







目录
(4.9)unordered_map与unordered_set等
一、STL总述
- C++标准库:英文名字是C++Standard Library。
- 标准模板库:英文名字是StandardTemplateLibrary(STL)。包含在C++标准库之中,作为C++标准库的一个重要组成部分或者说是C++标准库的核心,深深影响着标准库。
- C++标准库中包含很多的头文件,其中和STL相关的头文件有几十上百个(不同的STL版本的文件数目不同)。在使用STL的时候,也需要把这些头文件包含到自己的项目中来,现代版本标准库中的头文件名字,已经把.h扩展名去掉,变成了没有扩展名的头文件。还有一些C语言的标准头文件,以往的如#include<stdlib.h>,在新版本下推荐写成#include<cstdlib>。注意,这种写法是文件名前面多了个字母c,文件扩展名.h也被去掉了。当然,老版本的写法#include<stdlib.h>仍然能用(因为这些.h文件依然存在)。
- STL的组成部分:容器、迭代器、算法(可以理解成STL提供的一些函数,用来实现一些功能,例如查找用到search,排序用到sort,复制用到copy)、分配器(用于分配内存)、其他(包括适配器、仿函数/函数对象等)。

1.容器
STL中的容器可以分成三类:顺序容器、关联容器、无序容器。
(1)顺序容器
顺序容器(Sequence Containers)的意思就是放进去的时候把这个元素(放进容器中的数据称为容器中的元素)排在哪里,它就在哪里,例如把它排在最前面,那它就会一直在最前面待着,这就是顺序容器。如array、vector、deque、list、forward_list等容器都是顺序容器。
(2)关联容器
这种容器,它的每一个元素都是一个键值(key/value)对,用这个键来找这个值就特别迅速和方便。
关联容器的内部一般是使用一种称为“树”的数据结构实现数据的存储。刚刚谈到顺序容器时笔者说过,顺序容器是那种放进去的时候把这个元素排在哪里,它就在哪里。而关联容器则不同,把一个元素放到关联容器里去的时候,该关联容器会根据一些规则,如根据key,把这个元素自动放到某个位置。
换句话说,程序员不能控制元素插入的位置,只能控制插入的内容。set、map、multiset、multimap等都属于关联容器(Associative Containers)。
(3)无序容器
这种容器是C++11里推出的容器,按照官方的说法,这种容器里面的元素位置不重要,唯一重要的是这个元素是否在这个集合内。一般插入这种元素的时候也不需要给要插入的元素安排位置,这种容器也是会自动给元素安排位置。所以,根据这种容器的特点,无序容器(Unordered Containers)应该属于一种关联容器。
随着往这个容器中增加的元素数量的增多,很可能某个元素在容器中的位置会发生改变,这是由该容器内部的算法决定的。因此“无序容器”这种名字还是挺贴切的。无序容器内部一般是用哈希表这种数据结构来实现的。例如,unordered_set、unordered_multiset、unordered_map、unordered_multimap等都是无序容器。
C++标准并没有规定任何容器必须使用任何特定的实现手段。但一般来讲,都有规律可循,例如map用的是树这种数据结构存储数据,hash_开头的容器一般用的是哈希表这种数据结构存储数据。
(4)常用容器
(4.1)array 数组
array是一个顺序容器,其实是一个数组,所以它的空间是连续的,大小是固定的,刚开始时申请多大,就是多大,不能增加它的大小。
(4.2)vector
vector的空间是连续的,这个空间一增长,就要找一块新的足以容纳下当前所有元素的内存,把所有元素搬到新内存去,这一搬就很容易想到,老的容器中元素要析构,这些搬来的元素都要重新执行构造函数来构造。这显然非常影响程序执行效率。
容器里面有多少个元素可以用size来查看,而容器的空间可以用capacity来查看。capacity的结果一定不会小于size,也就是说容器中空间的数量一定不会比元素数量少。
当vector容器中删除一个元素时,会导致执行一次析构函数,然后所有后续元素的内存往前动(至少从表面上看元素对象是往前移动了),但并没有执行这些移动了的对象的任何构造和析构函数,这说明编译器内部有自己的处理,这个处理就很好。
向vector容器中间插入元素会导致后续的一些元素都被析构和重新构造,从中间插入元素代价都很大。所以,如果事先不知道有多少个元素要往vector里插入,需要的时候就往里插入一个,那么显然vector容器的运行效率应该不会高——频繁大量地构造、析构、寻找新的整块内存,这都是很让开发者忌讳的。但是,如果事先知道整个程序运行中这个vector容器里最多也不会超过多少个元素,例如程序员知道最多也不会超过10个元素,那就让capacity事先等于10(在容器中预留10个空间),这样往容器中插入元素时,只要不超过10个,那么就不需要频繁地构造和析构元素对象。换句话说,就不需要寻找新的整块内存进行元素搬迁了(所以,利用好capacity也能够提升vector容器的效率。)。
(4.3)deque 队列
deque这种顺序容器是一个双端队列(双向开口),deque是double-ended queue的缩写。该队列相当于一个动态数组,因为它是双端的,所以无论在头部还是在尾部插入和删除数据都会很快,但是若要在中间插入数据,因为要移动其他元素,效率就会比较低。
deque其实是一个分段数组。当插入元素多的时候,它就会把元素分到多个段中去,当然,每一段的内存是连续的(所以只能说内存是分段连续)。
(4.4)stack 栈
stack和vector有点类似,但请注意,vector还支持insert、erase,也就是说,vector支持从中间插入和删除元素的操作。但是stack只支持往栈顶放入元素和从栈顶取出元素(删除元素),因为stack这种容器设计的初衷就要求具备这种特性。
deque是包含stack功能的。
(4.5)queue 队列
deque是双端队列,但queue是普通队列(简称队列)。队列是一种比较基本的数据结构,其特点是先进先出。也就是说,元素从一端进入,从另一端取出(删除元素),queue容器设计的初衷就要求具备这种特性。
deque也是包含queue功能的。
(4.6)list 双向链表
list这种顺序容器是一个双向链表。各个元素之间不需要紧挨在一起,只需要用指针通过指向把元素关联起来即可。
list双向链表的特点:查找元素要沿着链来找,所以查找的效率并不突出,但因为它是一个双向链,所以在任意位置插入和删除元素都非常迅速——几个元素中的指针一改变指向就可以了。
(4.7)forward_list 单向链表
这是C++11新增加的顺序容器,是一个单向链表。forward_list比list少了一个方向的链(指针),官方称它为受限的list。少了一个方向的指针,会造成一定的访问不便,但是少了一个方向的指针后,一个容器中的元素就能节省下4字节的内存(在x86平台下)。容器中的元素若是很多,则省下的内存也很可观。
很多容器都有push_back成员函数,但是forward_list容器只有push_front,这说明这个容器最适合的是往前头插入元素。
(4.8)map和set
map和set都是关联容器。map和set这类容器内部的实现多为红黑树,红黑树这种数据结构本身内部有一套很好的保存数据的机制。向这种容器中保存数据的时候不需要指定数据的位置,这种容器会自动给加入的元素根据内部算法安排位置。
插入元素的时候,因为这类容器要给插入的元素找一个合适的位置,所以插入的速度可能会慢一些,但是,得到的好处是查找的时候快,所以对于需要快速找到元素的应用场景,重点考虑使用map、set这类容器。
map容器的每个元素(树节点)都是一个键值对(key/value)。这种容器通过key查找value的速度非常快,但不允许在一个map容器中出现两个相同的key,所以,如果key有可能重复,请使用multimap容器。
set容器中的元素没有key和value之分,每个元素就是一个value。元素保存到容器中后,容器会自动把这个元素放到一个位置,每个元素的值不允许重复,重复的元素插入进去也没有效果。如果想插入重复的元素,请使用multiset容器。
(4.9)unordered_map与unordered_set等
以往的诸如hash_set、hash_map、hash_multiset、hash_multimap,这些老的容器也能使用,但并不推荐使用了,新版本的容器一般都是以unordered_开头了。以unordered_开头的容器属于无序容器(关联容器的一种),无序容器内部一般是使用哈希表(散列表)来实现的。
unordered_map和unordered_multimap每个元素同样是一个键值对,unordered_map中保存的键是不允许重复的,而unordered_multimap中保存的键可以重复。
unordered_set和unordered_multiset的每个元素都是一个值,unordered_set中保存的值不允许重复,而unordered_multiset中保存的值可以重复。
(4.10)vector和list这两个容器的区别
- vector类似于数组,它的内存空间是连续的,list是双向链表,内存空间并不连续。
- vector插入、删除元素效率比较低,但list插入、删除元素效率就非常高。
- vector当内存不够时,会重新找一块内存,对原来内存中的元素做析构,在新找的内存重新建立这些对象(容器中的元素)。
- vector能进行高效的随机存取(跳转到某个指定的位置存取),而list做不到这一点。例如,要访问第5个元素,vector因为内存是连续的,所以极其迅速,它一下就能定位到第5个元素(一个指针跳跃一定数量的字节就可以到达指定位置)。反观list,要找到第5个元素,得顺着这个链逐个地找下去,一直找到第5个。所以说vector随机存取非常快,而list随机存取比较慢。
2.分配器
跟容器紧密关联在一起使用的是分配器,只是在编写代码时,一般都采用系统默认的分配器,不需要自己去指定分配器。
std::list<int> list;
std::list<int, std::allocator<int>> list;分配器的引入主要扮演内存池的角色,大量减少对malloc的调用以减少对内存分配的浪费。(分配器就是一次分配一大块内存,然后从这一大块内存中给程序员每次分配一小块来使用,用链表把这些内存块管理起来。这种内存池的内存分配机制有效地减少了调用malloc的次数,也就等于减少了内存的浪费,同时还一定程度上提高了程序运行效率。)
#include <list>
void TestSTL()
{
//分配器
std::list<int> list;//默认的分配器std::allocator<int>,并没有实现内存池
list.push_back(1);
list.push_back(2);
list.push_back(3);
//迭代器
for (std::list<int>::iterator iter = list.begin(); iter != list.end(); iter++)
{
std::cout << *iter << std::endl;
}
}系统默认为程序员提供了allocator这个默认的分配器,这是一个类模板,是标准库里写好的,直接提供给程序员使用的。当然,程序员也可以写一个自己的分配器用在容器中,这是可行的。默认的allocator到底怎样实现的,除非读它的源码,否则并不清楚它是否是通过一个内存池来实现内存分配的,也可能它根本就没实现什么内存池,而是最终简单地调用底层的malloc来分配内存,这都是有可能的。
分配器是一个类模板,带着一个类型模板参数。C++标准库中的容器,如std::vector、std::list等,默认使用std::allocator作为其分配器。但是用户可以提供自定义的分配器来改变容器如何获取和释放内存。一个典型的分配器需要定义以下类型和函数:
- value_type: 分配值的类型。
- allocate(): 分配未初始化内存。
- deallocate(): 释放先前由 allocate 分配的内存。
- construct(): 在给定位置上构造元素。
- destroy(): 销毁在给定位置上已经构造好的元素。
3.迭代器
迭代器是一个“可遍历STL容器全部或部分元素”的对象(为了方便理解,可以把迭代器理解为:行为类似于指针的对象)。迭代器用来表现容器中的某一个位置,迭代器是由容器来提供的。也就是说,一般来讲,是容器里面定义着迭代器的具体类型细节。
既然迭代器可以理解成行为类似于指针的对象,那么对于指针,可以用如*p来读取指针所指向的内容,所以对于迭代器,用如*iter一般也能读取到迭代器所指向的内容。
(1)迭代器的分类
迭代器与一个指针一样,到处跳,表示一个位置。分类也是根据它跳跃的能力来分的,每个分类都对应着一个struct结构。迭代器主要分为以下5类,这些结构是有继承关系的。
- 输出型迭代器(Output iterator)
- 输入型迭代器(Input iterator)
- 前向迭代器(Forward iterator)
- 双向迭代器(Bidirectional iterator)
- 随机访问迭代器(Random-access iterator)
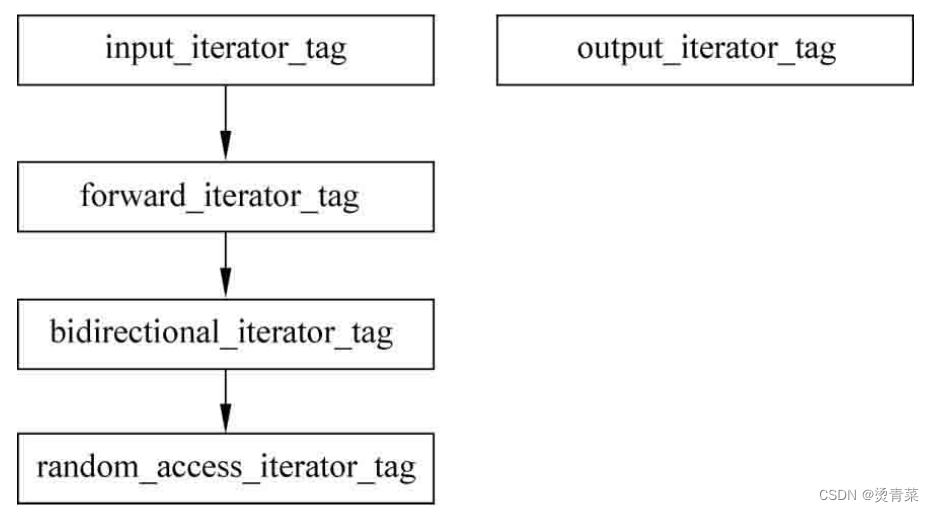

所谓随机读取,指的是跳过一定个数的元素,如当前位置在第1个元素这里,可以立即跳过3个元素直达第4个元素。随机访问迭代器看起来最灵活,因为随机访问迭代器支持的操作最多,如一次可以跳跃多个元素等。其所支持的容器array、vector的元素内存都是连续的,所以要跳到如第5个元素上,非常方便,做个加法运算,就立即能跳过去。deque这个双端队列容器虽然支持的迭代器也是随机访问迭代器,但这个容器是分段连续的,也就是说内存中它并不是真连续,虽然不是真连续,但它的迭代器仍旧是随机访问,也就是一次可以跳跃多个元素,这个设计还是挺精妙的。总之,支持随机访问迭代器的容器多数都是内存连续的。
也可以看到vector和list容器的区别:这两个容器所支持的迭代器类型不同,vector容器支持的是随机访问迭代器,list容器支持的是双向迭代器,没有随机访问迭代器支持这么多的迭代器操作。所以,vector容器和list容器的一个主要区别就是:vector能进行高效的随机存取,而list做不到这一点。
4.算法
算法可以理解成函数。更准确的说法是:算法理解为函数模板。STL中提供了很多算法,如查找、排序等,有数十上百个之多,而且数量还在不断增加中。
每个容器都带着许多适合该容器自身进行各种操作的成员函数,而算法不同于这些成员函数,可以把算法理解成全局函数或者全局函数模板(不针对某一个容器,但对部分或者大部分容器都适用)。既然算法是函数模板,它就有参数,也就是形参,那么传递进来的这些形参的类型一般前两个形参都是迭代器类型,用来表示某个容器中元素的一个区间,这个区间还得注意一下。
这种前闭后开区间的好处一般认为有两条:
- 算法只要判断迭代器等于后面这个开区间,那就表示迭代结束。
- 如果第一个形参等于第二个形参,那这就表示是一个空区间。
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {4, 2, 5, 3, 1};
std::sort(v.begin(), v.end());
// 现在v包含{1, 2, 3, 4, 5}
return 0;
}算法是一种搭配迭代器来使用的全局函数(或全局函数模板)。这些算法和具体容器没有什么关系,只跟迭代器有关,大部分容器都有迭代器。也就是说,这些算法对于大部分容器都是适合的,不需要针对某种容器专门定制。
当然,算法作为单独的一个函数(函数模板)来实现,也是违背了面向对象程序设计所讲究的封装性(把成员变量、成员函数包装到一起)的特点,这一点是比较遗憾的。
(1)常用算法
(1.1)for_each
for_each看起来像一个语句,实际是一个算法。
for_each的第一个和第二个形参都是迭代器,表示一段范围(或者说表示某个容器中的一段元素),for_each的第三个参数实际上是一个可调用对象。
(1.2)find
find用于寻找某个特定值。
有些容器自己有同名的成员函数(包括但不限于这里讲到的find函数),优先使用同名的成员函数(但同名的成员函数不像算法,一般不需要传递进去迭代器作为前两个参数),如果没有同名的成员函数,才考虑用全局的算法。
(1.3)find_if
find_if的调用返回一个迭代器(如:vector<int>::iterator),指向第一个满足条件的元素,如果这样的元素不存在,则这个迭代器会指向vector.end()。这个算法与find类似,只是find第三个参数是一个数字,而这里的find_if的第三个参数是一个可调用对象(lambda表达式),这个可调用对象里有一个规则——找第一个满足该规则的元素。
(1.4)sort
sort用于排序的目的。
sort算法应用于list容器时会报错,说明这个算法对list容器不适用。因为sort算法适用于随机访问迭代器而不适用于双向迭代器。
list容器有自己的sort成员函数,当然就使用list容器自身提供的sort成员函数了。
5.函数对象
sort的第三个参数是一个函数对象(functionobjects)或者叫仿函数(functors),用来指定一个排序的规则。仿函数其实就是函数对象,只不过仿函数这个称呼比较老,新称呼是函数对象。
这种函数对象在STL里面一般都是用来跟算法配合使用以实现一些特定的功能。换句话来说,这些函数对象主要用来服务于算法。

(1)自定义函数对象
bool myCompare(int a, int b) {
return (a > b);
}
int main() {
std::vector<int> v = {1, 5, 2, 4, 3};
std::sort(v.begin(), v.end(), myCompare);
}(2)标准库中定义的函数对象
除了自己写的函数对象,标准库中也提供了许多可以现成拿来使用的函数对象。函数对象分类:算术运算类、关系运算类、逻辑运算类、位运算类。
#include <functional>



std::cout << std::plus<int>()(3, 5) << std::endl;- plus <int>是一个实例化了的类。
- 类名后面加一个圆括号也就是“plus<int>()”代表生成一个类plus<int>的临时对象(因为plus中重载了operator(),所以这个临时对象是一个可调用对象)。
- 为了调用这个可调用对象,在临时对象后面,增加圆括号(),之后plus类模板的operator()中有什么参数,这个圆括号中就要有什么参数。(plus类模板的operator()中需要两个参数。)















 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











