







深度解析CopyOnWriteArraySet
一、概述
从JDK1.5开始Java并发包里提供了两个使用COW机制实现的并发容器,它们就是CopyOnWriteArrayList和CopyOnWriteArraySet。
CopyOnWriteArraySet 和 HashSet 都是继承于 AbstractSet 的,但 CopyOnWriteArraySet 是基于 CopyOnWriteArrayList 动态数组的,并没有使用哈希思想。而 HashSet 是基于 HashMap 散列表的,能够实现 O(1) 查询。
由于CopyOnWriteArraySet基于CopyOnWriteArrayList 动态数组,所以它具备CopyOnWriteArrayList的特点,并且在此基础上还具有去重的特性。
关于CopyOnWriteArrayList 动态数组的深度解析,请参考文章——(7条消息) CopyOnWriteArrayList源码解析_如果我是枫的博客-CSDN博客
接下来我们来通过源码进一步CopyOnWriteArraySet。
二、源码解析(JDK8)
1、属性定义
CopyOnWriteArraySet源码:
public class CopyOnWriteArraySet<E> extends AbstractSet<E>
implements java.io.Serializable {
private static final long serialVersionUID = 5457747651344034263L;
private final CopyOnWriteArrayList<E> al;
....
}
下面是对代码的分析:
- 类声明:
CopyOnWriteArraySet<E>声明了一个泛型类,表示一个线程安全的集合,该集合中的元素不允许重复。 - 继承关系:
CopyOnWriteArraySet<E>继承自AbstractSet<E>,说明它是一个抽象集合类的子类,继承了抽象集合类的一些基本行为和方法。 - 实现接口:
CopyOnWriteArraySet<E>实现了java.io.Serializable接口,表示该类可以被序列化。 - serialVersionUID:
serialVersionUID是一个序列化版本号,用于在反序列化过程中验证序列化对象和反序列化对象的版本是否一致。 - 成员变量:
private final CopyOnWriteArrayList<E> al是一个私有的CopyOnWriteArrayList对象,用于存储集合的元素。
HashSet属性定义:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
//serialVersionUID字段被声明为static final long类型,并赋予一个具体的值-5024744406713321676L作为版本号。该值是根据类的结构和内容计算生成的,用于唯一标识该类的序列化版本。
@java.io.Serial
static final long serialVersionUID = -5024744406713321676L;
//HashSet类声明了一个transient修饰符修饰的map字段,用于存储元素和对应的值。transient关键字表示该字段在序列化过程中会被忽略,不会被持久化保存。
private transient HashMap<E,Object> map;
//PRESENT常量,用作HashMap中的值,用于标识集合中的元素。
private static final Object PRESENT = new Object();
......
}
比较 CopyOnWriteArraySet和HashSet的属性定义,可以看到 CopyOnWriteArraySet 是基于 CopyOnWriteArrayList 动态数组的,并没有使用哈希思想。
这里还存在一个疑问:
声明serialVersionUID到底有什么用?什么时候声明?为什么看到有的类中有声明有的类中没声明?它的唯一标识号是根据什么生成的?
由于篇幅有限,在这里就不展开讲了,感兴趣的可以参考文章——(8条消息) 深入解析serialVersionUID原理及其使用场景_如果我是枫的博客-CSDN博客
2、 构造方法
看一下 CopyOnWriteArraySet 的构造方法,底层就是有一个 CopyOnWriteArrayList 动态数组。
CopyOnWriteArraySet.java
public class CopyOnWriteArraySet<E> extends AbstractSet<E> implements java.io.Serializable {
// 底层就是 OnWriteArrayList
private final CopyOnWriteArrayList<E> al;
// 无参构造方法
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
// 带集合的构造方法
public CopyOnWriteArraySet(Collection<? extends E> c) {
if (c.getClass() == CopyOnWriteArraySet.class) {
// 入参是 CopyOnWriteArraySet,说明是不重复的,直接添加
CopyOnWriteArraySet<E> cc = (CopyOnWriteArraySet<E>)c;
al = new CopyOnWriteArrayList<E>(cc.al);
}
else {
// 使用 addAllAbsent 添加不重复的元素
al = new CopyOnWriteArrayList<E>();
al.addAllAbsent(c);
}
}
public int size() {
return al.size();
}
}
总结:CopyOnWriteArraySet 是一个线程安全的集合类,它基于 CopyOnWriteArrayList 实现。它通过对 CopyOnWriteArrayList 进行封装,提供了一些集合操作的方法,并保证了多线程环境下的安全性。由于底层使用了写时复制的机制,它适用于读多写少的场景,并且在迭代期间支持并发修改操作。通过继承 AbstractSet,它提供了集合的一些基本操作和特性,如大小、迭代等。
3、 操作方法
CopyOnWriteArraySet 的方法基本上都是交给 CopyOnWriteArrayList 代理的,由于没有使用哈希思想,所以操作的时间复杂度是 O(n)。
CopyOnWriteArraySet.java
//add(E e) 方法调用了底层 CopyOnWriteArrayList 的 addIfAbsent(E e) 方法,并返回该方法的结果。addIfAbsent(E e) 方法用于向底层的 CopyOnWriteArrayList 添加元素 e,只有当元素不存在时才会添加,并返回添加操作的结果。
public boolean add(E e) {
return al.addIfAbsent(e);
}
//CopyOnWriteArraySet 类中的contains(Object o) 方法调用了底层 CopyOnWriteArrayList 的 contains(Object o) 方法,并返回该方法的结果。contains(Object o) 方法用于判断底层的 CopyOnWriteArrayList 是否包含元素 o。
public boolean contains(Object o) {
return al.contains(o);
}
//addIfAbsent(E e) 方法先获取底层数组的一个快照 snapshot,然后通过调用 indexOf(e, snapshot, 0, snapshot.length) 方法判断元素 e 是否存在于 snapshot 中。如果存在则返回 false,表示添加失败;如果不存在则调用 addIfAbsent(e, snapshot) 方法进行真正的添加操作。
CopyOnWriteArrayList.java
public boolean addIfAbsent(E e) {
Object[] snapshot = getArray();
return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false : addIfAbsent(e, snapshot);
}
//CopyOnWriteArrayList 类中的 contains(Object o) 方法也是先获取底层数组的一个快照 elements,然后通过调用 indexOf(o, elements, 0, elements.length) 方法判断元素 o 是否存在于 elements 中。如果存在则返回 true,表示包含该元素;如果不存在则返回 false。
public boolean contains(Object o) {
Object[] elements = getArray();
return indexOf(o, elements, 0, elements.length) >= 0;
}
//这个方法是一个线性扫描的方法,用于在数组 elements 的指定范围内查找元素 o 的位置。它遍历数组,逐个比较元素并进行匹配。如果找到匹配的元素则返回其索引,如果没有找到则返回 -1。
// 通过线性扫描匹配元素位置,而不是计算哈希匹配,时间复杂度是 O(n)
private static int indexOf(Object o, Object[] elements, int index, int fence) {
if (o == null) {
for (int i = index; i < fence; i++)
if (elements[i] == null) return i;
} else {
for (int i = index; i < fence; i++)
if (o.equals(elements[i])) return i;
}
return -1;
}
注意: 上面写了两个contains(Object o)方法,一个是CopyOnWriteArraySet 类中的contains(Object o) 方法,用来调用底层的CopyOnWriteArrayList 类中的 contains(Object o) 方法。后者判断元素 o 是否存在于快照elements 中。
总结:
CopyOnWriteArraySet 类的 add(E e) 方法和 contains(Object o) 方法都是通过调用底层的 CopyOnWriteArrayList 对应的方法来完成操作。底层的 CopyOnWriteArrayList 使用了线性扫描的方式进行元素匹配,而不是通过哈希匹配。这意味着在查找元素和添加元素时,时间复杂度是 O(n),需要遍历整个数组。这种实现方式适用于小型集合和并发写入较少的场景,因为它的并发性能较好,并且在迭代过程中可以进行并发修改操作。但对于大型集合或频繁的添加、删除操作,其性能可能较低。
三、 CopyOnWriteArraySet 的 clone() 过程
CopyOnWriteArraySet 的 clone() 很巧妙。按照正常的思维,CopyOnWriteArraySet 中的 array 数组是引用类型,因此在 clone() 中需要实现深拷贝,否则原对象与克隆对象就会相互影响。但事实上,array 数组并没有被深拷贝,有点不理解。
1、什么是深拷贝?
深拷贝是一种复制对象的方式,创建一个与原始对象完全独立的副本,使得对副本的修改不会影响原始对象,同时保持对象之间的数据一致性。
这意味着即使对象的属性是引用类型,深拷贝也会创建一个新的引用对象,而不是简单地复制引用本身。
常用于需要对对象进行修改或传递给其他模块时,确保操作的安全性和可靠性。
2、为什么 array 数组没有深拷贝?
这就是因为写时复制机制!没有写就没有复制。
CopyOnWriteArrayList 的设计目标和特性不需要对数组的元素进行深拷贝。
由于每次写操作都会创建一个全新的数组,即使数组中的元素引用没有改变,它们仍然指向相同的对象。因此,在 CopyOnWriteArrayList 的设计中,对于数组的深拷贝并不是必要的。如果进行深拷贝,将会增加额外的复杂性和性能开销。
3、clone()源码:
//clone() 方法用于创建当前对象的副本。在 CopyOnWriteArrayList 中,它通过调用父类的 clone() 方法创建一个新的 CopyOnWriteArrayList 对象的副本。
public Object clone() {
try {
@SuppressWarnings("unchecked")
//为什么 array 数组没有深拷贝?
CopyOnWriteArrayList<E> clone = (CopyOnWriteArrayList<E>) super.clone();
//调用了 resetLock() 方法来设置副本对象的 ReentrantLock 对象。这是为了确保副本对象具有独立的锁,避免多个对象之间共享同一个锁的状态。resetLock() 方法会重新创建一个 ReentrantLock 对象,并使用 UNSAFE.putObjectVolatile() 方法将其设置为副本对象的 lock 字段的值,实现了对 lock 字段的深拷贝。
clone.resetLock();
return clone;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
}
四、CopyOnWriteArraySet 的序列化过程
与 ArrayList 类似,CopyOnWriteArraySet 也重写了 JDK 序列化的逻辑,只把 elements 数组中有效元素的部分序列化,而不会序列化整个数组。
同时,ReentrantLock 对象是锁对象,序列化没有意义。在反序列化时,会通过 resetLock() 设置一个新的 ReentrantLock 对象。
//在序列化过程中,首先调用 s.defaultWriteObject() 将默认的序列化操作委托给父类,以便将对象的默认字段写入输出流。接下来,获取底层数组 elements 并写入其长度。然后,使用循环将数组中的每个元素进行序列化并写入输出流。
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {
s.defaultWriteObject();
Object[] elements = getArray();
// 写入数组长度
s.writeInt(elements.length);
// 写入有效元素
for (Object element : elements)
s.writeObject(element);
}
//在反序列化过程中,首先调用 s.defaultReadObject() 将默认的反序列化操作委托给父类,以便从输入流中读取默认字段。然后,调用 resetLock() 方法重新初始化锁对象。接下来,读取数组的长度并进行数组合法性检查。创建一个新的对象数组 elements,并使用循环从输入流中读取每个对象并存储到数组中。最后,使用 setArray(elements) 方法设置新的数组。
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
// 设置 ReentrantLock 对象
resetLock();
// 读取数组长度
int len = s.readInt();
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, len);
// 创建底层数组
Object[] elements = new Object[len];
// 读取数组对象
for (int i = 0; i < len; i++)
elements[i] = s.readObject();
// 设置新数组
setArray(elements);
}
//resetLock() 是什么?
//这个方法,用于重置 CopyOnWriteArrayList 对象的锁。通过使用 Unsafe 类的 putObjectVolatile 方法,将一个新的 ReentrantLock 对象设置为 lock 字段的值。这种方式相当于使用 Volatile 语义来设置字段的值。
private void resetLock() {
// 等价于带 Volatile 语义的 this.lock = new ReentrantLock()
UNSAFE.putObjectVolatile(this, lockOffset, new ReentrantLock());
}
// Unsafe API
private static final sun.misc.Unsafe UNSAFE;
// lock 字段在对象实例数据中的偏移量
private static final long lockOffset;
static {
try {
// 这三行的作用:获取 lock 字段在 CopyOnWriteArrayList 类的对象实例数据中的偏移量。
//通过调用 sun.misc.Unsafe 类的静态方法 getUnsafe() 获取 Unsafe 的实例。Unsafe 类提供了直接操作内存和对象的底层方法,但是它的使用需要谨慎,因为它涉及到底层的操作和绕过了 Java 语言的类型安全检查。
UNSAFE = sun.misc.Unsafe.getUnsafe();
//创建一个 Class 对象,表示 CopyOnWriteArrayList 类。
Class<?> k = CopyOnWriteArrayList.class;
//objectFieldOffset() 方法是 Unsafe 类的方法,用于获取给定字段在对象实例中的偏移量。通过 k.getDeclaredField("lock") 获取 lock 字段的反射对象,并将其传递给 objectFieldOffset() 方法,以获取字段的偏移量。
lockOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("lock"));
} catch (Exception e) {
throw new Error(e);
}
}
1、resetLock() 是什么?
resetLock() 是一个私有方法,用于重置 CopyOnWriteArrayList 对象中的锁。它使用 Java 的 Unsafe API 来设置 lock 字段的值。
在 readObject() 方法中,resetLock() 方法被调用以确保在反序列化对象时重新设置正确的锁对象。它使用 Unsafe.putObjectVolatile() 方法来将 ReentrantLock 对象设置为 lock 字段的新值。保证这个字段的写入具备内存可见性。
Unsafe 类是一个提供了直接操作内存和执行低级别非安全操作的 API。它允许绕过 Java 语言的安全限制,并进行底层内存操作。在这种情况下,Unsafe 类被用于设置对象实例中的字段偏移量和设置 lock 字段的新值。
请注意,Unsafe 类是一个受限制的 API,不建议在常规的应用程序开发中使用它,因为它涉及到底层的非安全操作,可能会导致内存和线程安全问题。只有在特定的情况下,比如在某些核心库或高性能框架的实现中,才会使用 Unsafe 类。
在 static 代码块中,会使用 Unsafe API 获取 CopyOnWriteArrayList 的 “lock 字段在对象实例数据中的偏移量” 。由于字段的偏移是全局固定的,所以这个偏移量可以记录在 static 字段 lockOffset 中。
在 resetLock() 中,通过 UnSafe API putObjectVolatile 将新建的 ReentrantLock 对象设置到 CopyOnWriteArrayList 的 lock 字段中,等价于带 volatile 语义的 this.lock = new ReentrantLock(),保证这个字段的写入具备内存可见性。
2、对象内存布局
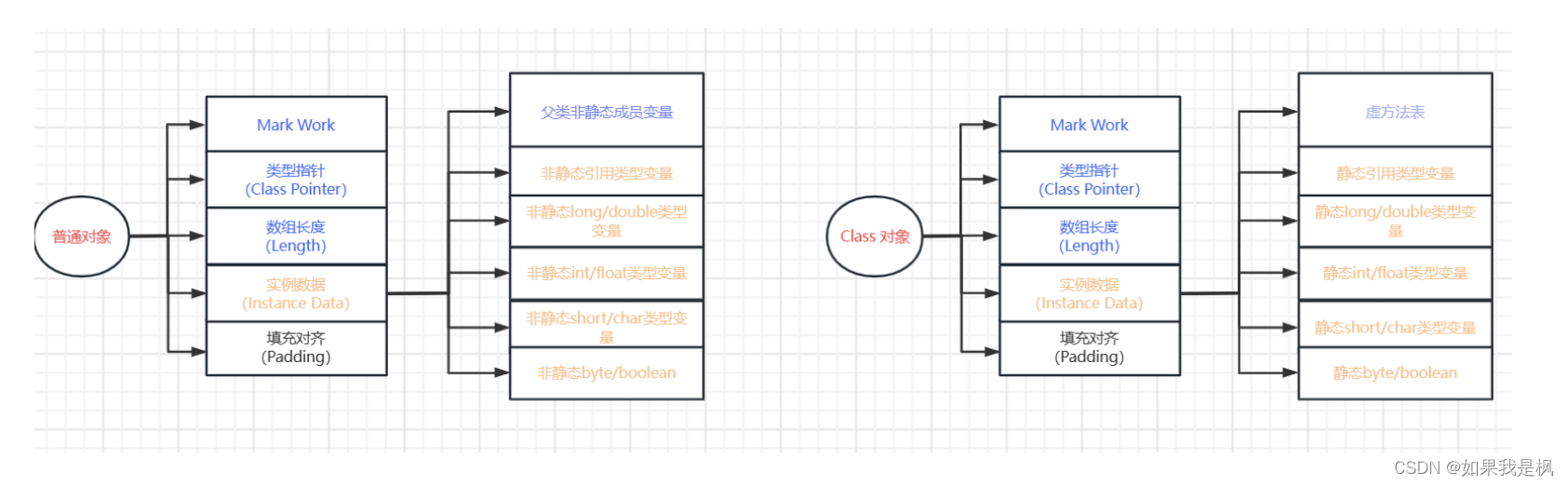
字段的偏移量是什么意思呢?简单来说,普通对象和 Class 对象的实例数据区域是不同的:
- 1、普通对象: 包括当前类声明的实例字段以及父类声明的实例字段,不包括类的静态字段。UnSafe API objectFieldOffset(Filed) 就是获取了参数 Filed 在实例数据中的偏移量,后续就可以通过这个偏移量为字段赋值;
- 2、Class 对象: 包括当前类声明的静态字段和方法表等。
3、Unsafe类是什么?有什么用?
3.1 Unsafe类位于rt.jar包,Unsafe类提供了硬件级别的原子操作,类中的方法都是native方法,它们使用JNI的方式访问本地C++实现库。由此提供了一些绕开JVM的更底层功能,可以提高程序效率。
JNI:Java Native Interface。使得Java 与 本地其他类型语言(如C、C++)直接交互。
3.2 Unsafe 类是一个提供了直接操作内存和执行低级别非安全操作的 API。它允许绕过 Java 语言的安全限制,并进行底层内存操作。
3.3 Unsafe里关于对象字段访问的方法把对象布局抽象出来,它提供了objectFieldOffset()方法用于获取某个字段相对Java对象的“起始地址”的偏移量,也提供了getInt、getLong、getObject之类的方法可以使用前面获取的偏移量来访问某个Java对象的某个字段。
3.4 Unsafe作用可以大致归纳为:
- 内存管理,包括分配内存、释放内存等。
- 非常规的对象实例化。
- 操作类、对象、变量。
- 自定义超大数组操作。
- 多线程同步。包括锁机制、CAS操作等。
- 线程挂起与恢复。
- 内存屏障。
实际上官方是不推荐我们在代码中直接使用Unsafe类的。我们知道C或C++是可以直接操作指针的,指针操作是非常不安全的,这也是Java“去除”指针的原因。而Unsafe类,类中包含大量操作指针偏移量的方法,偏移量要自己计算,如若使用不当,会对程序带来许多不可控的灾难,JVM直接崩溃亏。因此对它的使用我们需要慎之又慎,生产级别的代码就更不应该使用Unsafe类了。
另外Unsafe类还有很多自主操作内存的方法,这些都是直接内存,而使用的这些内存不受JVM管理(无法被GC),需要手动管理,一旦出现疏忽很有可能成为内存泄漏的源头。
虽然Unsafe是“不安全的”,但是它在JUC(java.util.concurrent)包中大量使用(主要是CAS),在netty中方便使用直接内存,还有一些高并发的交易系统为了提高CAS(compare and swap)的效率也有可能直接使用到Unsafe,比如Hadoop、Kafka、akka。
五、版本区别
resetLock()源码(JDK17):
resetLock()方法用于在反序列化或克隆对象时重新初始化锁。
/** Initializes the lock; for use when deserializing or cloning. */
private void resetLock() {
@SuppressWarnings("removal")
//通过特权操作 java.security.AccessController.doPrivileged 获取私有字段 lock 的引用。这里使用了特权操作的原因是 lock 字段为私有字段,需要通过反射来访问。
Field lockField = java.security.AccessController.doPrivileged(
(java.security.PrivilegedAction<Field>) () -> {
try {
Field f = CopyOnWriteArrayList.class
.getDeclaredField("lock");
//获取到 lock 字段后,设置其可访问性为 true,以便后续能够通过反射来修改字段的值。
f.setAccessible(true);
return f;
} catch (ReflectiveOperationException e) {
throw new Error(e);
}});
try {
//接下来,使用 lockField.set(this, new Object()) 的方式为当前对象设置一个新的锁对象。这里创建了一个简单的空对象作为新的锁对象。
lockField.set(this, new Object());
} catch (IllegalAccessException e) {
//如果在设置字段值的过程中发生了访问权限异常(IllegalAccessException),则抛出一个 Error。
throw new Error(e);
}
}
总体来说,JDK17版resetLock() 方法的作用是重新初始化 CopyOnWriteArrayList 对象的锁字段,将其设置为一个新的锁对象。这个方法通常在反序列化或克隆对象时调用,以确保对象的状态和同步机制的正确性。通过使用特权操作和反射,可以绕过访问限制来修改私有字段的值。
为什么用java.security.AccessController?
java.security.AccessController提供了一个默认的安全策略执行机制,它使用栈检查来决定潜在不安全的操作是否被允许。
AccessController最核心方法是它的checkPermission静态方法,该方法决定一个特定的操作是否被允许。允许则简单返回,禁止则抛出AccessControlException异常。checkPermission自顶向下检查栈帧,每个栈帧代表了当前线程调用的某个方法,每一个方法是在某个类中定义,每个类又属于某个保护域,每个保护域包含一些权限,因此每个栈帧间接和一些权限相关,要遇到一个没有权限帧就抛出异常。栈检查可以通过使用doPrivileged方法来中断,后续的栈帧对操作的资源不论是否有权限都无关。
JDK8和JDK17的区别:
JDK8通过使用 Unsafe 类的 putObjectVolatile 方法操作指针偏移量的方式,获取私有字段lock 。
JDK17使用特权操作 java.security.AccessController.doPrivileged 中断权限方式,通过反射获取私有字段 lock 。
前者通过操作指针偏移量的方式获取私有字段lock,它涉及到底层的非安全操作,可能会导致内存和线程安全问题,但是性能好。后者使用特权操作 java.security.AccessController.doPrivileged 中断权限方式,通过反射获取私有字段 lock ,较安全,但是反射相对于指针来说性能还是差点。
六、总结
-
CopyOnWriteArraySet基于CopyOnWriteArrayList 动态数组,并没有使用哈希思想。它具备CopyOnWriteArrayList的特点,并且在此基础上还具有去重的特性。
-
CopyOnWriteArraySet类的add(E e)方法和contains(Object o)方法都是通过调用底层的CopyOnWriteArrayList对应的方法来完成操作。底层的CopyOnWriteArrayList使用了线性扫描的方式进行元素匹配,而不是通过哈希匹配。 -
深拷贝是一种复制对象的方式,创建一个与原始对象完全独立的副本,使得对副本的修改不会影响原始对象,同时保持对象之间的数据一致性。
-
resetLock()方法用于重置 CopyOnWriteArrayList 对象的锁。通过使用 Unsafe 类的 putObjectVolatile 方法,将一个新的 ReentrantLock 对象设置为 lock 字段的值。这种方式相当于使用 Volatile 语义来设置字段的值。
-
JDK8通过使用 Unsafe 类的 putObjectVolatile 方法操作指针偏移量的方式,获取私有字段lock 。
JDK17使用特权操作 java.security.AccessController.doPrivileged 中断权限方式,通过反射获取私有字段 lock 。
















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









