







程序内功篇七--查找与排序
一、查找
1、查找概念
设
记录表L=(R1 R2……Rn),其中Ri(l≤i≤n)为记录,对给定的某个值k,在表L中确定key=k的记录的过程,称为查找。
若
表L中存在一个记录Ri的key=k,记为Ri.key=k,则查找成功,返回该记录在表L中的序号i(或Ri 的地址),否则(查找失败)返回0(或空地址Null)。
2、平均查找长度
对
查找算法,主要分析其T(n)。查找过程是key的比较过程,时间主要耗费在各记录的key与给定k值的比较上。比较次数越多,算法效率越差(即T(n)量级越高),故用“比较次数”刻画算法的T(n)。
一般以“平均查找长度”来衡量T(n)。
平均查找长度ASL(Average Search Length):
对给定k,查找表L中记录比较次数的期望值(或平均值),即:

Pi为查找Ri的概率。等概率情况下Pi=1/n;Ci为查找Ri时key的比较次数(或查找次数)。
3、查找方法
(1)顺序查找
顺序表,是将表中记录(R1 R2……Rn)按其序号存储于一维数组空间,查找时遍历整个数组。
①记录Ri的类型描述如下:
typedef struct
{ keytype key; //记录key//
…… //记录其他项//
} Retype;
②顺序表类型描述如下:
#define maxn 1024 //表最大长度//
typedef struct
{ Retype data[maxn]; //顺序表空间//
int len; //当前表长,表空时len=0//
} sqlist;
说明:sqlist r,则(r.data[1],……,r.data[r.len])为记录表(R1……Rn), Ri.key为r.data[i].key, r.data[0]称为监视哨,为算法设计方便所设。
算法思路:
设给定值为k,在表(R1 R2……Rn)中,从Rn开始,查找key=k的记录。
int sqsearch(sqlist r, keytype k)
{ int i;
r.data[0].key = k; //k存入监视哨//
i = r.len; //取表长//
while(r.data[i].key != k) i--;
return (i);
}
③设Ci(1≤i≤n)为查找第i记录的key比较次数(或查找次数):
若r.data[n].key = k, Cn=1;
若r.data[n-1].key = k, Cn-1=2;
……
若r.data[i].key = k, Ci=n-i+1;
……
若r.data[1].key = k, C1=n
故ASL = O(n)。而查找失败时,查找次数等于n+l,同样为O(n)。
对
查找算法,若ASL=O(n),则效率是很低的,意味着查找某记录几乎要扫描整个表,当表长n很大时,会令人无法忍受。
(2)折半查找
对给定值k,逐步确定待查记录所在区间,每次将搜索空间减少一半(折半),直到查找成功或失败为止。
设两个游标low、high,分别指向当前待查找表的上界(表头)和下界(表尾)。mid指向中间元素。
例如:查找k=20的记录
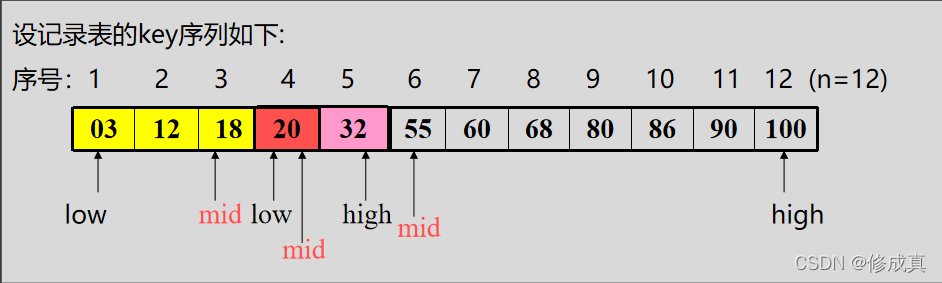
因此代码为:
int Binsearch(sqlist r, keytype k) //对有序表r折半查找的算法//
{ int low, high, mid; low = 1;high = r.len;
while (low <= high)
{ mid = (low+high) / 2;
if (k == r.data[mid].key) return (mid);
if (k < r.data[mid].key) high = mid-1;
else low = mid+1;
}
return(0);
}
注:一定要在
有序的情况下才能进行折半查找。
(3)分块查找
设记录表长为n,将表的n个记录分成b=n/s个块,每块s个记录(最后一块记录数可以少于s个),即:
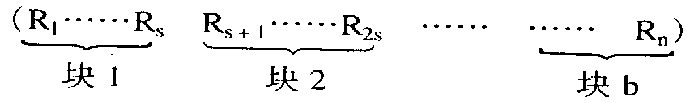
且表分块有序,即第i(1≤i≤b-1)块所有记录的key小于第i+1块中记录的key,但块内记录可以无序。
构建方法:
- ①
建立索引 - ②每块
对应一索引项: - ③其中
kmax为该块内记录的最大key;link为该块第一记录的序号(或指针)。

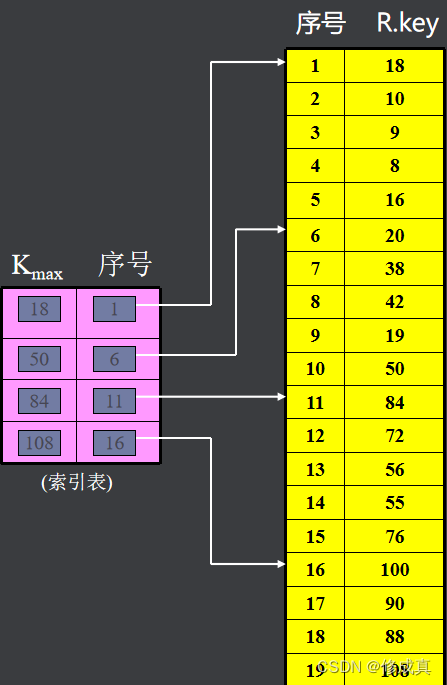
例如:设表长n=19,取s=5,b=19/5= 4,
分块索引查找分两步进行:
(1)由索引表确定待查找记录所在的块;
(2)在块内顺序查找。
如查找k=19的记录
索引表是按照kmax有序的,可对其折半查找。而块内按顺序方法查找。
(4)Hash表查找(重点)
(1)哈希查找的来由
理想的查找方法是:对
给定的k,不经任何比较便能获取所需的记录,其查找的时间复杂度为常数级O( C )。
这就要求在建立记录表的时候,确定记录的key与其存储地址之间的关系f,即使key与记录的存放地址H相对应:
当要查找key=k的记录时,通过关系f就可得到相应记录的地址而获取记录,从而免去了key的比较过程。
这个关系f就是所谓的Hash函数(或称散列函数、杂凑函数),记H(key)。
它实际上是一个地址映象函数,其自变量为记录的key,函数值为记录的存储地址(或称Hash地址)。

注:
不同的key可能得到同一个Hash地址,即当keyl≠key2时,可能有H(key1)=H(key2),此时称key1和key2为同义词。这种现象称为“冲突”或“碰撞”,因为一个数据单位只可存放一条记录。- 一般,选取Hash函数只能做到使冲突尽可能少,却
不能完全避免。这就要求在出现冲突之后,寻求适当的方法来解决冲突记录的存放问题。
选取(或构造)Hash函数的方法很多,原则是尽可能将记录均匀分布,以减少冲突现象的发生。以下介绍几种常用的构造方法。
- 直接地址法
- 平方取中法
- 叠加法
- 保留除数法
- 随机函数法
(2)保留除数法
又称
质数除余法,设Hash表空间长度为m,选取一个不大于m的最大质数p,令:H(key)=key%p
设记录的key集合k={28,35,63,77,105……},
若选取p=21=3*7(包括质数因子7),有:
key:28 35 63 77 105 ……
H(key)=key%21: 7 14 0 14 0 ……
使得包含质数因子7的key都可能被映象到相同的单元,冲突现象严重。
若取p=l9(质数),同样对上面给定的key集合k,有:
key:28 35 63 77 105
H(key)=key%19: 9 16 6 1 10
H(key)的随机度就好多了。
(3)处理冲突的方法
处理冲突的方法一般为:在
地址j的前面或后面找一个空闲单元存放冲突的记录,或将相互冲突的值记录拉成链表。
在处理冲突的过程中,可能发生一连串的冲突现象,
即可能得到一个地址序列H1、H2……Hn,Hi∈[0,m-l]。
H1是冲突时选取的下一地址,而H1中可能己有记录,
又设法得到下一地址H2……直到某个Hn不发生冲突为止。
这种现象称为“聚积”,它严重影响了Hash表的查找效率。
一个因素是
表的装填因子α,α=n/m,其中m为表长,n为表中记录个数。一般α在0.7~0.8之间,使表保持一定的空闲余量,以减少冲突和聚积现象。
(4)开放地址法
H(key)=key%13

(5)链地址法
发生冲突时,将
各冲突记录链在一起,即同义词的记录存于同一链表。
设H(key)取值范围(值域)为[0,m-l],
建立头指针向量HP[m],
HP[i](0≤i≤m-l)初值为空。
设H(key)=key%13
k={ 23,34,14,38,46,
16,68,15,07,31,26 }

链地址法解决冲突的优点:
无聚积现象;删除表中记录容易实现。
(5)Hash表的程序实行
这里我们选择使用
保留除数法构造函数,使用链地址法解决冲突问题
(1)结构体定义
#define DEBUG 1
#define N 14
typedef int data_t;
typedef struct node //哈希表结点定义
{
data_t value; //存入的数据
data_t key; //表中的位置,key = value % N
struct node *next; //下一结点的指针
}listhash,*linkhash;
typedef struct //哈希表定义
{
listhash a[N];
}hash;
(2)哈希表的创建
/**
* @description:哈希表的创建
* @param {*}
* @return {哈希表的地址}
*/
hash *create_hash()
{
hash *HT = (hash *)malloc(sizeof(hash)); //为表开辟空间
if(HT == NULL)
{
#if DEBUG
printf("hash create error!\n");
#endif
return 0;
}
memset(HT, 0, sizeof(hash)); //表中清0
return HT;
}
(3)数据存入进哈希表
/**
* @description: 数据存入进哈希表
* @param {hash} *HT-哈希表指针
* @param {data_t} value-存入的数据
* @return {0-函数失败,1-函数成功}
*/
int Add_hash(hash *HT, data_t value)
{
linkhash p,q;
if(HT == NULL)
{
#if DEBUG
printf("HT is NULL!\n");
#endif
return 0;
}
if((p = (linkhash)malloc(sizeof(listhash))) == NULL) //结点开辟空间
{
#if DEBUG
printf("node create error!\n");
#endif
return 0;
}
p->value = value; //结点存入数据
p->key = value % N;
p->next = NULL;
q = &(HT->a[p->key]);
while(q->next != NULL && q->next->value < p->value) //寻找放入哈希表的位置
q = q->next;
p->next = q->next; //放入哈希表
q->next = p;
return 1;
}
(4)数据查询
/**
* @description: 数据查询
* @param {hash} *HT-哈希表指针
* @param {data_t} value-查询的数据
* @return {返回数据所在哈希表的位置}
*/
linkhash query_hash(hash *HT, data_t value)
{
int key = value % N;
linkhash p;
if(HT == NULL)
{
#if DEBUG
printf("HT is NULL!\n");
#endif
return 0;
}
p = &(HT->a[key]);
while(p)
{
if(p->value == value)
return p;
p = p->next;
}
return NULL;
}
二、排序
1、排序的定义
(1)稳定排序和非稳定排序
设文件
f=(R1……Ri……Rj……Rn)中记录Ri、Rj(i≠j,i、j=1……n)的key相等,即Ki=Kj。
若在排序前Ri领先于Rj,排序后Ri仍领先于Rj,则称这种排序是稳定的,其含义是它没有破坏原本已有序的次序。反之就是非稳定排序。
(2)内排序和外排序
若
待排文件f在计算机的内存储器中,且排序过程也在内存中进行,称这种排序为内排序。`
若
排序中的文件存入外存储器,排序过程借助于内外存数据交换(或归并)来完成,则称这种排序为外排序。
2、排序的方法
各种内排序方法可归纳为以下五类:
(1)插入排序
(2)交换排序
(3)选择排序
(4)归并排序
(5)其他
网上方法太多太多了,这里主要给出效率较高的选择排序法的实现。
3、快速排序法
设记录的key集合k={50,36,66,76,36,12,25,95},每次以集合中第一个key为基准的快速排序过程如下:
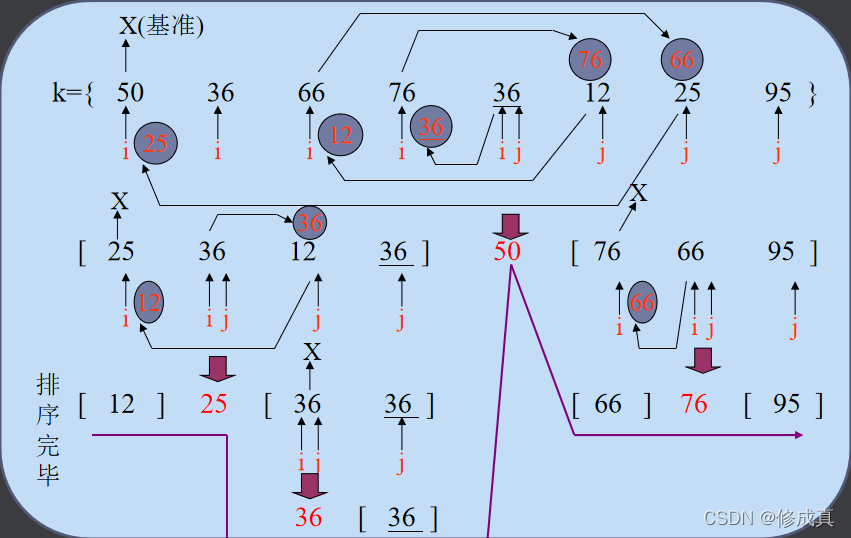
实现程序为:
#include<stdio.h>
#include<stdlib.h>
#define N 15
int query_sort(int *a, int low, int high);
int sort(int *a, int low, int high);
int compare(const void *a, const void *b);
int main(int argc,const char *argv[])
{
int i,a[N] = {0};
srandom(10);
for(i = 0; i < N; i++)
a[i] = random() % 100;
for(i = 0; i < N; i++)
printf("%d ",a[i]);
putchar('\n');
//qsort(a, N, sizeof(int), compare); //C库自带的排序函数,也是用的哈希表排序
query_sort(a, 0, N-1);
for(i = 0; i < N; i++)
printf("%d ",a[i]);
putchar('\n');
return 0;
}
/**
* @description: 一次排序确定中性值
* @param {int} *a -要排序的数组头指针
* @param {int} low -低位
* @param {int} high -高位
* @return {*} low -调整后的中性值位置
*/
int sort(int *a, int low, int high)
{
int temp;
if(a == NULL)
{
printf("array is NULL!\n");
return 0;
}
temp = a[low];
while(low < high)
{
while(low < high)
{
if(temp > a[high])
{
a[low] = a[high];
break;
}
high--;
}
while(low < high)
{
if(temp < a[low])
{
a[high] = a[low];
break;
}
low++;
}
}
a[low] = temp;
return low;
}
/**
* @description: 哈希排序
* @param {int} *a -数组头指针
* @param {int} low -低位
* @param {int} high -高位
* @return {*} -1-函数失败,0或1-函数成功
*/
int query_sort(int *a, int low, int high)
{
int r = 0;
if(a == NULL)
{
printf("array is NULL!\n");
return -1;
}
if(low >= high)
return 0;
r = sort(a, low, high);
query_sort(a, low, r-1); //比中性值小的
query_sort(a, r+1, high); //比中性值大的
return 1;
}
//比较函数
int compare(const void *a, const void *b)
{
return *(const int *)a - *(const int *)b;
}
到这里就结束啦!
最后还是给出哈希表与选择排序的实现程序的链接:
哈希表与选择排序C程序实现

















 2688
2688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











