







针对不平衡的分类问题,比如类别1有10个,类别2有1000个的情况,可以使用该技术。
from imblearn.over_sampling import KMeansSMOTE
from imblearn.combine import SMOTEENN
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import seaborn as sns
# 创建一个示例不平衡的数据集
# n_classes=2: 指定了两个类别。
# class_sep=2: 控制了类别之间分离的程度。较大的值将导致类别更加分离。
# weights=[0.1, 0.9]: 控制了每个类别的样本权重,这里设置为不平衡的权重,即第一个类别占总样本数的10%,第二个类别占90%。
# n_informative=2: 指定了有信息特征的数量。
# n_redundant=1: 指定了冗余特征的数量。
# n_features=20: 总共有20个特征。
# n_clusters_per_class=1: 每个类别中有一个簇,这有助于生成相对简单的数据结构。
# n_samples=1000: 总共生成1000个样本。
# random_state=42: 设置了随机数生成器的种子,以确保可以复现结果。
X, y = make_classification(n_classes=2, class_sep=2, weights=[0.1, 0.9],
n_informative=2, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=42)
# 使用 K-means SMOTE 进行过采样
# sampling_strategy='auto'是对少数类别的样本过采样,比如上面生成的数据集,类别y=1有900个,y=0有100个,则过采样后y=1和y=0都有900个
# 也可以设置sampling_strategy=0.6,即生成的合成样本数是少数类样本数的 60%
kmeans_smote = KMeansSMOTE(sampling_strategy='auto', random_state=42)
X_resampled, y_resampled = kmeans_smote.fit_resample(X, y)
# # 使用 SMOTE-ENN 进行过采样和清洗
# # 由于SMOTE-ENN返回的结果是Pandas DataFrame,因此在绘制散点图时,使用iloc选择DataFrame的列
# smote_enn = SMOTEENN(random_state=42, n_neighbors=3)
# X_resampled, y_resampled = smote_enn.fit_resample(X, y)
# 绘制原始和过采样后的数据分布(使用散点图)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
# 选取X的前两个特征作散点图(可能用了无关特征,也可能用了相关特征)
scatter_original = plt.scatter(X[:, 0], X[:, 1], c=y, cmap='Set1', edgecolor='k', s=20, label='Class 0/1')
plt.title('Original Data')
plt.legend(handles=scatter_original.legend_elements()[0], title='Classes')
plt.subplot(1, 2, 2)
scatter_resampled = plt.scatter(X_resampled[:, 0], X_resampled[:, 1], c=y_resampled, cmap='Set1', edgecolor='k', s=20,
label='Class 0/1')
plt.title('K-means SMOTE Resampled Data')
plt.legend(handles=scatter_resampled.legend_elements()[0], title='Classes')
plt.show()
下图是处理前后的对比
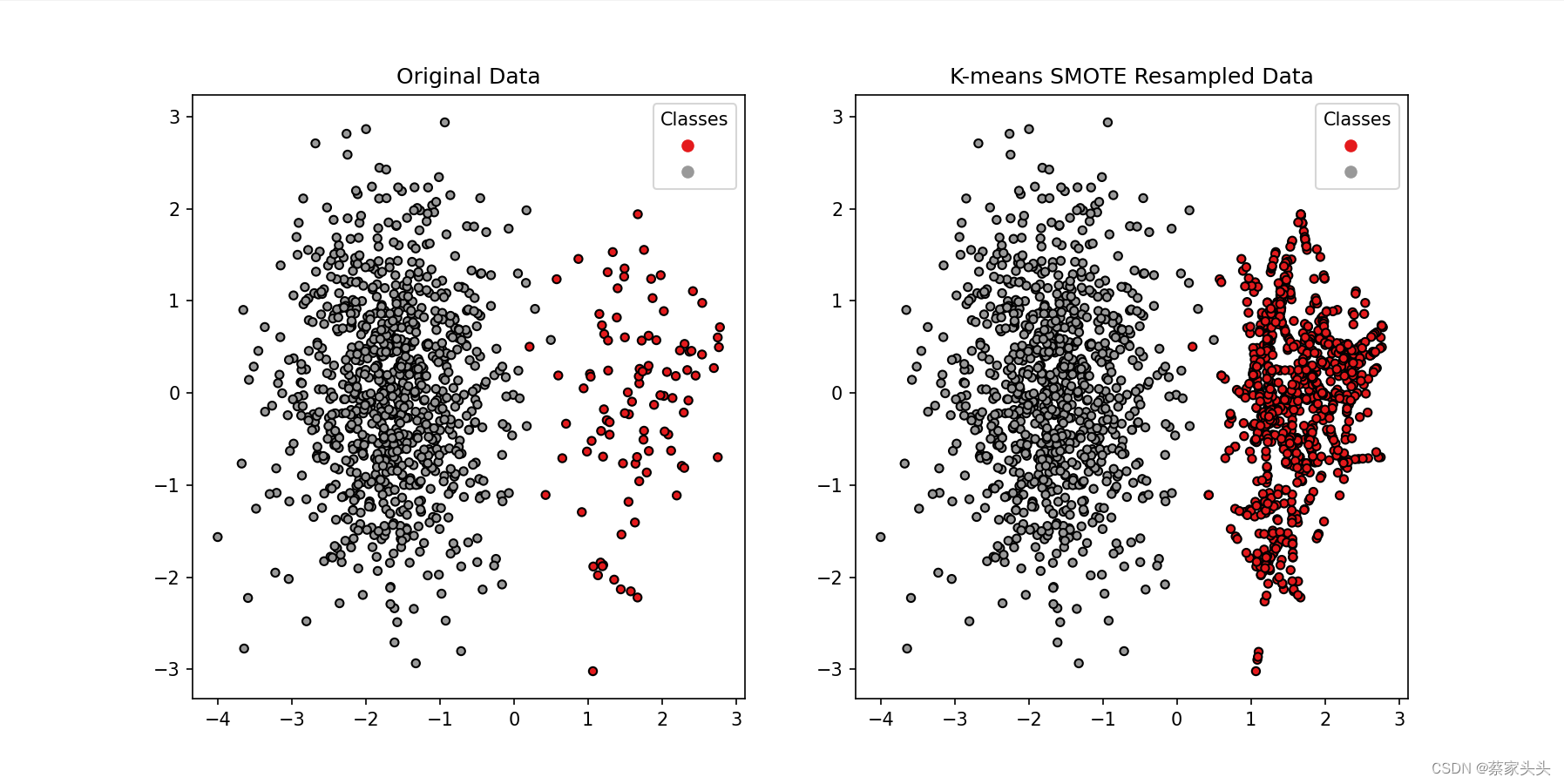
除了SMOTE,还有其他一些用于处理不平衡数据集的方法。以下是对这些常用技术的归纳:
SMOTE (Synthetic Minority Over-sampling Technique):
SMOTE 通过在特征空间中插入新的合成样本来平衡类别。这些新样本是通过对少数类样本之间的特征进行插值得到的。
Random Over-sampling:
随机过采样是通过从少数类中随机选择样本来创建副本,以增加少数类的样本数量。
Random Under-sampling:
随机欠采样是通过从多数类中随机删除样本来减少多数类的样本数量。
SMOTE-ENN (SMOTE combined with Edited Nearest Neighbors):
SMOTE-ENN 结合了 SMOTE 和 Edited Nearest Neighbors(ENN)。首先,使用 SMOTE 进行过采样,然后使用 ENN 进行欠采样,去除可能的噪声和重复样本。
ADASYN (Adaptive Synthetic Sampling):
ADASYN 根据每个样本的密度来生成合成样本,更关注密度较低的区域。
Tomek Links:
Tomek Links 是一种欠采样方法,通过去除一对类别之间的最近邻中的多数类样本和少数类样本来进行样本删除。
SMOTE-Tomek:
SMOTE-Tomek 结合了 SMOTE 和 Tomek Links,首先使用 SMOTE 进行过采样,然后使用 Tomek Links 进行欠采样。
Cluster-Based Over-sampling:
基于聚类的过采样方法,例如 Cluster SMOTE,通过在每个聚类中进行过采样来生成合成样本。

















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









