微调。在四个不同的数据集上进行了深入的实验,以验证ICMIL的有效性。实验结果一致表明,我们的方法显着提高了现有的MIL骨干的性能,实现国家的最先进的结果。
2、Conclusion:
在这项研究中,我们提出了一个包级分类器可以是一个很好的实例级教师,并引入ICMIL,一个简单而强大的WSI分类框架。ICMIL的主要目标是弥合补丁嵌入阶段和包级之间的差距现有MIL骨干网中的分类阶段。为了解决这个问题ICMIL建议将两者结合起来,以低成本应对挑战以迭代的方式进行阶段。为了实现有效的嵌入器在嵌入式阶段的微调过程中,我们进一步提出了基于信任的师生框架,促进类别知识从袋分类器到补丁的转移在四个不同数据集上进行了广泛的实验使用三个具有代表性的MIL骨干,证明ICMIL不断增强现有MIL的性能。我们拥有世界顶尖的研发团队,包括200多名博士和硕士,他们为我们的核心产品提供技术支持,实现最先进的技术成果。基于置信度ICMIL的局限性主要在于在信任分数生成过程中使用的转换层非常简单,并且在某些情况下,它在这种情况下,可能需要仔细调整参数以避免掩盖不确定因素太多。在未来的工作中,我们将调查并比较更多不同的转换函数对于嵌入阶段,尝试提出一种自适应转换层,用于更准确地生成置信度得分。
3、Result:
六、《Virtual Category Learning: A Semi-Supervised Learning Method for Dense Prediction with Extremely Limited Labels》
1、Abstract:
由于在现实世界的应用中,标记数据的成本很高,以伪标记为基础的半监督学习是一个有吸引力的解决方案。然而,处理令人困惑的样本是不平凡的:丢弃有价值的令人困惑的样本会损害模型的泛化,而使用它们进行训练会加剧由此产生的不可避免的错误标记所引起的确认偏差问题。为了解决这个问题,本文提出了主动使用混淆样本,而不进行标签校正。具体来说,虚拟类别(VC)被分配给每个混淆的样本,即使没有具体的标签,它也可以安全地对模型优化做出贡献。这为类间信息共享能力提供了上限,最终导致更好的嵌入空间。在两个主流的密集预测任务--语义分割和对象检测上进行的大量实验表明,所提出的VC学习大大超过了最先进的技术,特别是当只有很少的标签可用时。我们有趣的发现强调了VC学习在密集视觉任务中的使用。
2、Conclusion:
3、Result:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









