







 本文详细介绍了PyTorch中数据索引的基本操作,包括基本索引、布尔索引和整数数组索引,以及它们在深度学习中的应用,特别是在LeNet模型训练MNIST数据集时的数据预处理、数据加载和模型训练过程。
本文详细介绍了PyTorch中数据索引的基本操作,包括基本索引、布尔索引和整数数组索引,以及它们在深度学习中的应用,特别是在LeNet模型训练MNIST数据集时的数据预处理、数据加载和模型训练过程。
pytorch中的数据索引
在PyTorch中,数据索引是指在处理张量(Tensor)时访问或操作特定元素的过程。索引在数据处理和深度学习中是非常常见且重要的操作,它允许我们以各种方式访问数据集中的元素,执行数据的切片、提取、过滤等操作。
基本索引方法
在PyTorch中,数据索引的基本方法类似于Python中的列表索引。可以通过使用方括号和索引号来访问张量中的特定元素或子集。
import torch
# 创建一个张量
tensor = torch.tensor([1, 2, 3, 4, 5])
# 访问单个元素
print(tensor[0]) # 输出:1
# 切片操作
print(tensor[1:4]) # 输出:tensor([2, 3, 4])
# 修改元素的值
tensor[0] = 10
print(tensor) # 输出:tensor([10, 2, 3, 4, 5])
- 运行结果

高级索引方法
除了基本的索引方法外,PyTorch还支持一些高级的索引技巧,例如使用布尔索引、使用整数数组索引等。
布尔索引
使用布尔索引可以根据条件获取张量中满足条件的元素。
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
# 使用布尔索引获取大于2的元素
print(tensor[tensor > 2]) # 输出:tensor([3, 4, 5])
- 运行结果

使用整数数组索引
可以使用整数数组来获取张量中指定位置的元素。
import torch
tensor = torch.tensor([1, 2, 3, 4, 5])
# 使用整数数组索引获取指定位置的元素
indices = torch.tensor([0, 2, 4])
print(tensor[indices]) # 输出:tensor([1, 3, 5])
- 运行结果

应用场景
数据索引在深度学习中有许多应用场景,包括数据集加载、数据增强、数据筛选等。在训练神经网络时,经常需要对数据进行批处理,数据索引操作可以帮助我们有效地实现批处理操作。
实现了一个基于LeNet架构的简单神经网络对MNIST数据集进行训练和测试的过程。其中的关键步骤包括:
- 数据预处理:将图像转换为张量,并进行标准化处理。
- 创建数据加载器:用于批量加载训练和测试数据。
- 定义神经网络模型:LeNet模型包括卷积层、池化层和全连接层。
- 设置优化器和损失函数:使用随机梯度下降优化器和交叉熵损失函数。
- 训练模型:对训练集进行迭代训练。
- 测试模型:在测试集上评估模型性能。
这里用的数据集是:MNIST(Modified National Institute of Standards and Technology)数据集,它是一个常用的手写数字数据集,包含了大量的手写数字图片和对应的标签。
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 设置随机种子,以确保结果的可重复性
torch.manual_seed(0)
# 定义数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.1307,), (0.3081,)) # 标准化图像
])
# 加载MNIST数据集
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform) # 训练数据集
test_dataset = datasets.MNIST('data', train=False, download=True, transform=transform) # 测试数据集
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 训练数据加载器
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False) # 测试数据加载器
# 定义神经网络模型(LeNet)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 20, 5, 1) # 第一个卷积层
self.conv2 = torch.nn.Conv2d(20, 50, 5, 1) # 第二个卷积层
self.fc1 = torch.nn.Linear(4*4*50, 500) # 第一个全连接层
self.fc2 = torch.nn.Linear(500, 10) # 第二个全连接层(输出层)
def forward(self, x):
x = torch.nn.functional.relu(self.conv1(x)) # 第一个卷积层使用ReLU激活函数
x = torch.nn.functional.max_pool2d(x, 2, 2) # 最大池化层
x = torch.nn.functional.relu(self.conv2(x)) # 第二个卷积层使用ReLU激活函数
x = torch.nn.functional.max_pool2d(x, 2, 2) # 最大池化层
x = x.view(-1, 4*4*50) # 将特征图展平
x = torch.nn.functional.relu(self.fc1(x)) # 第一个全连接层使用ReLU激活函数
x = self.fc2(x) # 输出层
return torch.nn.functional.log_softmax(x, dim=1) # 使用log_softmax作为输出
# 创建神经网络模型实例
model = Net()
# 定义优化器和损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 使用随机梯度下降优化器
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失函数
# 训练模型
def train(epoch):
model.train() # 设置模型为训练模式
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad() # 清除梯度
output = model(data) # 进行前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
if batch_idx % 100 == 0:
print('训练 Epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 测试模型
def test():
model.eval() # 设置模型为评估模式
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\n测试集: 平均损失: {:.4f}, 准确率: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
# 进行模型训练和测试
for epoch in range(1, 11):
train(epoch) # 训练模型
test() # 测试模型
- 运行结果如下

训练过程:代码通过迭代训练集数据,每次迭代称为一个Epoch(一个完整的训练周期)。在每个Epoch中,训练集被分成多个批次(batch),每个批次包含多个样本。每个批次的大小为64。代码中的训练过程会迭代整个训练集,并对模型进行更新。
损失值(Loss):训练过程中打印了每个Epoch的损失值。损失值表示模型预测结果与实际标签之间的差异程度,越小表示模型的预测结果与实际值越接近。
测试集评估:在每个Epoch训练完成后,代码对测试集进行评估。测试集的损失值和准确率被打印出来。损失值和训练集中的损失值类似,准确率表示模型在测试集上的分类正确率。
准确率(Accuracy):准确率是模型在测试集上的分类正确率,通常以百分比表示。例如,"准确率: 9732/10000 (97%)"表示在10000个测试样本中,有9732个被正确分类。
Epochs:这段运行结果展示了模型训练了多个Epoch。随着Epoch的增加,模型的损失值通常会逐渐减小,而准确率会逐渐提高,这表明模型正在不断优化,并且逐渐学习到数据集的特征。
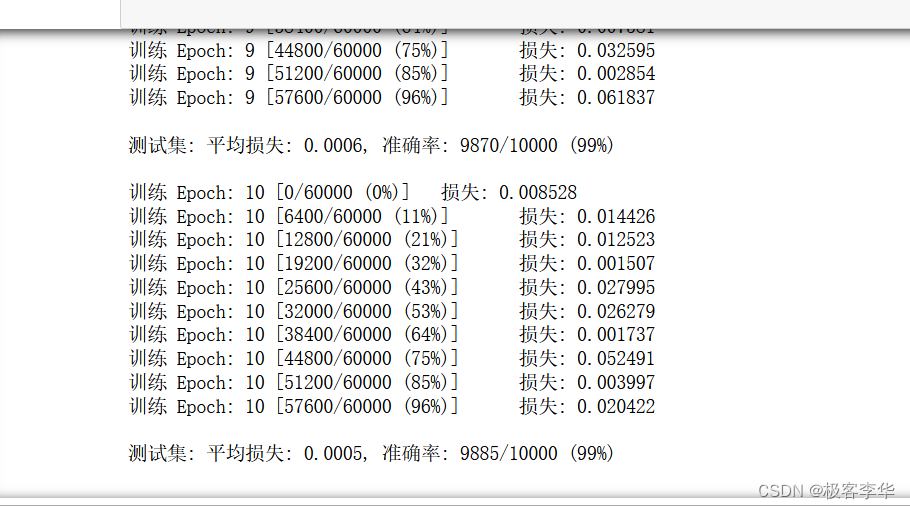
- 最后的训练结果说明了
训练损失下降:随着训练的进行,每个 Epoch 的训练损失都在逐渐下降。这表明模型在学习过程中逐渐减小了预测值与实际值之间的差异,即模型在训练数据上的拟合效果逐步改善。
测试准确率提高:测试集上的准确率在训练的不同阶段也逐步提高,从 97% 到 99%。这表明模型在未见过的数据上的预测能力逐步增强,具有了更好的泛化能力。
测试损失下降:与测试准确率提高相对应,测试集上的平均损失也在不断减小,从 0.0014 降到 0.0005。这说明模型的预测结果与真实标签之间的差异在逐步减小。
稳定性:在训练的后期阶段(如第 10 个 Epoch),模型的表现相对稳定。训练损失和测试损失均保持在较低水平,测试准确率也在高水平维持。

















 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











