







夺命连环问-Java基础篇之集合1
1、集合的形式有哪些?
集合可以有不同的形式,以下是一些常见的集合形式:
-
List:有序集合,元素可以重复。可以使用Collections.sort()方法对List进行排序。
-
Set:无序集合,元素不能重复。可以使用HashSet或者TreeSet等实现类。
-
Map:键值对集合,其中每个键对应唯一的值。可以使用HashMap或者TreeMap等实现类。
-
Queue:队列,按照先进先出(FIFO)的顺序存储元素。可以使用LinkedList或者ArrayDeque等实现类。
-
Stack:栈,按照后进先出(LIFO)的顺序存储元素。可以使用LinkedList或者ArrayDeque等实现类。
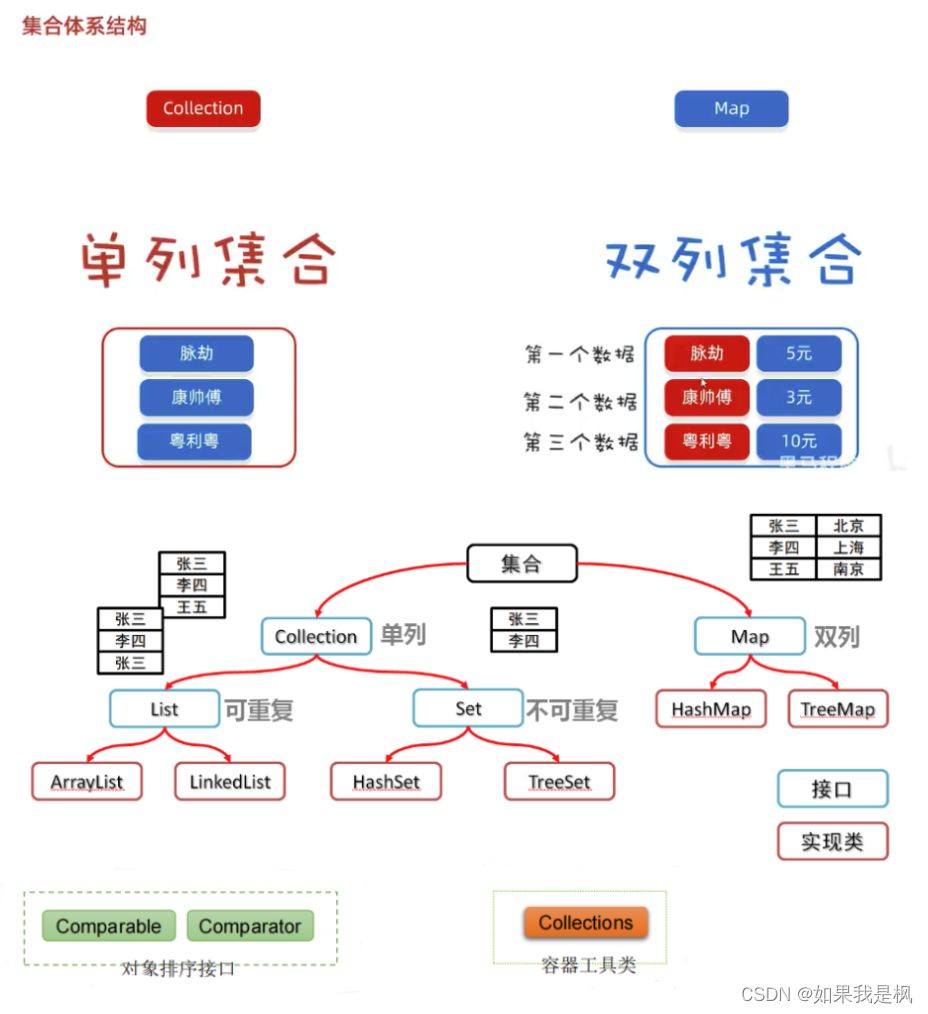
2、你能简单讲讲集合的体系结构吗?
集合可分为单列集合(Collection)和双列集合(Map)。
单列集合又可分为List集合和Set集合,他们的区别是List集合添加的元素是有序、可重复、有索引的,Set集合是无序、不重复、无索引的。
多列集合可分为HashMap和TreeMap。
3、简单谈谈数组和集合,并说说他们有什么区别?
答:
数组和集合都是用来存储一组数据的容器。
区别有以下几点:
1.在存储方式上,数组是一个固定长度的容器,它的长度一旦被初始化之后,就无法再改变了。而集合是一个动态长度的容器,它的长度可以根据需要进行自动扩展。
2.在元素类型上,数组可以存储任何类型的元素,包括基本数据类型和引用数据类型。而集合只能存储引用类型的元素,也就是说,集合中的元素必须是对象。
3.在数据处理上,数组和集合在数据处理方面也存在一些差异。对于数组,我们可以使用Arrays类中提供的一些方法来进行排序、查找等操作。对于集合,我们可以使用Collections类中提供的一些方法来进行排序、查找等操作。
4、你刚才说数组的长度是不可变的,那么动态数组的长度为什么就可以随便改变?
答:
JAVA中规定数组长度是不可变的,创建时多大就是多大。而动态数组可变并不是改变了原数组的长度,而是重新在堆中创建了一个新的数组,把原数组的标签撕下来贴到了新数组上面而已,没有标签的原数组内存空间会按照回收机制被回收。
因此当在对数据大小不确定的时候,我们可以在数组初始化的时候申请足够大的内存(这样会造成内存空间的浪费)或使用集合的方式存储数据,如List,Set和Map类型。我推荐后者,一方面这些类型的长度都是动态增长的,另一方面这些类中提供了便于操作数据的方法。
注:如果你想从源码和JVM内存角度深度了解数组,欢迎来阅读我的另一篇文章(9条消息) 数据结构与算法-数组(内含LeedCode练习)_如果我是枫的博客-CSDN博客
5、你刚才提到了List集合,你知道都有哪些List集合吗?或者平时在开发中都用到了那些集合?
答:
我们在开发中经常用到的就是ArrayList和LinkedList,偶尔为了解决线程安全问题会使用到CopyOnWriteArrayList。
List集合:
ArrayList:基于动态数组实现的List,它提供了快速的随机访问和修改元素的能力。LinkedList:基于双向链表实现的List,它提供了高效的插入和删除操作,但访问和修改元素的性能较差。Vector:与ArrayList类似,也是基于动态数组实现的List,但它是线程安全的,适用于多线程环境。(现在基本不用了)CopyOnWriteArrayList:与ArrayList类似,也是基于动态数组实现的List,但它是线程安全的,并且通过在修改操作时创建副本来实现读写分离。缺点是它会占用更多的内存,因为每次修改操作都会创建一个新的副本。
6、你能谈谈ArrayList和LinkedList它们有什么区别吗?
答:
ArrayList底层基于动态数组,是连续内存,提供了快速的随机访问的能力。
LinkedList底层基于双向链表,不是连续内存。提供了高效的插入和删除操作,但访问和修改元素的性能较差。

7、你研究过ArrayList底层源码吗?能简单说一下它的扩容机制吗?
答:
研究过,。ArrayList的底层是基于动态数组。它实现动态扩容的方式是通过增加一个默认的扩容因子来实现的。扩容的关键方法是add()方法调用的grow()方法,如果插入元素后的新元素个数超过了当前列表的长度,那么ArrayList会按照以下步骤进行扩容:
1. 计算新的容量大小,新容量大小为当前容量大小的1.5倍(即扩容因子默认为1.5)。
2. 创建一个新的数组,长度为新的容量大小。
3. 把原来数组中的所有元素都复制到新数组中。
4. 把新数组设置为ArrayList内部的数组对象。
另外ArrayList是非线程安全类,并发环境下,多个线程同时操作ArrayList,会引发不可预知的异常或错误。
顺序添加很方便。
删除和插入需要复制数组,性能差(可以使用LinkindList)
**注:**由于该实现方式涉及到数组拷贝等操作,因此在进行大数据量插入时,扩容会非常耗费性能。为了尽量避免扩容,可以在使用ArrayList时,尽量预估需要存储的元素数量,提前指定ArrayList的容量大小,避免频繁扩容。这可以通过调用ArrayList的构造方法,传入容量大小参数来实现:
ArrayList<String> list = new ArrayList<>(100); // 指定容量大小为100
无参构造情况下,默认new ArrayList初始化容量为0,存入1个元素时,首次扩容至默认值10,之后按1.5倍扩容(向下取整)
有参构造,如果参数小于10,容量是10,参数大于10,容量大小为你指定的参数。
如何扩容?
1.当调用add()方法添加新元素时,若集合中没有元素,则首次扩容为10,再次扩容为上次容量的 1.5 倍。(可以根据实际情况调整)
2.当调用addAll()添加很多元素时,若集合中没有元素Math.max(10, 实际元素个数);有元素时为 Math.max(原容量 1.5 倍, 实际元素个数)
上面只是用面试的角度来回答,如果想深入了解ArrayList底层源码的同学可以阅读文章----(9条消息) ArrayList源码解析及扩容机制讲解_如果我是枫的博客-CSDN博客

8、如果我连续向 一个使用无参构造创建的ArrayList 集合里面增值,增加到第 11 个的时候,数组的大小是多少?增加到16呢?
答:
15
ArrayList使用无参构造创建时,初始容量时0;当添加元素时会触发扩容,首次扩容大小为10;当添加第11个元素时,会触发再次扩容,扩容大小为原有容量的1.5倍,即15。所以此时数组大小为15
22
计算过程:
15*1.5=22.5
15>>1=7
15+7=22
9、ArrayList集合使用无参构造初始化,被加入一个值后,如果我使用 addAll 方法,一下子加入 15 个值,那么最终数组的大小是多少?
答:
是16,addAll的扩容原理是当原始容量不够时,在下次扩容的容量和实际的元素个数之间选一个较大值。
测试数据:
当前0,加3:
10
当前0,加11:
11
当前10,加3:
15
当前1,加15:
16
10、如果我需要新建一个ArrayList集合,并循环向其中添加1万条数据,那么请问如何创建集合的方式比较好,为什么?
答:
在预先知道数据的情况下,直接指定大小创建集合较好,因为不需要触发扩容。扩容的本质是新数组代替旧数组,旧数组被回收掉,在这个过程中会消耗性能。
11、Arrays.asList() 方法获取的List集合可以扩容吗?
答:
不能扩容,因为得到的是final修饰的固定大小的数组。
关于Arrays.asList的源码详情请阅读文章—(9条消息) Arrays.asList源码解析及常见误区_如果我是枫的博客-CSDN博客
12、如何使用ArrayList实现栈这种数据结构
答:
public class MyStack<T>{
private List<T> data = new ArrayList<>();
public T pop(){ //弹出栈
//取出集合的最后一个元素
if(data.size()!=0){//判断集合中是否存在元素
return data.remove(data.size()-1);
}else {//集合中不存在元素,直接返回null
return null;
}
}
public void push(T temp){//压栈
//向集合尾部添加元素
data.add(temp);
}
}
小提示:要实现栈的操作,要先明白栈的特点是先进后出。要使用list集合实现栈操作,只需要保证存取数据的操作从集合的一端进行就可以了。
例如都从集合的尾部操作,那就可以满足栈的特点了。
13、如何对ArrayList集合中的数据进行删除操作?
答:
List<String> list = new ArrayList<>();
list.addAll(Arrays.asList("张三","李四","王五","刘备",
"张飞","赵云","曹操","孙权","武松","宋江","鲁智深","张三丰","张无忌","张天师"));
//TODO 遍历集合,去除集合中所有姓张的
//方式一:使用for循环遍历,遍历的过程中判断当前姓名是否姓张,如果是则从元素中移除
// 此处注意建议倒序遍历
for (int i = list.size()-1; i >=0; i--) {
String name = list.get(i);
if(name.startsWith("张")){
list.remove(i);
}
}
System.out.println(list);
//方式二:使用stream流的对集合中的元素进行过滤,去除姓名中包含张的元素
List<String> result = list.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
if(s.startsWith("张")){
return false;
}
return true;
}
}).collect(Collectors.toList());
System.out.println(result);
}
我们有两种方法:
1.使用for循环倒序遍历方式,遍历的过程中判断当前姓名是否姓张,如果是则从元素中移除
2.使用stream流的对集合中的元素进行过滤,去除姓名中包含张的元素。
14、谈谈failFast和failSafe?你分析过它的源码吗?
答:
分析过failFast和failSafe的源码。
ArrayList是fail-fast的典型代表,一旦发现遍历的同时其他人来修改,则立即抛异常。
实现原理是记录了循环开始时的次数,如果在循环的过程中修改次数被改,则会尽快失败,抛出异常,阻止循环继续。
CopyOnWriteArrayList是fail-safe的典型代表,遍历的同时可以修改。
实现原理是读写分离。遍历时使用旧数组,在元素增加时创建一个新数组,长度是旧数组长度+1,然后将旧数组的元素copy到新数组中。遍历结算后回收旧数组,替换成新数组。这样添加和遍历就不是同一个数组了,互不干扰,也就不存在并发问题。
想具体了解的,请阅读文章—(14条消息) Iterator_FailFast_FailSafe源码解析_如果我是枫的博客-CSDN博客
15、你在开发中遇到了哪些线程安全问题?你是怎么解决的?
在多并发场景下,像订单查询、黑名单搜索这样的功能就会发生线程安全问题。对于这种读多写少的场景,我通常是用CopyOnWriteArrayList来解决线程安全问题的。
线程安全问题有哪些?怎么解决?
-
竞态条件(Race Condition):多个线程同时访问和修改共享数据,导致结果依赖于不可控的执行顺序。
public class Counter { private int count; public void increment() { count++; } public int getCount() { return count; } }解决方案:使用同步机制或锁来保护共享数据的访问,确保只有一个线程能够修改数据。
public class Counter { private int count; private Object lock = new Object(); public void increment() { synchronized (lock) { count++; } } public int getCount() { synchronized (lock) { return count; } } } -
数据竞争(Data Race):多个线程同时访问和修改共享数据,其中至少有一个线程进行写操作,可能导致未定义的行为或数据损坏。
public class DataRaceExample { private int value; public void setValue(int newValue) { value = newValue; } public int getValue() { return value; } }解决方案:使用原子类来保证数据的原子性操作。
import java.util.concurrent.atomic.AtomicInteger; public class DataRaceExample { private AtomicInteger value = new AtomicInteger(); public void setValue(int newValue) { value.set(newValue); } public int getValue() { return value.get(); } } -
死锁(Deadlock):多个线程相互等待对方释放资源,导致程序无法继续执行。
public class DeadlockExample { private Object lock1 = new Object(); private Object lock2 = new Object(); public void method1() { synchronized (lock1) { synchronized (lock2) { // Do something } } } public void method2() { synchronized (lock2) { synchronized (lock1) { // Do something } } } }解决方案:避免循环等待资源的情况,或者通过使用线程池、限制同步的顺序等方法来避免死锁的发生。
-
非原子操作:对于需要多个步骤才能完成的操作,如果多个线程同时执行这些步骤,可能导致不一致的结果。
解决线程安全问题的常见方法包括:
- 加锁(Locking):使用同步机制(如synchronized关键字)或锁(如ReentrantLock)来保护共享数据的访问,确保同一时间只有一个线程能够修改数据。
- 原子操作(Atomic Operations):使用原子类(如AtomicInteger、AtomicBoolean)或并发容器(如ConcurrentHashMap)来执行常见的原子操作,避免数据竞争和竞态条件。
- 使用线程安全的数据结构:选择适当的线程安全集合类(如Vector、CopyOnWriteArrayList)来存储和操作共享数据,避免手动进行同步。
- 线程间通信(Inter-Thread Communication):使用wait()、notify()、notifyAll()等方法,通过等待/通知机制来确保线程按照预期的顺序执行。
- 避免共享数据:尽量避免多个线程共享数据,通过将数据限定在各自的线程内部,或使用线程局部变量,来避免线程安全问题。
- 使用不可变对象(Immutable Objects):将对象设计成不可变的,即对象创建后不能被修改,这样多个线程之间可以安全地共享对象而无需额外的同步。
- 合理的线程设计:合理划分任务和线程的边界,避免不必要的线程间竞争,尽量减少共享数据的使用。
16、你是怎么通过CopyOnWriteArrayList解决线程安全问题的?你对它了解多少?
答:
CopyOnWriteArrayList 用了基于加锁(ReentrantLock重入锁)的 “读写分离” 和 “写时复制” 的方案解决线程安全问题,它的内部维护着一个使用 volatile 修饰的数组,用来存放元素数据。
思想 1 - 读写分离(Read/Write Splitting): 将对资源的读取和写入操作分离,使得读取和写入没有依赖,在 “读多写少” 的场景中能有效减少资源竞争;
思想 2 - 写时复制(CopyOnWrite,COW): 在写入数据时,不直接在原数据上修改,而是复制一份新数据后写入到新数据,最后再替换到原数据的引用上。这个特性各有优缺点:
优点 1 - 延迟处理: 在没有写入操作时不会复制 / 分配资源,能够避免瞬时的资源消耗。例如操作系统的 fork 操作也是一种写时复制的思想;
优点 2 - 降低锁颗粒度: 在写的过程中,读操作不会被影响,读操作也不需要加锁,锁的颗粒度从整个列表降低为写操作;
缺点 1 - 弱数据一致性: 在读的过程中,如果数据被其他线程修改,是无法实时感知到最新的数据变化的;
缺点 2 - 有内存压力: 在写操作中需要复制原数组,在复制的过程中内存会同时存在两个数组对象(只是引用,数组元素的对象还是只有一份),会带来内存占用和垃圾回收的压力。如果是 “写多读少” 的场景,就不适合。
篇幅有限,详细内容请看文章——(7条消息) CopyOnWriteArrayList源码解析_如果我是枫的博客-CSDN博客
17、遍历一个 List 有哪些不同的方式?
- for 循环遍历,基于计数器。在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到最后一个元素后停止。
- 迭代器遍历,Iterator。Iterator 是面向对象的一个设计模式,目的是屏蔽不同数据集合的特点,统一遍历集合的接口。Java 在 Collections 中支持了 Iterator 模式。
- foreach 循环遍历。foreach 内部也是采用了 Iterator 的方式实现,使用时不需要显式声明 Iterator 或计数器。优点是代码简洁,不易出错;缺点是只能做简单的遍历,不能在遍历过程中操作数据集合,例如删除、替换。
System.out.println("-----------for遍历-------------");
for (Student student : list) {
System.out.println(student);
}
System.out.println("-----------Iterator遍历-------------");
Iterator<Student> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
System.out.println("-----------forEach遍历-------------");
list.parallelStream().forEach(k -> {
System.out.println(k);
});
为了保证迭代器的正确性和一致性,Java设计决定在使用迭代器遍历集合时禁止对集合进行结构性修改。如果在遍历过程中修改集合,就可能导致迭代器产生不可预料的行为,甚至引发并发修改异常(ConcurrentModificationException)。
18、如何给List集合中的元素进行排序?
答:
可以有两种方式:
方式一:可以自定义一个比较器Comparator,自己指定排序顺序。
方式二:可以通过Collections.sour(list)默认升序排序。
List<Integer> list = new ArrayList<>();
list.addAll(Arrays.asList(new Integer[]{100,23,43,103,200,18,39,143,423}));
//TODO 对list中的元素进行排序【从小到达排序】
//方式一:自定义比较器Comparator,排序顺序可以自己指定
list.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1-o2;
}
});
//方式二:默认升序排序,排序方式不能改变
Collections.sort(list);
19、List和Array数组之间如何转换?
答:
list->Array 通过list.toArray
Array->list 通过Arrays.asList
20、如何确保集合不被修改?
答:
可以使用 Collections.unmodifiableCollection(Collection c) 方法来创建一个只读集合,这样改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常。
21、如何对list集合进行去重?
答:
可以通过strea流的distinct去重方法实现.
List<String> list = new ArrayList<>();
//使用Arrays.asList()方法将一个字符串数组转换为一个List<String>对象,并使用addAll()方法将该列表中的元素添加到list中。
list.addAll(Arrays.asList(new String[]{"张三","李四","王五","唐僧","李四","王五","孙悟空"}));
//TODO 对list集合进行去重处理
//此处使用的是strea流的distinct去重方法实现的。
Stream<String> stream = list.stream();
List<String> collect = stream.distinct().collect(Collectors.toList());
System.out.println(collect.toString());
流程:
- 创建了一个名为
list的ArrayList<String>对象,用于存储原始的字符串列表。 - 使用
Arrays.asList()方法将一个字符串数组转换为一个List<String>对象,并使用addAll()方法将该列表中的元素添加到list中。这样,list就包含了一些重复的字符串元素。 - 创建了一个名为
stream的Stream<String>对象,通过调用list.stream()方法来创建该流对象。 - 调用
distinct()方法对流中的元素进行去重操作,即去除重复的元素。 - 调用
collect(Collectors.toList())方法将去重后的流中的元素收集到一个新的List<String>对象中。 - 将去重后的结果列表通过
System.out.println()打印出来。
22、集合A和集合B里面有公共的元素,如何在去除两个集合中的公共部分?
答:
思路:将集合A,B分别放到HashSet集合里,然后调用removeAll方法去除集合A中与集合B重复重复的元素,得到去重后的集合A。同理可去除集合B中重复的元素。
代码示例:
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
/**
* 从listA里删除listB里有的数据
* @return
* 现在有两个集合listA和listB,需要从listA集合中删除两个集合的并集
* 思路:将集合A,B分别放到HashSet集合里,
* 然后调用removeAll方法去除集合A中与集合B重复重复的元素,得到去重后的集合A。同理可去除集合B中重复的元素。
*/
public class Listrem<T> {
public List<String> listremA(List<String> listA,List<String> listB){
HashSet hs1 = new HashSet(listA);
HashSet hs2 = new HashSet(listB);
hs1.removeAll(hs2);
List<String> listC = new ArrayList<>();
listC.addAll(hs1);
return listC;
}
}
测试示例:
public class ListremTest {
@Test
@DisplayName("去除集合A中与集合B有关的元素")
public void test01(){
List<String> listA = new ArrayList<>();
listA.add("A");
listA.add("B");
listA.add("C");
List<String> listB = new ArrayList<>();
listB.add("B");
listB.add("C");
listB.add("D");
Listrem<String> listrem = new Listrem<>();
List<String> listC = listrem.listremA(listA,listB);
System.out.println(listC);
}
}
Junit测试依赖包
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.8.2</version>
<scope>test</scope>
</dependency>
















 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









