






一、《In-context learning enables multimodal large language models to classify cancer pathology images》
1、Abstract:
医学图像分类需要标记的、针对特定任务的数据集,这些数据集用于从头开始训练深度学习网络,或用于微调基础模型。然而,这个过程在计算和技术上都很复杂。在语言处理领域,上下文学习提供了一种替代方案,即模型从提示中学习,无需更新参数。然而,上下文学习在医学图像分析领域的研究仍然不足。在本文中,我们系统地评估了具有视觉能力的生成式预训练转换器模型GPT-4V在癌症图像处理方面的性能,使用了上下文学习的方法,针对三个具有重要意义的癌症组织病理学任务进行了评估:结直肠癌组织亚型分类、结肠息肉亚型分类和淋巴结切片中的乳腺肿瘤检测。结果表明,上下文学习足以匹配甚至超越为特定任务训练的专用神经网络,同时只需极少量的样本。总之,本研究表明,在非领域特定数据上训练的大型视觉语言模型可以直接应用于解决组织病理学中的医学图像处理任务。这使不具备技术背景的医学专家能够更容易地获得通用型人工智能模型的使用权,特别是在标注数据稀缺的领域。
2、Conclusion:
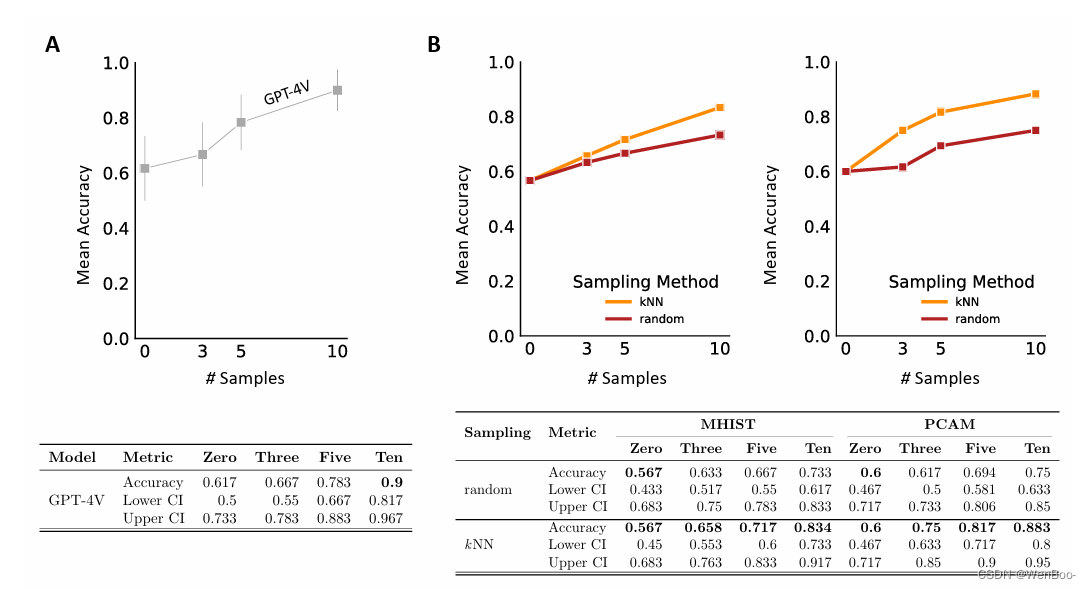
本研究通过GPT-4V的实例,证明了在视觉语言模型上进行上下文学习可以实现这些性质的可行性。我们展示了这种方法不仅在医学显微图像分类方面有效,而且其性能可以与在相同数量数据上训练的传统图像分类模型相媲美。这些结果令人鼓舞,特别是考虑到当前最先进的病理学基础模型,如Paige的的Virchow25,其性能指标仅略高于我们的方法。据报道,在MHIST数据集上,Virchow的准确率为82.7%,而GPT-4V的准确率为83.3%;在PatchCamelyon数据集上,Virchow的准确率为92.7%,而GPT-4V的准确率为88.3%。对于MHIST,我们在此必须指出,我们排除了没有完全评分者间一致性的图像,这使得我们的用例很可能比Vorontsov等人25使用的用例更容易。
我们承认公众无法访问GPT-4V的训练语料库,这增加了模型可能在我们的测试集上进行训练的可能性。然而,在零样本场景中观察到的性能略优于随机猜测,这使得数据用于训练的可能性较小。我们将此零样本基线用作比较,以调查上下文学习的益处。通过我们的方法,我们为一个通用的框架奠定了基础,该框架将最先进的提示技术应用于图像。
此外,我们的研究结果表明,精心选择高质量、少量样本示例可以显著提高模型性能。值得注意的一个方面是文本与视觉的结合,这为理解模型推理过程提供了一个新的维度,增加了可解释性。这解决了传统图像分类器的一个关键局限性,因为文本反馈为人类提供了一种比视觉工具更易于理解和解释的方式。
3、Result:
二、《Dynamic Graph Representation with Knowledge-aware Attention for Histopathology Whole Slide Image Analysis》
1、Abstract:
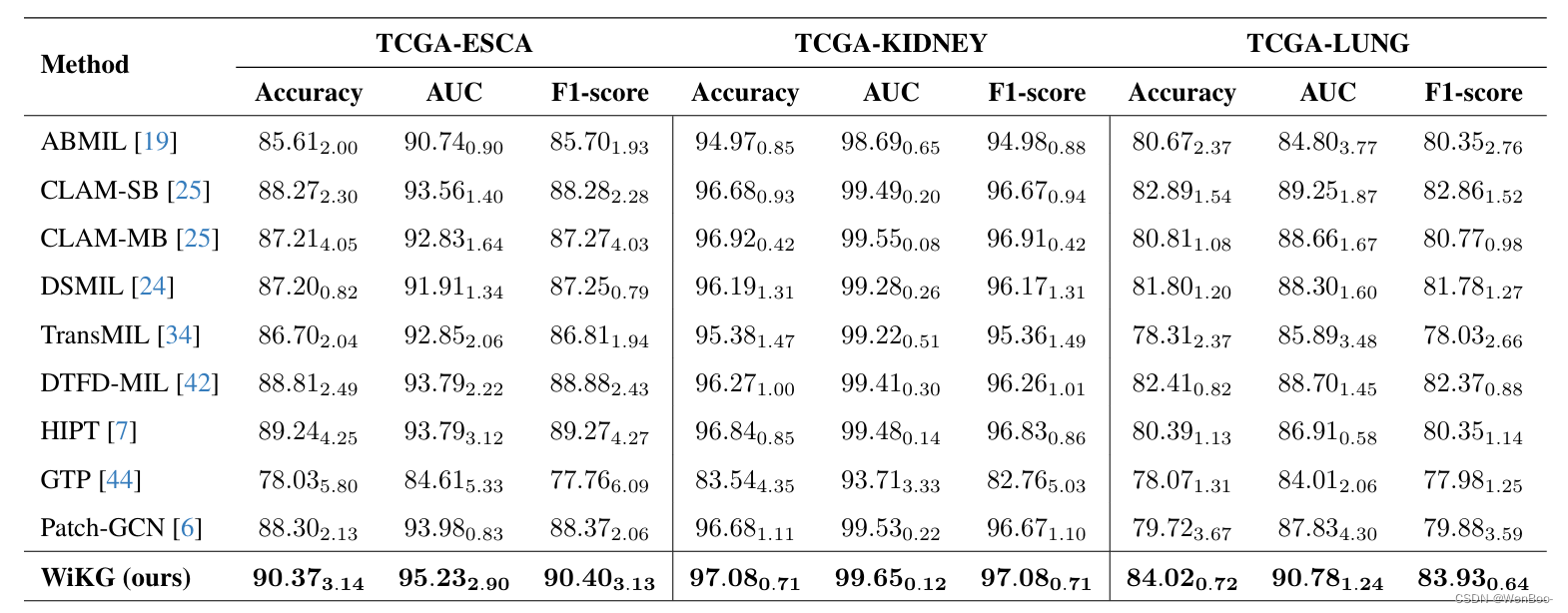
组织病理学全玻片图像(WSIs)分类已成为医学显微图像处理中的一项基础任务。目前的主流方法将WSIs作为实例袋表示进行学习,强调重要的实例,但难以捕捉实例之间的相互作用。此外,传统的图表示方法利用明确的空间位置来构建拓扑结构,但限制了任意位置(尤其是空间距离较远时)实例之间的灵活交互能力。为此,我们提出了一种新颖的动态图表示算法,将WSIs概念化为一种知识图结构。具体来说,我们根据实例之间的头尾关系动态构建邻居和有向边嵌入。然后,我们设计了一种知识感知的注意力机制,通过学习每个邻居和边的联合注意力分数来更新头节点特征。最后,我们通过更新后的头的全局池化过程获得图级嵌入,作为WSI分类的隐式表示。我们的端到端图表示学习方法在三个TCGA基准数据集和内部测试集上的表现均优于最先进的WSI分析方法。
2、Conclusion:
在本文中,我们介绍了一种名为WiKG的新型动态图表示方法,用于分析WSIs。通过建模头尾嵌入之间的相互作用,并构建一种知识感知的注意力机制来聚合邻居信息,WiKG释放了图像块在其拓扑结构中探索相互关系的能力,同时也利用实体之间的方向性贡献来更好地实现图像块之间的交互,从而实现了更好的WSI分析性能。通过对三个公共基准数据集和内部测试集进行广泛的实验和消融研究,我们证明了WiKG的有效性和更好的泛化性能。
在未来的工作中,我们将专注于WiKG在WSIs中的可解释性,并探索图池化对WSIs的影响。此外,我们还将对WSI分析任务的泛化性进行深入研究,因为现有研究方法可能不具备良好的泛化性能。我们相信,通过不断的研究和改进,WiKG将为医学显微图像处理领域带来更多的突破和进步。
3、Result:
三、《Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images》
from:CVPR 2024
1、Abstract:
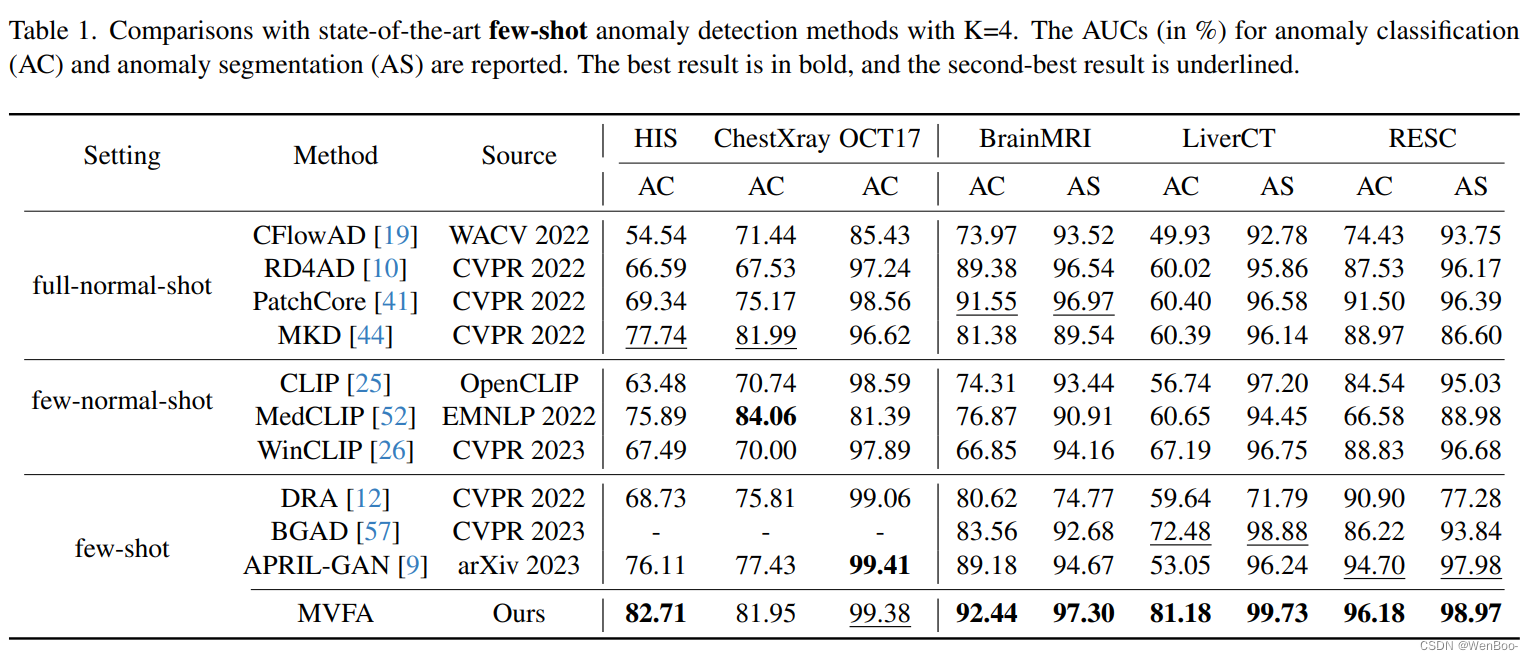
大规模视觉语言预训练模型的最新进展已经在自然图像域中的零/Few-Shot异常检测方面取得了重大进展。然而,自然和医学图像之间的实质性领域分歧限制了这些方法在医学异常检测中的有效性。本文介绍了一种新的轻量级的多级适应和比较框架,重新调整CLIP模型的医疗异常检测。我们的方法将多个残余适配器集成到预先训练的视觉编码器中,从而能够逐步增强不同级别的视觉特征。这种多级自适应由多级像素视觉语言特征对齐损失函数指导,该函数将模型的重点从自然图像中的对象语义重新校准到医学图像中的异常识别。调整后的特征在各种医疗数据类型中表现出改进的泛化,即使在模型在训练期间遇到看不见的医疗模态和解剖区域的zero-shot场景中也是如此。我们的医疗异常检测基准的实验表明,我们的方法显着超过当前最先进的模型,与平均AUC改善6.24%和7.33%的异常分类,2.03%和2.37%的异常分割,下zero-shot和Few-Shot设置,分别。源代码可从以下网址获得:https://github.com/MediaBrain-SJTU/MVFA-AD
2、Conclusion:
这篇论文将自然领域的预训练视觉语言模型应用于医学领域的异常检测(AD)任务,实现了跨领域、跨模态和跨解剖区域的泛化能力。这种适应不仅涉及从自然领域到医学领域的转变,还涉及从高级语义到像素级分割的转变。为了实现这些目标,论文引入了一种协作的多级特征适应方法,其中每个适应过程都由相应的视觉语言对齐进行指导,从而有助于从医学图像中分割出各种形式的异常。结合基于比较的AD策略,该方法能够灵活适应具有显著模态和分布差异的数据集。所提出的方法在零次/少次学习的异常分类(AC)和异常分割(AS)任务上优于现有方法。
这段文字主要描述了一篇论文在医学领域应用预训练视觉语言模型进行异常检测的研究内容。通过引入协作的多级特征适应方法和基于比较的AD策略,该方法能够在不同模态和解剖区域之间实现跨领域的泛化,并在零次/少次学习的任务上取得优于现有方法的表现。这对于提高医学图像分析的准确性和效率具有重要意义,有助于推动医学诊断技术的发展。
3、Result:
四、《Re-identification from histopathology images》
1、Abstract:
在众多研究中,深度学习算法已经证明了它们在组织病理学图像分析中的潜力,例如揭示肿瘤亚型或转移瘤的原发部位。这些模型需要大量的数据集进行训练,这些数据集必须匿名化以防止可能的病人身份泄露。本研究表明,即使是相对简单的深度学习算法也能以相当高的准确性在大型组织病理学数据集中重新识别病人。我们在两个TCIA数据集上评估了我们的算法,包括肺鳞状细胞癌(LSCC)和肺腺癌(LUAD)。我们还展示了该算法在内部脑膜瘤组织数据集上的表现。在LSCC和LUAD数据集上,我们分别预测了玻片来源病人的F1分数为50.16%和52.30%,而在我们的脑膜瘤数据集上则达到了62.31%。基于我们的发现,我们制定了一个风险评估方案,以在发布前估计病人隐私泄露的风险。
这段文字主要讨论了一项关于深度学习算法在组织病理学数据集中重新识别病人身份的研究。该研究发现,即使使用相对简单的深度学习算法,也能在大型组织病理学数据集中以相当高的准确性重新识别病人。这为医学图像分析领域的数据隐私保护提出了重要的问题。为了应对这一挑战,研究者还提出了一个风险评估方案,以便在发布前估计病人隐私泄露的风险。这有助于推动医学图像分析领域在保护病人隐私方面的进一步发展。
2、Conclusion:
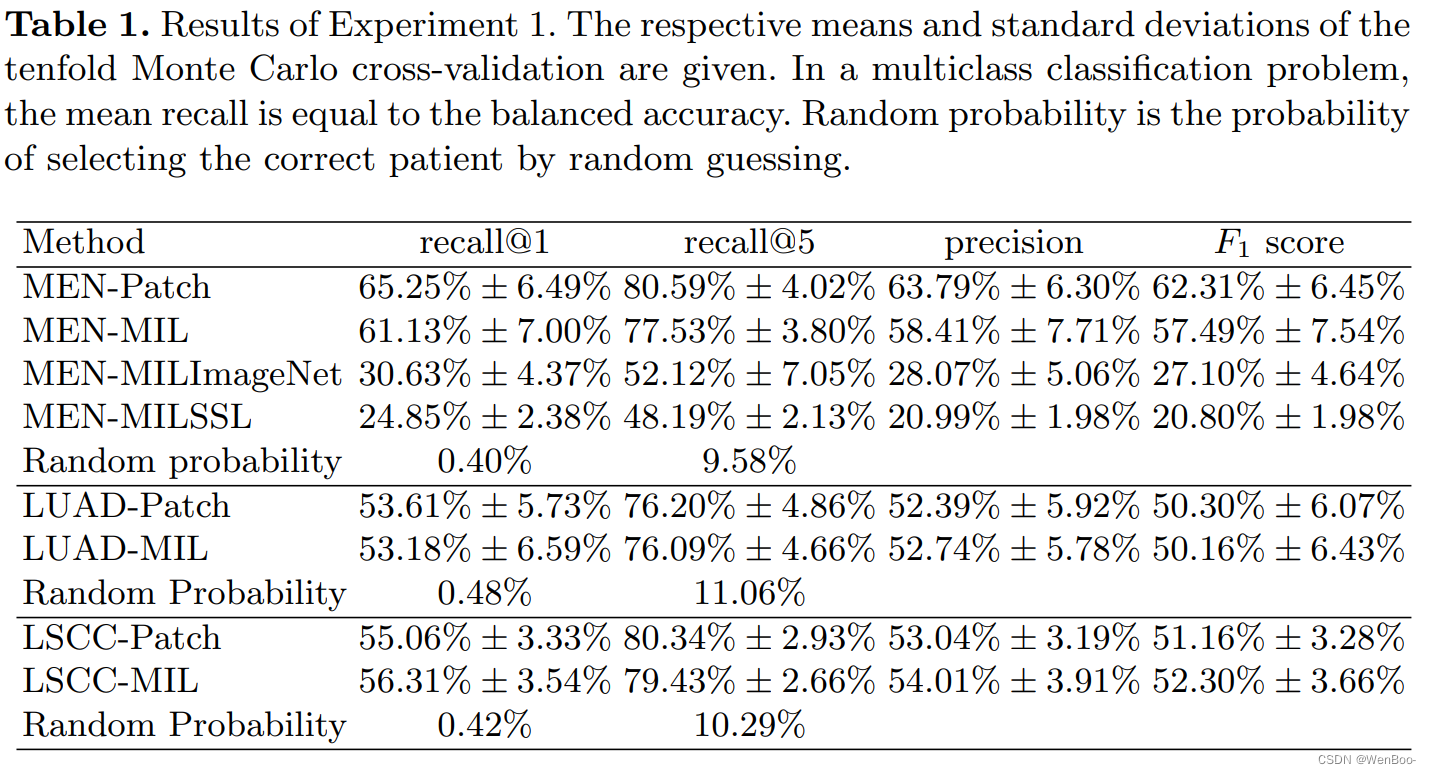
在所有三个数据集上,这些方法都显示出基于组织病理学切片重新识别病人的满意性能。详细结果可参见表1。在脑膜瘤数据集(MEN)上,基于补丁的MEN-Patch模型实现了最高的recall@1,达到65.25%。多实例学习(MIL)模型MEN-MIL的表现稍差,recall@1为61.13%。对于recall@5,这两个值分别为80.59%和77.53%。在比较MIL方法使用的不同特征编码器时,包含作为MEN-Patch模型一部分训练的特征干(feature stem)的MEN-MIL模型产生了最有利的结果。包含在ImageNet上训练的特征编码器的MIL模型(MEN-MILImageNet)实现了30.63%的recall@1。包含通过自监督学习(SSL)训练的特征干的MIL模型(MEN-MILSSL)实现了24.85%的recall@1。对于两个公共数据集,我们发现基于补丁的方法和MIL方法的性能非常相似。在肺腺癌数据集(LUAD)上,基于补丁的方法和MIL方法分别实现了53.61%和53.18%的recall@1。在肺鳞状细胞癌数据集(LSCC)上,我们分别找到了55.06%和56.31%的recall@1。与在脑膜瘤数据集上稍高的recall@1相比,所有模型在recall@5上都取得了非常相似的结果。
这段文字主要描述了在不同数据集上,基于补丁的方法和MIL方法在重新识别病人方面的性能表现。在脑膜瘤数据集上,基于补丁的方法表现稍好,而在两个公共数据集上,两种方法的表现非常接近。此外,文章还讨论了使用不同特征编码器对MIL模型性能的影响,发现在使用经过特定训练的特征干时,模型性能最佳。这些结果对于了解不同方法在重新识别病人方面的优势和局限性,以及选择适合特定应用场景的模型具有重要意义。
3、Result:
五、《Prompt-Guided Adaptive Model Transformation for Whole Slide Image Classification》
1、Abstract:
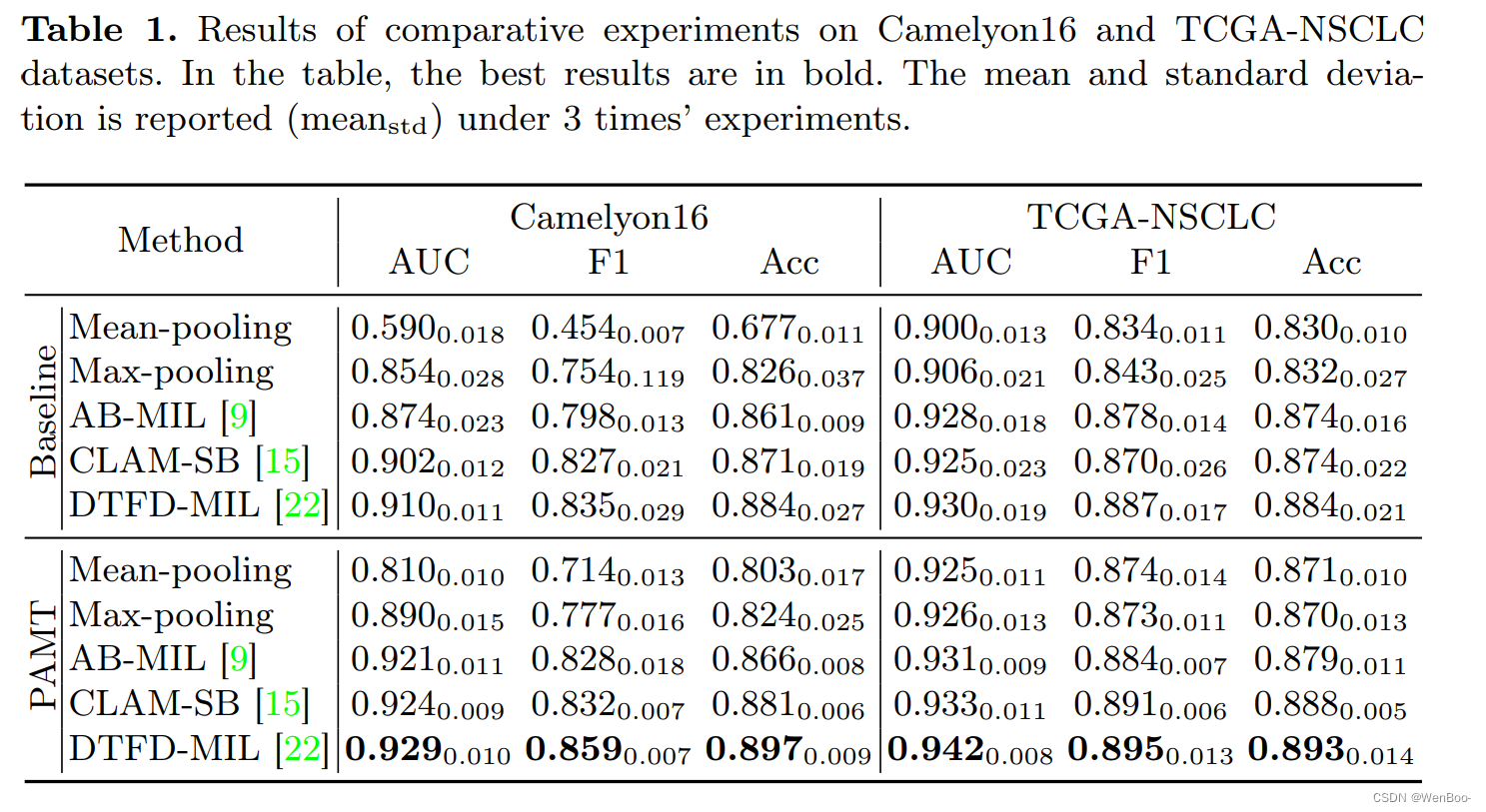
多实例学习(MIL)已经成为一种流行的方法,用于分类组织病理学全切片图像(WSIs)。现有的方法通常依赖于冻结的预训练模型来提取实例特征,忽略了预训练自然图像和组织病理学图像之间的实质性域转移。为了解决这个问题,我们提出了PAMT,这是一种新的自适应模型转换框架,它通过无缝地将预训练模型适应于组织病理学数据的特定特征来增强MIL分类性能。为了捕获复杂的组织病理学分布,我们引入了代表性补丁采样(RPS)和原型视觉提示(PVP)来改造输入数据,建立一个紧凑而信息丰富的表示。此外,为了缩小领域差距,我们引入了自适应模型转换(AMT),它将适配器块集成在特征提取管道中,使预训练的模型能够学习特定于领域的特征。我们在两个公开的数据集Camelyon 16和TCGA-NSCLC上严格评估了我们的方法,展示了各种MIL模型的实质性改进。我们的研究结果肯定了PAMT在WSI分类中建立新基准的潜力,强调了有针对性的重编程方法的价值。
2、Conclusion:
本研究中,我们介绍了PAMT,这是一种基于提示的自适应模型转换方法,用于全玻片图像分类。PAMT无缝集成了三个关键组件,即代表性补丁采样(RPS)、原型视觉提示(PVP)和自适应模型转换(AMT),旨在重塑输入数据和模型。PAMT利用视觉提示和适配器块,同时保留预训练主干网络的内在知识,确保针对病理图像进行量身定制的适应。在Camelyon16和TCGANSCLC两个公共数据集上,采用五种不同的多实例学习分类器进行了全面验证,强调PAMT能够显著改善WSI分类,展示了其有效性和效率。未来的工作将集中在开发更先进的视觉提示和适配器块,以考虑可伸缩性、灵活性和鲁棒性。
这段话介绍了PAMT这一新方法的核心思想和应用价值。PAMT通过结合代表性补丁采样、原型视觉提示和自适应模型转换这三个关键组件,对输入数据和模型进行改进,以优化全玻片图像分类的效果。该方法利用了视觉提示和适配器块,同时保持了预训练模型的基础性能,使其更加适用于病理图像的分析。在两个公共数据集上的验证结果表明,PAMT可以显著提高WSI分类的准确性和效率。此外,作者还提出了未来的研究方向,即开发更先进的视觉提示和适配器块,以提高方法的可伸缩性、灵活性和鲁棒性。这些工作将有助于进一步推动PAMT在医学图像处理领域的应用和发展。
3、Result:
六、《RetMIL: Retentive Multiple Instance Learning for Histopathological Whole Slide Image Classification》
1、Abstract:
病理切片扫描仪将微观视野存储为全玻片图像(WSI),为基于深度学习的自动诊断奠定了基础[18]。然而,吉像素级别的分辨率和缺乏像素级别的标注给开发此类智能工具带来了重大挑战。近年来,随着弱监督技术的发展,WSI分析的MIL方法得到了广泛研究,这些方法将WSI视为包,将裁剪的补丁视为实例。通过将实例嵌入到高维空间进行聚合,可以获得幻灯片级别的表示。MIL方法一般可分为实例级[4,7,11]和嵌入级[10,13,21]方法。由于数据需求巨大且泛化能力较弱,前者已逐渐被取代。
嵌入级的MIL方法通常侧重于提出有效的聚合策略,以获得更有效的WSI表示。虽然平均池化或最大池化是MIL理论的直接推论,但动态地为补丁分配重要性得分已被证明更为有效[10,16]。此外,由于Transformer的广泛应用[24],更多的研究集中在通过自注意力机制建模补丁之间的相关性来预测WSI得分,这有助于描述潜在的肿瘤微环境模式。基于Transformer的MIL方法在许多WSI分析任务中表现出了更好的性能[21,6,26]。然而,自注意力机制的非线性特性导致的平方复杂度在训练和推理过程中消耗了更多内存,增加了延迟并降低了速度,这不利于算法在实际临床场景中的部署。
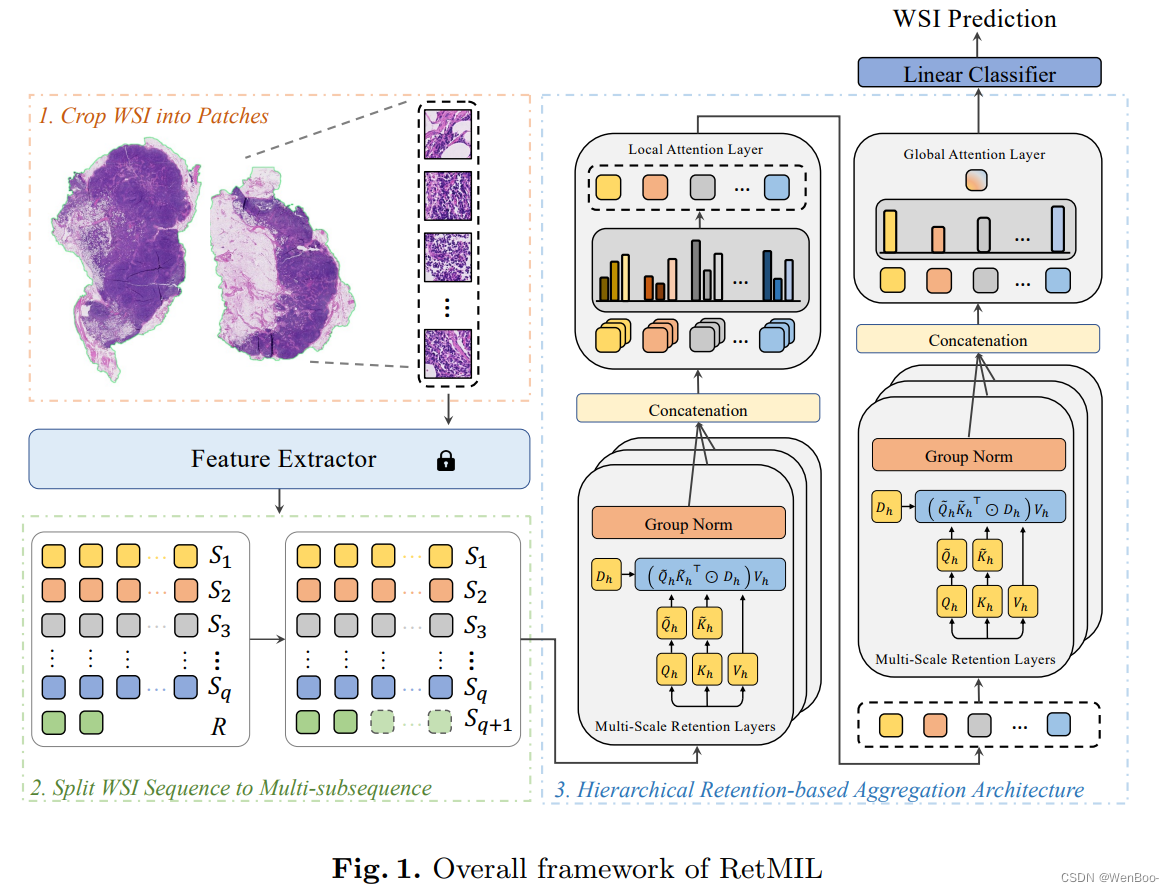
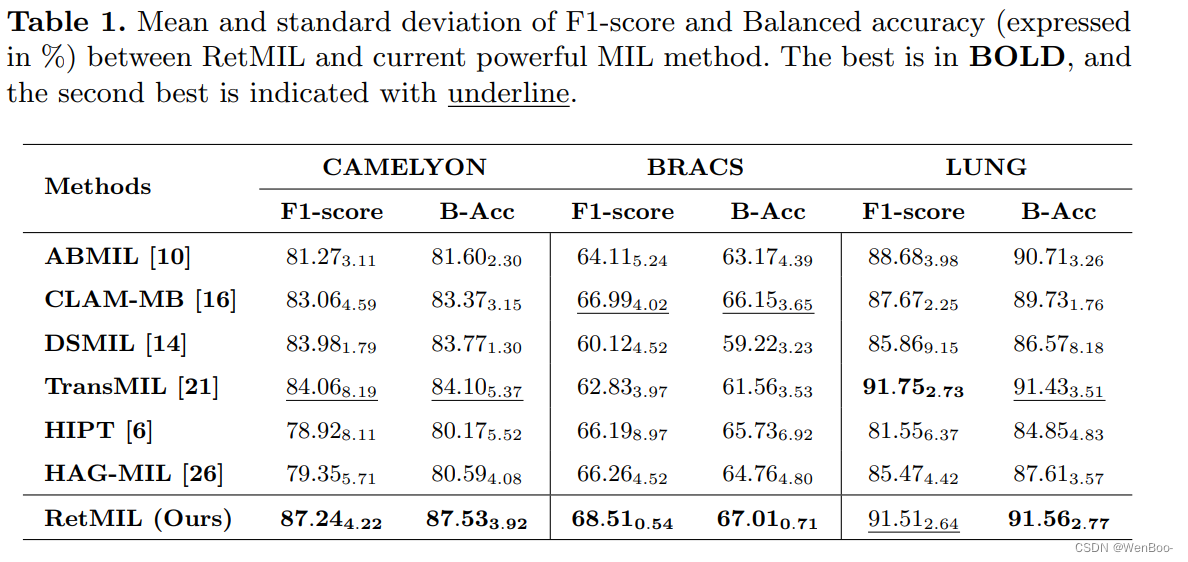
为了缓解上述挑战,本文提出了一种保留式的多实例学习神经网络,称为RetMIL。它引入了一种注意力机制来替代非线性的自注意力,并通过构建层次结构有效地整合WSI的子序列信息,以获取具有局部特征的全局表示。我们在公开的CAMELYON和BRACS数据集以及用于公共数据训练和内部数据测试的LUNG数据集上进行了实验。结果表明,我们提出的RetMIL在降低内存消耗和提高吞吐量的同时,表现出了具有竞争力的性能。
2、Conclusion:
在本文中,我们提出了一种保留式的多实例学习方法,称为RetMIL。该方法使用线性保留机制来降低计算开销,同时建模补丁之间的相关性。此外,我们还设计了层次化的保留聚合架构,以更新局部子序列并全面表征全局WSI序列。我们在三个组织病理学WSI数据集上进行了对比实验,展示了RetMIL的优越性。同时,我们还与基于Transformer的方法进行了推理性能的比较,结果表明我们提出的RetMIL具有更低的计算消耗。
3、Result:
七、《DTFD-MIL: Double-Tier Feature Distillation Multiple Instance Learning for Histopathology Whole Slide Image Classification》
1、Abstract:
2、Conclusion:
3、Result:
八、《Improved EATFormer: A Vision Transformer for Medical Image Classification》
1、Abstract:
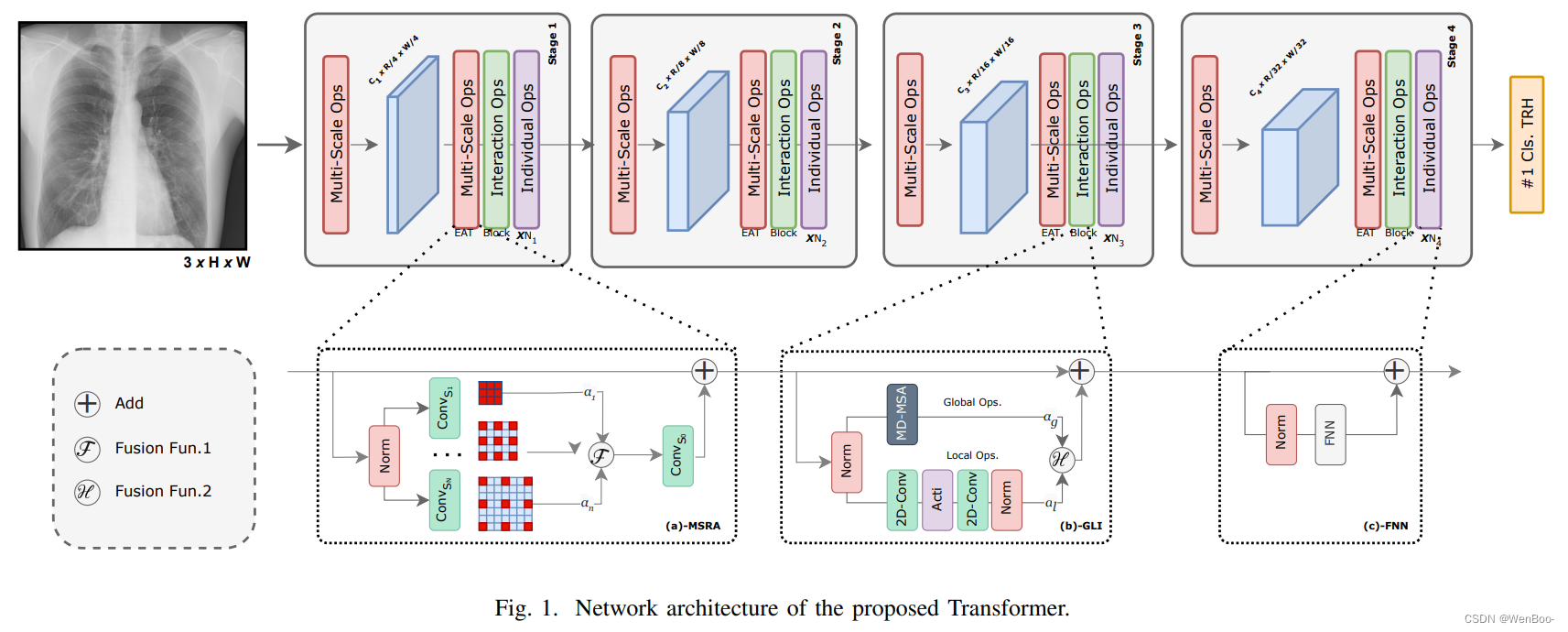
医学图像的精确分析对于诊断和预测医疗状况至关重要。传统上依赖放射科医生和临床医生的方法存在不一致性和漏诊的问题。计算机辅助诊断系统有助于实现早期、准确和高效的诊断。本文提出了一种基于进化算法的改进Transformer架构,用于使用视觉Transformer进行医学图像分类。提出的EATFormer架构结合了卷积神经网络和视觉Transformer的优点,利用它们识别数据中的模式和适应特定特性的能力。该架构包含新颖组件,包括带有前馈网络、全局和局部交互以及多尺度区域聚合模块的增强型EA基Transformer块。它还引入了调制可变形MSA模块,用于不规则位置的动态建模。
本文讨论了视觉Transformer(ViT)模型的关键特征,如基于补丁的处理、位置上下文整合和多头注意力机制。它介绍了多尺度区域聚合模块,该模块从不同感受野聚合信息以提供归纳偏置。全局和局部交互模块通过引入局部路径来提取具有区分性的局部信息,从而增强了基于MSA的全局模块。在胸部X光片和Kvasir数据集上的实验结果表明,与基线模型相比,提出的EATFormer显著提高了预测速度和准确性。
综上所述,该论文提出了一种创新的医学图像分类方法,结合了进化算法和Transformer架构的优势,并引入了一系列新颖组件,以提高诊断的准确性和效率。这为医学图像分析领域的研究和应用提供了新的思路和方向。
2、Conclusion:
本文提出了一种使用视觉Transformer架构进行医学图像分类的新颖方法。所提出的EATFormer架构融合了受进化算法启发的模块,如多尺度区域聚合(MSRA)、全局和局部交互(GLI)以及调制可变形MSA(MD-MSA),以提升模型的性能。在胸部X光片和Kvasir数据集上的实验结果表明,与基线模型相比,该方法在预测速度和准确性方面均取得了显著的提升。
本研究展示了视觉Transformer在医学图像分析中的有效性,并强调了将进化算法概念融入深度学习架构的潜力。所提出的方法有望协助医师和临床医生实现早期、准确和高效的诊断,从而改善患者预后,提高生活质量。
总的来说,这项研究不仅推动了医学图像分析领域的技术进步,还为临床应用提供了有力的支持,展现了深度学习和进化算法在医疗领域的广阔应用前景。
3、Result:
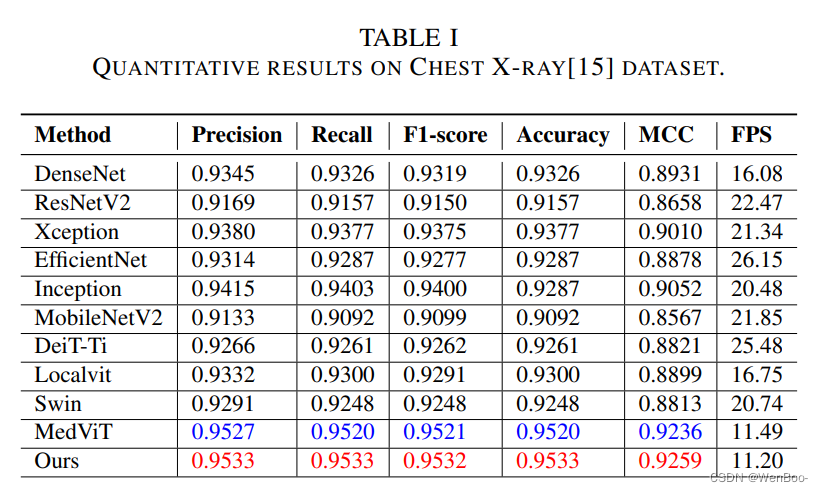
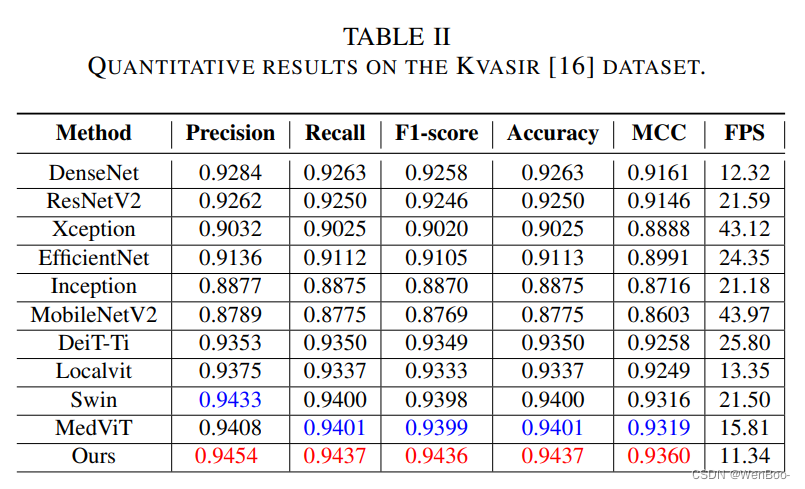
九、《MedViT: A Robust Vision Transformer for Generalized Medical Image Classification》
1、Abstract:
卷积神经网络(CNNs)已经推动了现有医学系统自动疾病诊断的发展。然而,对于深度医学诊断系统对抗潜在对抗性攻击的可靠性,仍存在担忧,因为不准确的诊断可能在安全领域带来灾难性后果。本研究提出了一种既稳健又高效的CNN-Transformer混合模型,该模型结合了CNNs的局部性和视觉Transformer的全局连接性。为了缓解自注意力机制的高二次复杂性,同时关注不同表示子空间中的信息,我们利用高效的卷积操作来构建注意力机制。此外,为了减轻Transformer模型对对抗性攻击的脆弱性,我们尝试学习更平滑的决策边界。为此,我们在高级特征空间中通过在小批量内排列特征均值和方差来增强图像的形状信息。与最先进的研究相比,我们提出的混合模型在大型标准化MedMNIST-2D数据集上具有较低的计算复杂度,同时展示了其高鲁棒性和泛化能力。
2、Conclusion:
在本文中,我们介绍了一种名为MedViT的新型混合CNN-Transformer架构,用于医学图像分类。具体来说,我们通过使用稳健的组件将局部表征与全局特征相结合。此外,我们还设计了一种新颖的patch moment changer增强方法,为训练数据增添了丰富的多样性和亲和力。实验表明,我们的MedViT在标准的大规模二维生物医学数据集上达到了最先进的准确性和鲁棒性。我们希望我们的模型能够鼓励更多的研究人员,并为未来在现实医疗部署中的工作提供灵感。
3、Result:
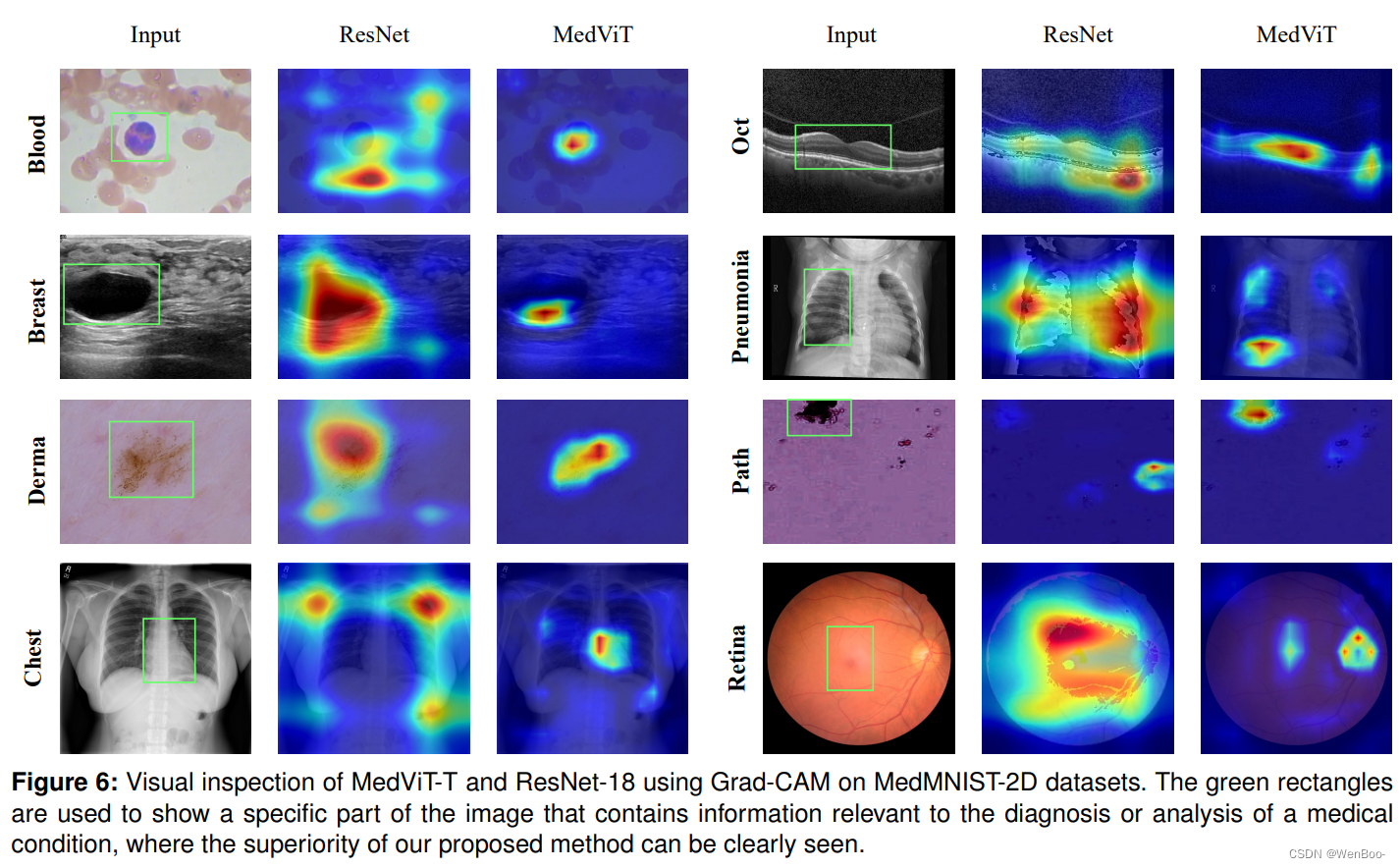

十、《MaskSAM: Towards Auto-prompt SAM with Mask Classification for Medical Image Segmentation》
1、Abstract:
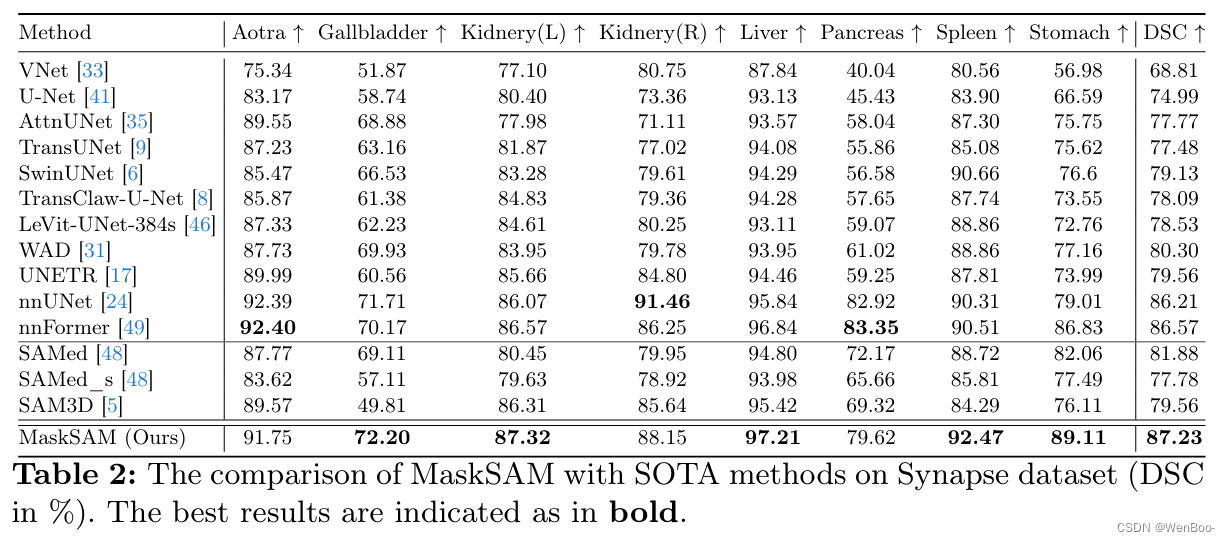
Segment Anything Model~(SAM)是一个基于图像分割的基础模型,它具有良好的zero-shot性能。然而,SAM在直接应用于医学图像分割任务时不起作用,因为SAM缺乏为预测的掩模预测语义标签的功能,并且需要提供额外的提示,例如点或框,以分割目标区域。同时,由于2D自然图像与3D医学图像之间存在着巨大的差距,因此SAM的性能对于医学图像分割任务来说并不理想。针对上述问题,提出了一种新的用于医学图像分割的无掩模分类的SAM自适应框架MaskSAM。我们设计了一个提示生成器,结合SAM中的图像编码器来生成一组辅助分类器标记,辅助二进制掩码和辅助包围盒。每对辅助掩码和框提示符可以解决额外提示符的需求,通过SAM的掩码解码器中的辅助分类器令牌和可学习的全局分类器令牌之和与类标签预测相关联,以解决语义标签的预测。同时,我们设计了一个用于图像嵌入的3D深度卷积适配器和一个用于提示嵌入的3D深度MLP适配器。我们将其中一个注入到图像编码器和掩码解码器中的每个Transformer块中,以使预训练的2D SAM模型能够提取3D信息并适应3D医学图像。我们的方法在AMOS 2022上实现了最先进的性能,90.52% Dice,与nnUNet相比提高了2.7%。我们的方法在ACDC上超过nnUNet 1.7%,在Synapse数据集上超过1.0%。
2、Conclusion:
在本文中,我们提出了一种针对医学图像分割的掩码分类无提示 SAM 适应框架,命名为 MaskSAM,该框架无需提供任何提示,即可将预训练的 SAM 模型从二维自然图像迁移到三维医学图像。我们通过在 SAM 的图像编码器中设计一个提示生成器,结合生成一组辅助分类器令牌、辅助二值掩码和辅助边界框。每对辅助掩码和框提示可以解决对额外提示的需求,并通过在 SAM 掩码解码器中的辅助分类器令牌和可学习的全局分类器令牌之和与类标签预测相关联,以解决语义标签的预测问题。通过将我们重新设计的 3D 深度卷积适配器(DConvAdapter)用于图像嵌入和 3D 深度 MLP 适配器(DMLPAdapter)用于提示嵌入插入到图像编码器和掩码解码器中的每个 Transformer 块中,我们的模型能够使预训练的 2D SAM 模型提取 3D 信息并适应 3D 医学图像。我们的方法在 AMOS2022 [27] 数据集上达到了最先进的性能,Dice 系数为 90.52%,比 nnUNet 提高了 2.7%。同时,我们的方法在 ACDC [3] 数据集上比 nnUNet 高出 1.7%,在 Synapse [29] 数据集上高出 1.0%。
3、Result:
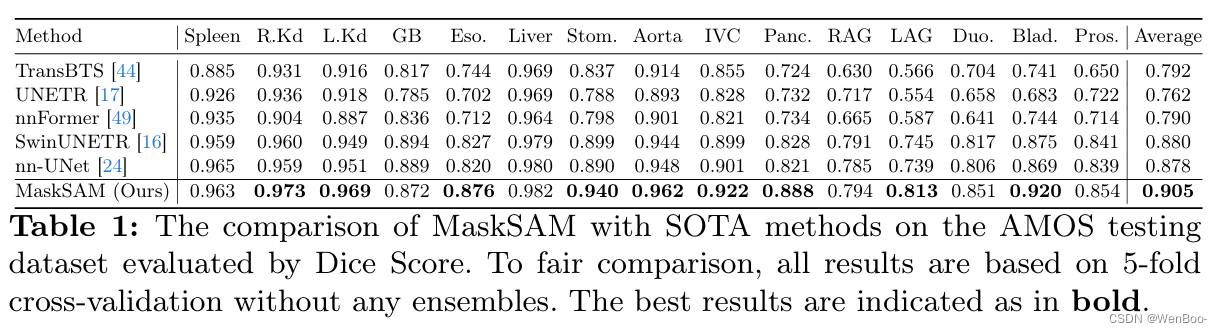
十一、《Towards Efficient Information Fusion: Concentric Dual Fusion Attention Based Multiple Instance Learning for Whole Slide Images》
1、Abstract:
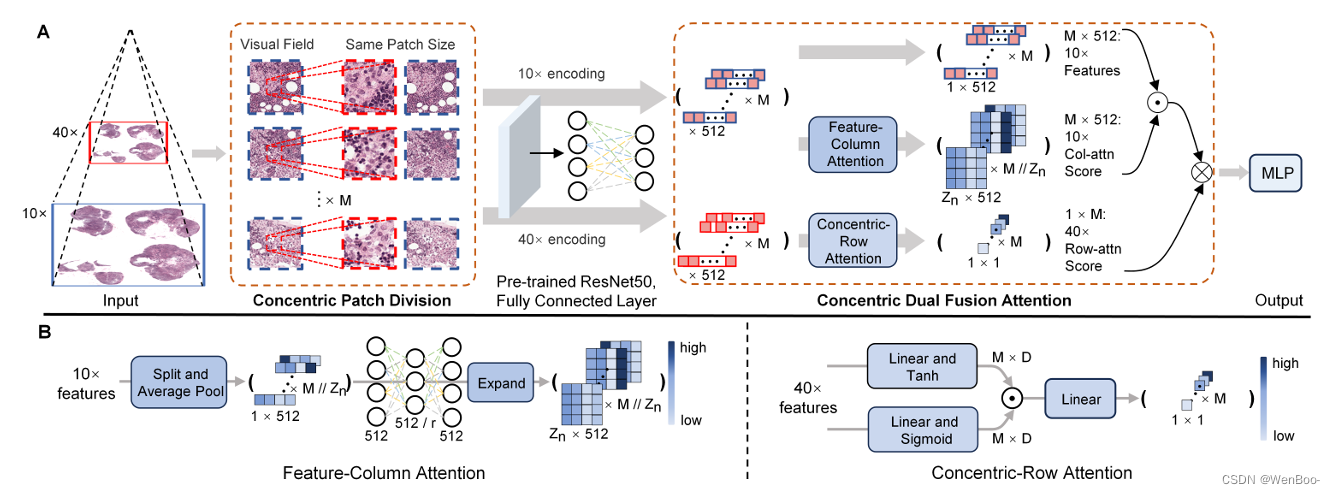
在数字病理学领域,多倍率多实例学习(multi-mag MIL)已证明在利用全扫描图像(WSIs)的层次结构以减少信息丢失和冗余数据方面非常有效。然而,当前的方法在弥合预训练模型与医学成像之间的领域差距方面存在不足,并且经常无法考虑不同倍率之间的空间关系。为了应对这些挑战,我们引入了同心双融合注意力-多实例学习(CDFA-MIL)框架,该框架创新性地使用同心块将点对区域特征注意力与点对点同心行注意力相结合。这种方法旨在有效地融合相关信息,增强特征表示,并为WSI分析提供更强大的相关性指导。
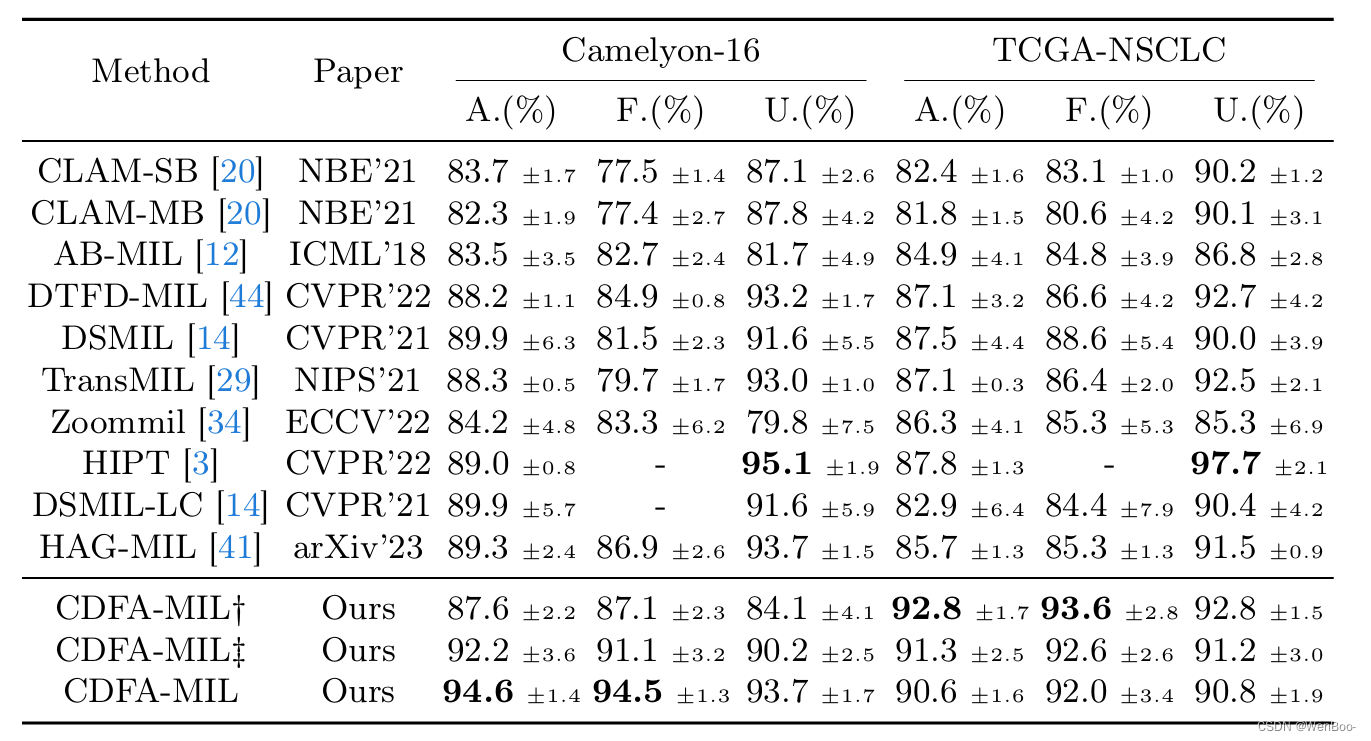
CDFA-MIL的独特之处在于它提供了一种强大的融合策略,从而实现了卓越的WSI识别性能。实际应用表明,它在准确率和F1分数方面显著超越了现有MIL方法,在诸如Camelyon16和TCGA-NSCLC等知名数据集上表现尤为出色。具体而言,CDFA-MIL在这些数据集上分别达到了93.7%的平均准确率和94.1%的F1分数,标志着对传统MIL方法的重大改进。

在文中对比了之前的MIL方法和作者提出的MIL方法:尽管传统的MIL方法使用不同的倍率,但它们仅通过简单的聚合器提取和聚合图像块特征。相比之下,我们的方法首先通过特征列注意力机制优化预训练模型提取的特征表示。随后,它利用同心块和同心行注意力机制的点对点关系,通过点乘的方式结合粗粒度和细粒度特征。
通过这种方式,CDFA-MIL框架不仅能够捕获不同倍率下的重要信息,还能有效地融合这些信息,从而提高WSI识别的准确性。这种融合策略使得CDFA-MIL在医学图像分析领域具有显著的优势,并为进一步的研究和应用提供了坚实的基础。
2、Conclusion:
在我们的研究中,我们引入了同心双融合注意力-多实例学习(CDFA-MIL)框架,这是一个用于全扫描图像(WSIs)弱监督分类的先进框架。CDFA-MIL有效地克服了融合相关信息时的挑战,解决了诸如特征表示不足以及融合过程中过度包含远距离图像块等问题。
我们的方法首先通过完整的同心块为每个高倍率图像块划定高度相关的区域。然后,我们基于通道相关性建模,采用点对区域特征列注意力机制,为特征点分配权重,从而增强跨领域差距的特征表示能力。此外,我们还整合了一个点对点同心行注意力机制,专门针对这些相关区域,以优化融合过程并关注相关图像块。
通过结合这两种注意力机制,CDFA-MIL能够更准确地捕获WSIs中的关键信息,提高分类的准确性和可靠性。这种创新性的框架为医学图像分析领域带来了新的可能性,并为未来的研究提供了有力的工具。
3、Result:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









