






1.环境的配置
(1)libtorch
下载地址(libtorch的版本要与yolov5中训练的torch和cuda版本匹配,下方链接为torch==2.0.0 cuda==11.8版本的libtorch):
https://download.pytorch.org/libtorch/cu118/libtorch-win-shared-with-deps-2.0.1%2Bcu118.zip
下方地址为不同版本的libtoch:
(177条消息) Libtorch各类版本下载---持续更新_libtorch下载_枫呱呱的博客-CSDN博客
(2)opencv
下载地址:https://opencv.org/releases.html
2.yolov5代码的训练和转换
(1)使用yolov5对数据集进行训练得到pt
(2).torchscript.pt版本模型导出(C++可以对该权重进行加载),通过如下python代码将yolov5训练得到的pt文件转换为torchscript.pt:
"""Exports a YOLOv5 *.pt model to ONNX and TorchScript formats
Usage:
$ export PYTHONPATH="$PWD" && python models/export.py --weights ./weights/yolov5s.pt --img 640 --batch 32
"""
import argparse
import sys
import time
sys.path.append('./') # to run '$ python *.py' files in subdirectories
import torch
import torch.nn as nn
import models
from models.experimental import attempt_load
from utils.activations import Hardswish, SiLU
from utils.general import set_logging, check_img_size
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='best.pt', help='weights path') # from yolov5/models/
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
parser.add_argument('--dynamic', action='store_true', help='dynamic ONNX axes')
parser.add_argument('--batch-size', type=int, default=32, help='batch size')
opt = parser.parse_args()
opt.img_size *= 2 if len(opt.img_size) == 1 else 1 # expand
print(opt)
set_logging()
t = time.time()
# Load PyTorch model
# gpu
model = attempt_load(opt.weights, device=torch.device('cuda')) # load FP32 model
labels = model.names
# Checks
gs = int(max(model.stride)) # grid size (max stride)
opt.img_size = [check_img_size(x, gs) for x in opt.img_size] # verify img_size are gs-multiples
# Input
# gpu
img = torch.zeros(opt.batch_size, 3, *opt.img_size).to(device='cuda') # image size(1,3,320,192) iDetection
model.eval()
# Update model
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if isinstance(m, models.common.Conv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
# elif isinstance(m, models.yolo.Detect):
# m.forward = m.forward_export # assign forward (optional)
model.model[-1].export = False # set Detect() layer export=True
y = model(img) # dry run
# TorchScript export
try:
print('\nStarting TorchScript export with torch %s...' % torch.__version__)
f = opt.weights.replace('.pt', '.GPU_torchscript.pt') # filename
ts = torch.jit.trace(model, img)
ts.save(f)
print('TorchScript export success, saved as %s' % f)
except Exception as e:
print('TorchScript export failure: %s' % e)
print('\nExport complete (%.2fs). Visualize with https://github.com/lutzroeder/netron.' % (time.time() - t))
3.vs中环境配置
(1)opencv和libtorch在包含目录和库目录进行加载
点击项目属性,点击VC++目录
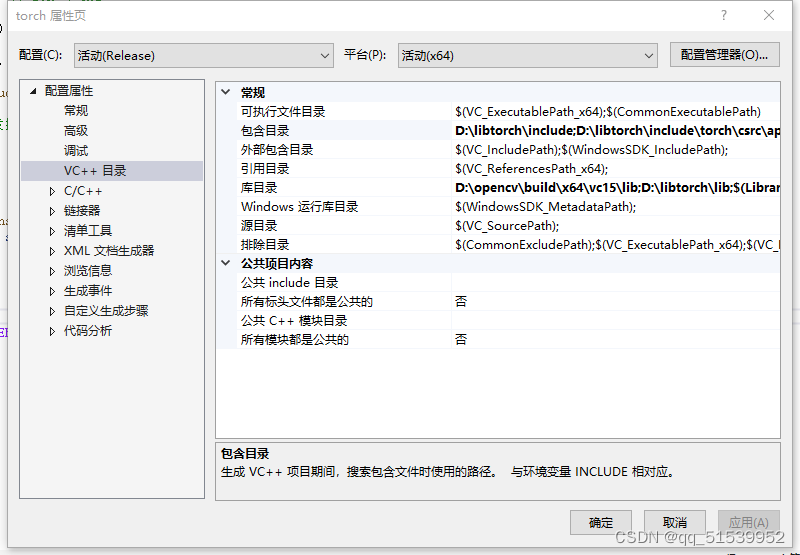

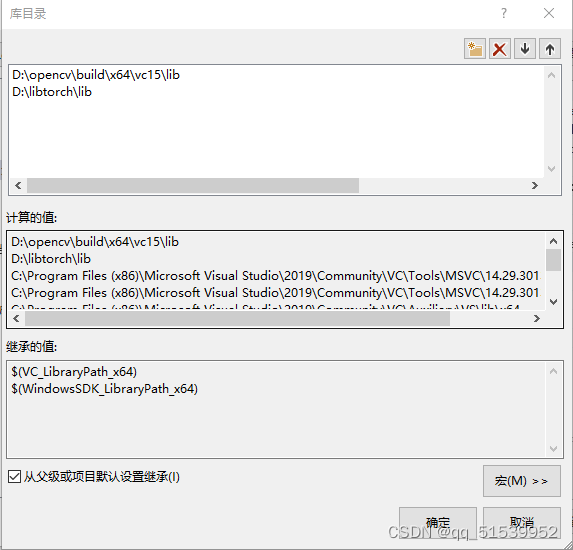
(2)在选择链接器、输入,附加依赖项中添加opencv和libtorchlib文件夹中所有的.lib:

这里我写了个python代码,直接读取路径将文件夹中后缀名为lib的名称输出来:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import copy
from lxml.etree import Element, SubElement, tostring, ElementTree
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
xml_path = os.path.join(CURRENT_DIR, 'D:/libtorch/lib/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[1]
if label_name == 'lib' :
print(img_xml)
4.C++调用模型进行推理检测
下面为进行检测的C++代码
分别对摄像头、单张图像以及文件夹图像进行检测,摄像头和单张图像检测代码以注释掉了,然后读取文件夹中所有图像进行检测后的结果以原图像名称进行保存:
wenjian.cpp
#pragma once
//max.cpp
#include"wenjian.h"//" "表示是我们自己定义的头文件
#include <stdio.h>
#include <time.h>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/ml.hpp>
#include <iostream>
#include<vector>
#include <fstream>
#include <io.h>
//#include <windows.h>
using namespace cv;
using namespace std;
//读入指定文件夹下的所有文件
void getFiles(string path, vector<string>& files, vector<string>& filenames)
{
intptr_t hFile = 0;//intptr_t和uintptr_t是什么类型:typedef long int/ typedef unsigned long int
struct _finddata_t fileinfo;
string p;
//assign方法可以理解为先将原字符串清空,然后赋予新的值作替换。
if ((hFile = _findfirst(p.assign(path).append("\\*").c_str(), &fileinfo)) != -1)
{
do
{
if (strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0)
//这句有点不明白,如果不加,识别的文件里就有.和..两个文件,哪位大神可以给解释下?感激不尽!!!
{
files.push_back(p.assign(path).append("\\").append(fileinfo.name));
filenames.push_back(fileinfo.name);
}
} while (_findnext(hFile, &fileinfo) == 0);
_findclose(hFile);
}
}
wenjian.h
#include<iostream>
#include<opencv2/opencv.hpp>
#include <stdio.h>
#include <time.h>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/ml.hpp>
#include <iostream>
#include<vector>
#include <fstream>
#include <io.h>
using namespace std;
using namespace cv;
//读入指定文件夹下的所有文件
void getFiles(string path, vector<string>& files, vector<string>& filenames);
yolo.cpp
#include <torch/script.h>
#include <memory>
#include <torch/torch.h>
#include<opencv2/opencv.hpp>
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui_c.h>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <time.h>
#include"wenjian.h"
#include <fstream>
#include <string>
using namespace cv;
using namespace std;
std::vector<std::string> LoadNames(const std::string& path)
{
// load class names
std::vector<std::string> class_names;
std::ifstream infile(path);
if (infile.is_open()) {
std::string line;
while (std::getline(infile, line)) {
class_names.emplace_back(line);
}
infile.close();
}
else {
std::cerr << "Error loading the class names!\n";
}
return class_names;
}
std::vector<float> LetterboxImage(const cv::Mat& src, cv::Mat& dst, const cv::Size& out_size)
{
auto in_h = static_cast<float>(src.rows);
auto in_w = static_cast<float>(src.cols);
float out_h = out_size.height;
float out_w = out_size.width;
float scale = std::min(out_w / in_w, out_h / in_h);
int mid_h = static_cast<int>(in_h * scale);
int mid_w = static_cast<int>(in_w * scale);
cv::resize(src, dst, cv::Size(mid_w, mid_h));
int top = (static_cast<int>(out_h) - mid_h) / 2;
int down = (static_cast<int>(out_h) - mid_h + 1) / 2;
int left = (static_cast<int>(out_w) - mid_w) / 2;
int right = (static_cast<int>(out_w) - mid_w + 1) / 2;
cv::copyMakeBorder(dst, dst, top, down, left, right, cv::BORDER_CONSTANT, cv::Scalar(114, 114, 114));
std::vector<float> pad_info{ static_cast<float>(left), static_cast<float>(top), scale };
return pad_info;
}
enum Det
{
tl_x = 0,
tl_y = 1,
br_x = 2,
br_y = 3,
score = 4,
class_idx = 5
};
struct Detection
{
cv::Rect bbox;
float score;
int class_idx;
};
void Tensor2Detection(const at::TensorAccessor<float, 2>& offset_boxes,
const at::TensorAccessor<float, 2>& det,
std::vector<cv::Rect>& offset_box_vec,
std::vector<float>& score_vec)
{
for (int i = 0; i < offset_boxes.size(0); i++) {
offset_box_vec.emplace_back(
cv::Rect(cv::Point(offset_boxes[i][Det::tl_x], offset_boxes[i][Det::tl_y]),
cv::Point(offset_boxes[i][Det::br_x], offset_boxes[i][Det::br_y]))
);
score_vec.emplace_back(det[i][Det::score]);
}
}
void ScaleCoordinates(std::vector<Detection>& data, float pad_w, float pad_h,
float scale, const cv::Size& img_shape)
{
auto clip = [](float n, float lower, float upper)
{
return std::max(lower, std::min(n, upper));
};
std::vector<Detection> detections;
for (auto& i : data) {
float x1 = (i.bbox.tl().x - pad_w) / scale; // x padding
float y1 = (i.bbox.tl().y - pad_h) / scale; // y padding
float x2 = (i.bbox.br().x - pad_w) / scale; // x padding
float y2 = (i.bbox.br().y - pad_h) / scale; // y padding
x1 = clip(x1, 0, img_shape.width);
y1 = clip(y1, 0, img_shape.height);
x2 = clip(x2, 0, img_shape.width);
y2 = clip(y2, 0, img_shape.height);
i.bbox = cv::Rect(cv::Point(x1, y1), cv::Point(x2, y2));
}
}
torch::Tensor xywh2xyxy(const torch::Tensor& x)
{
auto y = torch::zeros_like(x);
// convert bounding box format from (center x, center y, width, height) to (x1, y1, x2, y2)
y.select(1, Det::tl_x) = x.select(1, 0) - x.select(1, 2).div(2);
y.select(1, Det::tl_y) = x.select(1, 1) - x.select(1, 3).div(2);
y.select(1, Det::br_x) = x.select(1, 0) + x.select(1, 2).div(2);
y.select(1, Det::br_y) = x.select(1, 1) + x.select(1, 3).div(2);
return y;
}
std::vector<std::vector<Detection>> PostProcessing(const torch::Tensor& detections,
float pad_w, float pad_h, float scale, const cv::Size& img_shape,
float conf_thres, float iou_thres)
{
/***
* 结果纬度为batch index(0), top-left x/y (1,2), bottom-right x/y (3,4), score(5), class id(6)
* 13*13*3*(1+4)*80
*/
constexpr int item_attr_size = 5;
int batch_size = detections.size(0);
// number of classes, e.g. 80 for coco dataset
auto num_classes = detections.size(2) - item_attr_size;
// get candidates which object confidence > threshold
auto conf_mask = detections.select(2, 4).ge(conf_thres).unsqueeze(2);
std::vector<std::vector<Detection>> output;
output.reserve(batch_size);
// iterating all images in the batch
for (int batch_i = 0; batch_i < batch_size; batch_i++) {
// apply constrains to get filtered detections for current image
auto det = torch::masked_select(detections[batch_i], conf_mask[batch_i]).view({ -1, num_classes + item_attr_size });
// if none detections remain then skip and start to process next image
if (0 == det.size(0)) {
continue;
}
// compute overall score = obj_conf * cls_conf, similar to x[:, 5:] *= x[:, 4:5]
det.slice(1, item_attr_size, item_attr_size + num_classes) *= det.select(1, 4).unsqueeze(1);
// box (center x, center y, width, height) to (x1, y1, x2, y2)
torch::Tensor box = xywh2xyxy(det.slice(1, 0, 4));
// [best class only] get the max classes score at each result (e.g. elements 5-84)
std::tuple<torch::Tensor, torch::Tensor> max_classes = torch::max(det.slice(1, item_attr_size, item_attr_size + num_classes), 1);
// class score
auto max_conf_score = std::get<0>(max_classes);
// index
auto max_conf_index = std::get<1>(max_classes);
max_conf_score = max_conf_score.to(torch::kFloat).unsqueeze(1);
max_conf_index = max_conf_index.to(torch::kFloat).unsqueeze(1);
// shape: n * 6, top-left x/y (0,1), bottom-right x/y (2,3), score(4), class index(5)
det = torch::cat({ box.slice(1, 0, 4), max_conf_score, max_conf_index }, 1);
// for batched NMS
constexpr int max_wh = 4096;
auto c = det.slice(1, item_attr_size, item_attr_size + 1) * max_wh;
auto offset_box = det.slice(1, 0, 4) + c;
std::vector<cv::Rect> offset_box_vec;
std::vector<float> score_vec;
// copy data back to cpu
auto offset_boxes_cpu = offset_box.cpu();
auto det_cpu = det.cpu();
const auto& det_cpu_array = det_cpu.accessor<float, 2>();
// use accessor to access tensor elements efficiently
Tensor2Detection(offset_boxes_cpu.accessor<float, 2>(), det_cpu_array, offset_box_vec, score_vec);
// run NMS
std::vector<int> nms_indices;
cv::dnn::NMSBoxes(offset_box_vec, score_vec, conf_thres, iou_thres, nms_indices);
std::vector<Detection> det_vec;
for (int index : nms_indices) {
Detection t;
const auto& b = det_cpu_array[index];
t.bbox =
cv::Rect(cv::Point(b[Det::tl_x], b[Det::tl_y]),
cv::Point(b[Det::br_x], b[Det::br_y]));
t.score = det_cpu_array[index][Det::score];
t.class_idx = det_cpu_array[index][Det::class_idx];
det_vec.emplace_back(t);
}
ScaleCoordinates(det_vec, pad_w, pad_h, scale, img_shape);
// save final detection for the current image
output.emplace_back(det_vec);
} // end of batch iterating
return output;
}
cv::Mat Demo(cv::Mat& img,
const std::vector<std::vector<Detection>>& detections,
const std::vector<std::string>& class_names,
bool label = true)
{
if (!detections.empty()) {
for (const auto& detection : detections[0]) {
const auto& box = detection.bbox;
float score = detection.score;
int class_idx = detection.class_idx;
cv::rectangle(img, box, cv::Scalar(0, 0, 255), 2);
if (label) {
std::stringstream ss;
ss << std::fixed << std::setprecision(2) << score;
std::string s = class_names[class_idx] + " " + ss.str();
auto font_face = cv::FONT_HERSHEY_DUPLEX;
auto font_scale = 1.0;
int thickness = 1;
int baseline = 0;
auto s_size = cv::getTextSize(s, font_face, font_scale, thickness, &baseline);
cv::rectangle(img,
cv::Point(box.tl().x, box.tl().y - s_size.height - 5),
cv::Point(box.tl().x + s_size.width, box.tl().y),
cv::Scalar(0, 0, 255), -1);
cv::putText(img, s, cv::Point(box.tl().x, box.tl().y - 5),
font_face, font_scale, cv::Scalar(255, 255, 255), thickness);
}
}
}
return img;
//cv::namedWindow("Result", cv::WINDOW_NORMAL);
//cv::imshow("Result", img);
}
int main()
{
//cout << "cuda是否可用:" << torch::cuda::is_available() << endl;
//cout << "cudnn是否可用:" << torch::cuda::cudnn_is_available() << endl;
torch::DeviceType device_type;
device_type = torch::kCUDA;
torch::Device device(device_type);
torch::jit::script::Module module;
module = torch::jit::load("best.GPU_torchscript.pt", device); //加载模型
module.eval();
std::vector<std::string> class_names = LoadNames("coco.names");//读取标签
if (class_names.empty()) {
return -1;
}
// set up threshold
float conf_thres = 0.4;
float iou_thres = 0.5;
//视频检测
//VideoCapture video1(0);//打开笔记本自带摄像头(1)为外接摄像头
//video1.set(CAP_PROP_FRAME_WIDTH, 1280);
//video1.set(CAP_PROP_FRAME_HEIGHT, 720);
读取视频帧率
//double rate = video1.get(CAP_PROP_FPS);
//std::cout << "rate: " << rate << std::endl;
当前视频帧
//Mat frame;
每一帧之间的延时
//int delay = 1000 / rate;
//bool stop(false);
//while (!stop)
//{
// double t = (double)cv::getTickCount();//开始计时
// if (!video1.read(frame))
// {
// std::cout << "no video frame" << std::endl;
// break;
// }
//文件夹进行检测
char windowname[10];
string filePath = "D:/Deep learning/yolov5-master/images/"; //源文件夹
string dst_filePath = "images/"; //目标文件夹
vector<string> files;
vector<string> filenames;
getFiles(filePath, files, filenames);
int number = files.size();//文件数量
for (int i = 0; i < number; i++)
{
//clock_t t_start = clock();
string saveFilename = dst_filePath + filenames[i]; //写入部分
Mat img = imread(files[i]);
clock_t t_start = clock();
//cv::Mat img = imread("right_outside_005458.bmp");
//inference
torch::NoGradGuard no_grad;
cv::Mat img_input = img.clone();
std::vector<float> pad_info = LetterboxImage(img_input, img_input, cv::Size(640, 640));
const float pad_w = pad_info[0];
const float pad_h = pad_info[1];
const float scale = pad_info[2];
cv::cvtColor(img_input, img_input, cv::COLOR_BGR2RGB); // BGR -> RGB
//归一化需要是浮点类型
img_input.convertTo(img_input, CV_32FC3, 1.0f / 255.0f); // normalization 1/255
// 加载图像到设备
auto tensor_img = torch::from_blob(img_input.data, { 1, img_input.rows, img_input.cols, img_input.channels() }).to(device_type);
// BHWC -> BCHW
tensor_img = tensor_img.permute({ 0, 3, 1, 2 }).contiguous(); // BHWC -> BCHW (Batch, Channel, Height, Width)
std::vector<torch::jit::IValue> inputs;
// 在容器尾部添加一个元素,这个元素原地构造,不需要触发拷贝构造和转移构造
inputs.emplace_back(tensor_img);
//start = clock();
torch::jit::IValue output = module.forward(inputs);
// 解析结果
auto detections = output.toTuple()->elements()[0].toTensor();
auto result = PostProcessing(detections, pad_w, pad_h, scale, img.size(), conf_thres, iou_thres);
cv::Mat pre_img = Demo(img, result, class_names);
//imwrite("结构图.jpg",pre_img);
clock_t t_stop = clock();
double endtime = (double)(t_stop - t_start) / CLOCKS_PER_SEC;
imwrite(saveFilename, pre_img);
}
//单张图像检测
//clock_t t_start = clock();
// cv::Mat img = imread("right_outside_005458.bmp");
// //inference
// torch::NoGradGuard no_grad;
// cv::Mat img_input = img.clone();
// std::vector<float> pad_info = LetterboxImage(img_input, img_input, cv::Size(640, 640));
// const float pad_w = pad_info[0];
// const float pad_h = pad_info[1];
// const float scale = pad_info[2];
// cv::cvtColor(img_input, img_input, cv::COLOR_BGR2RGB); // BGR -> RGB
// //归一化需要是浮点类型
// img_input.convertTo(img_input, CV_32FC3, 1.0f / 255.0f); // normalization 1/255
// // 加载图像到设备
// auto tensor_img = torch::from_blob(img_input.data, { 1, img_input.rows, img_input.cols, img_input.channels() }).to(device_type);
// // BHWC -> BCHW
// tensor_img = tensor_img.permute({ 0, 3, 1, 2 }).contiguous(); // BHWC -> BCHW (Batch, Channel, Height, Width)
// std::vector<torch::jit::IValue> inputs;
// // 在容器尾部添加一个元素,这个元素原地构造,不需要触发拷贝构造和转移构造
// inputs.emplace_back(tensor_img);
// //start = clock();
// torch::jit::IValue output = module.forward(inputs);
//
// // 解析结果
// auto detections = output.toTuple()->elements()[0].toTensor();
// auto result = PostProcessing(detections, pad_w, pad_h, scale, img.size(), conf_thres, iou_thres);
//
// cv::Mat pre_img = Demo(img, result, class_names);
// imwrite("结构图.jpg",pre_img);
// clock_t t_stop = clock();
// double endtime = (double)(t_stop - t_start) / CLOCKS_PER_SEC;
//cout << "检测时间:" << endtime << endl;
//t = ((double)cv::getTickCount() - t) / cv::getTickFrequency();//结束计时
//int fps = int(1.0 / t);//转换为帧率
//std::cout << "FPS: " << fps << std::endl;//输出帧率
//putText(pre_img, ("FPS: " + std::to_string(fps)), Point(0, 50), FONT_HERSHEY_COMPLEX, 0.5, Scalar(0, 0, 0));//输入到帧frame上
//cv::namedWindow("Result", cv::WINDOW_NORMAL);
//cv::namedWindow("Result", cv::WINDOW_AUTOSIZE);
//cv::imshow("Result", pre_img);
//waitKey()函数的作用是刷新imshow()展示的图片
//if (waitKey(10) == 27)//27是键盘摁下esc时,计算机接收到的ascii码值
//{
// break;
//}
//}
//video1.release();
system("pause");
return 0;
}
检测效果:

Python代码检测效果如左图所示,C++代码检测如右图所示:
















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









