







释放pytorch占用的gpu显存_Pytorch释放显存占用方式
计算复杂度
from thop import profile
model = resnet50()
input = torch.randn(1, 3, 224, 224)
macs, params = profile(model, inputs=(input, ))macs把一次乘法和加减当成一次运算,其实复杂度是 macs的1-2倍,一般取2
from thop import profile
filepath = './weightsresnet18/last224stand_sit_resnet18.pth'
checkpoint = torch.load(filepath)
model = checkpoint['model'] # 提取网络结构
model.load_state_dict(checkpoint['model_state_dict']) # 加载网络权重参数
model.eval()
import torch
from thop import profile
input = torch.randn(1, 3, 224,224).cuda()
flops, params = profile(model, inputs=(input, ))
print(flops/1e9, params/1e6,)下面代码是更改profile增加模型访存量的计算
#profile计算计算量的函数更改成下面的
def profile_macs(model: nn.Module, inputs, custom_ops=None, verbose=True):
handler_collection = {}
types_collection = set()
if custom_ops is None:
custom_ops = {}
def add_hooks(m: nn.Module):
m.register_buffer('total_ops', torch.zeros(1, dtype=torch.float64))
m.register_buffer('total_params', torch.zeros(1, dtype=torch.float64))
# m.register_buffer('',torch.zeros(1,dtype=torch.float64))
m.register_buffer('total_kernel_macs',torch.zeros(1,dtype=torch.float64))
m.register_buffer('total_output_macs',torch.zeros(1,dtype=torch.float64))
# for p in m.parameters():
# m.total_params += torch.DoubleTensor([p.numel()])
m_type = type(m)
fn = None
print(m_type)
if m_type in custom_ops: # if defined both op maps, use custom_ops to overwrite.
fn = custom_ops[m_type]
if m_type not in types_collection and verbose:
print("[INFO] Customize rule %s() %s." % (fn.__qualname__, m_type))
elif m_type in register_hooks:
fn = register_hooks[m_type]
if m_type not in types_collection and verbose:
print("[INFO] Register %s() for %s." % (fn.__qualname__, m_type))
else:
if m_type not in types_collection and verbose:
prRed("[WARN] Cannot find rule for %s. Treat it as zero Macs and zero Params." % m_type)
if fn is not None:
handler_collection[m] = (m.register_forward_hook(fn), m.register_forward_hook(count_parameters))
types_collection.add(m_type)
prev_training_status = model.training
model.eval()
model.apply(add_hooks)
with torch.no_grad():
model(*inputs)
def dfs_count_macs(module: nn.Module, prefix="\t") -> (int, int):
# total_ops, total_params = 0, 0
total_ops, total_params, total_kernel_macs, total_output_macs = module.total_ops.item(), 0, 0, 0
ret_dict = {}
for n, m in module.named_children():
# if not hasattr(m, "total_ops") and not hasattr(m, "total_params"): # and len(list(m.children())) > 0:
# m_ops, m_params = dfs_count(m, prefix=prefix + "\t")
# else:
# m_ops, m_params = m.total_ops, m.total_params
next_dict = {}
if m in handler_collection and not isinstance(m, (nn.Sequential, nn.ModuleList)):
# m_ops, m_params = m.total_ops.item(), m.total_params.item()
m_ops, m_params, m_kernel_macs, m_output_macs = m.total_ops.item(), m.total_params.item(), m.total_kernel_macs.item(), m.total_output_macs.item()
else:
# m_ops, m_params = dfs_count(m, prefix=prefix + "\t")
m_ops, m_params, m_kernel_macs, m_output_macs, next_dict = dfs_count_macs(m, prefix=prefix + "\t")
ret_dict[n] = (m_ops, m_params, m_kernel_macs, m_output_macs, next_dict)
total_ops += m_ops
total_params += m_params
total_kernel_macs += m_kernel_macs
total_output_macs += m_output_macs
# print(prefix, module._get_name(), (total_ops.item(), total_params.item()))
# return total_ops, total_params
return total_ops, total_params, total_kernel_macs, total_output_macs, ret_dict
# total_ops, total_params = dfs_count(model)
total_ops, total_params, total_kernel_macs, total_output_macs, ret_dict = dfs_count_macs(model)
# reset model to original status
model.train(prev_training_status)
for m, (op_handler, params_handler) in handler_collection.items():
op_handler.remove()
params_handler.remove()
m._buffers.pop("total_ops")
m._buffers.pop("total_params")
m._buffers.pop("total_kernel_macs")
m._buffers.pop("total_output_macs")
return total_ops, total_params, total_kernel_macs, total_output_macs
#各个算子的访存量计算成这个样的
import argparse
import logging
import torch
import torch.nn as nn
from torch.nn.modules.conv import _ConvNd
multiply_adds = 1
def count_parameters(m, x, y):
total_params = 0
for p in m.parameters():
total_params += torch.DoubleTensor([p.numel()])
m.total_params[0] = total_params
def zero_ops(m, x, y):
m.total_ops += torch.DoubleTensor([int(0)])
def count_convNd(m: _ConvNd, x: (torch.Tensor,), y: torch.Tensor):
x = x[0]
kernel_ops = torch.zeros(m.weight.size()[2:]).numel() # Kw x Kh
bias_ops = 1 if m.bias is not None else 0
# N x Cout x H x W x (Cin x Kw x Kh + bias)
total_ops = y.nelement() * (m.in_channels // m.groups * kernel_ops + bias_ops)
m.total_ops += torch.DoubleTensor([int(total_ops)])
total_kernel_macs = kernel_ops * m.in_channels * m.out_channels # K^2 * C_in * C_out
m.total_kernel_macs += torch.DoubleTensor([int(total_kernel_macs)])
total_output_macs = y.nelement() # N x Cout x H x W
m.total_output_macs += torch.DoubleTensor([int(total_output_macs)])
def count_convNd_ver2(m: _ConvNd, x: (torch.Tensor,), y: torch.Tensor):
x = x[0]
# N x H x W (exclude Cout)
output_size = torch.zeros((y.size()[:1] + y.size()[2:])).numel()
# Cout x Cin x Kw x Kh
kernel_ops = m.weight.nelement()
if m.bias is not None:
# Cout x 1
kernel_ops += + m.bias.nelement()
# x N x H x W x Cout x (Cin x Kw x Kh + bias)
m.total_ops += torch.DoubleTensor([int(output_size * kernel_ops)])
def count_bn(m, x, y):
x = x[0]
nelements = x.numel()
if not m.training:
# subtract, divide, gamma, beta
total_ops = 2 * nelements
m.total_ops += torch.DoubleTensor([int(total_ops)])
total_output_macs = y.nelement()
m.total_output_macs += torch.DoubleTensor([int(total_output_macs)])
def count_relu(m, x, y):
x = x[0]
nelements = x.numel()
m.total_ops += torch.DoubleTensor([int(nelements)])
total_output_macs = y.nelement()
m.total_output_macs += torch.DoubleTensor([int(total_output_macs)])
def count_softmax(m, x, y):
x = x[0]
batch_size, nfeatures = x.size()
total_exp = nfeatures
total_add = nfeatures - 1
total_div = nfeatures
total_ops = batch_size * (total_exp + total_add + total_div)
m.total_ops += torch.DoubleTensor([int(total_ops)])
total_output_macs = y.nelement()
m.total_output_macs += torch.DoubleTensor([int(total_output_macs)])
def count_avgpool(m, x, y):
# total_add = torch.prod(torch.Tensor([m.kernel_size]))
# total_div = 1
# kernel_ops = total_add + total_div
kernel_ops = 1
num_elements = y.numel()
total_ops = kernel_ops * num_elements
m.total_ops += torch.DoubleTensor([int(total_ops)])
total_output_macs = y.nelement()
m.total_output_macs += torch.DoubleTensor([int(total_output_macs)])
def count_adap_avgpool(m, x, y):
kernel = torch.DoubleTensor([*(x[0].shape[2:])]) // torch.DoubleTensor(list((m.output_size,))).squeeze()
total_add = torch.prod(kernel)
total_div = 1
kernel_ops = total_add + total_div
num_elements = y.numel()
total_ops = kernel_ops * num_elements
m.total_ops += torch.DoubleTensor([int(total_ops)])
total_output_macs = y.nelement()
m.total_output_macs += torch.DoubleTensor([int(total_output_macs)])
# TODO: verify the accuracy
def count_upsample(m, x, y):
if m.mode not in ("nearest", "linear", "bilinear", "bicubic",): # "trilinear"
logging.warning("mode %s is not implemented yet, take it a zero op" % m.mode)
return zero_ops(m, x, y)
if m.mode == "nearest":
return zero_ops(m, x, y)
x = x[0]
if m.mode == "linear":
total_ops = y.nelement() * 5 # 2 muls + 3 add
elif m.mode == "bilinear":
# https://en.wikipedia.org/wiki/Bilinear_interpolation
total_ops = y.nelement() * 11 # 6 muls + 5 adds
elif m.mode == "bicubic":
# https://en.wikipedia.org/wiki/Bicubic_interpolation
# Product matrix [4x4] x [4x4] x [4x4]
ops_solve_A = 224 # 128 muls + 96 adds
ops_solve_p = 35 # 16 muls + 12 adds + 4 muls + 3 adds
total_ops = y.nelement() * (ops_solve_A + ops_solve_p)
elif m.mode == "trilinear":
# https://en.wikipedia.org/wiki/Trilinear_interpolation
# can viewed as 2 bilinear + 1 linear
total_ops = y.nelement() * (13 * 2 + 5)
m.total_ops += torch.DoubleTensor([int(total_ops)])
total_output_macs = y.nelement()
m.total_output_macs += torch.DoubleTensor([int(total_output_macs)])
# nn.Linear
def count_linear(m, x, y):
# per output element
total_mul = m.in_features
# total_add = m.in_features - 1
# total_add += 1 if m.bias is not None else 0
num_elements = y.numel()
total_ops = total_mul * num_elements
m.total_ops += torch.DoubleTensor([int(total_ops)])
total_output_macs = y.nelement()
m.total_output_macs += torch.DoubleTensor([int(total_output_macs)])
total_kernel_macs = m.in_features * num_elements
m.total_kernel_macs += torch.DoubleTensor([int(total_kernel_macs)])
from models.CBN_model import CBRES2 as md
model = md()
from thop import profile_macs
input = torch.randn(1, 16, 448,448)
flops, params,kmacs,omacs = profile_macs(model, inputs=(input, ))
# flops = (flops*224/)
omacs = omacs
print(flops/1e9*2, params/1e6,(kmacs/1e6+omacs/1e6)*8)
#kmacs是kernel的访存,omacs是输出的访存,随后*8是因为python中float32是8个字节
print(flops/1e9*2, params/1e6,(kmacs/1e6+omacs/1e6)*8)https://blog.51cto.com/u_16213599/8039726
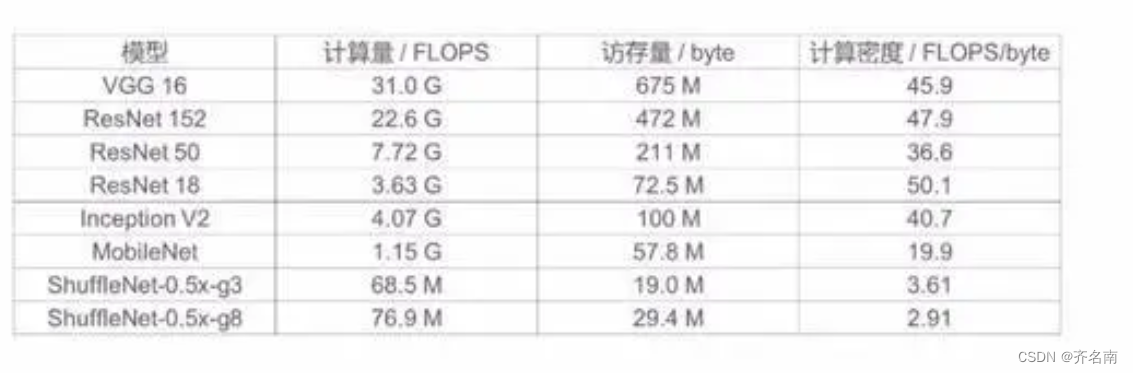
6种方法计算神经网络参数量Params、计算量FLOPs、Macs简单代码_计算网络的param和glops的方法-CSDN博客
【原创】如何解决python进程被kill掉后GPU显存不释放的问题_jzrita的博客-CSDN博客_python 释放gpu内存














 1326
1326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









