






一、《NearbyPatchCL: Leveraging Nearby Patches for Self-Supervised Patch-Level Multi-Class Classification in Whole-Slide Images》
1、Abstract:
全切片图像(WSI)分析在癌症诊断和治疗中起着至关重要的作用。在解决这一关键任务的需求时,自监督学习(SSL)方法已经成为一种宝贵的资源,利用它们的效率来规避对大量注释的需求,这对于部署监督方法来说既昂贵又耗时。然而,补丁式表示可能会表现出不稳定的性能,主要是由于类的不平衡所产生的补丁内的WSI选择。在本文中,我们介绍了邻近补丁对比学习(NearbyPatchCL),一种新的自监督学习方法,利用附近的补丁作为正样本和解耦的对比损失进行鲁棒的表示学习。我们的方法展示了一个有形的增强下游任务的性能,涉及补丁级多类分类。此外,我们策划了一个新的数据集,该数据集来自犬皮肤癌组织学的WSI,从而建立了一个严格评估斑块级多类分类方法的基准。密集的实验表明,我们的方法显着优于监督基线和国家的最先进的SSL方法的前1名的分类准确率为87.56%。我们的方法也实现了相当的结果,同时利用仅1%的标记数据,与其他方法的100%标记数据要求形成鲜明对比。
2、Conclusion:
本文提出了一种新的基于补丁级的多分类基准测试方法。使用SSL方法进行WSI分类。解决标记数据稀缺的问题数字病理图像中的不平衡数据集问题,我们的工作已经表明通过在SSL阶段利用附近的补丁作为阳性样本,提出的方法可以具有更鲁棒的表示,并在下游任务。此外,我们已经证明使用DCL损失可以有利于在非平衡数据集上进行训练时,使用对比方法。
在未来的工作中,我们的目标是将我们的方法扩展到其他医学成像领域。并探索其在其他下游任务中的应用。我们还计划进一步研究增强学习表示的可解释性的方法,并整合特定领域的知识以提高性能该模型在现实临床环境中的适用性。
3、Result:

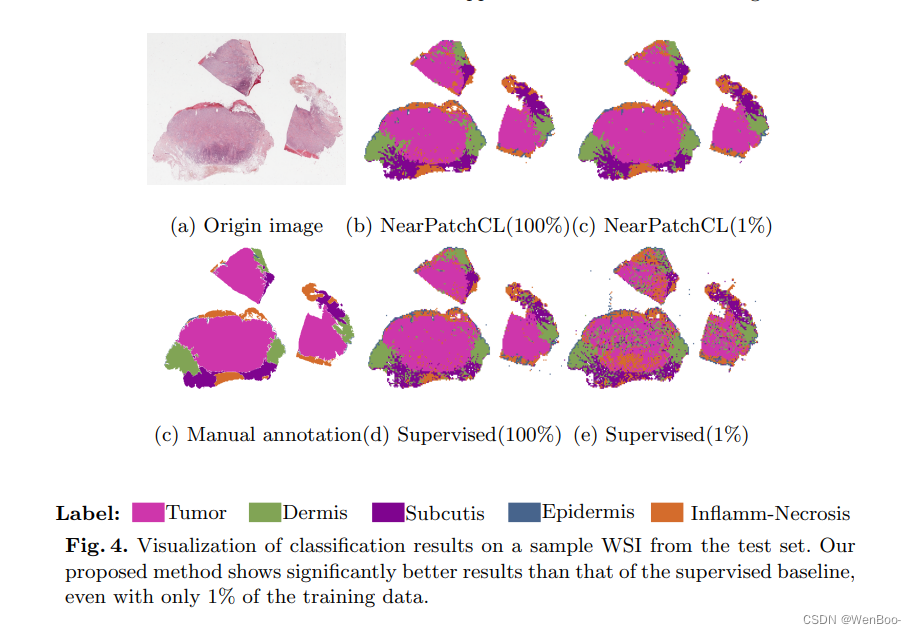
二、《CLASSMix: Adaptive stain separation-based contrastive learning with pseudo labeling for histopathological image classification》
1、Abstract:
组织学图像分类是医学图像分析中的一个重要方面。由于在模型训练中与标记数据相关联的高开销,已经提出了半监督学习方法来减轻对广泛标记数据集的需求。在这项工作中,我们提出了一个半监督分类任务的数字组织病理学苏木精和伊红(H&E)图像模型。我们将这种新模型称为具有自适应染色分离和混合的对比学习(CLASSMix)。我们的模型由两个主要部分组成:自适应染色分离的苏木精图像和伊红图像之间的对比学习,以及使用MixUp的伪标记。我们将我们的模型与来自我们机构和癌症基因组图谱计划(TCGA)的透明细胞肾细胞癌(ccRCC)数据集的其他最先进模型进行了比较。我们证明了我们的CLASSMix模型在两个数据集上都具有最佳性能。分析了模型中各部分的贡献。
2、Conclusion:
本文提出了一种新型的半监督分类模型CLASS-M,用于通过采用基于自适应染色分离的对立学习方法和使用MixUp的伪标签进行组织病理学图像分类。我们提供了新标注的犹他州ccRCC数据集和TCGA ccRCC数据集。对它们的实验表明,与其它最先进的模型相比,我们的CLASS-M模型始终达到了最佳分类结果。我们的模型展示了在训练中仅对约30个WSI进行粗略标注的情况下,在不同分辨率下进行准确补丁级分类的能力。我们的模型的代码也已公开。
理论上,半监督学习的优势在于尽管牺牲了自监督学习的便利性,但可以进行端到端的训练。自监督学习在最终训练中使用带有标签的数据冻结预训练编码器,缺乏对整个模型进行微调的灵活性。然而,在最终训练中解冻编码器会导致过拟合,因为不再有访问大量未标记数据集的权限,特别是在标签数据有限的情况下。
未来的工作可能涉及解决处理噪声标签的挑战。在我们的数据集中,有一小部分瓦片只包含血管,这使得标签不准确。一个能够容忍噪声标签的模型可能是一个有趣的研究方向。我们的方法也可以很容易地应用于其他类型的组织病理学图像,如免疫组织化学(IHC)染色图像。
3、Result:

三、《Dual Structure-Preserving Image Filterings for Semi-supervised Medical Image Segmentation》
1、Abstract:
半监督图像分割是近年来图像分割领域的研究热点。关键是如何在训练过程中利用未标记的图像。大多数方法在变化(例如,在图像和/或模型级中添加噪声/扰动或创建替代版本)。在大多数图像层次的变化中,医学图像往往具有先验结构信息,而这些信息尚未得到很好的挖掘。在本文中,我们提出了新的双重结构保持图像滤波(DSPIF)作为半监督医学图像分割的图像级变化。基于结构感知树图像表示中的连通滤波简化了图像,我们采用了双对比度不变的最大树和最小树表示。具体来说,我们提出了一种新的连接过滤,删除拓扑等价节点(即连接组件)没有兄弟姐妹的最大/最小树。这导致两个滤波图像保留拓扑关键结构。将这种双重结构保持的图像滤波应用于相互监督中,有利于半监督医学图像分割。在三个基准数据集上的大量实验结果表明,所提出的方法显着/一致优于一些国家的最先进的方法。
2、Conclusion:
我们提出了一种新的图像级变分方法,称为双结构保真图像滤波(DSPIF)半监督医学图像分割。明确地我们利用双最大树和最小树图像表示,并删除所有在图像中没有兄弟节点的节点。对应树。这相当于删除所有拓扑在保持拓扑关键性的同时,等效区域两个图像具有不同的外观同时具有与原始拓扑结构相同的拓扑结构形象将提出的DSPIF应用于相互监督的网络,可以减少其错误共识。对未标记图像的预测。这有助于缓解过度拟合噪声伪标签的确认偏差问题对未标记的图像进行分类,从而有效地提高了分割性能。广泛的实验结果在三个广泛使用的基准数据集上进行了演示所提出的方法显著/一致地优于最先进的方法。
3、Result:



四、《Contrastive Learning of Medical Visual Representations from Paired Images and Text》
(ps:Clip在该文章基础上进行提升)
1、Abstract:
学习医学图像(如X射线)的视觉表示是医学图像的核心。机器翻译技术已经取得了长足的进步,但它的进步却因缺乏人工注释而受到阻碍。现有工作通常依赖于微调从 ImageNet 预训练中转移的权重,由于图像特征的巨大差异或基于规则的分类器,这是次优的。从与医学图像配对的文本报告数据中提取标签,这是不准确且难以概括的。与此同时,最近的一些研究表明,从自然图像中进行的无监督对比学习,但我们发现这些方法有帮助由于医学图像的类间相似性很高,因此对其研究很少。我们提出了ConVIRT,一种通过利用无监督学习策略来学习医学视觉表示的替代方法自然发生的成对描述性文本。我们预训练医学图像的新方法通过双向对比目标,对成对文本数据进行编码两种模式与领域无关,不需要额外的专家输入。我们通过将预训练的权重转移到4个医学图像分类任务中来测试ConVIRT,2个zero-shot检索任务,并表明它导致的图像表示在大多数情况下都优于强baseline。值得注意的是,在所有4个分类任务中,我们的方法只需要10%的标注训练数据,ImageNet初始化需要100%的标注训练数据实现更好或可比性能的对手,展示优越的数据效率。
2、Conclusion:
我们提出了ConVIRT,这是一种从成对的描述性文本中学习医学视觉表征的无监督方法。我们的方法依赖于通过两者之间的双向目标将图像表征与成对的描述性文本进行对比在4个医学图像分类任务和2个图像检索任务中,ConVIRT优于其他强大的领域内初始化方法,并导致具有与 ImageNet 预训练相比,ConVIRT 能够实现在标记数据数量减少一个数量级的情况下,分类准确率保持不变。这对于数据稀疏性是一个重要问题的医疗保健领域来说尤其关键,ConVIRT中的创新跨模态预训练可以扩展到考虑其他我们希望ConVIRT继续激励未来的数据科学家们该工作更有效地利用多模态数据来理解医学图像。
3、Result:















 1584
1584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









