







 本文介绍了Python中层次聚类(包括HAC)和DBSCAN聚类算法。层次聚类通过构建聚类树进行数据分组,DBSCAN则是一种基于密度的聚类方法,对异常值不敏感,能发现任意形状的簇。文章通过实例详细解释了两种算法的工作原理、优缺点以及实现过程。
本文介绍了Python中层次聚类(包括HAC)和DBSCAN聚类算法。层次聚类通过构建聚类树进行数据分组,DBSCAN则是一种基于密度的聚类方法,对异常值不敏感,能发现任意形状的簇。文章通过实例详细解释了两种算法的工作原理、优缺点以及实现过程。
层次聚类和DBSCAN
1.层次聚类
下面这样的结构应该比较常见,这就是一种层次聚类的树结构,层次聚类是通过计算不同类别点的相似度创建一颗有层次的树结构,在这颗树中,树的底层是原始数据点,顶层是一个聚类的根节点。
创建这样一棵树的方法有自底向上和自顶向下两种方式。
下面介绍一下如何利用自底向上的方式的构造这样一棵树:
为了便于说明,假设我们有5条数据,对这5条数据构造一棵这样的树,如下是5条数据:

第一步,计算两两样本之间相似度,然后找到最相似两条数据(假设1、2两个最相似),然后将其merge起来,成为1条数据:
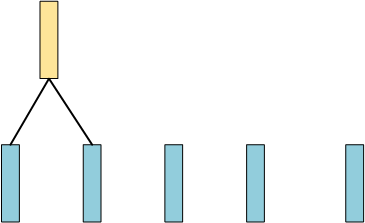
现在数据还剩4条,然后同样计算两两之间的相似度,找出最相似的两条数据(假设前两条最相似),然后再merge起来:
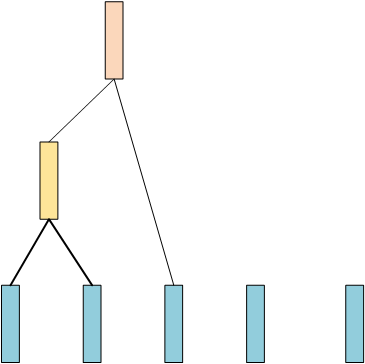
现在还剩余3条数据,然后继续重复上面的步骤,假设后面两条数据最相似,那么:
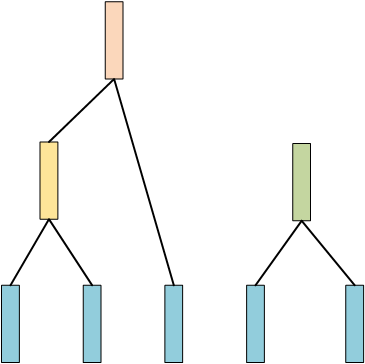
然后还剩余两条数据,再把这两条数据merge起来,最终完成一个树的构建:
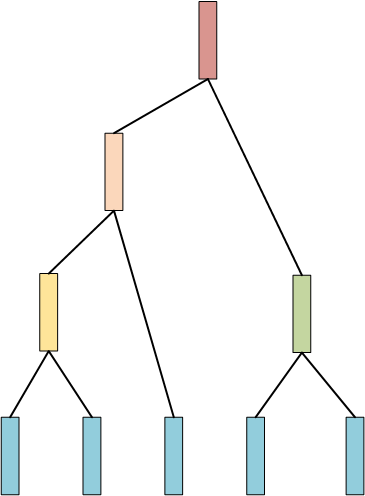
上述就是自底向上聚类树的构建过程,自顶向下的过程与之相似,只不过初始数据是一个类别,不断分裂出距离最远的那个点,知道所有的点都成为叶子结点。
那么我们如何根据这棵树进行聚类呢?
我们从树的中间部分切一刀,像下面这样:

然后叶子节点被分成两个类别,也可以像下面这样切:
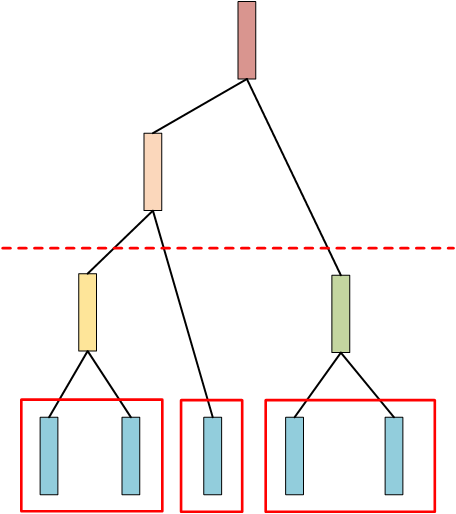
那么样本集就被分成3个类别。 这个切割的线是由一个阈值“threshold”来决定切在什么位置,而这个阈值是需要预先给定的 。
但在实做过程中,往往不需要先构建一棵树,再去进行切分,注意看上面切分,切完后,所剩余的节点数量就是类别个数。
那么在 建树的过程中,当达到所指定的类别后,则就可以停止树的建立了 。
下面看一下HAC(自底向上)的实现过程:
import math
import numpy as np
def euler_distance(point1, point2):
distance = 0.0
for a, b in zip(point1, point2):
distance += math.pow(a-b, 2)
return math.sqrt(distance)
# 定义聚类树的节点
class ClusterNode:
def __init__(self, vec, left=None, right=None, distance=-1, id=None, count=1):
"""
vec: 保存两个数据merge后新的中心
left: 左节点
right: 右节点
distance: 两个节点的距离
id: 保存哪个节点是计算过的
count: 这个节点的叶子节点个数
"""
self.vec = vec
self.left = left
self.right = right
self.distance = distance
self.id = id
self.count = count
# 层次聚类的类
# 不同于文中所说的先构建树,再进行切分,而是直接根据所需类别数目,聚到满足条件的节点数量即停止
# 和k-means一样,也需要指定类别数量
class Hierarchical:
def __init__(self, k=1):
assert k > 0
self.k = k
self.labels = None
def fit(self, x):
# 初始化节点各位等于数据的个数
nodes = [ClusterNode(vec=v, id=i) for i, v in enumerate(x)]
distance = {}
point_num, feature_num = np.shape(x)
self.labels = [-1] * point_num
currentclustid = -1
while len(nodes) > self.k:
min_dist = np.inf
# 当前节点的个数
nodes_len = len(nodes)
# 最相似的两个类别
closest_part = None
# 当前节点中两两距离计算,找出最近的两个节点
for i in range(nodes_len-1):
for j in range(i+1, nodes_len):
# 避免重复计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5039
5039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









