







夺命连环问-Java基础篇之集合2
1、List、Map、Set 三个接口存取元素时,各有什么特点?
答:
- List是有序集合,允许存储重复元素,通过索引访问和操作元素。
- Map是键值对存储的集合,不允许存储重复的键值对,键唯一,键值对无序。
- Set是不允许重复元素的集合,无序。
2、List集合和Map集合的区别是什么?
1、数据结构不同:List是一个有序的集合,它可以包含重复的元素,而Map是一个无序的键值对集合。
注:List集合可以是有序的,也可以是无序的。如果需要保持元素的有序性,可以使用Collections.sort()方法对List进行排序;如果不需要保持有序性,可以使用ArrayList或者LinkedList等实现类。
Map集合中的元素是无序的,因为Map是通过键值对来存储数据的,键值对的顺序是不固定的。如果需要按照键名对Map进行排序,可以使用TreeMap或者LinkedHashMap等实现类。
2、存储方式不同:List中的元素是对象,而Map中的元素是键值对。
3、访问方式不同:List中的元素可以通过索引进行访问,而Map中的元素需要通过键进行访问。
4、初始化方式不同:List可以使用Arrays.asList()或者ArrayList.newInstance()等方法进行初始化,而Map可以使用HashMap.newKeyValuePair()或者TreeMap.newNode()等方法进行初始化。
5、线程安全性不同:List不是线程安全的,如果多个线程同时对同一个List进行修改操作,可能会导致数据不一致的问题。而Map是线程安全的,可以在多线程环境下进行并发访问。
性能差异:由于List需要维护有序性,因此在插入、删除、查找等操作时需要进行比较和排序操作,这些操作会带来一定的性能开销。而Map使用哈希表来实现快速的查找操作,因此在查找操作时性能较高。
3、那么什么是Map?
Map是 Java 中的一个接口,它表示映射表,即一种将键映射到值的数据结构。在 Map 中,每个键最多只能映射到一个值。常见的实现类包括 HashMap,TreeMap和 LinkedHashMap。 Map接口提供了一系列方法来操作映射表,例如 put()用于添加键值对,get()用于获取指定键所对应的值等。
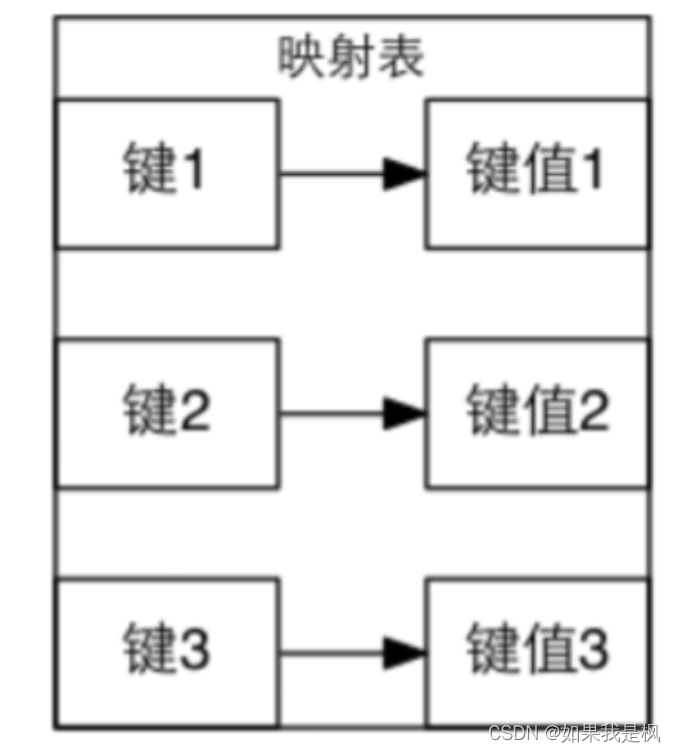
4、如何让map存储有序数据?
在Java中,Map是一个无序的键值对集合,如果需要存储有序的数据,可以考虑使用LinkedHashMap。
LinkedHashMap继承自HashMap,它可以记录元素的插入顺序或者访问顺序,即元素按照插入或者访问的顺序进行排序。因此,在使用LinkedHashMap时,可以保证元素的顺序与插入或访问的顺序相同。
下面是一个示例代码:
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapExample {
public static void main(String[] args) {
// 创建一个空的LinkedHashMap对象
Map<String, Integer> map = new LinkedHashMap<>();
// 向LinkedHashMap中添加元素,元素会按照插入顺序进行排序
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
// 从LinkedHashMap中获取元素,元素也会按照插入顺序进行排序
System.out.println(map.get("A")); // 输出1
System.out.println(map.get("B")); // 输出2
System.out.println(map.get("C")); // 输出3
}
}
需要注意的是,由于LinkedHashMap需要维护元素的插入顺序或者访问顺序,因此它的性能可能会比HashMap略低一些。同时,由于LinkedHashMap是线程不安全的,如果需要在多线程环境下使用,需要进行同步处理。
5、如何创建Map?
在Java中,创建Map可以使用以下几种方式:
1. 使用HashMap构造函数创建Map对象
Map<String, Integer> map = new HashMap<>();
这个示例代码创建了一个键类型为String,值类型为Integer的HashMap对象。需要注意的是,如果没有指定容量,HashMap会根据元素数量自动调整容量大小。
1. 使用Collections.singletonMap()方法创建Map对象
Map<String, Integer> map = Collections.singletonMap("key", "value");
这个示例代码创建了一个只包含一个键值对的Map对象,其中键为"key",值为"value"。需要注意的是,该方法返回的是一个不可变的Map对象。
1. 使用Map.putAll()方法创建Map对象
Map<String, Integer> map = new HashMap<>();
map.putAll(new HashMap<>());
这个示例代码创建了一个空的HashMap对象,并使用Map.putAll()方法将另一个Map对象中的键值对添加到当前Map对象中。需要注意的是,该方法是线程安全的。
1. 使用Stream API创建Map对象
Map<String, Integer> map = Stream.of(new AbstractMap.SimpleEntry<>("key", "value"))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
这个示例代码使用Stream API创建了一个键类型为String,值类型为Integer的Map对象。需要注意的是,该方法返回的是一个临时性的Map对象,如果需要将其转换为真正的Map对象,可以使用toMap()方法进行转换。
6、常用的Map有哪些?
在Java中,常用的Map有以下几种:
1. HashMap
HashMap是最常用的Map类型之一,它是基于哈希表实现的。它提供了快速的插入、删除和查找操作,并且支持null键和null值。但是,由于哈希表的结构不稳定,如果发生哈希冲突,会导致链表扩容,从而影响性能。
2. LinkedHashMap
LinkedHashMap是继承自HashMap的一种Map类型,它维护了元素的插入顺序或者访问顺序。因此,在使用LinkedHashMap时,可以保证元素的顺序与插入或访问的顺序相同。但是,由于它需要维护链表结构,所以它的性能可能会比HashMap略低一些。
3. TreeMap
TreeMap是一种基于红黑树实现的有序Map类型。它提供了按照自然顺序或者自定义排序方式进行排序的能力。由于它是基于红黑树实现的,所以它的性能相对较高。但是,由于它的遍历方式比较特殊,所以对于某些场景可能不太适用。
7、Map集合几种遍历方式?
答:
第一种: 通过Map.keySet获取key的Set集合,之后在通过key进行遍历
第二种: 通过Map.values获取所有value,之后再进行遍历
第三种: 通过Map.entrySet获取Set集合,之后通过iterator进行遍历
第四种: 直接通过foreach对Map.entrySet获取的Set集合进遍历
代码示例:
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//第一种:通过Map.keySet遍历key和value
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//第二种:通过Map.entrySet使用iterator遍历key和value
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
============了解===========
//第三种:通过Map.entrySet遍历key和value
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第四种:通过Map.values()遍历所有的value,但不能遍历key
for (String v : map.values()) {
System.out.println("value= " + v);
}
}
8、什么是HashMap?
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了不同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。另外,HashMap是非线程安全的,也就是说在多线程的环境下,可能会存在问题,而Hashtable是线程安全的。
HashMap的初始值为16
注意:在使用HashMap时,要确保键的唯一性,并正确实现键的hashCode()和equals()方法。如果需要线程安全性,可以考虑使用ConcurrentHashMap或进行外部同步操作。
9、HashMap什么时候进行扩容,是如何扩容的?
答:
当HashMap中的元素个数超过数组大小*loadFactor时,就会进行数组双倍扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32
10、如何在HashMap中插入一个数据
HashMap的put方法
将指定的值与此映射中的指定键相关联,如果Map中已经包含了该键的映射,那么旧的映射值将会被替代,也就是说在put时,如果map中已经包含有key所关联的键值对,那么后续put进来的键值对,将会以相同key为准替换掉原来的那一对键值对。
返回的值则将是之前在map中实际与key相关联的Value值(也就是旧的值),如果key没有实际映射值的话那就返回null。
内部实现时则立马调用了其内部putValue方法,并将put进去(覆盖)之前的结果k-v中的v进行了返回,进行值的覆盖
// 创建一个 HashMap
HashMap<Integer, String> map = new HashMap<>();
// 往 HashMap 添加一些元素
map.put(1, "11");
map.put(2, "22");
map.put(3, "33");
System.out.println("HashMap: " + map);//HashMap: {1=11, 2=22, 3=33}
//如果存储的key已经存在,则直接覆盖数据
map.put(1,"44");
System.out.println("HashMap: " + map);//HashMap: {1=44, 2=22, 3=33}
总结
在 HashMap 中,元素是以键值对的形式存储的,可以通过调用 put(key, value) 方法将元素存储到 HashMap 中。具体的操作流程如下:
1.创建一个新的键值对(Entry)对象,将要存储的键和值作为参数传入。
2.对键进行哈希运算,以得到在底层数组中的位置(桶)。
3.如果该位置为空,则将新的键值对放入该位置。
4.如果该位置已经存在键值对,则进行链式存储。新的键值对将成为链表头部,原有键值对将成为链表的后继节点。
5.如果链表长度达到一个阈值(默认为8),则会将链表转化为红黑树结构,以提高查找效率。
6.如果键已经存在于 HashMap 中,则会将原有的值替换为新的值。
11、HashMap和TreeMap区别?
HashMap和TreeMap都是Java中常用的集合类型,它们都可以存储一组有序或无序的元素。但是,它们在实现方式、性能以及使用场景等方面有一些不同点。
1.实现方式
HashMap是基于哈希表实现的,它通过哈希函数将键值对映射到数组的某个位置上,从而实现快速的插入、删除和查找操作。由于哈希表的结构不稳定,如果发生哈希冲突,会导致链表扩容,从而影响性能。
TreeMap是基于红黑树实现的,它通过维护红黑树结构来保证元素的有序性。由于它是基于红黑树实现的,所以它的性能相对较高。但是,由于它的遍历方式比较特殊,所以对于某些场景可能不太适用。
2.性能
在单线程环境下,HashMap的性能比TreeMap要好一些,因为HashMap可以通过哈希函数快速定位元素的位置。但是,在多线程环境下,由于哈希冲突的存在,HashMap的性能会受到影响。
在多线程环境下,TreeMap的性能比HashMap要好一些,因为它可以通过红黑树的性质保证元素的有序性。但是,由于TreeMap需要进行遍历操作,所以在并发访问量较大的情况下,可能会出现性能瓶颈。
3.使用场景
HashMap适用于需要快速插入、删除和查找元素的场景,例如缓存、计数器等。由于HashMap的性能较好,所以在这些场景下使用HashMap可以获得较好的性能表现。
TreeMap适用于需要保持元素有序性的场景,例如按照时间顺序排序或者按照某个属性排序等。由于TreeMap的性能较差,所以在这些场景下使用TreeMap可能会导致性能瓶颈。
总之,HashMap和TreeMap都有各自的优缺点和适用场景,需要根据具体的需求来进行选择。
12、HashMap和HashTable有什么区别?
- 线程安全性:HashTable是线程安全的,即在多线程环境下可以进行并发操作而不需要额外的同步机制。它通过在方法级别上添加锁来实现线程安全。而HashMap则不是线程安全的,需要在多线程环境中采取额外的同步措施,例如使用
ConcurrentHashMap或手动添加同步机制。 - 空键和空值:HashTable不允许使用
null作为键或值,即键和值都不能为null。而HashMap则可以使用null作为键和值。 - 继承关系:HashTable是早期Java集合框架的一部分,它继承自
Dictionary类,并实现了Map接口。而HashMap则是Java集合框架的一部分,实现了Map接口,但没有继承任何类。 - 迭代顺序:HashTable不保证迭代键值对的顺序,而HashMap在大多数情况下也不保证。但从Java 8开始,HashMap提供了一种顺序保证的实现——
LinkedHashMap,可以按照插入顺序或访问顺序迭代键值对。 - 性能:由于HashTable的线程安全性需要额外的同步开销,所以在单线程环境下,HashMap通常比HashTable具有更好的性能。HashMap在没有竞争的情况下不需要同步,可以提供更快的读写操作。
总结:
1、HashMap是非线程安全的,HashTable是线程安全的。
2、HashMap的键和值都允许有null值存在,而HashTable则不行。
3、因为线程安全的问题,HashMap效率比HashTable的要高
4、HashMap适合于单线程环境,而Hashtable适合于多线程环境
13、HashMap是如何实现的?
HashMap底层实现JDK<1.8数组+链表 JDK>1.8数组+链表+红黑树;
当链表的长度大于8时,并且数组长度大于64的时候,自动升级为红黑树
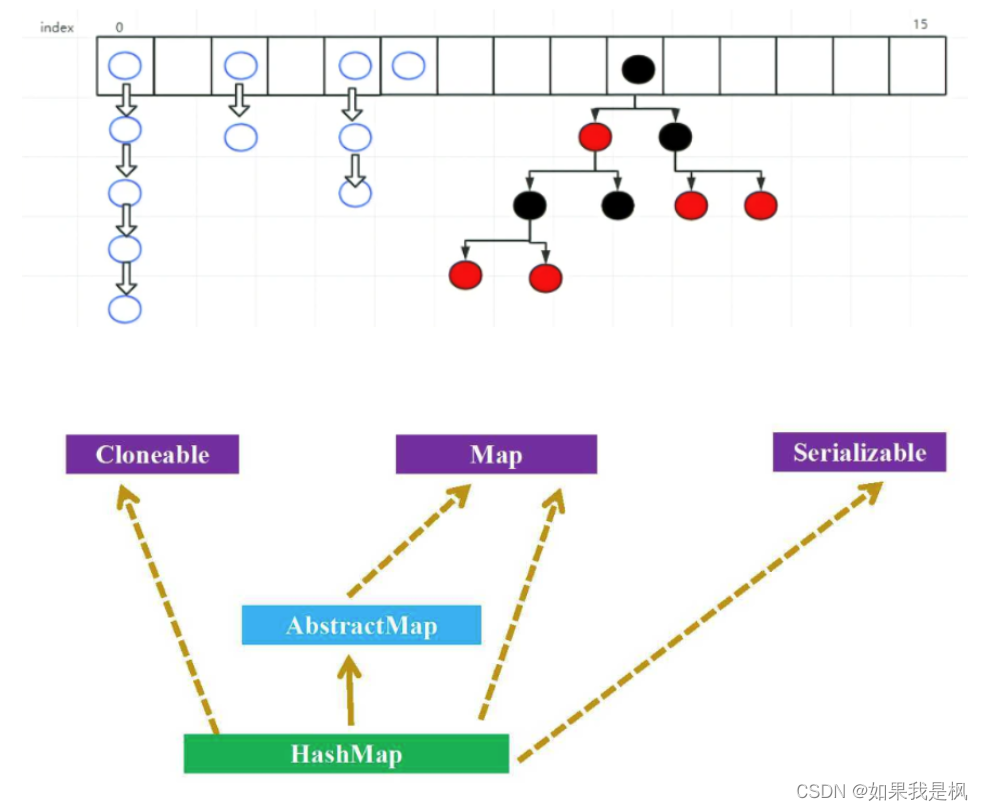
14、HashMap是怎么解决哈希冲突的?
答:
这个问题需要从以下几个方面来回答:
第一,想要了解hash冲突,首先我们需要了解一下Hash算法和Hash表。
Hash算法就是把任意长度的输入通过散列算法变成固定长度的输出,这个输入结果就是一个散列值。
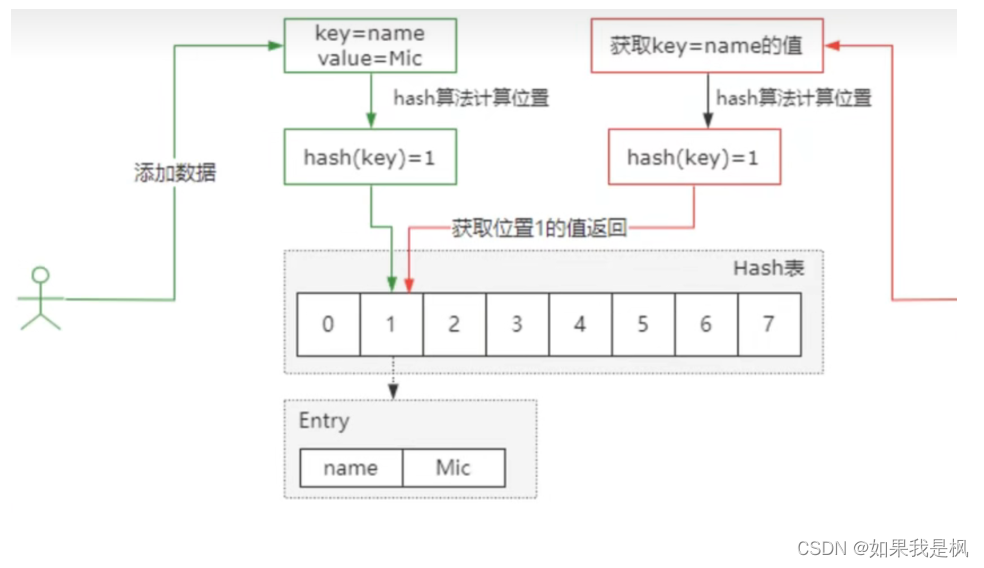
第二Hash表又叫做散列表,它是通过Key直接访问到内存存储位置的数据结构。在具体时间上呢,我们通过Hash函数,把Key映射到表中的某个位置,来获取这个位置的数据,从而去加快数据的查找。
所谓的Hash冲突,是由于被计算的数据是无限的,而计算后的结果的范围是有限的,所以总会存在不同的数据,经过计算之后得到的值是一样的,那么这个时候就会出现所谓的Hash冲突。
第三,通常解决Hash冲突的方法有四种。
1、开放定址法,也称线性探测法。就是从发生冲突的那个位置开始,按照一定次序,从Hash表中去找到一个空闲的位置,然后把发生冲突的元素存入到这个位置,而在Java中,ThreadLocal就用到了线性探测法来解决Hash冲突,像这种情况,在Hash表索引1的位置存了一个Key=name,再向它添加Key=hobby的时候,假设Hash计算得到的索引也是1,就会冲突,而开放定址法就是按照顺序,向前去找到一个空闲的位置,来存储这个空闲的Key。
2、链式寻址法,简单理解就是把存在Hash冲突的key,以单项链表的方式来进行存储,比如HashMap就用到了链式寻址法。
3、再hash法,就是通过某个Hash函数计算的Key存在hash冲突之后,再对这个Key进行Hash,一直运算直到不再产生冲突为止,这个方式会增加计算的一个时间。
4、建立公共溢出区,就是把Hash表分为基本表和溢出表两个部分,凡是存在冲突的元素,一律放到溢出表中。
第四个,HashMap在JDK1.8版本中是通过链式寻址法以及红黑树的方式来解决Hash冲突问题的,其中红黑树是为了优化Hash表的链表过长导致时间复杂度增加的一个问题,当链表长度大于8并且Hash表的容量大于64的时候,再向链表中添加元素
15、为什么1.8中引入红黑树?
当我们的HashMap中存在大量数据时,加入我们某个bucket下对应的链表有n个元素,那么遍历时间复杂度就为O(n),为了针对这个问题,JDK1.8在HashMap中新增了红黑树的数据结构,进一步使得遍历复杂度降低至O(logn);
简单总结一下HashMap是使用了哪些方法来有效解决哈希冲突的:
- 使用链地址法(使用散列表)来链接拥有相同hash值的数据;
- 使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均;
- 引入红黑树进一步降低遍历的时间复杂度,使得遍历更快;
拓展:红黑树
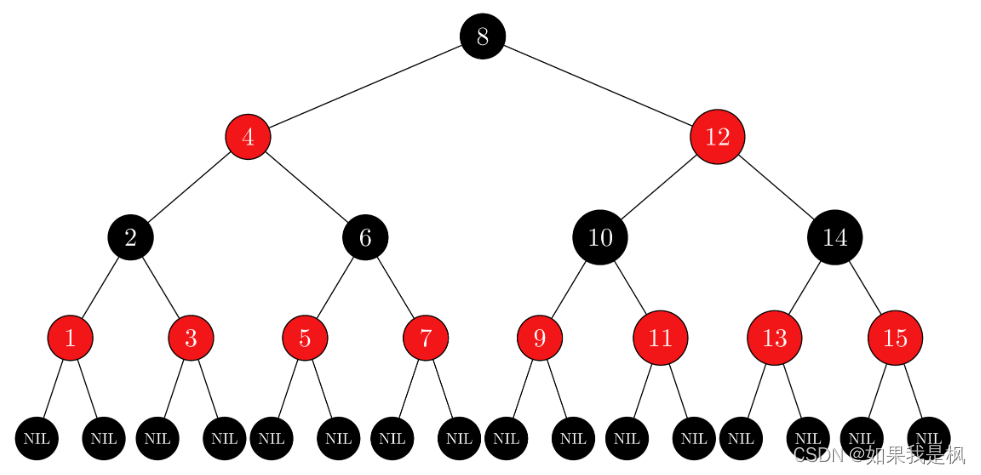
红黑树(Red-Black Tree)是一种自平衡的二叉搜索树,通过节点的颜色和旋转操作来保持树的平衡性。在最坏情况下的插入、删除和查找操作的时间复杂度为 O(log n)。具有以下特性:
-
节点颜色:每个节点要么是红色,要么是黑色。
-
根节点:根节点是黑色的。
-
叶子节点:叶子节点(空节点)都是黑色的。
-
红色节点特性:
- 红色节点的子节点必须是黑色的。
- 红色节点的父节点必须是黑色的。
-
黑高度平衡:从根节点到任意叶子节点的路径上,黑色节点的数量相同。也就是说,任意路径上的黑色节点数量相等,确保了树的平衡性。
6.红黑树可以用于实现有序集合(例如 Java 中的 TreeMap)和有序映射(例如 Java 中的 TreeMap)等数据结构。
7.红黑树的插入和删除操作可能需要进行颜色调整和旋转操作,以保持红黑树的特性。
总结:红黑树是一种自平衡的二叉搜索树,通过节点的颜色和平衡性规则来保持树的平衡。它具有高效的插入、删除和查找操作,适用于需要动态维护有序集合或有序映射的场景。
16、HashMap是线程安全的吗?如果不是,有有哪些线程安全的Map?
答:
HashMap本身是线程不安全的.
线程安全的map:
ConcurrentHashMap
HashTable
Collections.synchronizedMap(map) 可以将线程不安全的HashMap转变为线程安全的map
17、HashMap的key和value能否为null?
答:
可以
18、简述HashMap的put方法执行流程?
答:
1. 计算key的hash值,通过hash值得到数组下标
3. 如果数组下标处还没被占用,创建Node节点,插入对应数组下标位置
4. 如果数组下标已经有人占用,判断该数组下标处存储的Node类型
1. 已经是 TreeNode 走红黑树的添加或更新逻辑
2. 是普通 Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值【8】并且Hash表的容量大于64的时候,走树化逻辑。
5. 返回前检查容量是否超过阈值,一旦超过进行扩容
19、简述HashMap的get方法执行流程?
答:
1 通过key的hash值,计算出该key对应的数组下标位置,根据数组下标获取数据节点对象【首节点】;
2 判断首节点是否为空, 为空则直接返回空;
3 再判断首节点的 key值 是否和目标值相同, 相同则直接返回(首节点不用区分链表还是红黑树);
4 通过首节点.next,获取下个节点,判断是否为空:是说明没有数据了,则直接返回空;
5 首节点后面还有节点,则判断首节点类型,如果是树形节点, 则进入红黑树数的取值流程, 并返回结果;
6 如果是链表类型,进入链表的取值流程, 并返回结果;
20、HashMap是有序的吗?如果不是,你知道哪些map是有序的?
答:
不是,LinkedHashMap和TreeMap是有序
21、ConcurrentHashMap是如何保证线程安全的?

答:
ConcurrentHashMap在JDK 1.7中使用的数组 加 链表的结构,其中数组分为两类,大数组Segment 和 小数组 HashEntry,而加锁是通过给Segment添加ReentrantLock重入锁来保证线程安全的【分段加锁】。
ConcurrentHashMap在JDK1.8中使用的是数组 加 链表 加 红黑树的方式实现,它是通过 CAS 和 synchronized 来保证线程安全的,并且缩小了锁的粒度,查询性能也更高。
1、使用了 volatile 修饰 table 变量,并使用 Unsafe 的 getObjectVolatile() 方法拿到最新的 Node
2、CAS 操作:如果上述拿到的最新的 Node 为 null,则说明还没有任何线程在此 Node 位置进行插入操作,说明本次操作是第一次
3、synchronized 同步锁:如果此时拿到的最新的 Node 不为 null,则说明已经有线程在此 Node 位置进行了插入操作,此时就产生了 hash 冲突;此时的 synchronized 同步锁就起到了关键作用,防止在多线程的情况下发生数据覆盖(线程不安全),接着在 synchronized 同步锁的管理下按照相应的规则执行操作:
当 hash 值相同并 key 值也相同时,则替换掉原 value
否则,将数据插入链表或红黑树相应的节点。
22、统计如下英文语句中所有字母出现的次数,结果使用map封装,例如:{“a”:10,“b”:20 ,…}
Chaoyang District is a good place to have fun. It’s on Chaoyang Street. It’s a very busy but clean street. There is a nice school, a clean park, a beautiful garden, a big supermarket, a quiet library and a good restaurant.
//你的代码:
public static void main(String[] args) {
String content = "Chao yang District is a good place to have fun. It’s on Chao yang Street." +
" It’s a very busy but clean street. " +
"There is a nice school, a clean park, a beautiful garden, " +
"a big supermarket, a quiet library and a good restaurant.";
countNumbers(content);
}
private static void countNumbers(String content) {
if (content == null || content.length() < 1) {
return;
}
HashMap<Character, Integer> map = new HashMap<>();
char c;
//遍历短文
for (int i = 0; i < content.length(); i++) {
c = content.charAt(i);
if((c>=65&&c<=90)||(c>=97&&c<=122)){
if (map.containsKey(c)) {
//有相同的,直接加一
map.put(c, map.get(c) + 1);
}else {
//没有相同则存入
map.put(c, 1);
}
}
}
//最后遍历map
for (Character key : map.keySet()) {
System.out.println(key+":"+map.get(key));
}
}
23、统计出每个国家分别在哪些年举行过世界杯
//如下map集合数据,统计出每个国家分别在哪些年举行过世界杯
Map<String, String> map = new HashMap<String,String>();map.put("1930", "乌拉圭");
map.put("1934", "意大利");
map.put("1938", "意大利");
map.put("1950", "乌拉圭");
map.put("1954", "西德");
map.put("1958", "巴西");
map.put("1962", "巴西");
map.put("1966", "英格兰");
map.put("1970", "巴西");
map.put("1974", "西德");
map.put("1978", "阿根廷");
map.put("1982", "意大利");
map.put("1986", "阿根廷");
map.put("1990", "西德");
map.put("1994", "巴西");
map.put("1998", "法国");
map.put("2002", "巴西");
map.put("2006", "意大利");
map.put("2010", "西班牙");
map.put("2014", "德国");
//最终数据封装到map集合中,key为国家的名称,value为这个国家举办过世界杯的年份的集合,例如
// 意大利:[1934,1938,1982,2006]
Map<String, List<String>> result = new HashMap<>();
for (String time : map.keySet()) {//遍历map中的所有key,key为举办世界杯的时间
String country = map.get(time);//获取key对应的value,即举办国
List<String> list = result.get(country);//根据国家名称,从result结果中获取对应的举办时间集合
if(list == null){//如果为空,说明result结果集合中没有当前国家的举办时间集合,需要新建一个。
list = new ArrayList<>();
}
list.add(time);//添加举办时间
result.put(country,list);//存入结果集合中
}
//打印结果
for (String key : result.keySet()) {
System.out.println(key +":"+result.get(key));
}
















 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









