







本章内容概述
本文用于笔者学习《C++新经典》一书中并发与多线程内容是,记录笔记之用,并酌情附加笔者的个人思考与补充,希望可以更好的掌握 C++ 中并发与多线程相关的知识。
需要强调的是,本章内容笔者也是初次接触,对书中部分内容会加入更多笔者自己的验证和理解,由于笔者水平受限,而并发与多线程作为难度绝不次于对象模型的一块知识,难免会出现错误之处,也希望读者指正。最后,希望本章内容能帮助笔者和读者更深刻的理解和掌握 C++ 并发与多线程相关的知识。
一、基本概念
首先对并发与多线程中提到的相关名词做出解释,如并发、进程、线程等。
1. 并发,进程,线程
并发,是指在同一时刻执行多个任务,这依赖于多个处理器或单个多核处理器来实现,同时做多个任务可以提高计算机性能。与之相关的还有并行的概念,并行是指,虽然仅有一个单核处理器,但是处理器会在多个任务之间不断地进行快速切换,即上下文切换,从而使得看起来是多个任务在同时被处理,称为并行,本质上在某一时刻依然只有一个任务再在被处理。
进程,进程可以被看做一个正在执行的任务,多个任务同时进行,即多进程,本质上,进程就是一个运行中的可执行程序。
线程,是比进程更小的运行单位,每个进程都有一个主线程,当主线程结束后,代表这个进程运行结束。但是在主线程运行期间,可以通过编写代码创建其他线程,与主线程同时运行。
当然,线程并不是越多越好,线程创建也需要分配独立的堆栈空间等资源,但是在某些情况下,如服务器,必须使用多线程的方式设计才能满足用户需求。
因此,多线程程序开发的学习很有必要,难度也会更高,代码会更复杂,在学习中不能急于求成,要稳扎稳打,保证理解每个知识点后再继续学习。这对以后在昂罗通信、网络服务器领域的发展很有帮助。
2. 并发的实现
在程序中实现并发,一般有两种方法,可以通过创建多个进程实现,也可以在单一进程下创建多个线程实现。
2.1 多进程并发
每次运行可执行程序,都会产生一个改程序的进程,多次运行,则会产生多个进程,但是多个进程之间内存相互独立,数据受到保护,进程间通信较为复杂,并不是最理想的实现方法。
2.2 多线程并发
多线程,即在单个进程下创建多个线程,这些线程共享内存空间,可以访问并操作共享数据,因此多线程的开销远小于多进程,但是也会带来相应的问题,即多线程在操作共享数据时很容易引发冲突,这需要合适的方式解决。
综合来看,多线程并发启动速度更快,更轻量级,而且系统开销少,执行速度快,同时需要注意共享资源的保护。本文主要讨论的,也是多线程并发的内容。
3. C++11 新标准线程库
通常情况下,编写多线程并发的程序时,在不同操作平台下的方法也不尽相同,如 Windows 系统下需要用 CreateThread 函数创建线程,同时涉及许多线程相关的概念(临界区,互斥量),在 Linux 系统下使用 pthread_create 创建线程。那么不难得出,这些代码不能跨平台使用,如需编写跨平台代码,需要配置专业的环境,并不十分方便。
C++11 中弥补了这一缺憾,增加了语言本身对多线程的支持可以使用语言本身自带的接口进行编写,大大提高了代码可移植性。本章重点介绍C++11 下的多线程程序编写。
二、线程基本使用
在程序运行时,一般都会沿 main 函数这一条主线程进行,这条线程是自动创建的,从 main 函数开始执行,当 main 函数执行完毕后,主线程也就结束。其余线程也与之类似,可以通过入口函数开始执行,当入口函数执行完毕后,该线程也就执行结束。但是需要注意的是,整个程序结束的标志,是 main 函数所在主线程的结束,即当主线程结束后,其余未完成的线程将被强制终止,因此如果需要子线程完整执行,必须在主线程中等待。
1. 线程创建与启动
在主函数中创建子线程并调用接口函数,代码如下:
#include <iostream>
#include <thread>
using namespace std;
void show() //子线程入口函数,表示子线程从这里开始运行
{
cout << "show thread begin" << endl;
cout << "show thread work" << endl;
cout << "show thread end" << endl;
}
int main()
{
cout << "main thread begin" << endl;
thread showThread(show); //实例化出一个线程类对象,并用 show 函数初始化,子线程开始运行
showThread.join(); //表示需要等待该线程运行结束,主线程才能继续运行
return 0;
}
运行结果如下图所示:
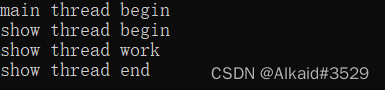
从图中可以看出,主线程和子线程分别在各自的入口函数结束后结束,也符合预期。在这里需要注意的是:
thread,这是一个类,可以通过这个类实例化出的对象来创建子线程,初始化时需要提供子线程对应的入口函数,此处注意,笔者翻阅源码查看了 thread 的构造函数,虽然存在无参构造,但是笔者测试如果不提供入口函数进行调用,会引发程序崩溃,(如果仅创建却不使用不会,但没有意义),因此笔者建议一定要在实例化一个线程对象时绑定该线程的入口函数。
join,表示主程序运行到此处时,应当等待该子线程完成后再继续运行,是一种安全的线程使用方式,可以保证主程序不会在子线程结束前结束,使得子线程以外访问非法内存。
detach,表示主程序无需在意该线程运行情况,可以自由结束,但也会导致失去对改线程的控制,并不安全,因此笔者不推荐使用这种方式管理线程,此处不作演示。
joinable,针对一个线程,在调用 join 后,是不可以再次调用 detach 的,否则会导致程序异常,joinable 可以用于判断线程是否已经调用过结束方式,同时避免多次调用 join 或者 detach ,代码如下:
if (showThread.joinable()) { showThread.join(); }
通过查看 join 和 detach 的源码,不难发现,源码中也是这样子处理的,代码如下:
void join()
{
if (!joinable()) { _Throw_Cpp_error(_INVALID_ARGUMENT); }
if (_Thr._Id == _Thrd_id()) { _Throw_Cpp_error(_RESOURCE_DEADLOCK_WOULD_OCCUR); }
if (_Thrd_join(_Thr, nullptr) != _Thrd_success) { _Throw_Cpp_error(_NO_SUCH_PROCESS); }
_Thr = {};
}
void detach()
{
if (!joinable()) { _Throw_Cpp_error(_INVALID_ARGUMENT); }
_Check_C_return(_Thrd_detach(_Thr));
_Thr = {};
}
2. 其余线程创建方法
除了先前提到的,使用入口函数作为县城创建方式,还有其余的线程创建方式,如使用类或者 lambda 表达式创建,不过需要注意的是如果用类对象进行创建线程,务必要注意对象的释放时机,如果在子线程运行结束前意外释放对象内存,和容易产生非法访问内存的问题,更为详细的关于对象作为线程函数创建线程时的内存管理与传递方式,将会在下一部分详细讲解。
三、线程参数传递
线程传递参数时,在 join 情况下一般正常,但如果在 detach 情况下,很容易产生子线程还未执行完毕,主线程已经释放相关内存的问题,未避免这种情况,需要对1传递的参数的状态进行更多的测试与探讨。
1. 临时对象做线程参数
关于传递参数方式的问题,笔者从最简单的按值传递讲起,逐步分析在创建线程时编译器对参数的处理方式究竟如何。为方便观察测试条件,首先创建用于测试的类,代码如下:
class A
{
public:
A(int v = 0) :a(v) { cout << "this = " << this << ", a = " << a << ", construct" << endl; }
A(const A& temp) { a = temp.a; cout << "this = " << this << ", a = " << a << ", copy construct" << endl; }
~A() { cout << "this = " << this << ", a = " << a << ", destruct" << endl; }
private:
int a;
};
分别在构造、拷贝和析构是输出对象信息,方便观察,接下来是线程入口函数,代码如下:
void show(A temp) //子线程入口函数,表示子线程从这里开始运行
//void show(const A& temp) //子线程入口函数,表示子线程从这里开始运行
{
cout << "show thread begin" << endl;
cout << "&temp = " << &temp << endl;
cout << "show thread end" << endl;
return;
}
然后便可以开始测试了,主函数代码如下:
int main()
{
cout << "main thread begin" << endl;
A a1;
thread showThread(show,a1); //实例化出一个线程类对象,并用 show 函数初始化,子线程开始运行
showThread.join(); //表示需要等待该线程运行结束,主线程才能继续运行
return 0;
}
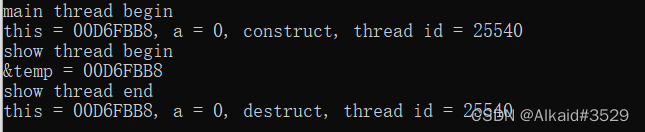
首先采用最普通的传递方式,按值传递,观察输出结果:
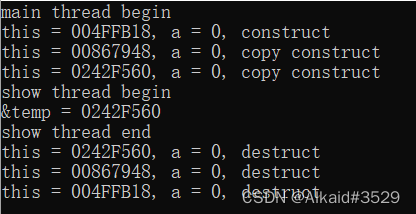
可以观察到,在对象第一次创建之后,在子线程开始运行之前,一共发生了两次对象拷贝,在子线程中使用的是第二次拷贝的结果,那么在这里抛出一个疑问,为什么多发生了一次对象拷贝?多拷贝出的这个对象又是做什么用的呢?
带着这个问题,分析看一下第二种传递方式,引用传递,观察输出结果:
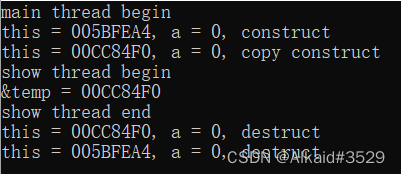
意料之内的是,确实比按值传递减少了一次拷贝,并且子线程内使用的是拷贝出的对象,但是意料之外的是,依然存在一次拷贝构造,而且,既然是引用传递,为什么子线程内使用的并不是主函数创建出的对象呢?
暂时不考虑这个问题,尝试使用指针传递,代码如下:
//void show(A temp) //子线程入口函数,表示子线程从这里开始运行
//void show(const A& temp) //子线程入口函数,表示子线程从这里开始运行
void show(A* temp) //子线程入口函数,表示子线程从这里开始运行
{
cout << "show thread begin" << endl;
cout << "temp = " << temp << endl;
temp->a = 10;
cout << "show thread end" << endl;
return;
}
这次的结果终于符合正常预期了,在不发生任何拷贝的情况下,可以修改主函数中的对象:
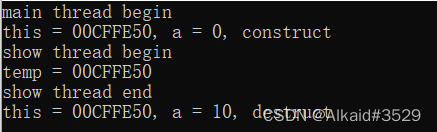
现在再回顾先前的问题,为什么总存在一次拷贝无法甩掉呢?这是语言特性还是编译环境问题呢?再次进行测试。
经笔者测试,在 linux 环境下,g++ 编译后的运行结果也是如此,笔者猜测,可能是考虑到在引用情况下,很容易出现主线程提前结束而子线程非法访问的意外,未避免此类情况发生,语言作出了如此处理,使得即便未考虑到此问题,也能保证代码安全性。
那么如果确实需要在子线程内部访问主函数中的变量呢?C++11 专门提供了特定的方法,随后讲解。
经过了上述大量测试,相信读者对参数传递的方式有了基本认识,接下来引入新的知识——中间变量创建时机,中途拷贝的变量,究竟是在主函数还是在子线程中创建的呢?可以通过观察线程序号实现,代码如下:
class A
{
public:
A(int v = 0) :a(v) { cout << "this = " << this << ", a = " << a << ", construct" <<", thread id = "<<this_thread::get_id() << endl; }
A(const A& temp) { a = temp.a; cout << "this = " << this << ", a = " << a << ", copy construct" << ", thread id = " << this_thread::get_id() << endl; }
~A() { cout << "this = " << this << ", a = " << a << ", destruct" << ", thread id = " << this_thread::get_id() << endl; }
private:
int a;
};
在引用传递的情况下,结果如下:

不难看出,创建时机都在主函数内部,而子线程内的对象的析构时机在子线程内部,这也就意味着,不会发生子线程意外使用主函数析构的空间,主函数提前结束也不会影响子线程内部对象的析构。
除此之外,笔者还建议,一般情况下传递简单参数时,按值传递即可,可以避免很多意外;必须传递引用时,可以选择使用临时对象作为参数,在传递结束后临时对象立刻被析构,子线程中的对象在主函数内创建,在子线程内析构,是很好的选择。
2. 实参对象做线程参数
在特殊情况下,如果确实需要传递实参到子线程中,可以使用 std::ref ,代码如下:
thread showThread(show, ref(a1));
运行结果可以看到,无多余拷贝,实参传递:
四、多线程创建与共享数据保护
1. 多线程创建
在主函数内一次性创建多个线程,并依次调用,代码如下:
#include <iostream>
#include <thread>
#include <vector>
using namespace std;
void show(int i) //子线程入口函数,表示子线程从这里开始运行
{
cout << "show thread" << i << " begin" << endl;
cout << "show thread" << i << " end" << endl;
return;
}
int main()
{
cout << "main thread begin" << endl;
vector<thread> showThreadCac;
for (int i = 0; i < 3; i++) { showThreadCac.push_back(thread(show, i)); }
for (auto iter = showThreadCac.begin(); iter != showThreadCac.end(); iter++) { iter->join(); }
return 0;
}
运行结果如下图所示:
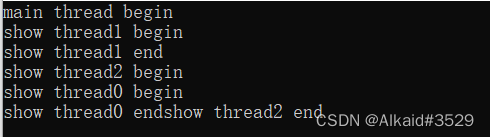
可以看出,给线程之间运行顺序杂乱无章,输出结果也是无规律可循,证明多个线程之间运行无顺序可言。
2. 共享数据保护
既然多线程之间运行顺序杂乱无章,那么不可避免联想到,如果需要多线程之间共同访问某些数据,甚至是共同读写某些数据时,无顺序的访问和读写势必会破坏共享数据的安全性,这个问题必须解决,可以先直观感受一下,代码如下:
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
using namespace std;
class Mail
{
public:
void recvMail() { for (int i = 0; i < 100; i++) { cout << "mail" << i << " comes" << endl; mailbox.push_back(i); } }
void getMail()
{
int mail = 0;
for (int i = 0; i < 100; i++)
{
if (!mailbox.empty())
{
mail = mailbox.front();
cout << "succeed to get mail" << mail << endl;
mailbox.erase(mailbox.begin());
}
else { cout << "try to get mail, but the box is empty" << endl; }
}
cout << endl;
}
private:
vector<int> mailbox;
};
int main()
{
Mail m1;
thread mthread1(&Mail::recvMail, ref(m1));
thread mthread2(&Mail::getMail, ref(m1));
mthread1.join();
mthread2.join();
return 0;
}
运行后不出意外的发生了意外,输出混乱不堪,那么接下来,笔者就从此问题入手,详细分析,由此正式进入并发与多线程讨论分析。
五、互斥量
笔者浅薄的认为,整个并发与多线程的核心,最关键的点就在于共享数据的访问与读写,如何安全的操作共享数据时亟需解决的核心问题,要想解决这个问题,互斥量,就是一种很高效的工具,因此,笔者会尽可能对此概念进行充分的讲解。
1. 基本概念
互斥量,英译 mutex ,本质上,mutex 是一个类,可以将其理解为一把锁。在同一时间,多个线程都可以使用这把锁,用这把锁将该线程试图访问的共享数据“锁住”,即 lock ,一旦某个线程加锁成功,那么其余试图加锁的线程都会因加锁失败而卡在试图加锁处,只有当“上锁”的线程解锁后,其余线程才能有且仅有一个加锁成功。因此,不难得出结论,访问共享数据必须加锁,访问结束后必须解锁,否则都会影响其余线程的进行。
互斥量,使用时务必小心谨慎,基本原则有:访问共享数据必须加锁,每次上锁都必须有对应的解锁,尽可能对最少的代码加锁,尽快解锁。
2. 基本使用
2.1 mutex
使用时需要实例化出对象,通过对于对应函数进行加锁,代码如下:
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
using namespace std;
class Mail
{
public:
void recvMail()
{
for (int i = 0; i < 100; i++)
{
mailmutex.lock();
cout << "mail " << i << " comes" << endl;
mailbox.push_back(i);
mailmutex.unlock();
}
}
void getMail()
{
int mail = 0;
for (int i = 0; i < 100; i++)
{
mailmutex.lock();
if (!mailbox.empty())
{
mail = mailbox.front();
mailbox.erase(mailbox.begin());
cout << "succeed to get mail " << mail << endl;
mailmutex.unlock();
}
else
{
cout << "try to get mail, but the box is empty" << endl;
mailmutex.unlock();
}
}
cout << endl;
}
private:
vector<int> mailbox;
mutex mailmutex;
};
int main()
{
Mail m1;
thread mthread1(&Mail::recvMail, ref(m1));
thread mthread2(&Mail::getMail, ref(m1));
mthread1.join();
mthread2.join();
return 0;
}
多次运行后,程序基本稳定,符合预期效果,笔者理解,mailmutex 相当于类本身自带了一把锁,当有线程锁住这把锁时,其余线程就不能打开这把锁,从而使得尝试打开这把锁的线程都被卡主,但是无需打开这把锁的线程却可以正常执行,这点很容易理解,因此,需要十分明确每把锁要锁住的数据,在本情境下,如果有两个信箱共访问,则势必需要两把锁分别锁住不同的信箱以提高效率,希望读者能够深刻理解锁的概念,这对接下来的学习十分重要。
2.2 lock_guard
前文提到,在每次访问共享资源时,务必要使用互斥量进行加锁,从而保证数据安全,但是每次加锁后,也一定要谨记对互斥量进行解锁,否则一定会导致程序崩溃。但是在编程过程中,难免会出现加锁后忘记解锁的情况,为了方便使用,C++ 推出了 lock_guard 模板,可以自动上锁与解锁,代码如下:
void getMail()
{
int mail = 0;
for (int i = 0; i < 100; i++)
{
lock_guard<mutex> mailguard(mailmutex);
//mailmutex.lock();
if (!mailbox.empty())
{
mail = mailbox.front();
mailbox.erase(mailbox.begin());
cout << "succeed to get mail " << mail << endl;
//mailmutex.unlock();
}
else
{
cout << "try to get mail, but the box is empty" << endl;
//mailmutex.unlock();
}
}
cout << endl;
}
观察运行结果,执行正常,即此模板可以自动为程序上锁,并自动解锁,从而保证访问共享数据的安全。其实不难理解,设想如果在一个类的构造函数中上锁,在析构函数中解锁,那么只在类对象的生存周期内访问共享数据,就肯定是安全的,lock_guard 原理即是如此。
但是需要注意的是,在使用类模板初始化对象时,依旧需要一个互斥量对象作为参数传入,不难理解,类模板中并不包含互斥量,依旧需要一把锁来实现上锁的功能。
既然会在产生对象时对互斥量上锁,那如果将已经锁住的互斥量传入会怎样呢?毫无疑问程序崩溃,前文提到,一把锁在解开之前是不能被重复锁住的,如果需要将已经锁住的互斥量传入 lock_guard 模板,那么需要添加额外的参数,表示传入的互斥量已经上锁,代码如下:
void getMail()
{
int mail = 0;
for (int i = 0; i < 100; i++)
{
mailmutex.lock();
lock_guard<mutex> mailguard(mailmutex, adopt_lock);
if (!mailbox.empty())
{
mail = mailbox.front();
mailbox.erase(mailbox.begin());
cout << "succeed to get mail " << mail << endl;
//mailmutex.unlock();
}
else
{
cout << "try to get mail, but the box is empty" << endl;
//mailmutex.unlock();
}
}
cout << endl;
}
运行正常,符合预期,可以看到,即便提前上锁,但是在传入 lock_guard 模板后,无需解锁,因为类析构函数会自动解锁传入的互斥量。
3. 死锁
3.1 基本概念
死锁,指在多把锁之间互相锁住而无法解开,导致整个程序停止不前。不难理解,如果存在多个线程需要同时锁住相同的两把锁,其中一个子线程锁住了第一把锁,另外一个子线程锁住了第二把锁,此时,第一个线程不断尝试锁住第二把锁失败,难以前进,二第二个线程尝试锁住第一把锁失败,无法前景,产生死锁。
为避免这种情况出现,在设计程序时应当提前考虑到这种情况,如固定两把锁的上锁顺序,使得子线程按照同一顺序对这两把锁上锁,即无法锁住第一把锁的线程也无法锁住第二把锁,进而避免死锁现象产生。
3.2 lock
lock 函数,可以一次性锁住两个及以上的互斥量,仅存在全部锁住和全部未锁住的情况,可以避免因上锁顺序引发的死锁问题,代码如下:
void getMail()
{
int mail = 0;
for (int i = 0; i < 100; i++)
{
//mailmutex.lock();
//lock_guard<mutex> mailguard(mailmutex,adopt_lock);
lock(mailmutex, mailmutex1);
if (!mailbox.empty())
{
mail = mailbox.front();
mailbox.erase(mailbox.begin());
cout << "succeed to get mail " << mail << endl;
mailmutex.unlock();
mailmutex1.unlock();
}
else
{
cout << "try to get mail, but the box is empty" << endl;
mailmutex.unlock();
mailmutex1.unlock();
}
}
cout << endl;
}
不难看出,函数可以完成一次性对多个互斥量上锁,但是需要注意的是,这个函数需要谨慎使用,因为在程序中,同时需要对两个互斥量上锁的情况并不多见,每把锁都保护相应的共享数据,同时锁住两把锁意味着需要同时访问两块共享数据,这是不多见的操作,因此使用需谨慎,滥用锁会导致程序效率变低。
4. 递归互斥量
前文可知,一个互斥量是不能上两次锁的,很容易引发程序崩溃,相信也不会有读者专门连读对一个互斥量上两次锁,但是现在请读者假象一种情况,在两个函数中,都需要访问某共享变量,因此分别对同一把锁上锁,但是某时刻需要在一个函数中调用另一个函数没那么此时就会出现一把锁被锁两次的情况,那么此时如何处理呢?
未避免此类情况发生,C++ 11 推出了递归的互斥量 recursive_mutex ,此类锁允许同一线程对一个互斥量上两次锁,但是需要考虑的是,为什么会出现这种情况?是否是代码有待改进?
六、unique_lock
1. 基本使用
unique_lock基本使用方法与 lock_guard 相似,可以完全替代 lock_guard,但是使用更灵活,代码如下:
void getMail()
{
int mail = 0;
for (int i = 0; i < 100; i++)
{
unique_lock<mutex> mailguard(mailmutex);
if (!mailbox.empty())
{
mail = mailbox.front();
mailbox.erase(mailbox.begin());
cout << "succeed to get mail " << mail << endl;
}
else { cout << "try to get mail, but the box is empty" << endl; }
}
cout << endl;
}
2. 构造参数
在实例化类对象时,除了需要传入互斥量,还可以传入额外参数控制对象属性。
2.1 adopt_lock
adopt_lock,参数表示传入的互斥量已经被锁,无需在构造函数内加锁,使用此参数需要确保传入的互斥量已经加锁,否则势必会引发程序崩溃,代码如下:
void getMail()
{
int mail = 0;
for (int i = 0; i < 100; i++)
{
mailmutex.lock();
unique_lock<mutex> mailguard(mailmutex,adopt_lock);
if (!mailbox.empty())
{
mail = mailbox.front();
mailbox.erase(mailbox.begin());
cout << "succeed to get mail " << mail << endl;
}
else { cout << "try to get mail, but the box is empty" << endl; }
}
cout << endl;
}
2.2 try_to_lock
try_to_lock,表示实例化出的类对象会尝试锁定传入的互斥量,但是即便未锁定成功,代码也不会被原地卡住,而是继续运行,简单来说,普通的对象是一定要锁住才继续运行,try_to_lock 修饰的对象只会尝试一次锁定,失败即略过,代码如下:
void getMail()
{
int mail = 0;
for (int i = 0; i < 100; i++)
{
unique_lock<mutex> mailguard(mailmutex, try_to_lock);
if (mailguard.owns_lock()) //判断是否成功锁定
{
if (!mailbox.empty())
{
mail = mailbox.front();
mailbox.erase(mailbox.begin());
cout << "succeed to get mail " << mail << endl;
}
else { cout << "try to get mail, but the box is empty" << endl; }
}
else { cout << "fail to get mailmutex" << endl; }
}
cout << endl;
}
这样设计可以使得未获取到锁权限的子线程不会被卡在原地等待,而是做一些别的事情,在一定程度上提高程序效率。但是需要注意的是,使用 try_to_lock 参数,则务必不能自行将互斥量锁定,否则程序会卡死。
2.3 defer_lock
derfer_lock,此参数表示将传入的互斥量初始化,且不对其加锁,这样就获得了一个未加锁的互斥量初始化的 unique_lock,进而可以配合成员函数灵活使用,代码如下:
unique_lock<mutex> mailguard(mailmutex, defer_lock);
3. 成员函数
3.1 lock
对互斥量加锁,如果加锁失败则一直等待直到成功加锁,代码如下:
```cpp
void getMail()
{
int mail = 0;
for (int i = 0; i < 100; i++)
{
unique_lock<mutex> mailguard(mailmutex,adopt_lock);
if (!mailbox.empty())
{
mailguard.lock(); //对互斥量加锁
mail = mailbox.front();
mailbox.erase(mailbox.begin());
cout << "succeed to get mail " << mail << endl;
}
else { cout << "try to get mail, but the box is empty" << endl; }
}
cout << endl;
}
3.2 unlock
可以随时对互斥量解锁,相比于 lock_guard 更加灵活,但是解锁后如需访问共享数据,仍然需要加锁,即便不手动解锁,也会在生命周期结束后自动解锁。
3.3 try_lock
尝试对互斥量加锁,即便加锁失败也不会阻塞,代码如下:
void recvMail()
{
for (int i = 0; i < 100; i++)
{
unique_lock<mutex> mailguard(mailmutex, defer_lock);
if (mailguard.try_lock() == 1)
{
cout << "mail " << i << " comes" << endl;
mailbox.push_back(i);
}
else
{
cout << "mail " << i << " lost" << endl;
}
}
}
3.4 release
release,用于解除 unique_lock 与绑定的 mutex 之间的关系,即当互斥量被释放后,unique_lock 不再对互斥量具有所有权。需要注意的是,解除关联后,unique_lock 不再对该互斥量负责,因此有必要手动对释放后的互斥量进行解锁等操作。
总而言之,unique_lock 提供了更加灵活的智能锁定放啊,可以满足各种实用需求,但具体使用时仍需注意,有 lock 必有 unlock,尽可能减少锁住代码的规模,即降低锁的粒度来提高程序效率。
4. 所有权传递
从先前介绍中,相信读者对 unique_lock 有了一定的认知,不难看出,该类依靠与一个 mutex 变量绑定,通过控制 mutex 来实现自动加锁、解锁,在初始化后,该 mutex 的所有权也一直绑定在 unique_lock 对象上,这个所有权不能被复制,很容易理解,多个 unique_lock 共用一把锁,肯定会导致多次加锁、解锁的问题出现引发程序崩溃。
但是这个所有权,是可以被转移的,可以通过 move 函数完成转移,相信对右值熟悉的读者来说并不难理解。
七、条件变量
1. condition_variable
condition_variable,是一个与条件相关的类,类对象与 unique_lock 配合使用,可以实现在条件满足的情况下再完成对互斥量的锁定,从而在一定程度上提高程序效率。
首先在类中声明一个条件变量,代码如下:
condition_variable mailcond;
继续修改代码如下:
void getMail()
{
int mail = 0;
while (1)
{
unique_lock<mutex> mailguard(mailmutex);
mailcond.wait(mailguard, [this]
{
if (!mailbox.empty()) { return true; }
return false;
}
);
mail = mailbox.front();
mailbox.erase(mailbox.begin());
cout << "succeed to get mail " << mail << endl;
mailguard.unlock();
}
cout << endl;
}
当且仅当 wait 函数中第二个参数为真时,线程才会继续运行,否则会释放掉锁,等待唤醒,那么如何唤醒呢?这就需要另一个函数。
2. notify_one
notify_one,用于唤醒一个停滞的 wait,使其尝试正常工作,代码如下:
void recvMail()
{
for (int i = 0; i < 100; i++)
{
unique_lock<mutex> mailguard(mailmutex);
cout << "mail " << i << " comes" << endl;
mailbox.push_back(i);
mailcond.notify_one();
}
}
接下来详细分析其工作流程,当前在按程序中存在一个 wait 处于睡眠状态等待被唤醒,这时 notify_one 唤醒了这个线程,wait 被唤醒后,首先会尝试获取锁,如果没有获取到,则会不停尝试,直到获取成功;获取到锁后,继续判断第二个参数是否为真,若为真,则继续执行;若为假,则释放锁,再次睡眠,表达式默认为真。整个工作流程便是如此,希望读者能够完全理解。
3. notify_all
notify_all,可以用于唤醒所有处于睡眠状态的 wait 线程,但是由于这些 wait 函数都需要竞争一把锁,因此仅能有一个线程获得锁,并在满足第二参数条件的情况下顺利执行,其余得到锁但不满足第二参数条件的线程将再度沉睡,未得到锁的 wait 函数继续竞争。
八、async
1. 基本使用
async,作为一个函数模板,专门用于创建或启动一个异步任务,在启动对应异步任务后,会返回一个 future 类对象,表示异步任务的返回结果。
所谓异步任务,即创建一个新的线程(也可能不会创建线程),并执行对应的入口函数,并且返回一个 future 类对象,此对象中包含异步任务的执行结果,可以通过成员函数获得。
future,作为类模板,提供一种异步操作结果访问机制,表示这个结果即便现在无法立刻拿到,但可以在未来某个时间点获得,常与 async 搭配使用,代码如下:
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
#include <future>
using namespace std;
int plusThread(int a)
{
cout << "plusThread start, id = " << this_thread::get_id() << endl;
a++;
cout << "plusThread run" << endl;
cout << "plusThread end" << endl;
return a;
}
int main()
{
cout << "main start, id = " << this_thread::get_id() << endl;
future<int> ans = async(plusThread, 10); //虽然创建了异步任务,但并不立刻执行
cout << "main continue" << endl;
cout << ans.get() << endl; //在此处,异步任务才开始执行,获得结果
return 0;
}
//输出结果
//main start, id = 31368
//main continue
//plusThread start, id = 31392
//plusThread run
//plusThread end
//11
不难看出,异步任务并没有在创建时便立刻执行,而是直到需要获取结果时才开始执行,返回结果。
2. 参数分析
async,提供了一个 launch 类型的额外参数,用于控制执行方式。
2.1 deferred
deferred,使用此参数,表示允许创建出的异步任务延迟,直至调用 future or wait 时再开始执行,如果没有调用,则放弃执行,代码如下:
future<int> ans = async(launch::deferred, plusThread, 10);
//输出结果
//main start, id = 31368
//main continue
//plusThread start, id = 31368
//plusThread run
//plusThread end
//11
从输出结果可以看到,甚至并没有创建出新的线程,直接在主线程中运行得到了结果。
2.2 async
async,使用此参数表示要求系统必须创建出新的线程执行入口函数,代码如下:
future<int> ans = async(launch::async, plusThread, 10);
//输出结果
//main start, id = 31368
//main continue
//plusThread start, id = 31392
//plusThread run
//plusThread end
//11
可以发现系统确实创建出了新的线程执行入口函数,并且读者可以自行尝试,即便不调用 get 函数,线程依然会执行。
2.3 deferred | async
同时使用两个参数,表示允许系统根据情况选择使用两种方式中的任意一种,也是函数的默认参数。
3. async & thread
了解过 async 的默认参数后,相信不难理解两者的不同之处。
thread,线程一旦被创建,就应立刻开始执行,线程结束且没有返回结果;async,可以选择控制异步任务执行时机,在允许情况下甚至可以不予执行,从而一定程度上解决计算机资源。
4. future
在前文提到了 future 类模板,表示一个可以在将来获取到的结果,除了get 之外,还有许多函数提供额外的功能,代码如下:
int main()
{
cout << "main start, id = " << this_thread::get_id() << endl;
future<int> ans = async(plusThread, 10);
cout << "main continue" << endl;
//cout << ans.get() << endl; 仅能获取一次结果
future_status status = ans.wait_for(chrono::seconds(1)); // 表示等待一秒
if (status == future_status::timeout) { cout << "timeout" << endl; cout << ans.get(); }
else if (status == future_status::ready) { cout << "already" << endl; cout << ans.get() << endl; }
else if (status == future_status::deferred) { cout << "delay" << endl; cout << ans.get(); }
return 0;
}
可以通过对应变量查看异步任务执行状态。
九、原子操作
前文讲到,互斥量可以保护访问共享数据的代码不被打断,使得共享数据不会被破坏,本质上可以看做利用互斥量完成了一个不会被打断的操作,在此段代码执行时,不允许其余代码打断此代码的操作,这也就是原子操作的定义所在。
在 C++ 11 中,引入了 atomic 代表原子操作,可以用其封装一个值,使得对此值的操作变为原子操作,不允许被打断,代码如下:
atomic<int> at_i = 0;
这就封装了一个整型原子变量,对此变量进行的操作也全部成为原子操作,但仍需注意,在一条语句中,尽可能保证原子变量金出现一次,否则可能引发程序崩溃,代码如下:
at_i++;
at_i+=1;
//at_i = at_i + 1; 不允许
本章总结
本章主要讨论了并发与多线程的相关知识,内容众多,但也看看入门,希望对初次了解此内容的读者有所帮助,更为详细的讲解笔者会陆续推出。
最后,我是Alkaid#3529,一个追求不断进步的学生,期待你的关注!

















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











