







5.Redis【Java面试第三季】
前言
2023-2-4 09:57:18
以下内容源自
【尚硅谷Java大厂面试题第3季,跳槽必刷题目+必扫技术盲点(周阳主讲)-哔哩哔哩】
仅供学习交流使用
推荐
Java开发常见面试题详解(LockSupport,AQS,Spring循环依赖,Redis)
5.Redis
40_redis版本升级说明
1.安装redis6.0.8
- Redis官网:https://redis.io/
- Redis中文网:http://redis.cn/
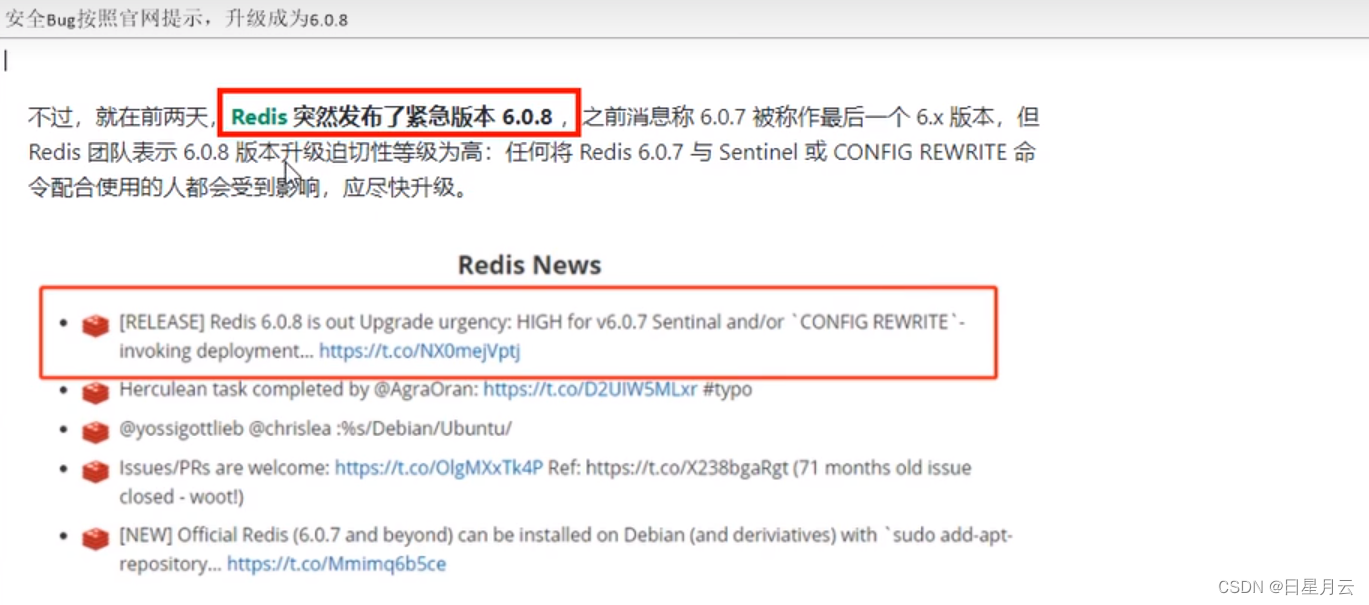
- 安全Bug按照官网提示,升级成为6.0.8
进入Redis命令行,输入info,返回关于Redis服务器的各种信息(包括版本号)和统计数值。
PS D:\Desktop> redis-server -v
Redis server v=3.2.100 sha=00000000:0 malloc=jemalloc-3.6.0 bits=64 build=dd26f1f93c5130ee
PS D:\Desktop> redis-cli
127.0.0.1:6379>
PS D:\Desktop> redis-cli
127.0.0.1:6379> server
127.0.0.1:6379> info
# Server
redis_version:3.2.100
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:dd26f1f93c5130ee
redis_mode:standalone
os:Windows
arch_bits:64
multiplexing_api:WinSock_IOCP
process_id:7708
run_id:2cbe9a9a6851280c5c5684938945530f55e6675d
tcp_port:6379
uptime_in_seconds:456
uptime_in_days:0
hz:10
lru_clock:14532145
executable:E:\Redis-x64-3.2.100\redis-server.exe
config_file:
要升级成6,一定要升级到6.0.8
以下学习345都行
41_redis两个小细节说明
redis基本类型:
- string
- list
- set
- zset(sorted set)
- hash
除了上述5大数据类型,其他redis的类型
- bitmap
- HyperLogLogs
- GEO
- Stream
2.redis传统五大数据类型的落地应用
官网命令大全网址
http://www.redis.cn/commands.html
8大类型
1.String(字符类型)
2.Hash(散列类型)
3.List(列表类型)
4.set(集合类型)
5.SortedSet(有序集合类型,简称zset)
6.Bitmap(位图)
7.HyperLogLog(统计)
8.GEO(地理)
备注
- 命令不区分大小写,而key是区分大小写的
- help @类型名词
42_string类型使用场景
string
最常用
SET key valueGET key
同时设置/获取多个键值
MSET key value [key value…]MGET key [key…]
数值增减
- 递增数字
INCR key(可以不用预先设置key的数值。如果预先设置key但值不是数字,则会报错) - 增加指定的整数
INCRBY key increment - 递减数值
DECR key - 减少指定的整数
DECRBY key decrement
获取字符串长度
STRLEN key
分布式锁
SETNX key valueSET key value [EX seconds] [PX milliseconds] [NX|XX]- EX:key在多少秒之后过期
- PX:key在多少毫秒之后过期
- NX:当key不存在的时候,才创建key,效果等同于setnx
- XX:当key存在的时候,覆盖key
应用场景
- 商品编号、订单号采用INCR命令生成
- 是否喜欢的文章
- 阅读数:只要点击了rest地址,直接可以使用incr key命令增加一个数字1,完成记录数字。
43_hash类型使用场景
hash
Redis的Hash类型相当于Java中Map<String, Map<Object, Object>>
一次设置一个字段值
HSET key field value
一次获取一个字段值
HGET key field
一次设置多个字段值
HMSET key field value [field value …]
一次获取多个字段值
HMGET key field [field …]
获取所有字段值
HGETALL key
获取某个key内的全部数量
HLEN
删除一个key
HDEL
应用场景
-
购物车早期,当前小中厂可用
- 新增商品
hset shopcar:uid1024 334488 1 - 新增商品
hset shopcar:uid1024 334477 1 - 增加商品数量
hincrby shopcar:uid1024 334477 1 - 商品总数
hlen shopcar:uid1024 - 全部选择
hgetall shopcar:uid1024
- 新增商品
44_list类型使用场景
list
向列表左边添加元素
LPUSH key value [value …]
向列表右边添加元素
RPUSH key value [value …]
查看列表
LRANGE key start stop
获取列表中元素的个数
LLEN key
应用场景
- 微信文章订阅公众号
大V作者李永乐老师和CSDN发布了文章分别是11和22
阳哥关注了他们两个,只要他们发布了新文章,就会安装进我的List
lpush likearticle:阳哥id11 22
查看阳哥自己的号订阅的全部文章,类似分页,下面0~10就是一次显示10条
lrange likearticle:阳哥id 0 10
45_set类型使用场景
set
添加元素
SADD key member [member …]
删除元素
SREM key member [member …]
获取集合中的所有元素
SMEMBERS key
判断元素是否在集合中
SISMEMBER key member
获取集合中的元素个数
SCARD key
从集合中随机弹出一个元素,元素不删除
SRANDMEMBER key [数字]
从集合中随机弹出一个元素,出一个删一个
SPOP key[数字]
集合运算
- 集合的差集运算A - B
- 属于A但不属于B的元素构成的集合
SDIFF key [key …]
- 集合的交集运算A ∩ B
- 属于A同时也属于B的共同拥有的元素构成的集合
SINTER key [key …]
- 集合的并集运算A U B
- 属于A或者属于B的元素合并后的集合
SUNION key [key …]
应用场景
- 微信抽奖小程序
- 用户ID,立即参与按钮
SADD key 用户ID - 显示已经有多少人参与了、上图23208人参加
SCARD key - 抽奖(从set中任意选取N个中奖人)
SRANDMEMBER key 2(随机抽奖2个人,元素不删除)
SPOP key 3(随机抽奖3个人,元素会删除)
- 微信朋友圈点赞
- 新增点赞
sadd pub:msglD 点赞用户ID1 点赞用户ID2 - 取消点赞
srem pub:msglD 点赞用户ID - 展现所有点赞过的用户
SMEMBERS pub:msglD - 点赞用户数统计,就是常见的点赞红色数字
scard pub:msgID - 判断某个朋友是否对楼主点赞过
SISMEMBER pub:msglD用户ID
- 微博好友关注社交关系
- 共同关注:我去到局座张召忠的微博,马上获得我和局座共同关注的人
sadd s1 1 2 3 4 5
sadd s2 3 4 5 6 7
SINTER s1 s2 - 我关注的人也关注他(大家爱好相同)
sadd s1 1 2 3 4 5
sadd s2 3 4 5 6 7
SISMEMBER s1 3
SISMEMBER s1 2
- 共同关注:我去到局座张召忠的微博,马上获得我和局座共同关注的人
- QQ内推可能认识的人
sadd s1 1 2 3 4 5
sadd s2 3 4 5 6 7
SINTER s1 s2
SDIFF s1 s2
SDIFF s2 s1
46_zset类型使用场景
zset
向有序集合中加入一个元素和该元素的分数
添加元素
ZADD key score member [score member …]
按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素
ZRANGE key start stop [WITHSCORES]
获取元素的分数
ZSCORE key member
删除元素
ZREM key member [member …]
获取指定分数范围的元素
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
增加某个元素的分数
ZINCRBY key increment member
获取集合中元素的数量
ZCARD key
获得指定分数范围内的元素个数
ZCOUNT key min max
按照排名范围删除元素
ZREMRANGEBYRANK key start stop
获取元素的排名
-
从小到大
ZRANK key member -
从大到小
ZREVRANK key member
建议:score设置为固定不变的量
应用场景
- 根据商品销售对商品进行排序显示
思路:定义商品销售排行榜(sorted set集合),key为goods:sellsort,分数为商品销售数量。
- 商品编号1001的销量是9,商品编号1002的销量是15
zadd goods:sellsort 9 1001 15 1002 - 有一个客户又买了2件商品1001,商品编号1001销量加2
zincrby goods:sellsort 2 1001 - 求商品销量前10名
ZRANGE goods:sellsort 0 10 withscores
- 抖音热搜
- 点击视频
ZINCRBY hotvcr:20200919 1 八佰
ZINCRBY hotvcr:20200919 15 八佰 2 花木兰 - 展示当日排行前10条
ZREVRANGE hotvcr:20200919 0 9 withscores
3.知道分布式锁吗?有哪些实现方案?你谈谈对redis分布式锁的理解,删key的时候有什么问题?
61_redis内存调整默认查看
4.redis缓存过期淘汰策略
粉丝反馈的面试题
- 生产上你们的redis内存设置多少?
- 如何配置、修改redis的内存大小
- 如果内存满了你怎么办?
- redis清理内存的方式?定期删除和惰性删除了解过吗
- redis缓存淘汰策略
- redis的LRU了解过吗?可否手写一个LRU算法
- 。。。
Redis内存满了怎么办
Redis默认内存多少?在哪里查看?如何设置修改?
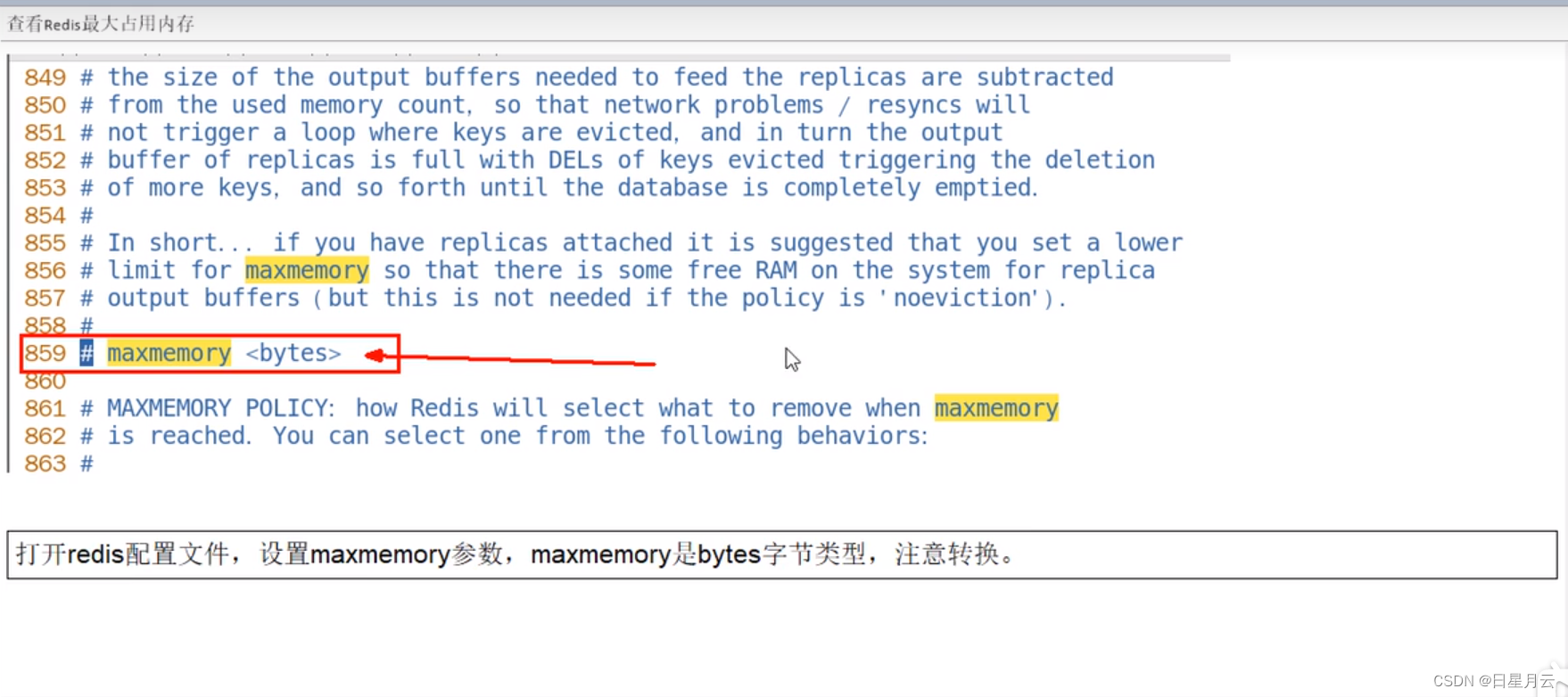
查看Redis最大占用内存
- 配置文件redis.conf的maxmemory参数,maxmemory是bytes字节类型,注意转换。
redis默认内存多少可以用?
- 如果不设置最大内存大小或者设置最大内存大小为0,在64位操作系统下不限制内存大小,在32位操作系统下最多使用3GB内存
一般生产上你如何配置?
- 一般推荐Redis设置内存为最大物理内存的四分之三。
如何修改redis内存设置
- 修改配置文件redis.conf的maxmemory参数,如:
maxmemory 104857600 - 通过命令修改
config set maxmemory 1024
config get maxmemory
什么命令查看redis内存使用情况?
info memory
62_redis打满内存OOM
真要打满了会怎么样?如果Redis内存使用超出了设置的最大值会怎样?
我改改配置,故意把最大值设为1个byte试试
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "0"
127.0.0.1:6379> config set maxmemory 1
OK
127.0.0.1:6379> set a 123
(error) OOM command not allowed when used memory > 'maxmemory'.
结论
- 设置了maxmemory的选项,假如redis内存使用达到上限
- 没有加上过期时间就会导致数据写满maxmemory
为了避免类似情况,引出下一章内存淘汰策略
63_redis内存淘汰策略
redis缓存淘汰策略
往redis里写的数据是怎么没了的?
redis过期键的删除策略
如果一个键是过期的,那它到了过期时间之后是不是马上就从内存中被被删除呢?
如果回答yes,你自己走还是面试官送你?
如果不是,那过期后到底什么时候被删除呢??是个什么操作?
三种不同的删除策略
定期删除
Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。
立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力,让CPU心累,时时需要删除,忙死。
这会产生大量的性能消耗,同时也会影响数据的读取操作。
- 总结:对CPU不友好,用处理器性能换取存储空间(拿时间换空间)
惰性删除
数据到达过期时间,不做处理。等下次访问该数据时,
如果未过期,返回数据;
发现已过期,删除,返回不存在。
惰性删除策略的缺点是,它对内存是最不友好的。
如果一个键已经过期,而这个键又仍然保留在数据库中,那么只要这个过期键不被删除,它所占用的内存就不会释放。
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏 – 无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息。
- 总结:对memory不友好,用存储空间换取处理器性能(拿空间换时间)
上面两种方案都走极端
定期删除
定期删除策略是前两种策略的折中:
定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
周期性轮询Redis库中的时效性数据,来用随机抽取的策略,利用过期数据占比的方式控制删除频度
特点1:CPU性能占用设置有峰值,检测频度可自定义设置
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
总结:周期性抽查存储空间(随机抽查,重点抽查)
举例:
redis默认每个100ms检查,是否有过期的key,有过期key则删除。注意:redis不是每隔100ms将所有的key检查一次而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis直接进去ICU)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
定期删除策略的难点是确定删除操作执行的时长和频率:如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将CPU时间过多地消耗在删除过期键上面。如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除束略一样,出现浪费内存的情况。因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
- 定期抽样key,判断是否过期(存在漏网之鱼)
上述步骤都过堂了,还有漏洞吗?
- 定期删除时,从来没有被抽查到
- 惰性删除时,也从来没有被点中使用过
上述2步骤====>大量过期的key堆积在内存中,导致redis内存空间紧张或者很快耗尽
必须要有一个更好的兜底方案
内存淘汰策略登场
有哪些(redis6.0.8版本)
- noeviction:不会驱逐任何key
- volatile-lfu:对所有设置了过期时间的key使用LFU算法进行删除
- volatile-Iru:对所有设置了过期时间的key使用LRU算法进行删除
- volatile-random:对所有设置了过期时间的key随机删除
- volatile-ttl:删除马上要过期的key
- allkeys-lfu:对所有key使用LFU算法进行删除
- allkeys-Iru:对所有key使用LRU算法进行删除
- allkeys-random:对所有key随机删除
上面总结
- 2*4得8
- 2个维度
- 过期键中筛选
- 所有键中筛选
- 4个方面
- LRU
- LFU
- random
- ttl(Time To Live)
- 8个选项
你平时用哪一种
allkeys-Iru:对所有key使用LRU算法进行删除
不使用noeviction,redis服务会崩
不敢使用random,可能删除热点key
如何配置、修改
- 命令
config set maxmemory-policy noevictionconfig get maxmemory
- 配置文件
- 配置文件redis.conf的maxmemory-policy参数
64_lru算法简介
5. redis的LRU算法简介
Redis的LRU了解过吗?可否手写一个LRU算法
是什么
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法
选择最近最久未使用的数据予以淘汰。
算法来源
LeetCode - Medium - 146. LRU Cache
65_lru的思想
设计思想
1.所谓缓存,必须要有读+写两个操作,按照命中率的思路考虑,写操作+读操作时间复杂度都需要为O(1)
2.特性要求
2.1 必须要有顺序之分,一区分最近使用的和很久没有使用的数据排序。
2.2 写和读操作一次搞定。
2.3 如果容量(坑位)满了要删除最不长用的数据,每次新访问还要把新的数据插入到队头(按照业务你自己设定左右那一边是队头)
查找快、插入快、删除快,且还需要先后排序---------->什么样的数据结构可以满足这个问题?
你是否可以在O(1)时间复杂度内完成这两种操作?
如果一次就可以找到,你觉得什么数据结构最合适?
- LRU的算法核心是哈希链表
本质就是HashMap + DoubleLinkedList
时间复杂度是O(1),哈希表+双向链表的结合体
编码手写如何实现LRU
66_巧用LinkedHashMap完成lru算法
- 参考LinkedHashMap
This kind of map is well-suited to building LRU caches. - 依赖JDK
案例01
package lru;
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCacheDemo<K,V> extends LinkedHashMap<K,V> {
private int capacity;//缓存坑位
/**
*
* accessOrder – the ordering mode -
* true for access-order,
* false for insertion-order
*/
public LRUCacheDemo(int capacity) {
super(capacity,0.75f,true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return super.size() > capacity;
}
public static void main(String[] args) {
LRUCacheDemo lruCacheDemo = new LRUCacheDemo(3);
lruCacheDemo.put(1,"a");
lruCacheDemo.put(2,"b");
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());//[1, 2, 3]
lruCacheDemo.put(4,"d");
System.out.println(lruCacheDemo.keySet());//[2, 3, 4]
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());//[2, 4, 3]
lruCacheDemo.put(4,"d");
System.out.println(lruCacheDemo.keySet());//[2, 3, 4]
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());//[2, 4, 3]
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());//[2, 4, 3]
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());//[2, 4, 3]
lruCacheDemo.put(5,"x");
System.out.println(lruCacheDemo.keySet());//[4, 3, 5]
}
/**
* accessOrder – the ordering mode -
* true for access-order, 访问顺序
* [1, 2, 3]
* [2, 3, 4]
* [2, 4, 3]
* [2, 3, 4]
*
* [2, 4, 3]
* [2, 4, 3]
* [2, 4, 3]
*
* [4, 3, 5]
*/
/**
*
* accessOrder – the ordering mode -
* false for insertion-order 插入顺序
*
* [1, 2, 3]
* [2, 3, 4]
* [2, 3, 4]
* [2, 3, 4]
*
* [2, 3, 4]
* [2, 3, 4]
* [2, 3, 4]
*
* [3, 4, 5]
*/
}
67_手写LRU-上
案例02
- 不依赖JDK
完成数据结构 哈希表 + 双向链表
package lru;
import java.util.HashMap;
import java.util.Map;
public class LRUCacheDemo {
//map复杂查找,构建一个虚拟的双向链表,它里面安装的就是一个个Node结点,作为数据载体。
//构造一个Node结点,作为数据载体。
class Node<K,V>{
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
public Node() {
this.prev = this.next = null;
}
public Node(K key, V value) {
this.key = key;
this.value = value;
this.prev = this.next = null;
}
}
//2 构造一个双向队列,里面安放的就是我们的Node
class DoubleLinkedList<K, V>{
Node<K, V> head;
Node<K, V> tail;
//2.1构造方法
public DoubleLinkedList() {
//头尾哨兵节点
this.head = new Node<K, V>();
this.tail = new Node<K, V>();
this.head.next = this.tail;
this.tail.prev = this.head;
}
//2.2 添加到头
public void addHead(Node<K, V> node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
//2.3删除结点
public void removeNode(Node<K, V> node) {
node.next.prev = node.prev;
node.prev.next = node.next;
node.prev = null;
node.next = null;
}
//2.4获得最后一个结点
public Node<K, V> getLast() {
return tail.prev;
}
}
private int cacheSize;
private Map<Integer, Node<Integer, Integer>> map;
private DoubleLinkedList<Integer, Integer> doubleLinkedList;
public LRUCacheDemo(int cacheSize) {
//该写构造方法了
}
}
68_手写LRU-下
完成算法 LRU
package lru;
import java.util.HashMap;
import java.util.Map;
public class LRUCacheDemo {
//map复杂查找,构建一个虚拟的双向链表,它里面安装的就是一个个Node结点,作为数据载体。
//构造一个Node结点,作为数据载体。
class Node<K,V>{
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
public Node() {
this.prev = this.next = null;
}
public Node(K key, V value) {
this.key = key;
this.value = value;
this.prev = this.next = null;
}
}
//2 构造一个双向队列,里面安放的就是我们的Node
class DoubleLinkedList<K, V>{
Node<K, V> head;
Node<K, V> tail;
//2.1构造方法
public DoubleLinkedList() {
//头尾哨兵节点
this.head = new Node<K, V>();
this.tail = new Node<K, V>();
this.head.next = this.tail;
this.tail.prev = this.head;
}
//2.2 添加到头
public void addHead(Node<K, V> node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
//2.3删除结点
public void removeNode(Node<K, V> node) {
node.next.prev = node.prev;
node.prev.next = node.next;
node.prev = null;
node.next = null;
}
//2.4获得最后一个结点
public Node<K, V> getLast() {
return tail.prev;
}
}
private int cacheSize;
private Map<Integer, Node<Integer, Integer>> map;
private DoubleLinkedList<Integer, Integer> doubleLinkedList;
public LRUCacheDemo(int cacheSize) {
this.cacheSize = cacheSize;
map=new HashMap<>();
doubleLinkedList =new DoubleLinkedList<>();
}
public int get(int key) {
if(!map.containsKey(key)) {
return -1;
}
Node<Integer, Integer> node = map.get(key);
//更新节点位置,将节点移置链表头
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
return node.value;
}
//saveOrUpdate method
public void put(int key, int value) {
if(map.containsKey(key)) {//update
Node<Integer, Integer> node = map.get(key);
node.value = value;
map.put(key, node);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
}else {
if(map.size() == cacheSize) {//如果已达到最大容量了,把旧的移除,让新的进来
Node<Integer, Integer> lastNode = doubleLinkedList.getLast();
map.remove(lastNode.key);//node.key主要用处,反向连接map
doubleLinkedList.removeNode(lastNode);
}
//才是新增
Node<Integer, Integer> newNode = new Node<>(key, value);
map.put(key, newNode);
doubleLinkedList.addHead(newNode);
}
}
public static void main(String[] args) {
LRUCacheDemo lruCacheDemo = new LRUCacheDemo(3);
lruCacheDemo.put(1,1);
lruCacheDemo.put(2,2);
lruCacheDemo.put(3,3);
System.out.println(lruCacheDemo.map.keySet());//[1, 2, 3]
lruCacheDemo.put(4,1);
System.out.println(lruCacheDemo.map.keySet());//[2, 3, 4]
lruCacheDemo.put(3,1);
System.out.println(lruCacheDemo.map.keySet());//[2, 3, 4]
lruCacheDemo.put(3,1);
System.out.println(lruCacheDemo.map.keySet());//[2, 3, 4]
lruCacheDemo.put(3,1);
System.out.println(lruCacheDemo.map.keySet());//[2, 3, 4]
lruCacheDemo.put(5,1);
System.out.println(lruCacheDemo.map.keySet());//[3, 4, 5]
}
}
最后
2023-2-4 19:06:24
这篇博客能写好的原因是:站在巨人的肩膀上
这篇博客要写好的目的是:做别人的肩膀
开源:为爱发电
学习:为我而行
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











