






Yolov5网络
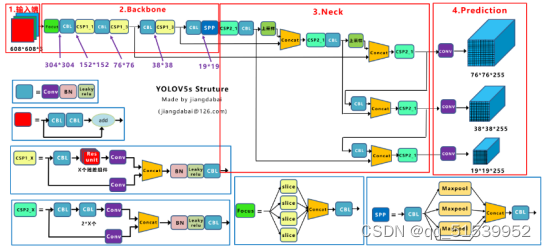
1.输入端
(1)Mosaic数据增强
采用4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。
(2)自适应锚框计算
在yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
(3)自适应图像缩放
在常用的目标检测算法中,不同的图片长宽也不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,在送入检测网络中。
2.特征提取网络
(1)CBL
由Conv+Bn+Leaky_relu激活函数三者组成。
(2)CSP
特征提取网络中的CSP1_X先将特征图按通道拆分为两部分,一部分进行常规卷积操作,另一部分利用残差网络的思想构建残差组件,最后将这两部分合并得到新的特征图。这种设计可以避免重复计算梯度值,提高模型推理速度。而且带有残差组件的CSP结构,在反向传播过程中可以增强梯度值,当主干网络的层数较深时,可以缓解梯度消失的问题,增强网络的特征提取能力。
CSP2_X用卷积层代替了残差组件,用于将输入的特征图分为两部分,分别计算后再融合,能保留更多图像信息。
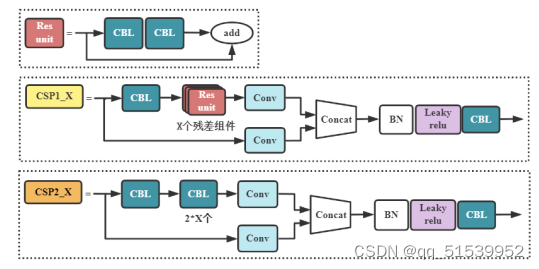
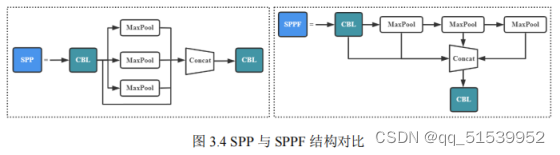
(3)SPP
SPP模块与SPPF模块的结构如图所示。由图可知,SPP模块将特征图并行输入卷积核尺寸为5×5、9×9和13×13的最大池化层,然后将4个感受野不同的特征图拼接到一起。而SPPF模块则是将特征图串行输入卷积核大小为5×5的最大池化层,再进行特征融合。由于两个5×5的最大池化层与一个9×9的最大池化层的效果相同,而且三个5×5的最大池化层与一个13×13的最大池化层的运算结果也相同。故使用SPPF结构能发挥相同效果,而且模型计算量更小、效率更高。
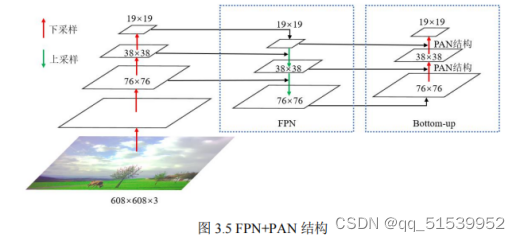
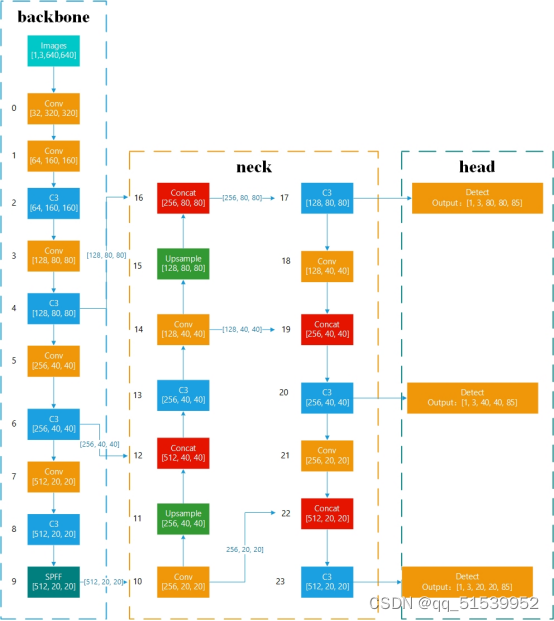
3.Neck
YOLOv3采用FPN结构将深层特征图上采样后与浅层特征图融合,再针对特征金字塔中的每层特征图分别进行预测。而YOLOv5在YOLOv3的基础上又增加了一个自底向上的特征金字塔,该特征金字塔包含两个PAN结构,能将浅层特征图下采样后与深层特征图融合。如图3.5所示,是FPN与PAN结构图,这种双管齐下的设计方式既能自顶向下传递强语义信息,又能自底向上传达强定位信息,有效提高了算法性能。
4.输出端
目标检测任务的损失函数一般由Classification Loss(分类损失函数)和Bounding Box Regression Loss(回归损失函数)两部分组成。
(1)回归损失函数
回归损失函数的Loss近些年的发展过程是:Smooth L1 Loss->IOU Loss(2016)->GIOU Loss(2019)->DIOU Loss(2020)->CIOU Loss(2020)
IOU Loss
IOU的loss其实很简单,主要是交集/并集。
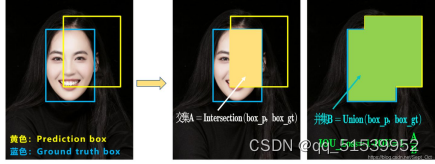
但主要会存在交集一样的问题,如下所示:
问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反映两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。

GIOU
先计算两个框的最小闭包区域面积C(通俗理解:同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
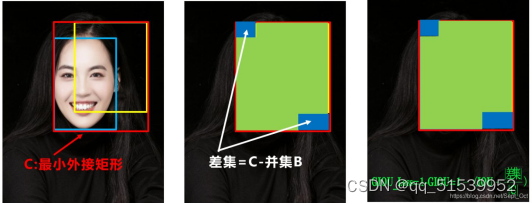
问题:状态1、2、3都是预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。

DIOU
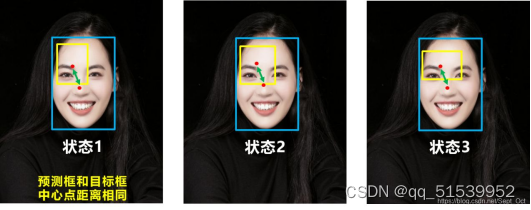
DIOU主要考虑重叠面积、中心点距离、长宽比。

如下图所示,目标框包裹预测框,但预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。
CIOU
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。
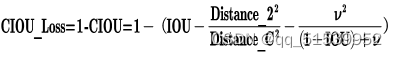
其中v是衡量长宽比一致性的参数,我们也可以定义为:

(2)nms非极大值抑制
NMS的本质是搜索局部极大值,抑制非极大值元素。非极大值抑制,主要就是用来抑制检测时冗余的框。因为在目标检测中,在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,所以我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
算法流程
对所有预测框的置信度降序排序
选出置信度最高的预测框,确认其为正确预测,并计算他与其他预测框的 IOU。
根据步骤2中计算的 IOU 去除重叠度高的,IOU > threshold 阈值就直接删除。
剩下的预测框返回第1步,直到没有剩下的为止。
SoftNMS:当两个目标靠的非常近时,置信度低的会被置信度高的框所抑制,那么当两个目标靠的十分近的时候就只会识别出一个BBox。为了解决这个问题,可以使用softNMS。它的基本思想是用稍低一点的分数来代替原有的分数,而不是像NMS一样直接置零。
5.Yaml文件讲解
卷积层输出大小 = (原图大小 - 卷积核尺寸 + 2填充)/步幅 + 1
卷积层参数数量 = (前一层卷积核尺寸前一层卷积核通道数当前卷积核数量)+当前层卷积核数量
参数解析:
(1)nc:数据集中的类别数
(2)depth_multiple:模型层数因子,用于调整网络的深度
为了控制控制层的重复的次数。它会和后面的backbone&head的number相乘后取整,代表该层的重复的数量。
如:[[-1,1,Conv,[64,6,2,2]],当depth_multiple为1时候,则重复11个。
(3)width_multiple:模型通道数因子,用来调整网络的宽度。
为了控制输出特征图的通道数,它会和出特征图的通道数相乘,代表该层的输出通道数。
如:[[-1, 1, Conv, [64, 6, 2, 2]],当width_multiple为0.5时候,则输出通道为640.5=32通道
(4)anchors:锚定框
yolov5 初始化了9个anchors,分别在三个特征图(feature map)中使用,每个feature map的每个grid cell(网络单元)都有三个anchor进行预测。分配规则:
尺度越大的feature map越靠前,相对原图的下采样率越小,感受野越小,所以相对可以预测一些尺度比较小的物体(小目标),分配到的anchors越小。
尺度越小的feature map越靠后,相对原图的下采样率越大,感受野越大,所以可以预测一些尺度比较大的物体(大目标),所以分配到的anchors越大。
即在小特征图(feature map)上检测大目标,中等大小的特征图上检测中等目标,在大特征图上检测小目标。
(5)[from,number,module,args]参数:卷积核的个数就是输出的通道数
第一个参数from:从哪一层获得输入,-1表示从上一层获得,[-1, 6]表示从上层和第6层两层获得。
第二个参数number:表示有几个相同的模块,如果为9则表示有9个相同的模块。
第三个参数module:模块的名称,这些模块写在common.py中。
第四个参数args:类的初始化参数,用于解析作为 moudle 的传入参数。
args参数依次为:输出channel,卷积核尺寸kernel size,步长stride,l零填充大小
yolov5s.yaml的width_multiple都为0.50
举例:[[-1, 1, Conv, [64, 6, 2, 2]],当width_multiple为0.5时候,则输出通道为640.5=32通道。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









