






最近在学习目标检测,要用Cascde RCNN训练自己的数据集,因为本地电脑没有GPU,所以就借用Colab云端来进行模型训练,想要记录一下操作过程,以及希望可以给更多电脑没有GPU,但是需要用mmdetection做项目的同种情况的人一些参考。
目录
一、Colab平台准备(要先做到科学上网才能使用Colab)
3、安装mmdete所需要的依赖包和环境,因为Colab上面已经配置了pytorch和cuda,所以配置过程很简单
一、Colab平台准备(要先做到科学上网才能使用Colab)
1、上传自己的数据集
数据集的制作过程不做多余赘述,可以在CSDN上找到很多参考资料,本文使用的数据集是voc2007数据集,如果是自己本地制作的数据集,就需要先上传到谷歌云盘。
官网链接:https://drive.google.com/drive/my-drive
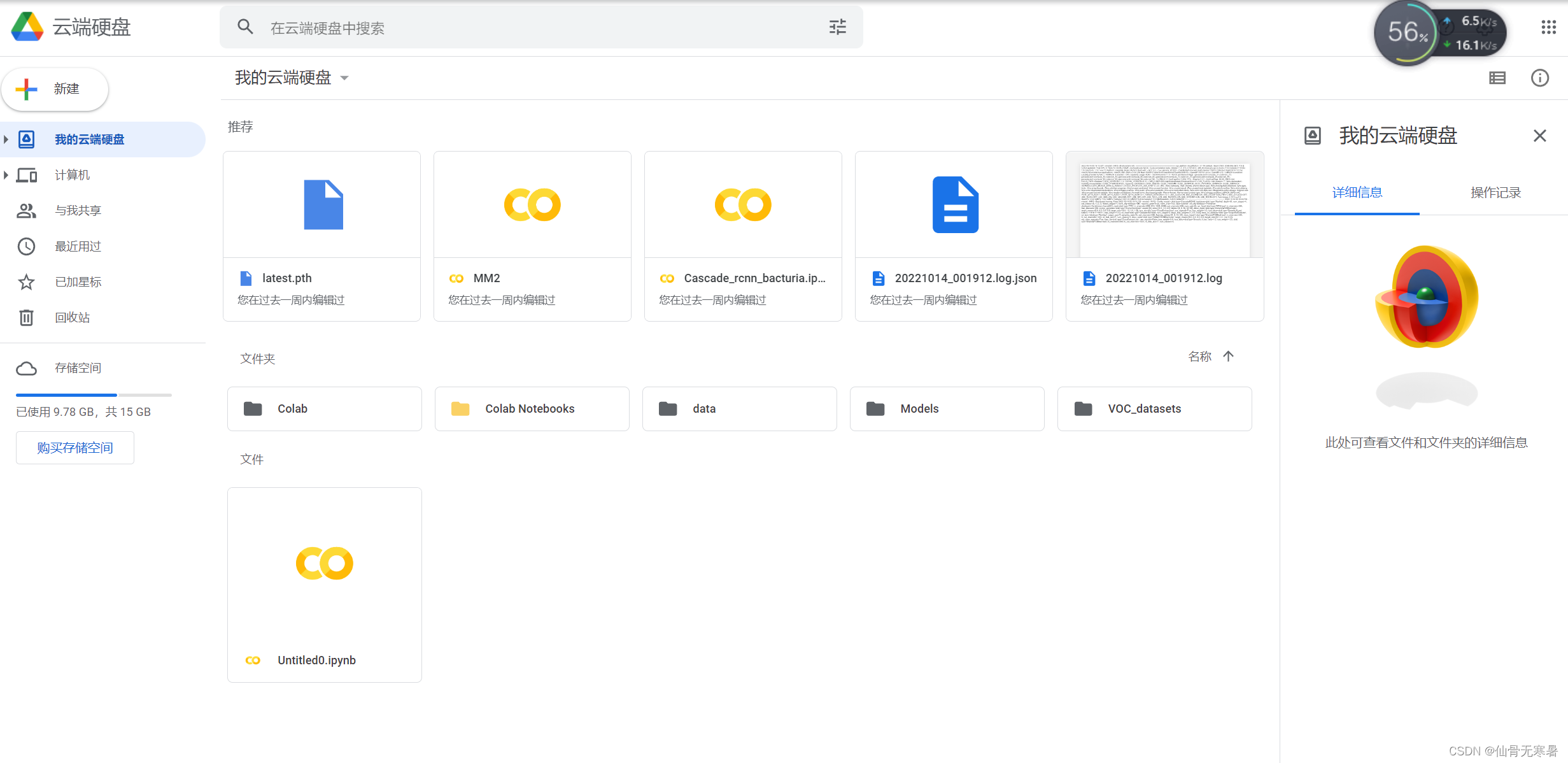
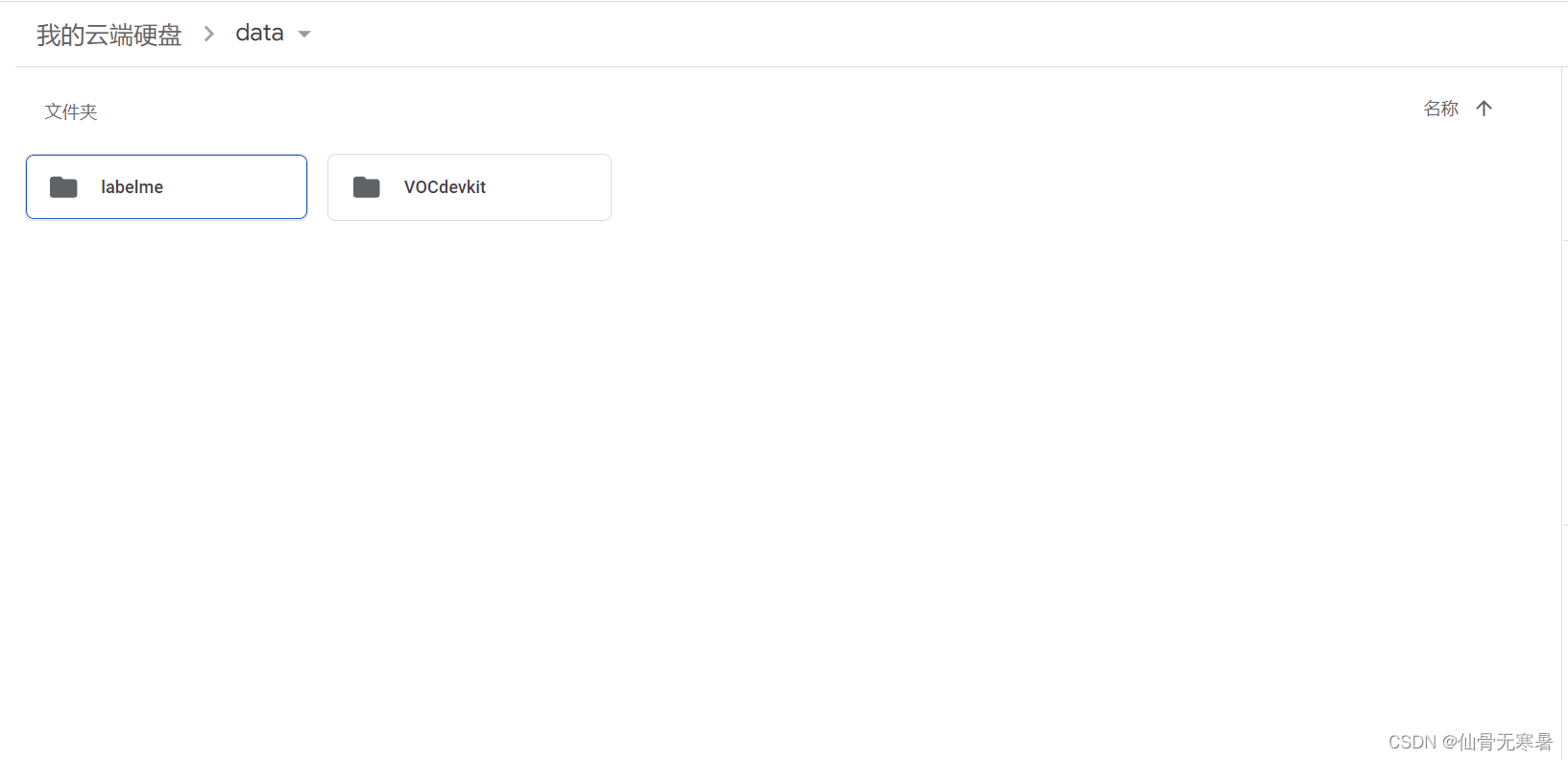
点击新建,新建文件夹data存放数据集,然后打开data文件,直接将数据集拖拽就可以完成数据集的上传
2、配置使用Colab
点击新建,新建Colab项目,命名为Mmdetection-master
修改配置,点击代码执行程序,点击更改运行时类型,将加速器更改为GPU,这样就可以白嫖GPU了。
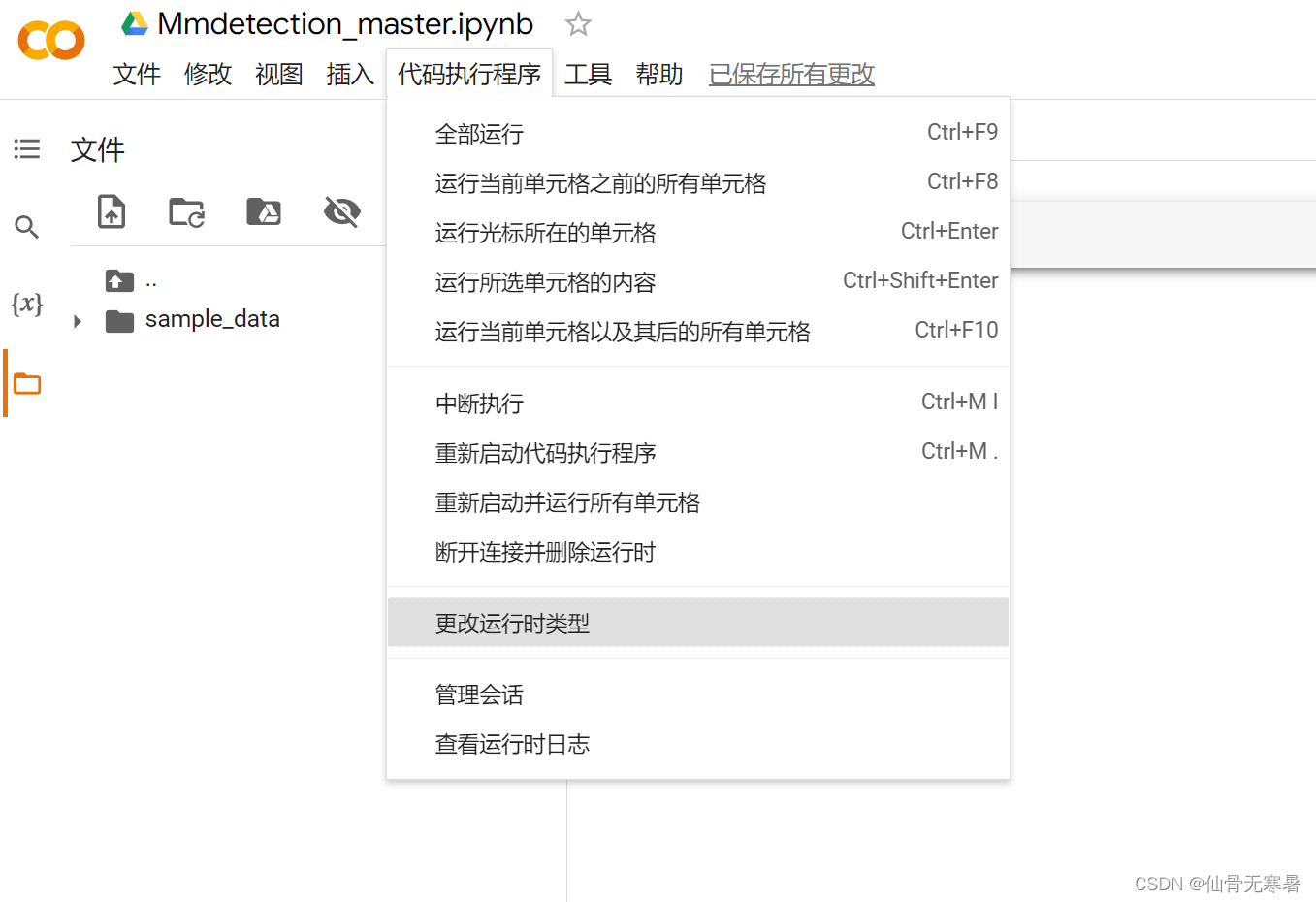

输入代码查看显卡配置
!nvcc -V
!gcc --version
!rm -rf /content/sample_data
#查看分配的显卡配置,建议刷到v100
!nvidia-smi挂载云盘,连接到自己的谷歌云盘
from google.colab import drive
drive.mount('/content/drive')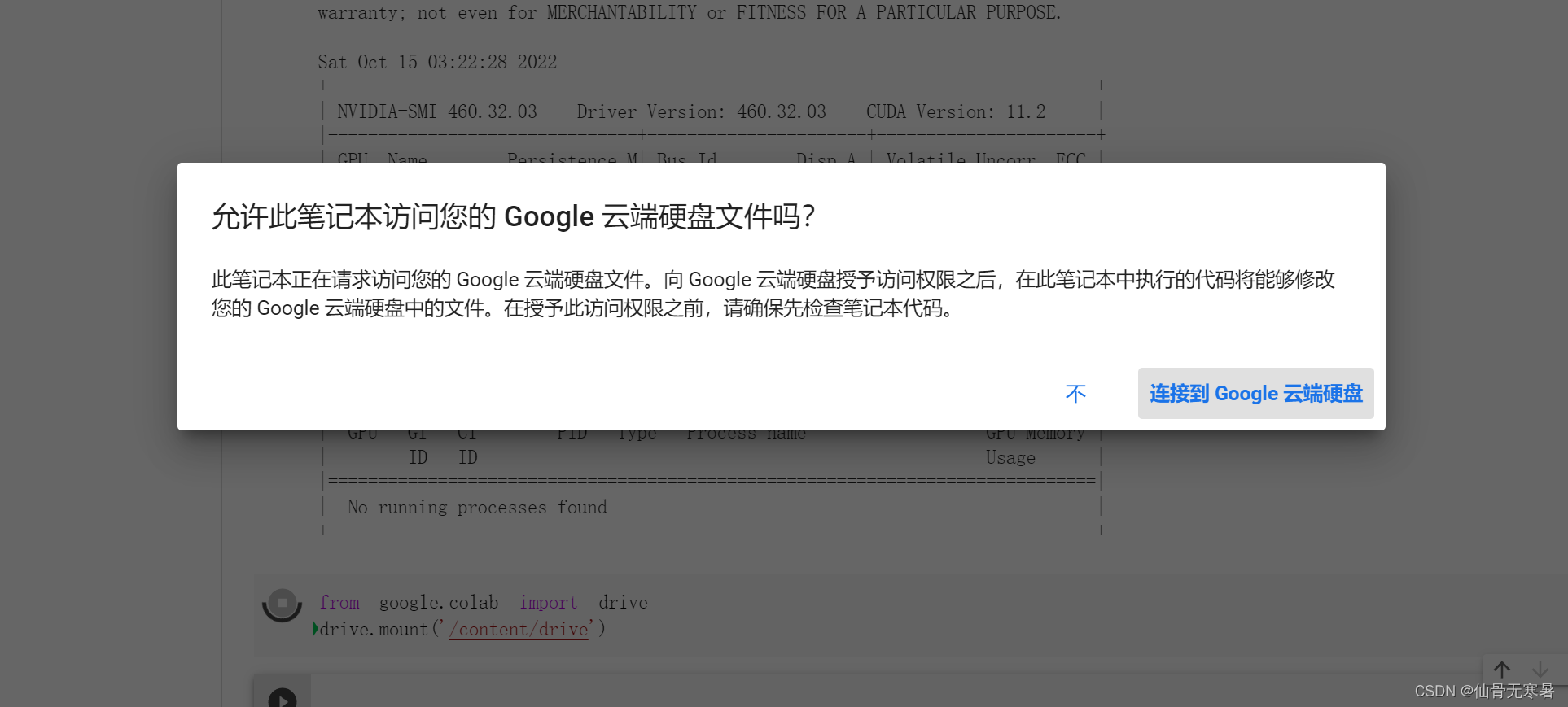
点击刷新就会出现自己的云盘文件夹
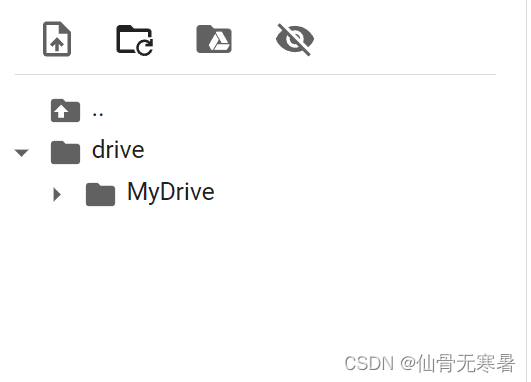
二、在Colab上配置mmdetection环境并训练
这里有官网的文档,大家也可以做一个参考https://mmdetection.readthedocs.io/en/stable/get_started.html
1、下载mmdetection
%cd /content
!rm -rf mmdetection
!git clone https://github.com/open-mmlab/mmdetection.git
#新建一个存放数据集的文件夹
!mkdir mmdetection/data2、配置数据集
#将云盘里的数据集复制到mmdet项目里面
!cp -r /content/drive/MyDrive/data/VOCdevkit -d /content/mmdetection/data/VOCdevkit
#!cp -r 源地址 -d 目标地址一定要注意数据集的目录是下图的格式

3、安装mmdete所需要的依赖包和环境,因为Colab上面已经配置了pytorch和cuda,所以配置过程很简单
先切换到mmdetection项目
#切换当前目录
%cd /content/mmdetection# 成功配置
!pip install -U openmim
!mim install mmcv-full!pip install -r requirements/build.txt
!python setup.py develop要注意两段代码的先后过程,如果反了就会在训练的时候出现以下出现错误,如果出现了,建议卸载mmdet,!pip uninstall mmdet,再重新利用第二段代码进行mmdet安装
# AssertionError: The `num_classes` (4) in Shared2FCBBoxHead of MMDataParallel does not matches the length of `CLASSES` 20) in RepeatDataset
然后用下面代码测试相关环境是否安装成功
import mmdet
print(mmdet.__version__)
# Check mmcv installation
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
print(get_compiling_cuda_version())
print(get_compiler_version())
4、进行相关参数的修改
这里参考了相关文章https://blog.csdn.net/weixin_45798949/article/details/107976157
这里选用cascade_rcnn方法,也可以选择fasterrcnn方法,修改类似
1.修改:mmdetection/configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py
_base_ = [
'../_base_/models/cascade_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
改:
_base_ = [
'../_base_/models/cascade_rcnn_r50_fpn.py',
'../_base_/datasets/voc0712.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
2.修改:mmdetection/configs/_base_/datasets/voc712.py
找到,并注释掉一句voc2012
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='RepeatDataset',
times=3,
dataset=dict(
type=dataset_type,
ann_file=[
data_root + 'VOC2007/ImageSets/Main/trainval.txt',
#data_root + 'VOC2012/ImageSets/Main/trainval.txt'
], # 把含有VOC2012的路径去掉
img_prefix=[data_root + 'VOC2007/', data_root + 'VOC2012/'],
pipeline=train_pipeline)),
3.修改:mmdetection/configs/_base_/models/cascade_rcnn_r50_fpn.py
num_classes的值,一共三处,分别修改,不然报错。
根据自己的分类的个数,不需要
考虑背景+1,一类就写1
如果想换预训练模型
model = dict(
type='CascadeRCNN',
pretrained='torchvision://resnet50',#可欢resnet101等
4.修改:mmdetection/mmdet/core/evaluation/class_names.py
def voc_classes():
return [
'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person',
'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'
]#对应换成自己标签。
def voc_classes():
return ['lf', ]#我是一类,后面加逗号
5.修改:mmdetection/mmdet/datasets/voc.py
class VOCDataset(XMLDataset):
CLASSES = ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
'tvmonitor')
修改同上
修改完成之后重新进行编译
!python setup.py develop5、开始训练数据集
因为Colab特别容易掉线,所以建议先配置一下Colab网页防止掉线
在任意网页端右键,点击检查,点击Console
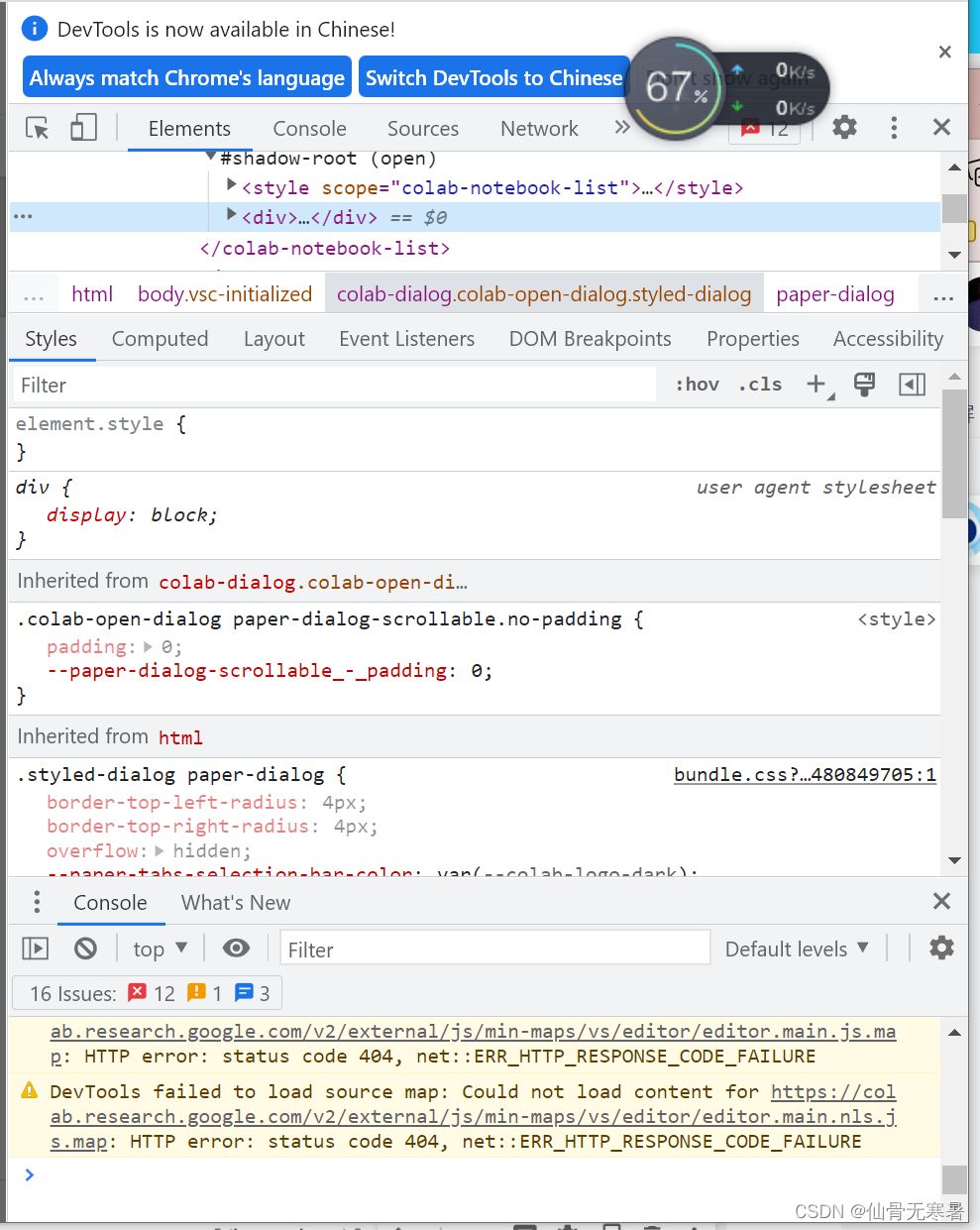
添加一下代码
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,60000);
然后开始美美训练
!python tools/train.py ./configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py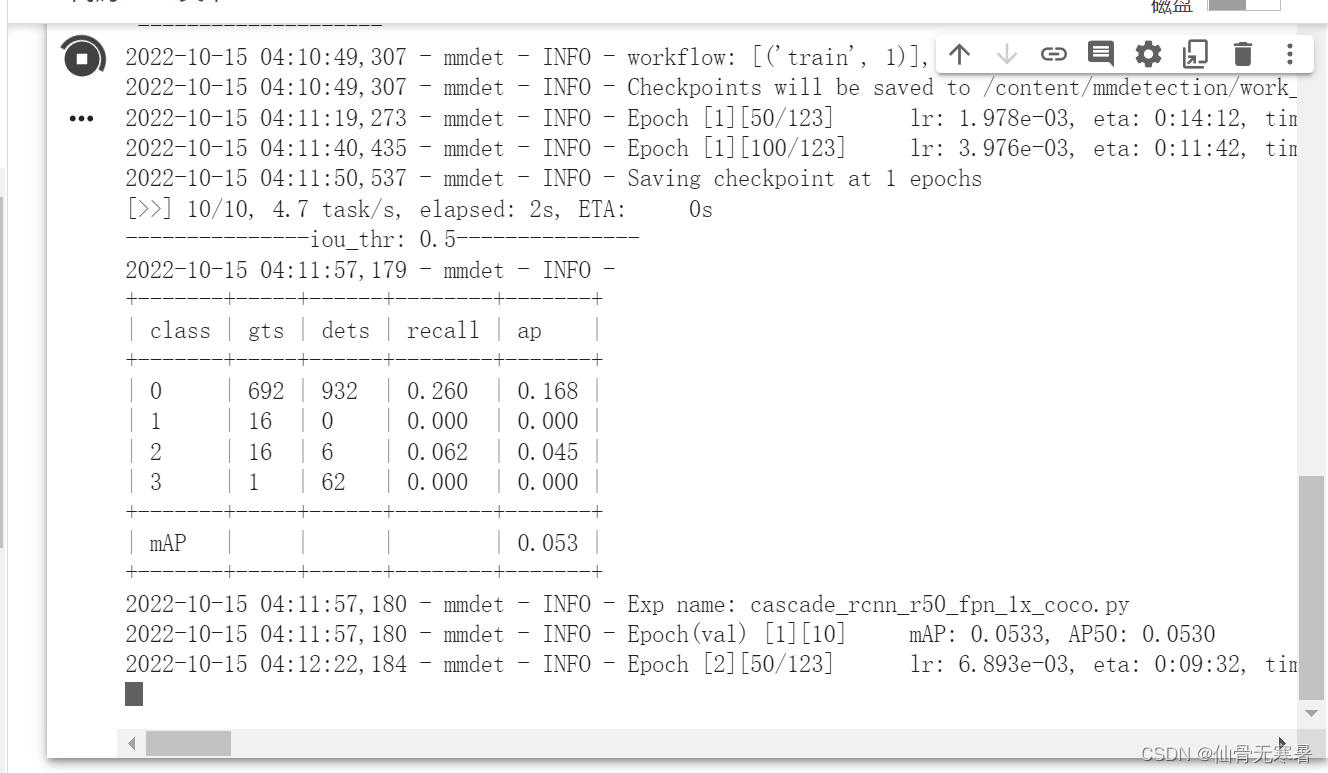
训练的结果权重都保存在work_dir目录下面,点击下载就可下载到本地使用了。
还有就是所有相关参数,例如学习率,epoch,backbone都在以下四个文件中,可以进行查找然后修改相关参数
_base_ = [
'../_base_/models/cascade_rcnn_r50_fpn.py',
'../_base_/datasets/voc0712.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]对于已经训练好了的模型权重可以这样进行测试使用
python demo/image_demo.py demo/img.jpg configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py work_dirs/cascade_rcnn_r50_fpn_1x_coco/epoch_48.pth --device cpu --out-file result1.jpg
#python 图片path configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py 权重path --device cpu --out-file 结果path更方便的是新建一个py文件进行编译
from mmdet.apis import init_detector, inference_detector
import mmcv
# Specify the path to model config and checkpoint file
config_file = 'configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py'
checkpoint_file = 'work_dirs/cascade_rcnn_r50_fpn_1x_coco/epoch_48.pth'
# build the model from a config file and a checkpoint file
model = init_detector(config_file, checkpoint_file, device='cpu')
# test a single image and show the results
img = 'image/0060_Color.jpg'
# img = mmcv.imread(img) # which will only load it once
result = inference_detector(model, img)
# visualize the results in a new window
# 可视化推理检测的结果
model.show_result(img, result)
# or save the visualization results to image files
# 将推理的结果保存
model.show_result(img, result, out_file='result_new.jpg')
# test a video and show the results
# 测试视频片段的推理结果
# video = mmcv.VideoReader('video.mp4')
# for frame in video:
# result = inference_detector(model, frame)
# model.show_result(frame, result, wait_time=1)
三、总结
本文主要是为了帮助像我一样的没有GPU来炼丹的cv初学者,如果只是简单的项目的话,希望你不要因为本地没有GPU而烦恼,不得不说Cascade RCNN的精确度确实很顶,小目标检测太绝了。















 8503
8503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









