







双聚类算法概念
双聚类算法(Biclustering algorithm)是一种能够同时对数据集中的行和列进行聚类的算法。与传统的单一聚类算法不同,双聚类算法能够发现同时具有相似性的数据子集,这些子集在数据集中既可以是连续的行和列,也可以是不连续的行和列。因此,双聚类算法可以处理各种类型的数据,包括文本、图像、基因表达等。
双聚类算法是一种无监督学习方法,它的目标是将数据集分成多个双聚类子集,其中每个子集包含一组相似的行和一组相似的列。这些子集通常被称为双聚类或联合聚类。双聚类算法可以通过最小化一个损失函数来实现聚类过程,这个损失函数通常衡量了子集内部的相似度和子集之间的差异度。
双聚类算法有许多不同的形式,包括基于贪心算法的双向聚类、基于矩阵分解的双因子分解、基于模型的隐含狄利克雷分布双聚类等。每种算法都有其特定的优缺点和适用范围,需要根据具体数据和应用场景选择合适的算法。
在scikit-learn官网上有如下介绍:
算法采用不同的方式给双向簇分配行列,这导致了不同的双向聚类结构。当将行和列划分为区块时,将出现块对角或棋盘结构。
如果每一行和每一列恰好属于一个二元组,则重新排列数据矩阵的行和列将显示对角线上的二元组。这是此结构的示例,此结构的双向簇具有比其他行列更高的平均值:
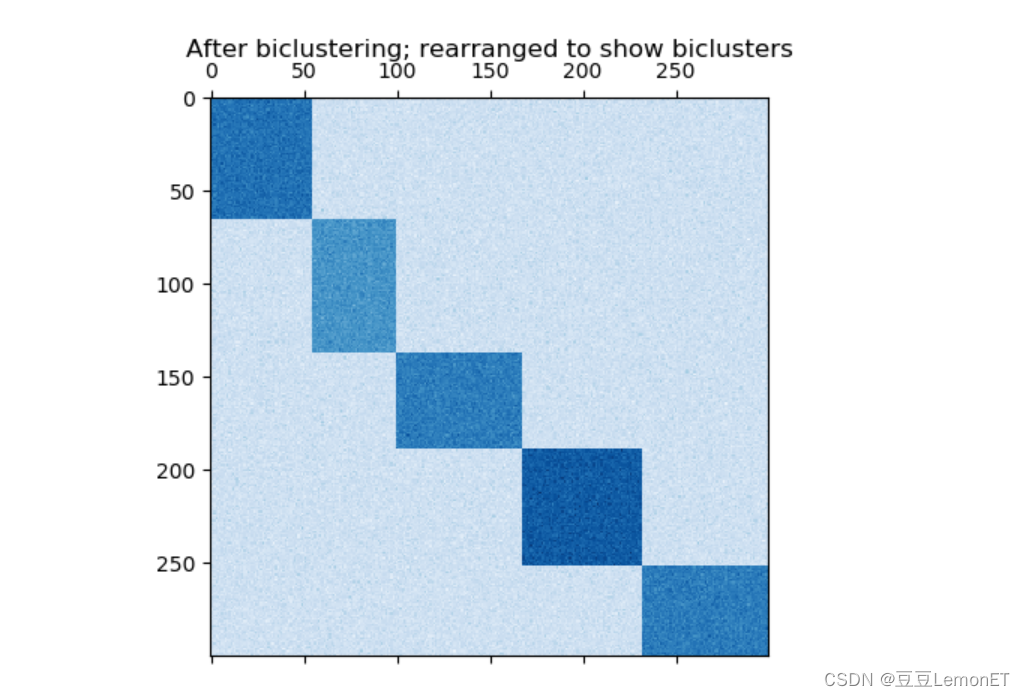
通过分隔行和列形成的双向簇的示例
在棋盘结构的例子中,每一行属于所有的列簇,每一列属于所有的行簇。下面是这种结构的一个例子,每个双向簇内的值差异较小:
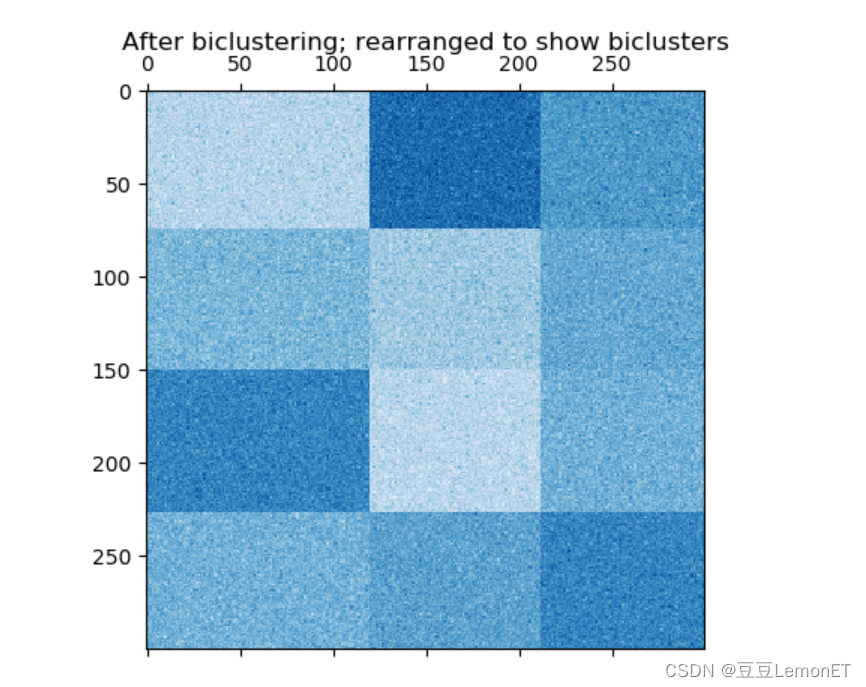
常见的双聚类算法
常见的双聚类算法包括以下几种:
-
Spectral Coclustering(谱双聚类):
谱双聚类是一种基于谱聚类的方法,它将数据矩阵转换为图结构,并利用图分割的方法进行聚类。该算法通过优化一个目标函数来寻找最优的双聚类结果。 -
Plaid Model(方格模型):
方格模型是一种基于概率模型的双聚类算法,它假设数据矩阵可以由多个双聚类组成,并通过最大似然估计来求解模型参数,从而得到最优的双聚类结果。 -
BiMax(双向最大相似度):
BiMax算法是一种基于贪心策略的双聚类算法,它通过不断地选择具有最大相似度的行和列来构建双聚类。该算法具有简单高效的特点,适用于大规模数据集。 -
Cheng and Church Algorithm(程和Church算法):
程和Church算法是一种基于模式匹配的双聚类算法,它通过比较数据矩阵中的行和列之间的相似性来寻找双聚类。该算法可以处理不完全数据和噪声数据。 -
xMotif(扩展Motif):
xMotif算法是一种基于模式发现的双聚类算法,它通过寻找数据矩阵中的子矩阵来进行聚类。该算法可以发现具有相似性的局部结构。
这些双聚类算法各有特点,适用于不同类型的数据和任务。在选择算法时,需要考虑数据的特征、算法的复杂度和效果等因素,并根据实际情况进行选择。
Spectral Coclustering(谱双聚类)
此示例演示如何使用谱协聚类算法(pectral Co-Clustering algorithm)生成数据集和双光泽数据集。
数据集是使用 make biluster 函数生成的,该函数创建一个小值矩阵和具有较大值的集群。然后对行和列进行洗牌,并将其传递给谱协聚类算法。重新排列洗牌矩阵,使集群连续显示,该算法明确的表明地找到了集群,
# _*_ coding : utf-8 _*_
# @Time: 2024/1/17 18:16
# @Author : doudou
# @File : test1
# @Project : test代码
print(__doc__)
# Author: Kemal Eren <kemal@kemaleren.com>
# License: BSD 3 clause
import numpy as np # 导入numpy库,用于数值计算
from matplotlib import pyplot as plt # 导入matplotlib库中的pyplot模块,用于绘图
from sklearn.datasets import make_biclusters # 导入sklearn库中的datasets模块,用于生成合成数据集
from sklearn.cluster import SpectralCoclustering # 导入sklearn库中的cluster模块的SpectralCoclustering类,用于实现谱双聚类算法
from sklearn.metrics import consensus_score # 导入sklearn库中的metrics模块,用于计算聚类结果的一致性分数
# 生成一个具有5个双聚类的合成数据集,shape参数指定数据集的形状,n_clusters参数指定双聚类的数量,noise参数指定噪声程度
data, rows, columns = make_biclusters(
shape=(300, 300), n_clusters=5, noise=5,
shuffle=False, random_state=0)
plt.matshow(data, cmap=plt.cm.Blues) # 绘制热图,表示原始数据集
plt.title("Original dataset")
# 洗牌操作,将数据集的行和列进行随机重排
rng = np.random.RandomState(0)
row_idx = rng.permutation(data.shape[0])
col_idx = rng.permutation(data.shape[1])
data = data[row_idx][:, col_idx]
plt.matshow(data, cmap=plt.cm.Blues) # 绘制热图,表示洗牌后的数据集
plt.title("Shuffled dataset")
model = SpectralCoclustering(n_clusters=5, random_state=0) # 创建SpectralCoclustering对象,并设置聚类数量和随机种子
model.fit(data) # 对洗牌后的数据集进行双聚类
score = consensus_score(model.biclusters_,
(rows[:, row_idx], columns[:, col_idx])) # 计算聚类结果的一致性分数
print("consensus score: {:.3f}".format(score)) # 打印聚类结果的一致性分数
fit_data = data[np.argsort(model.row_labels_)] # 根据行标签对双聚类结果进行重新排序
fit_data = fit_data[:, np.argsort(model.column_labels_)] # 根据列标签对双聚类结果进行重新排序
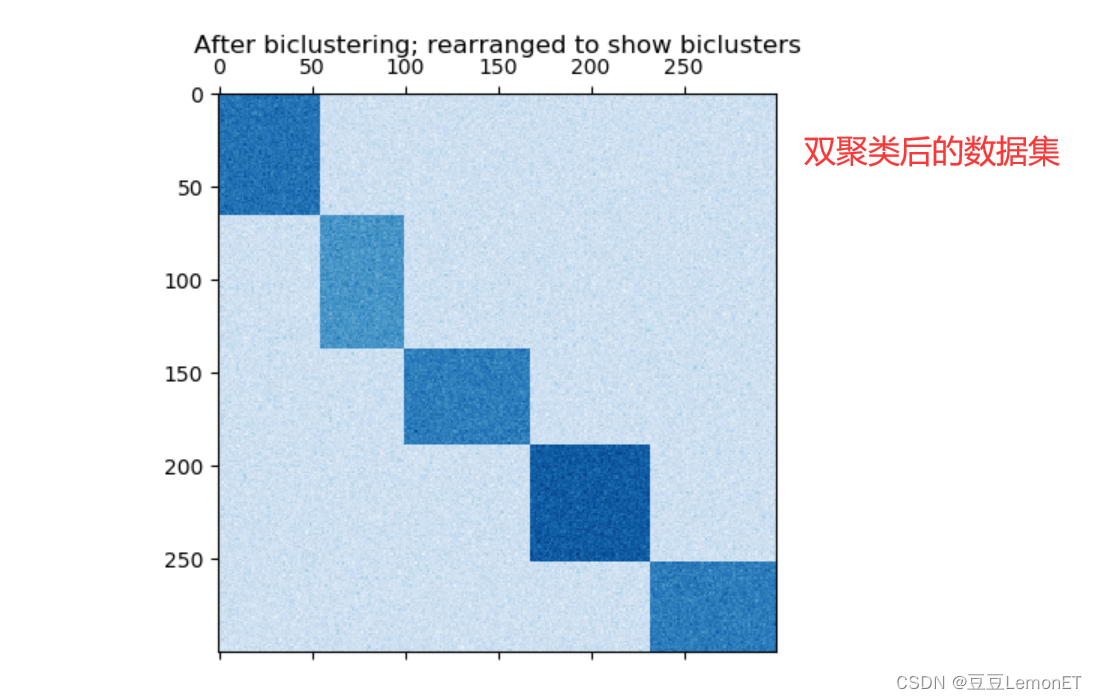
plt.matshow(fit_data, cmap=plt.cm.Blues) # 绘制热图,表示双聚类之后的数据集
plt.title("After biclustering; rearranged to show biclusters")
plt.show() # 显示绘制的图形
运行结果:
- 首先,生成了一个具有5个双聚类的合成数据集
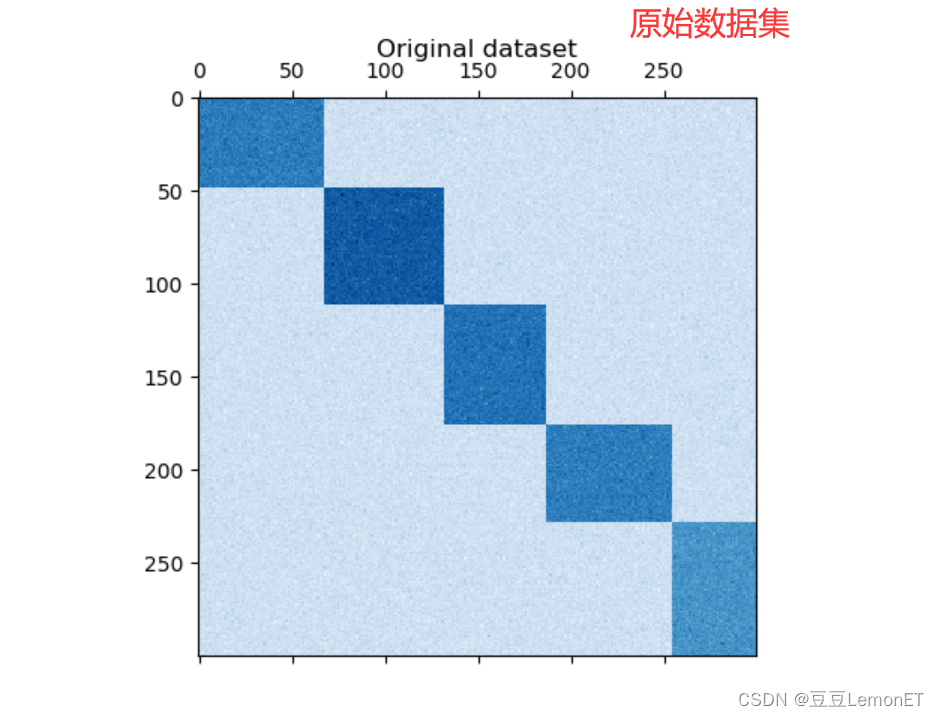
- 然后对数据进行洗牌操作
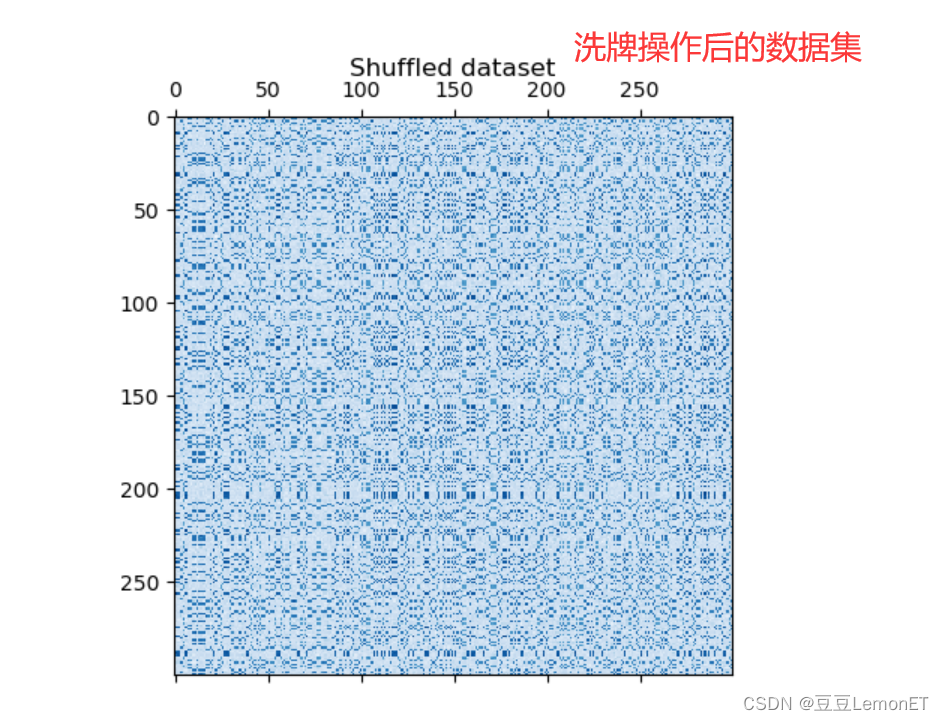
- 利用SpectralCoclustering算法对洗牌后的数据进行双聚类

















 1450
1450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









