







今天来讲一下贝叶斯网络及结构学习。在讲贝叶斯网络之前呢,我们先回顾一下概率与统计中学到的一些基础概念。
0.基础
0.1贝叶斯定理
如果提到贝叶斯网络,那脑海中想到了最相关的东西肯定是贝叶斯定理!贝叶斯网络的基石与核心就是贝叶斯定理。贝叶斯定理允许我们在已知某些证据的情况下更新我们的概率估计。
那么贝叶斯定理是什么呢?

那么看完这些,大家估计还是有些迷惑,什么是先验概率?什么是后验概率?什么是似然?什么又是边缘概率?
首先说一下:先验概率(Prior Probability)
定义:在获取新证据(或者说观测数据)之前,我们对某个事件发生概率的初始判断或已有知识。
特点:可以是基于历史数据、相关领域专家的经验或主观假设。不一定是“准确”的,但能为后续推理提供一个起点。
我们举一个例子:抛硬币。假设一枚硬币是公平的,抛出正面的先验概率是50%。这是基于生活经验所制定的。因为硬币就两个面,一般情况下,你抛一枚硬币不是正面,就是反面,二者各占50%。这种已有的初始认识,就是先验概率。
我们可以再拿天气预报举一个例子:基于咱们燕郊气象台过去100天的统计,其中20天在下雨,我们根据这个经验和历史数据,那么我们就把明天下雨的先验概率定为20%。
再说:似然(Likelihood)
下面我们继续以天气预报为例子来说明:
定义:在某个假设成立的条件下,观察到当前证据的概率。
我们举一个例子:我们想知道在某个假设(下雨)成立的条件下,观察到当前证据(如乌云)的概率。

比喻:如果明天下雨,这个假设是真的,那么我们就有90%的把握看到乌云;如果不下雨,这个假设是假的,我们还是有30%的概率看到乌云。
通俗一句话总结什么是似然:
似然就是“假设某个事件发生成立时,你观测到证据的可能性有多大”——比如假设明天下雨,那么你今天看到乌云的概率就是90%。
边缘概率(Marginal Probability)
定义:证据(乌云)在所有可能情况下出现的总概率(无论下雨与否)。
我们根据全概率公式:


结论:我们经过计算发现,平均有42%的日子会有乌云(无论是否下雨)。就是说,不论结果的可能情况是什么,我们观测到这个证据出现的总概率是42%。
后验概率提高意味着“有了新证据的支持我们对某个假设的信任度提升了”——比如看到乌云后,下雨的概率从20%涨到42%,说明乌云让明天下雨这个事件的发生更可信了!
然后再说:后验概率(Posterior Probability)
定义:在观察到证据(乌云)后,更新后的事件发生的(下雨)概率。
计算步骤(这时候后验概率的计算就要依赖我们的贝叶斯公式了):
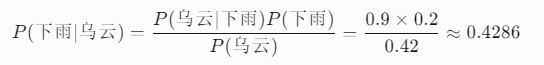
结论:我们观测到乌云这个证据后,事件发生(下雨)的概率从20%提升至约42.86%。


0.2 条件独立性
我们来回顾一下刚刚的天气预报例子:

我们可以发现一些局限性:
1.仅处理两变量:无法建模多变量间的复杂依赖关系。
2.忽略间接原因:其他的变量,如气压变化(C),可能同时影响下雨(A)和乌云(B)。
3.无法表达条件独立性:当多个变量共同作用时,某些变量可能在给定其他变量后独立,即条件独立性。
我们首先来说一下单变量因果关系的缺点,我们举一个其他例子:学生的成绩

- 缺点:
- 忽略其他因素:智商(C)、课程难度(D)也会影响成绩,但模型未包含。
- 无法处理共同原因:课程难度(D)可能同时影响学习时间(A)和考试成绩(B),导致伪相关。
- 无法建模间接影响:例如,课程难度(D)→ 学习时间(A)→ 考试成绩(B)。
那么这会导致什么后果:若仅用学习时间预测成绩,可能得出“学习时间越长成绩越好”的误导结论,忽略智商或课程难度的干扰。
那么如何解决多变量依赖问题呢?我们可以采用一种有向无环图的形式来建立变量之间的关系。


我们可以对这些变量进行建立关系:

现在我们来看这个有因果关系的有向无环图,说一下之前提到的“条件独立性”是什么。
我们在生活中往往发现这么一种现象:
- 当课程变难(D=高)时,考试成绩(B)往往会变差。
- 但真的是“课程难”直接导致“成绩差”吗?也就是说,课程难度是否与考试成绩具有真正的因果关系?错!课程难度(D)不直接影响成绩(B)!这两个变量的因果关系其实是虚假的。
- 它通过中间变量“学习时间(A)”间接影响成绩:D→A→B(比如:课越难→学习时间被迫增加→但时间多不一定成绩好)
然后我们介绍一下条件独立性的概念:如果两个变量在已知某个条件后变得无关,就叫条件独立。
我们把这个定义代入例子:


举个栗子🌰:
- 假设已知小明每天学习5小时(即,A的状态=长):
- 无论课程难(D=高)还是简单(D=低),他的成绩(B)概率只取决于这5小时学得是否高效(比如智商C的影响)。
- 课程难度D的信息已经体现在“学习时间A”中,不再额外影响成绩。
然后,我们来对比一下“关联”和“条件独立”
情景1:不知道学习时间(A)
- 课程难(D=高)和成绩差(B=差)“看起来”相关(比如统计数据显示两者同时出现)。
- 但这只是虚假关联!真正的原因是:
- 课程难 → 学生被迫花更多时间(A增加)(这才是重点,A才是原因) → 但智商不足的学生即使花时间也学不好(C影响B)。
情景2:已知学习时间(A)
- 如果已经知道小明每天学5小时(A=长):
- 课程难易(D)的信息对预测成绩(B)不再有用。
- 成绩只取决于:智商(C) + 这5小时的学习效率。
条件独立性的现实意义是什么?
-
破除虚假因果,找到真正的因果关系:不要因为“课程难时成绩差”就认为降低课程难度能提高成绩,真正需要优化的是学习效率(比如改进智商C或学习方法)。
-
分解一个复杂的问题:如果学校想预测成绩,只需关注学习时间(A)和智商(C),无需单独收集课程难度数据(因为D的信息已经被A包含)。
-
辅助后续的策略制定:对智商低的学生,与其抱怨课程难,不如帮他们规划学习时间;对智商高的学生,即使课程难,也可能通过增加时间(A)获得好成绩。
终极总结:条件独立性三句话
- “大哥罩着小弟”:课程难度(D)和学习时间(A)是大哥和小弟的关系。
- “小弟出面,大哥退场”:一旦知道学习时间(A),课程难度(D)就退出成绩预测的舞台。
- “各司其职”:成绩(B)只直接受学习时间(A)和智商(C)影响,其他都是间接传递。
1.贝叶斯网络
1.1 基础介绍
贝叶斯网络(bayesian network)又称信念网络(belief network),由2011年图灵奖获得者Judea Pearl提出。贝叶斯网络是一种用于计算复杂逻辑、推理因果关系中模糊概率的图模型,能够表示随机变量以及变量间的依赖关系。其以因子分解的方式定义了联合概率分布的数据结构,并且给出了这个分布中一系列的条件独立假设。
贝叶斯网络的组成分为两部分,其拓扑结构是一个有向无环图,以及条件概率表(CPT)。其中节点表示随机变量,有向边表示他们之间的条件概率依赖关系。“有向”指的是用来连接不同节点的边的方向是固定的,起点和终点顺序不能调换,这说明由因到果的逻辑关系不能颠倒;“无环”指的是从任意节点出发,无法经过若干条边再次回到该点,即在图中不存在任何环路。我们应该按照因果关系来决定变量顺序。非条件独立的两个随机变量节点之间连接的起始节点为“因”,终点节点为“果”。
我们再回到刚刚的学习成绩网络拓扑图,其实刚刚那个就是“贝叶斯网络”。我们会发现:

贝叶斯网络的核心——分解复杂问题
“如果要计算‘课程难、智商高、学习时间长、成绩优’的概率,该怎么算?”
传统方法:
列出所有可能性(D、C、A、B各有2种情况 → 16种组合),调查每种概率,计算量爆炸!
贝叶斯网络的巧思:
利用箭头关系,将联合概率拆解为局部因果关系的乘积:
![]()

这个公式是根据链式法则(通用公式)简化而来:
对于任意变量,联合概率可分解为:


我们再引入一个概念:条件概率表(Conditional Probability Table, CPT)
定义:条件概率表是一种用表格形式表示变量之间条件概率的工具。
核心作用:在贝叶斯网络中,每个节点(变量)的CPT明确其直接依赖关系,从而将复杂概率问题模块化。
根据公式中的分解项,每个变量对应一个CPT:
(1) 根节点:课程难度(D)和智商(C):无父节点,只需记录其先验概率。
| 课程难度(D) | P(D) |
|---|---|
| 高 | 0.3 |
| 低 | 0.7 |
| 智商(C) | P(C) |
|---|---|
| 高 | 0.2 |
| 低 | 0.8 |
(2) 中间节点:学习时间(A):父节点:课程难度(D) → CPT需列出不同D值下A的概率。
| 课程难度(D) | 学习时间(A=长) | 学习时间(A=短) |
|---|---|---|
| 高 | 0.8 | 0.2 |
| 低 | 0.3 | 0.7 |
解读:
- 当课程难(D=高),80%学生选择长时间学习(A=长);
- 课程简单(D=低),70%学生选择短时间学习(A=短)。
(3) 结果节点:考试成绩(B)
| 学习时间(A) | 智商(C) | B=优 | B=差 |
|---|---|---|---|
| 长 | 高 | 0.9 | 0.1 |
| 长 | 低 | 0.4 | 0.6 |
| 短 | 高 | 0.6 | 0.4 |
| 短 | 低 | 0.1 | 0.9 |
解读:
- 高智商(C=高)+ 长时间学习(A=长)→ 90%概率成绩优;
- 低智商(C=低)+ 短时间学习(A=短)→ 90%概率成绩差。
现在我们就可以来计算刚刚的联合概率了!
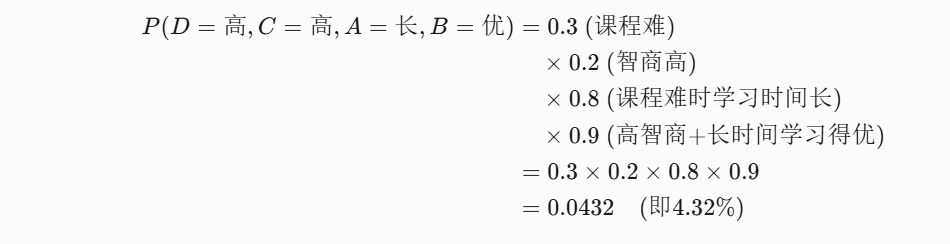
- 4.32%的概率表示:在全校学生中,同时满足“课程难、智商高、学习时间长、成绩优”这四个条件的比例约为4.32%。
下面我们来计算一个后验概率的例子:已知智商高(C=高),课程难,学习时间短,求成绩优(B=优)的后验概率

从提供的条件概率表中:
| 学习时间(A) | 智商(C) | B=优 | B=差 |
|---|---|---|---|
| 短 | 高 | 0.6 | 0.4 |

总结贝叶斯网络的核心思想(!)
- 变量抽象:找出关键因素(D、C、A、B);
- 箭头建模:用方向箭头表达因果关系;
- 条件独立:已知某些信息后,其他变量不再相关;
- 概率分解:将复杂问题拆解为简单模块计算。
1.2 参数估计
我们进行到这里,相信大家对贝叶斯网络已经有了一个初步的认识了,但是现在还存在一个问题:条件概率表是贝叶斯网络的组成部分,但是这个表是从哪得到的呢?
在深度学习里,比如什么全连接层,每个模型中都有很多的参数,贝叶斯网络作为机器学习的一种经典模型,它也有一些参数,但是数量远远不如深度学习模型,它的参数就是条件概率表中的概率矩阵里面的一个个数。
这些数字肯定不是自己生成的,它都是通过一些方式,经过估计或者计算得来的,下面我就简单给大家介绍一些这种参数估计的方法。
1.2.1最大似然估计(Maximum Likelihood Estimation, MLE)
还是回到刚才的例子,“假设我们调查了100个学生,记录了他们的课程难度(D)、智商(C)、学习时间(A)和考试成绩(B)。现在的问题是:
‘如何通过这些数据,推测出课程难度、智商等因素如何影响学习时间和考试成绩?’
比如,如果课程很难(D=高),学生选择长时间学习(A=长)的概率是多少?
如果学生智商高(C=高)且学习时间长(A=长),考试成绩好(B=优)的概率又是多少?
最大似然估计就是解决这类问题的数学工具!”
“想象你是一个侦探,要通过已有的‘线索’(观测数据),反推出最合理的‘真相’(概率参数)。
比如,你观察到:
- 在课程难度高(D=高)时,80%的学生选择了长时间学习(A=长)。
- 当学习时间长(A=长)且智商高(C=高)时,90%的学生成绩优秀(B=优)。
MLE的核心思想是:
找到一组概率参数,使得这些观测到的数据出现的可能性最大。就像侦探说:‘根据目前的线索,真相最有可能是这样的!’”
结合具体例子拆解步骤
以课程难度(D)和学习时间(A)的关系为例:
1. 根节点(课程难度D)的概率估计
假设数据中有30%的学生选了高难度课程(D=高),70%选了低难度(D=低)。
MLE的答案:
直接按比例算!

为什么合理?
因为如果数据中30%的人选了高难度课程,那么‘最合理’的猜测就是概率为0.3!
2. 中间节点(学习时间A)的条件概率估计
假设在课程难度高(D=高)的学生中:

为什么合理?
因为观测数据中,高难度课程的学生大部分选择了长时间学习,所以我们‘相信’这个比例最可能接近真实概率!
3. 结果节点(考试成绩B)的条件概率估计
假设在学习时间长(A=长)且智商高(C=高)的学生中:

为什么合理?
因为这些学生大部分成绩优秀,所以‘最可能’的概率是0.9!
最大似然估计就是:
- 数数:统计数据中每种情况出现的次数;
- 算比例:用频率代替概率;
- 相信数据:假设观测到的比例就是最接近真实的概率。
就像学生考试时,如果做10道题错了3道,老师估计你的错误率是30%。这就是MLE的思路!”
优点:
- 简单直观:直接用数据中的频率作为概率,无需复杂计算。
- 数据驱动:参数完全由观测数据决定,避免主观假设。
- 可解释性强:例如,“课程难度高时学习时间长的概率是80%”直接反映了数据中的规律。
缺点:
- 如果某些情况从未出现(比如A=短且C=高的学生成绩优),MLE会直接给出0概率,这在实际中可能不合理(需要数据平滑)。
简单来说,MLE是“让数据自己说话”的工具,它告诉模型:“根据现有数据,最合理的概率应该是这样的!
再给大家介绍几个参数估计的方法:
现在有一个条件,就是智商C,假如这个变量我们是无法观测的,那么如何将条件概率表的参数估计出来呢?

1.2.2 贝叶斯估计(Bayesian Estimation)(先验+数据→后验)
- 功能:通过引入先验分布(prior),结合观测数据计算后验分布(posterior),从而估计参数。
- 与MLE的区别:
- MLE仅基于数据频率,而贝叶斯估计融合了先验知识(例如专家经验)和数据。
- 贝叶斯估计输出的是参数的概率分布(后验分布),而非单一最优值。
- 适用场景:
- 数据量小或存在稀疏数据时(例如某些父节点组合未在数据中出现);
- 需要结合领域知识(如医学诊断中的先验概率)
“同学们,假设你发现班上选高难度课程的同学中,大部分学习时间很长。但如果你只观察了5个学生,其中3人学习时间长,你会直接说‘高难度课程的学生有60%学习时间长’吗?这显然不靠谱!因为数据太少,偶然性太大。
贝叶斯估计的核心思想是:结合经验(先验知识)和实际数据,给出更合理的概率估计,而不是单纯依赖数据。”
我们之前讲过最大似然估计是将数据转换为频率,那么知道了这些现在就可以给大家介绍两种学派了:
- 频率学派:直接统计观测数据中的比例,比如观测到3/5的学生学习时间长,则估计概率为0.6。
- 贝叶斯学派:引入先验知识(例如“高难度课程通常需要更长时间学习”),再结合数据修正估计。
关键区别:贝叶斯估计认为概率是“不确定性的度量”,而非固定值!
方面 频率派 贝叶斯派 概率定义 长期频率 主观信念或知识状态 参数性质 固定未知的常数 具有概率分布的随机变量 推断目标 估计参数值(点估计或区间) 更新参数的后验分布 先验信息 不使用 必须指定先验分布 结果解释 基于重复实验的频率解释 基于当前数据和先验的概率解释
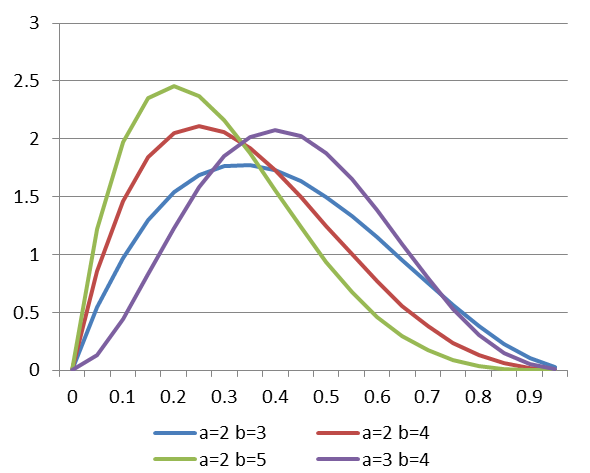
补充内容:“对于二值变量(如A=长/短),贝叶斯估计常用 Beta分布 作为先验分布,公式为:
举例:
- 若认为选高难度课程的学生中,约50%学习时间长,可选择 α=2,β=2(对称分布,均值为0.5)。
- 若认为学习时间长的概率更高,可选择 α=5,β=2(右偏分布,均值为5/7≈0.714)。”

我们还是假定智商C是无法观测的隐变量。


![]()
![]()

结论:该学生智商高的概率为36%。、
- 频率学派:直接统计样本中C=高的比例,但隐变量无法观测,无法直接计算。
- 贝叶斯学派:通过联合分布整合先验知识和观测数据,解决隐变量问题。
关键优势:贝叶斯估计在小数据或隐变量场景下更稳健!
参数更新:
“假设观测到10名D=高、A=长、B=优的学生,其中:
- 实际智商C=高的有3人,C=低的有7人(但C未被记录)。
如何用贝叶斯估计更新智商先验 P(C=高)?”

总结贝叶斯估计的核心步骤

不过在实际应用中,我们不需要这么手动计算,手算只是展示一下数学原理,python的pgmpy库直接提供了这个方法,我们直接调用即可出结果。
1.2.3 EM期望最大化算法(Expectation-Maximization, EM)(处理隐变量)
EM算法是一种迭代优化算法,用于在概率模型中寻找参数的最大似然估计(MLE),尤其适用于包含隐变量(Latent Variable)的不完全数据(如缺失数据、噪声数据)。其核心思想通过交替执行期望(E)步骤和最大化(M)步骤逐步逼近最优参数。
- 功能:处理存在隐变量或数据缺失时的参数估计问题。
- 与MLE的关系:
- 1. EM算法内部通常使用MLE(或MAP)作为迭代步骤的参数更新方法。
- 2. 当数据完整时,EM退化为MLE。

举例:假设C还是隐变量无法被观测。以估计 P(B=优∣A=长,C=高) 为例:
- 观测数据:
- 30名:学习时间长(A=长)且成绩优秀(B=优)
- 10名:学习时间长(A=长)但成绩差(B=差)
- 隐变量:智商(C=高/低)
- 目标:通过EM算法估计参数 θ=P(B=优∣A=长,C=高)。
假设初始值 (即70%的高智商学生学习时间长时成绩优秀)。
(即70%的高智商学生学习时间长时成绩优秀)。
同时假设隐变量C的先验概率均匀分布: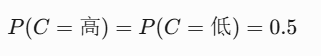
E步(Expectation):计算后验概率



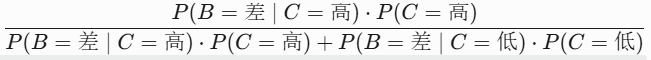
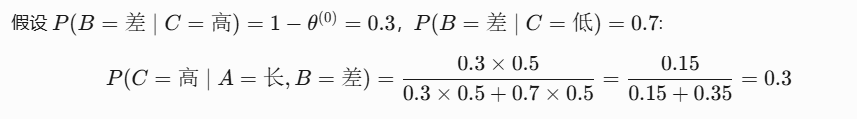
M步(Maximization):更新参数
目标:根据E步的期望计数,更新参数 θ。
-
计算隐变量C=高的期望计数:
- B=优的贡献:30×0.7=21
- B=差的贡献:10×0.3=3
- 总计:21+3=24

迭代与收敛

总结:“EM算法像‘闭着眼睛摸象’,通过不断猜测隐变量,逐步逼近真实参数,但可能停在局部最优解!”
此外,还有一些参数估计的方法比如变分推断(Variational inference,VI),以及马尔科夫链蒙特卡洛(MCMC)算法,这个MCMC算法也比较重要,简单来说就是用于解决高维分布的采样的问题,通过利用马尔可夫链的平稳分布和无记忆性特点与蒙特卡罗方法的通过随机采样逼近积分特点结合而来。这个方法不仅可以用于参数估计,还可以用于解决后面要将到的网络结构学习问题。但是详细讲这个的话又涉及到很多新的概念像:马尔科夫链,吉布斯采样,Metropolis-Hastings(M-H)算法,蒙特卡罗采样等等,所以就简单说一下当作了解内容,大家有兴趣可以自行学习。
这里是以前写的博客可作为知识补充:
总结-如何选择参数估计方法
| 方法 | 核心特点 | 适用场景 |
|---|---|---|
| 变分推断 | 用简单分布逼近复杂后验 | 大数据,速度优先 |
| MCMC | 采样参数和隐变量→后验均值 | 复杂后验,计算资源充足 |
| MLE | 完全依赖数据频率 | 数据充足、无缺失 |
| 贝叶斯/MAP | 结合先验知识 | 数据稀疏、需避免极端估计 |
| EM | 处理隐变量或缺失数据 | 数据不完整 |
- 若数据完整且充足,MLE是最直接的选择;
- 若某些父节点组合未出现(如A=短且C=高),可改用贝叶斯估计或MAP(加入伪计数平滑);
- 若数据存在缺失值(如部分学生的智商未记录),需使用EM算法结合MLE。
2.贝叶斯网络结构学习
上面这个网络结构是直接告诉你们的。但现实中,如果我们只有学生的成绩数据,如何自动发现这些变量之间的因果关系呢?
还有,如果你要处理一个复杂且用人类的视角很难发现,或者不可能发现许多变量间的因果依赖关系,那又该怎么办呢?
我们会思考:
- 可能需要统计变量之间的相关性;
- 但相关性≠因果性(例如冰淇淋销量和溺水人数相关,但高温才是共同原因)。
这就引出了核心问题:
贝叶斯网络结构学习就是从数据中自动推断变量之间的因果关系(箭头方向),而不是依赖人工假设。
2.1 NP难问题(可能性爆炸)
但是自动推断变量之间的因果关系,即寻找网络结构时,还会遇到一个很难的问题,我们举一个例子:
案例回顾:
假设我们要从学生数据(课程难度D、智商C、学习时间A、成绩B)中自动发现因果关系网络。
任务分解:
- 可能的网络结构:每个变量可以有多个父节点(原因),例如:
- D→A→B?
- C←D→B?
- ……(箭头方向和连接组合爆炸式增长)


结论:穷举所有结构在计算上是完全不可行!可能性空间超指数增长,属于N-P难问题。
为什么结构学习是NP难问题?
先理解什么是“计算复杂度”。
想象你要在一堆杂乱的书架上找一本特定的书:
- 简单任务:如果书按书名首字母排序,你几秒钟就能找到 → 这是“高效算法”;
- 困难任务:如果书完全乱放,你可能要一本本翻遍整个书架 → 这是“低效算法”。

什么是“NP难问题”?

通俗解释就是,每个变量是否连接、箭头方向如何去选择,这些变量组合是一个非常庞大的空间,且数量随变量数指数爆炸增长,无法暴力破解。
如何面对这个N-P难问题?即如何寻找优秀的网络结构?
目前的研究有三种方法,我们分别来介绍。
2.2 基于约束(Constrain-based BN learning, CB)的方法
这种方法我也没深入了解过,所以就简单介绍一下。该方法是最早提出的结构学习方法,利用条件独立性测试(Conditional Independence,CI)来学习贝叶斯网络结构,尽可能多地去除变量之间的多余的依赖关系。该方法认为结构学习是约束满足性问题,将贝叶斯网络看作是具有独立变量的结构模型,通过CI检验或者互信息判断变量之间的独立关系,学习变量间的骨架图;再利用V-结构和定向规则对变量间的无向边进行定向,即确定因果方向。但是这种方法存在一些问题:由于需要大量样本来测试独立性,所以基于约束的方法时间代价较大,且有时不可靠的测试会使输入级的错误被放大传导到输出,导致网络的推理结果准确性降低。
1990 年,最早的基于约束的学习算法:SGS(Spirtes-Glymour-Scheines)算法被提出,利用特定的因果模型来判断变量之间的条件独立性,不需要预先知道节点顺序。然而,SGS 算法具有不稳定性,容易影响后续过程,产生较大误差,且学习贝叶斯网络结构过程中需要进行指数级的CI 测试,面对节点稍微多一些的网络,这个方法根本不适用。
后来,Peter 和 Clark 在 SGS 算法基础上进行改进,提出了 PC算法,该算法属于是约束学习里面最为经典的算法。PC算法是从顶点集上生成的完全无向图开始,利用 d-分离判断进行 CI 检测,递归删除边,直至生成需要的网络结构模型。对于稀疏和离散的网络,PC 算法不需要测试高阶独立性关系,大大减少了测试的次数,具有计算量小,复杂程度低的特点。算法在保证独立性判断准确的情况下,结果也具有一定程度的可靠性,但缺点是收敛速度非常非常慢。
刚刚提到了V-结构和D-分离,那么他们都是什么意思呢?
2.2.1 什么是V-结构和D-分离
定义:V-结构(又称碰撞节点、对撞节点)是贝叶斯网络中的一种特殊拓扑结构,由三个节点组成,中间节点是两个父节点的共同子节点,形如:
X → Z ← Y
(X和Y是Z的父节点,Z是碰撞点)
核心特性:
- 无观测时:X和Y独立(没有直接连接,也没有共同父节点)
- 观测Z或其子节点时:X和Y可能变得相关(条件依赖)
- 仅观测Z的某个父节点时:不影响独立性
举个例子,假设医生试图诊断患者发烧的原因:
- X = 病毒感染(是/否)
- Y = 细菌感染(是/否)
- Z = 发烧(是/否)
网络结构:X → Z ← Y(病毒感染或细菌感染都可能导致发烧,但病毒感染和细菌感染本身无关)
1. 无观测时:X和Y独立
- 直觉:病毒感染和细菌感染是两种独立事件,没有直接联系。
- 数学验证:
联合概率分解为:

2. 观测到Z时:X和Y变得相关
- 直觉:如果已知患者发烧(Z=是),发现“病毒感染”(X=否)会提高“细菌感染”(Y=是)的概率。
- 数学验证:
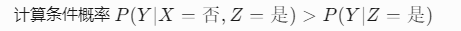
例如:
- 假设病毒感染和细菌感染先验概率均为10%,且发烧在任一感染存在时概率为90%。
- 若已知没有病毒感染(X=否),但患者发烧(Z=是),则细菌感染的概率会显著上升。
3. 观测Z的子节点时:同样会激活相关性
假设增加一个节点:
- W = 检测到白细胞升高(是/否)
结构变为:X → Z ← Y → W - 观测W时(如已知白细胞升高),会间接传递信息到Z,进而让X和Y相关。
V-结构的深层意义
1. 信息流动的方向性
- V-结构体现了贝叶斯网络的“因果不对称性”。
- 正向推理(因果→证据):从原因推断结果(如已知病毒感染,推断发烧概率)。
- 反向推理(证据→因果):从结果推断原因(如已知发烧,推断病毒感染和细菌感染的关系)。
2. 条件独立性动态变化
- d-分离(d-separation)规则:V-结构是贝叶斯网络中唯一一种在给定子节点时父节点变得相关的结构。
- 应用场景:在因果推断中,V-结构可用于识别混杂变量或隐藏变量。
那么什么是D-分离呢?
定义:d-分离(Directed Separation)是贝叶斯网络中判断两个节点是否条件独立的图形化准则。
- 核心思想:如果两个节点间的所有路径都被“阻塞”,则它们条件独立。
- 路径阻塞规则:取决于路径中节点的连接方式和是否被观测(即是否在“条件集”中)。
三种关键路径类型与阻塞规则
贝叶斯网络中的路径由三种基本结构组合而成。下面我们通过举例逐一分析:
1. 顺连路径(Chain/Causal Path)
结构:X → Z → Y
(Z是中间节点,信息从X通过Z传递到Y)
阻塞条件:
- 若Z未被观测:路径未阻塞,X和Y可能相关。
- 若Z被观测:路径被阻塞,X和Y条件独立(即 X⊥Y∣Z)。
案例:
- X=下雨,Z=路滑,Y=车祸
- 如果不知道路滑(Z未观测),下雨(X)会影响车祸(Y)的概率。
- 如果已知路滑(Z已观测),下雨对车祸的直接影响被阻断,X和Y独立。
2. 分连路径(Fork/Common Cause)
结构:X ← Z → Y
(Z是X和Y的共同原因)
阻塞条件:
- 若Z未被观测:路径未阻塞,X和Y可能相关。
- 若Z被观测:路径被阻塞,X和Y条件独立(即 X⊥Y∣Z)。
案例:
- Z=季节,X=下雨,Y=花粉浓度
- 如果不知道季节(Z未观测),下雨(X)和花粉浓度(Y)可能相关(例如夏季多雨且花粉多)。
- 如果已知是春季(Z已观测),下雨和花粉浓度之间的关系由季节解释,X和Y独立。
3. 对撞路径(Collider/V-structure)
结构:X → Z ← Y(V-结构)
(Z是X和Y的共同结果)
阻塞条件:
- 若Z未被观测:路径被阻塞,X和Y独立。
- 若Z被观测:路径未阻塞,X和Y可能相关(即 X⊥Y∣Z)。
- 扩展:若观测Z的子节点(如Z→W),路径也会被激活。
案例:
- X=闪电,Y=洒水器开启,Z=草地湿
- 如果不知道草地湿(Z未观测),闪电(X)和洒水器(Y)独立。
- 如果已知草地湿(Z已观测),闪电和洒水器可能相关(例如草地湿但未闪电,则更可能洒水器开启了)。
常见误区与难点
-
对撞节点的特殊性:
- 对撞节点(V-结构)的观测会创造相关性而非消除,这与我们直觉往往是相反的。
- 例如,在“闪电→草地湿←洒水器”中,观测“草地湿”会使得闪电和洒水器相关。
-
路径激活与子节点观测:即使未直接观测对撞节点Z,但观测Z的子节点(如Z→W)也会激活路径。
-
多路径叠加:若两节点间存在多条路径,需所有路径均被阻塞才能判定d-分离。
d-分离的数学意义
-
概率推断的简化:
- d-分离允许我们直接从图结构判断条件独立性,无需计算复杂的联合概率。
- 例如,在贝叶斯网络参数学习时,可忽略条件独立的变量,降低计算复杂度。
-
因果推理的桥梁:
- d-分离规则反映了因果关系的传递性(如干预后的独立性变化)。
- 例如,在因果图中,若X和Y被d-分离,则干预X不会影响Y。
-
隐含假设的可视化:
- 如果实际数据违背d-分离的独立性,说明图结构可能有误或存在隐藏变量。
2.3 基于评分搜索的方法
这种方法目前应用最广泛,它允许灵活地将专家知识作为结构的先验引入搜索学习过程,利用评分函数来评估每个可能的网络结构是否优秀。但是随着节点数量的增加,基于评分搜索的方法学习网络结构空间数量非常庞大,使得搜索代价过高。所以,设计出一种搜索代价小,且学习到网络结构突破局部最优解找到接近理论最优的变量因果关系,是目前研究比较火爆的热点。
该方法的核心思想是将所有可能的结构作为定义域,将衡量特定结构质量的标准作为评分函数,将寻找最佳结构的过程看作在定义域范围内寻找评分函数最优值的问题。该方法由一个初始网络开始,通过搜索算法对网络结构进行优化操作;之后,使用评分函数对网络结构进行打分,将新网络与旧网络结构的分值进行比较,若评分高于旧网络,则对新网络继续进行优化,直到网络模型不再优化或达到搜索迭代次数限制。
我们既然用了基于评分搜索的方法,那么肯定要选取一个评分函数。评分函数用来评估贝叶斯网络结构与给定数据集的拟合程度,评分函数的适合度直接影响网络模型选择的准确性,所有选择好评分函数非常重要。评分函数主要包含两类:贝叶斯评分函数和信息论评分函数。
(1)贝叶斯评分函数


同贝叶斯评分函数选择模型等价的评分函数有:CH(Cooper-Herskovits,CH)评分、贝叶斯狄利克雷(Bayesian-Dirichlet,BD)评分、分数等效贝叶斯狄利克雷(Bayesian-Dirichlet equivalent,BDe)评分和贝叶斯狄利克雷等效一致性(Bayesian-Dirichlet equivalent uniform,BDeu)评分等。
(2)信息论评分函数
信息论评分函数基于编码长度和信息论的概念将数据集进行压缩,贝叶斯网络的得分与网络对数据集所能实现的压缩程度有关。信息论评分函数包括:最小描述长度准则(Minimum DesriptionLengthMDL)、等效贝叶斯信息准则(Bayesian Information Criterion,BIC)、Akaike 信息准则(AkaikeInformation Criterion,AIC)、归一化极大似然函数(Normalized Maximum Likelihood,NML )和相互信息测试分数(Mutual Information Tests, MIT)等。
经过大量试验分析,贝叶斯评分函数能够应对样本数较大的 DAG 结构,而信息论评分函数对于小样本数据搜索学习到的网络结构更优。
除了选择评分函数,还要选择搜索策略。模型优化是通过搜索策略在所有可行结构组成的空间中寻找评分最高网络结构的过程。实际上,搜索策略才是导致结构学习 NP-难题的核心,即使每个节点的最大父节点数为固定值,搜索空间也是巨大的。有学者引入专家知识指导搜索过程,以达到对搜索空间进行限制的目的,例如 K2算法、K3 算法等;还有学者采取了启发式搜索策略,利用启发信息引导搜索过程,减少搜索范围,降低问题复杂度,比如贪心算法、模拟退火算法、粒子群算法等。
1992 年,Cooper 和 Herskovit 提出了著名的 K2 算法,先根据专家经验确定节点顺序,然后通过贝叶斯评分准则评估候选结构,再使用爬山搜索策略寻找评分最高的模型。K2算法的精度取决于节点序的优劣,K2 算法使用先验信息优化搜索过程,该思路被后续BN 结构学习方法广为借鉴。1994年,又有学者(Bouckaert) 提出了 K3 算法,采用 MDL评分准则,增加了约束网络复杂程度的罚项函数,避免学习模型时出现过拟合。在采用启发式搜索策略的算法中,爬山算法(Hill-Climbing,HC)是一种局部搜索算法,其核心思想是每次都选择局部最优解,分数到达稳定状态后结束搜索,输出最优网络。该算法缺点是全局开发能力弱,容易产生局部最优解。为了解决局部最优的问题,学者们提出了基于单个解的优化算法进行改进,包括:禁忌搜索(Tabu Search,Ts)、模拟退火(Simulated Annealing,SA)等。
近年来,基于自然选择的群体智能(Swarm Intelligence,SI)优化算法引起了学者的广泛关注。这些优化算法包括:遗传算法(GA),进化规划,蚁群优化(ACO),粒子群优化(PSO),布谷鸟优化,象群优化,水循环优化,人工蜂群(ABC)和细菌觅食优化等。基于 SI 的算法共同特点是使用元启发式搜索机制对 BN 结构空间进行探索,通过多次计算对局部模型进行状态更新,在每次计算时都会创建新的种群来寻找局部最优解。随着循环次数的增加,解的质量不断提高,最终可以接近最优模型。
与非 SI方法相比,三种 SI算法在每项指标下几乎一致获得最佳结果,就目前来说应该是最有效的结构学习方法。基于贪婪搜索的算法性能一般,在大多数情况下明显不如三种 SI 算法,基于爬山搜索的算法对噪音的增加不敏感,几乎在所有情况下性能指标都是最差,但从执行时间上是最快的,远远优于其他四种算法,原因是:SI算法是一种基于群体的优化方法,每个个体在每次迭代中都要独立执行优化任务,并完成个体之间的信息交换,因此时间成本较高,同时也获得了较好的鲁棒性。
基于评分搜索的方法与基于约束方法中利用 CI测试及 V-结构定向的学习策略不同,需要确定具体的搜索策略与评分函数。目前可以创新的点主要聚焦四大类:
(1)改进经典启发式搜索策略如禁忌搜索、爬山算法等,使其更好地避免陷入局部最优值,进而学习得到最佳的网络结构;
(2)融合不同类型群智能算法如粒子群算法、蚁群算法等,以达到优势互补的目的,优化算法性能,克服收敛速度慢、精确度低等主要问题;
(3)评分函数选择方面,综合考虑模型对于数据样本的拟合度和模型复杂度,以提高模型质量和学习效率;
(4)设计新的搜索策略方面,综合考虑算法的全局搜索能力和时间复杂度,以减小在搜索过程中出现局部最优解的几率,提高算法的搜索效率。
2.4 混合方法
混合方法是将约束和评分搜索结合在一起,结合二者的优点,通过独立性检验缩小、限制搜索空间,然后再采用基于评分搜索的方式学习最优的网络,此方法适用于节点数量特别多的大型网络。
目前混合搜索算法研究创新点主要集中在以下方面:
(1)探索不同人工智能方法的融合能力,发挥智能算法优势,突破传统算法学习短板,提高贝叶斯网络学习效率与学习精度;
(2)针对强化对大规模复杂网络的学习能力,利用贝叶斯网络本身特点与数据所提供的信息,缩小搜索空间,用启发式信息指导搜索过程,减少搜索盲目性,提高学习效率。
2.5 非完备信息下的结构学习
结构学习算法在一般情况下通常假设数据集是完整的,但真实的数据集往往存在两类情况。一类是部分观测变量数据缺失的情况;另一类是存在无法被观测的变量,这类变量被称为隐结构变量。针对上述两种情况,学者们研究非完备信息下的贝叶斯网络结构学习方法。由于现实各领域积累的数据往往具有非完备性,所以该方向的研究具有良好的工程应用前景。
2.5.1 数据缺失的结构学习
无论是因为偶然性缺失还是系统性缺失,缺失的数据都可以分为三类:随机缺失(MissingAtRandom,MAR),完全随机缺失(Missing Compl-etely At Random,MCAR)和非随机缺失(MissingNotAt Random,MNAR)。MAR 类型数据的缺失依赖于其他已知变量。MCAR 类型数据的缺失是随机发生的,且丢失概率与数据变量已知或未知无关。MNAR 类型数据缺失的概率取决于已观测到和未观测到的数据本身。
在这种情况下,一般的研究点我们就还是以EM算法为基础或者对它进行改进来进行结构学习:
-
结构EM(Structural EM):
- 由Friedman提出,结合EM与结构搜索。
- E步:估计缺失数据的后验分布。
- M步:搜索最优结构(如通过评分函数BIC、MDL)并更新参数。
- 需要权衡计算复杂度,通常采用启发式搜索(如爬山算法)。
-
隐变量引入:
- 假设网络中某些未观测的隐节点影响观测变量,通过EM迭代优化隐变量的结构和参数。
如何将缺失数据合理完备化是非完备信息下贝叶斯网络结构学习的关键
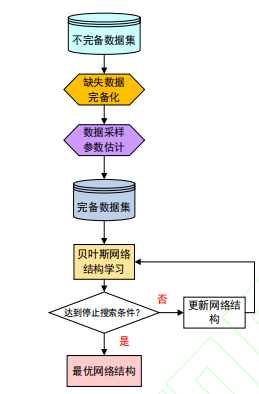
EM 算法具有对初始化数据敏感,计算复杂,收敛较慢,不适用于大规模数据集和高维数据,容易出现陷入局部最优的问题。除了在 EM 算法框架上进行改进,学者们近期还提出了其他一些从含有缺失值的数据中进行的结构学习算法。2019 年提出一种基于吉布斯采样(Gibbs Sampling的马尔科夫链蒙特卡洛(Markov Chain Monte Carlo,MCMC)算法。
Gibbs 采样是一种在节点间局部交互的图形结构中执行的采样过程,用于在难以直接采样时从某一多变量概率分布中近似抽取样本序列,计算其联合概率分布或积分。该算法用于检测变化点的经验贝叶斯信息准则(emBIC),能同时估计变化点配置和相关参数。首先,使用经验贝叶斯和最大似然原理推导出模型选择或变化点选择标准;当观测的后验分布是复杂且高维时,EM 方法只能得到后验分布的众数,此时可以利用 Gibbs 采样对贝叶斯网络的后验分布进行抽样,得到 Gibbs 序列,使其收敛到一个独立于初始值的平稳分布,从而求得如后验均值、方差和分位线等更多的后验量;然后通过在变化点指示器上诱导多变量离散分布,并使用GibbsSampling 从诱导分布生成马尔可夫链来估计最佳变化点配置。该方法相比于 EM 具有更快的收敛速度。
2.5.2 含有隐变量的结构学习
隐变量是指在贝叶斯网络学习中隐藏或潜在的变量,这些变量可以是实际存在但不能被观测的变量,也可以是为了贝叶斯网络学习的合理性而被提出的虚拟变量。例如在某次医学案例中:训练数据集包含医生观察到的症状(如发烧、头痛、血压等)和处方药物,这些已知变量被称为观测变量:而病人自身不能被观测到的症状就是我们所说的隐变量。这些隐变量与大多数观测变量是相互独立的,却又能够对患病“原因”和治疗“结果”的解释产生深远的影响。因此,我们可以通过学习隐藏变量,避免产生对数据的过拟合,提高 BN的可解释性,从而更有效地进行推理。
隐变量大体包括两种:一种是隐变量取值个数已知但数值未知的变量,被称作值隐变量;另外一种则是隐变量取值个数与数值均未知的变量,被称作势隐变量。包含至少一个隐变量的贝叶斯网络模型被称为隐变量模型。在实际应用中往往需要考虑多个隐变量存在的情况,并通过它们与观测变量以及自身之间的关系,通过数据分析得到模型中隐变量的个数、隐变量的势、网络模型结构,以及模型参数,这一过程被称为隐结构模型学习(Latent Structure Model Learning)。
含有隐变量的网络结构学习大多采用数据降维的方法,将具有复杂依赖关系的节点变量分解为少数无法直接观测到的公共因子(隐藏变量),以此来确定网络中含有的隐变量和与之对应的观测变量的位置、数量:之后,再通过 EM 算法等补全隐变量的参数,然后再通过基于约束、分数、混合的方法来搜索。在复杂网络结构中研究隐含变量,能够帮助我们在简化网络的同时,更深入的了解节点间相互影响的方式。
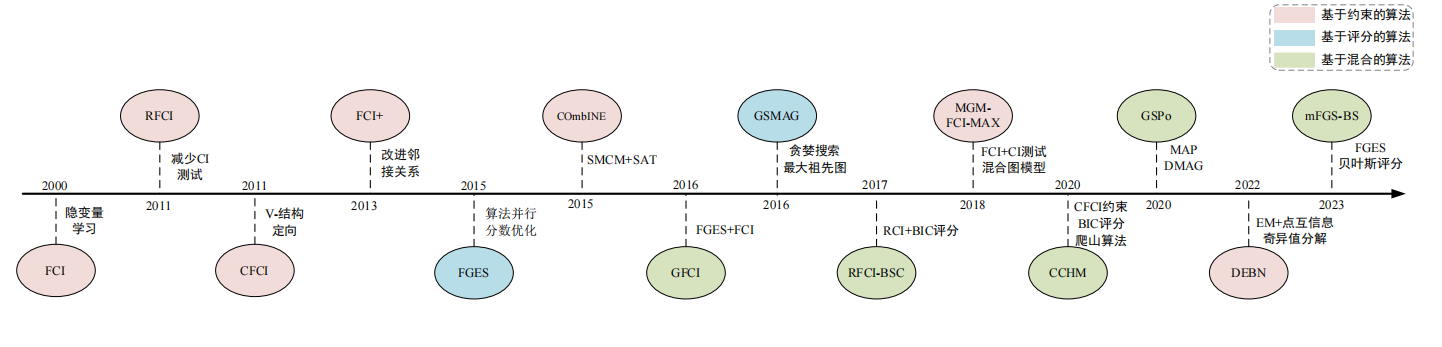
2.6 结构学习的总结与展望
贝叶斯网络因其“白盒性”、工程易用性引起了广泛关注。
针对贝叶斯网络在复杂问题域中存在的模型维数高、学习难度大、易陷入局部最优解等难题,学者们从不同角度提出了多种算法进行改进,并在多个领域的应用中验证了贝叶斯网络的研究和推广价值。
概括来说,基于约束算法以变量间的条件独立性检验为基础,识因果依赖关系,在数据样本完备的条件下,能够学习获得质量较高的贝叶斯网络模型。
基于评分搜索的方法设计评分函数作为贝叶斯网络模型选择指标,多以启发式知识指导模型搜索过程,通过多轮迭代持续优化模型。
混合学习方法可以结合基于约束和基于评分搜索学习算法的优点,通过条件独立性检验缩小搜索空间,并采用基于评分搜索的方法进行网络结构学习,对大型网络学习速度有明显提高。
针对现实应用中的数据往往具有非完备性,从缺失数据处理和隐变量学习两个维度阐释了非完备贝叶斯网络结构学习的研究现状。
我认为,未来贝叶斯网络结构学习的发展趋势如下:
(1)非完备信息条件下的贝叶斯网络学习
在军事决策、大型装备故障诊断等复杂应用领域,非完备信息的存在极大增加了贝叶斯网络结构学习的难度,如何准确的将缺失数据完备化,以及提高含有隐变量模型的学习精确度是未来贝叶斯网
络结构学习研究的热点之一;
(2)大型或高维度贝叶斯网络学习🔺
目前贝叶斯网络学习涉及范围逐渐广泛,复杂领域的需求使得贝叶斯算法逐渐向着善于学习大型网络模型的方向发展。网络中节点的增加会导致贝叶斯网络结构学习准确性降低。因此,在高维度贝叶斯网络算法研究中通常会出现局部最优解的情况,导致最终结果偏差较大。如何解决这些问题,寻求适应大型贝叶斯网络的学习算法也是未来的研究重点
(3)融合人工智能方法的贝叶斯网络学习
随着人工智能技术的进步,很多学者已经尝试研究融合不同智能算法的贝叶斯网络混合学习方法,以发挥不同智能算法的优点,达到学习复杂程度更高的模型,提升算法性能的目的。可以预期,随着智能算法研究的不断深入,通过融合先进算法来不断完善贝叶斯网络模型学习方法将成为未来研究的发展趋势。
3.实际应用
我们都知道,我们做的很多工作都是围绕“防灾减灾”展开的,地震是一种破坏性很强的自然灾害,不管是灾前预防,灾中救援和灾后评估都很重要。贝叶斯网络就可以用来进行对某地区某尺度的地震发生危险性概率进行计算,它会根据设置的多个变量,以及变量间的依赖关系,给出输入观测数据(证据)后,某地区发生地震的危险性概率有多大,根据它计算的后验概率结果,相关的领域专家可以对该地区指定不同的防震预案,从而最大程度地减少人员伤亡和财产损失。
举个例子,假如我想针对云南地区的地震危险性概率做一个统计,首先我们要有数据,比如我们选择地震目录。地震目录我们都知道,它是一种表格数据,里面有发生地震的震级、经纬度、深度,等等。但是对于数据我们知道它是一种类似于“冰山”图的事物,我们能看到的往往只是冰山一角,数据其中潜在的规律和隐性的逻辑,就需要借助机器学习的方式来发掘其中的规律。通过地震目录,我们可以根据一些现有的指标,设计出一些变量作为贝叶斯网络的节点,比如我们现在设计一个节点叫做“该地区过去3个月5级以上地震的发生频率”,等等,然后结果节点定为“该地区下个月是否发生5.0以上的地震”。(变量(节点)的设计出自《2021年度全国震情短临跟踪和会商研判技术方案》)


设计出变量以后,为了构建贝叶斯网络,我们还需要对变量添加因果关系。但是我们之前说了:相关≠因果。所以构建因果关系时,我们是很难,几乎不可能去人工去设计的,尤其是对于地震这种自然灾害。目前就是说,地震局尝试过去依靠专家知识来构建贝叶斯网络来处理一些问题,我也看了,但是这种网络都存在一个问题:我们以专家的知识先验去构建时只考虑了单向因果,就是A影响B,C也影响B,而且搭建的因果关系还不一定对,可能只是“浮于表面”的虚假因果关系,但构建不了,或者说人凭知识很难去发现一些变量可能潜在的一些双向因果影响。
所以,我们可以用结构学习的方式,去自动的构建一个贝叶斯网络,让机器去学习,去发现这其中的因果关系。这也是我们之前说的“破除虚假因果,去寻找真正的因果关系”。而且通过贝叶斯网络,一个复杂的预测问题,就被分解成了简单的收集多变量观测数据的问题。
根据地震目录的统计,我们可以提供一个先验概率给贝叶斯网络。随后,随着观测数据的不断增加,贝叶斯网络在进行最大似然估计的时候会不停的更新条件概率表,使得模型越来越趋于准确。
假如说,根据地震目录,我们发现云南地区下个月发生5.0以上地震的概率是0.00017%,但是经过观测数据作为证据后,后验概率上升至了4%,这就很说明问题了!后验概率提高意味着“有了新证据的支持我们对地震发生信任度提升了”说明证据让地震发生的危险更可信了。这时候工作人员看到模型得到了这个结果,就要及时的商讨,制定防震预案了。
4. 总结:贝叶斯网络有什么优点
那么说到这里,我们总结一下,为什么有些问题要用贝叶斯网络来解决?贝叶斯网络相比于当下最热门的深度学习,它的独特优势在哪?
-
数据依赖度(以粉笔盒为例)
- 贝叶斯网络:像这个粉笔盒,用10根粉笔就能搭建稳定结构 → 适应小样本数据
- 深度学习:需要装满整个盒子的粉笔才能立稳 → 依赖海量数据
- 例:某地区过去百年来的有记录的特大地震只有零零散散几例,那么用贝叶斯网络来更加合适。
-
推理逻辑可视化(透明/黑箱对比图)
- 贝叶斯网络:如同透明管道,每个节点的水流(概率)流向可见,贝叶斯网络是一个白盒模型,这个特性非常非常重要!
- 深度学习:像封闭的消防栓,输入输出可见,内部运作不可解释
- 例:深度学习的模型预测不太能让专业人员信服,因为你说不出来为什么。即使用上最新的XAI这种可解释问题,不可信问题依然存在。而贝叶斯网络可以清晰表达为什么该地区下个月大概率有发生地震的危险,它是有理有据的。
-
不确定性量化能力
- 同时处理随机不确定性和认知不确定性(用天气预报举例)
- 输出完整概率分布而非单点预测(对比深度学习输出置信度)
- 案例:航空航天领域,火箭发射决策需要知道"成功概率89%±3%"而不是光输出一个"成功"就行了
那我们什么场景下用贝叶斯网络比较好呢?
-
是否需要解释决策路径?
- 是 → 选择贝叶斯网络(如法律量刑辅助系统)
- 否 → 考虑深度学习(如图像风格迁移)
-
数据量是否充足?
- <1000样本 → 贝叶斯网络(如考古文物年代鉴定)
- 10万样本 → 可尝试深度学习(如电商推荐系统)
-
是否存在明确因果关系?
- 是 → 贝叶斯网络(如流行病传播建模)
- 否 → 深度学习(如自然语言生成)
为什么NASA的故障检测系统坚持使用贝叶斯网络?
可靠性需求:必须明确知道每个报警信号的产生逻辑
资源限制:航天器搭载的计算芯片不能支撑大模型运行
知识传承:数十年积累的故障树知识可直接转化为网络结构
(敲黑板)记住这个核心:贝叶斯网络是用人类理解世界的方式建模,而深度学习是在用机器理解数据的方式建模。当我们需要与人类认知对齐、资源有限且重视解释性时,贝叶斯网络就是更优解。
(后续内容5月继续更新)

















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









