







 文章讲述了在JavaScript中使用XPath时遇到的问题,即在代码中无法获取选中的元素。作者建议使用ID选择器,若遇到问题可尝试将页面下载到本地,利用浏览器的XPath工具获取正确路径,然后在本地路径下进行元素抓取。
文章讲述了在JavaScript中使用XPath时遇到的问题,即在代码中无法获取选中的元素。作者建议使用ID选择器,若遇到问题可尝试将页面下载到本地,利用浏览器的XPath工具获取正确路径,然后在本地路径下进行元素抓取。
你是否也遇到过,在浏览器中选中了某个元素后,再copy xpath,想在代码中获取到你选中的元素,但是代码中显示结果为空。再三检查代码也没有发现异常,为什么就是获取不到数据呢?
使用xpath插件,能获取到正确的数据,为什么就是到代码中就不行了呢?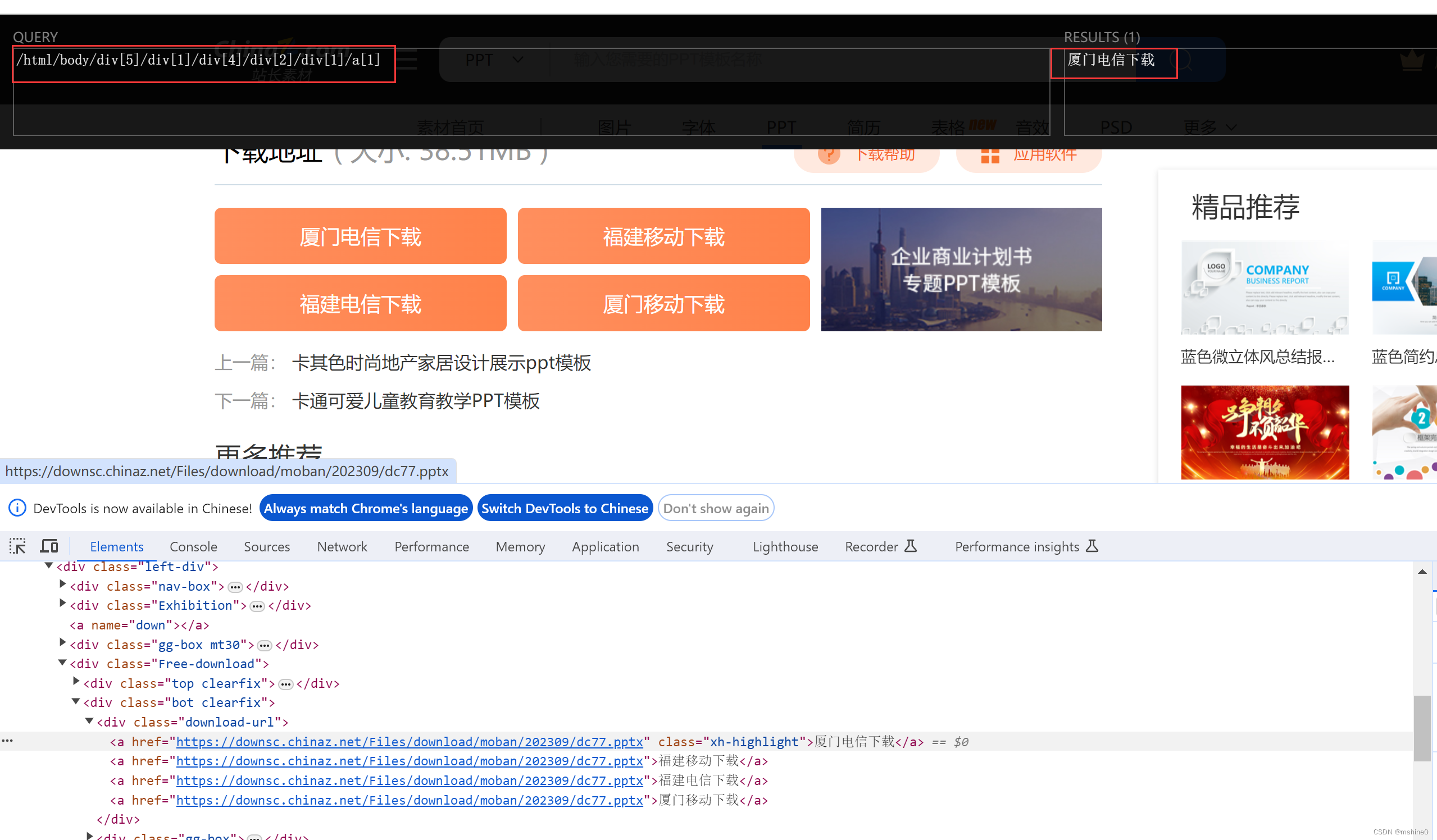
原因多多,就不一一列举了,我们直接说解决办法吧。如果有ID选择器,我们最好使用ID选择器,因为具有唯一性,类选择器的话,结果就不好说了。
但是我们最简单粗暴的办法就是,用我们的requests请求把当前页面下载到本地来,如下:
ppt_info = requests.get(url=ppt_href, headers=headers)
ppt_info.encoding = 'utf-8'
s = open('a.html', 'w', encoding='utf8')
s.write(ppt_info.text)
下载到本地后,我们再使用浏览器打开,获取xpath
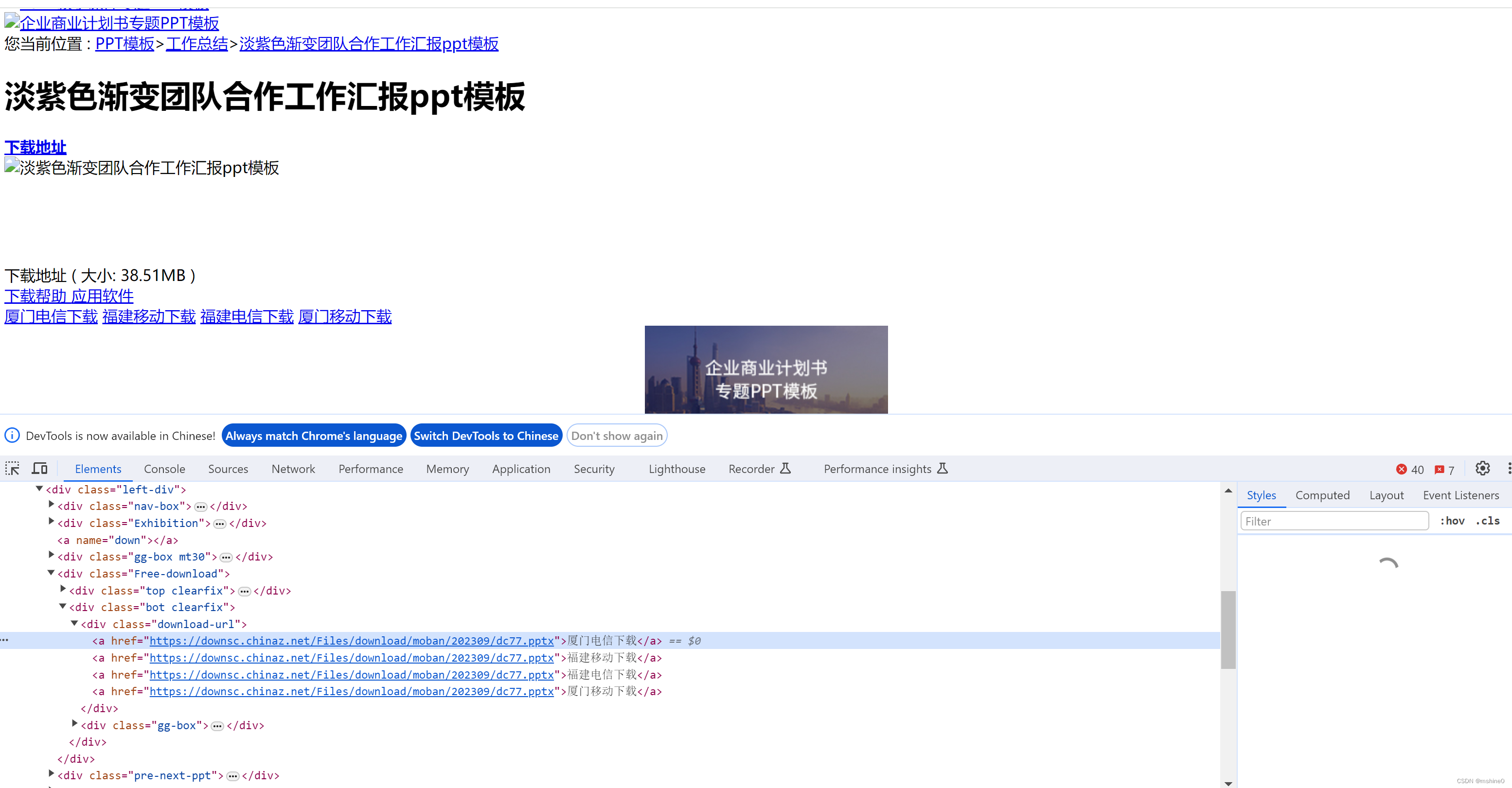
不要看现在页面内容显示不全,这丝毫不影响我们copy xpath,两次copy xpath的结果如下,一个是原网页的,一个是下载到本地的,可以看到两个xpath有差异。我们只需要使用本地的这个xpath就能猎取到我们想要的元素了,就不会再爬出个空了。
/html/body/div[5]/div[1]/div[4]/div[2]/div[1]/a[1]
/html/body/div[4]/div[1]/div[4]/div[2]/div[1]/a[1]
欢迎大家加V,一起学习,共同进步。















 5042
5042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









